目录
-
论文阅读
-
代码简析
-
小结
论文阅读
Inception V2是Inception家族的一个中间件产物,在论文Rethinking the Inception Architecture for Computer Vision中提到了Inception V2的概念,但是google的代码实现却是命名为Inception V3。从google实现的Inception V2源码可以看出V2的改进主要是以下两点:
- 使用了Batch Normalization,Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- 用两个3x3Convolution替代一个5x5Convolution,Rethinking the Inception Architecture for Computer Vision
此文论文阅读只会学习一下Batch Normalization这篇论文,Rethinking the Inception Architecture for Computer Vision这篇论文在学习Inception V3的网络的时候再仔细阅读。
1.前言
训练深度神经网络的时候每一层的输入会随着训练发生变化,因为前一层参数的变化会引起这一层输入的分布发生变化,作者把这种现象叫做internal covariate shift。这种现象会导致我们需要设置更小的learning rate,需要很小心设置参数的初始值,否则网络可能训练变慢难以收敛。作者提出了一种batch normalization的方式来解决这个问题。试验下来如果使用BN只需1/14的训练次数可以达到同样的精确度,并且可以让我们在ImageNet Classification的TOP5 error达到4.9%。
2.BN介绍
如果训练集和测试集的分布不同,即样本之间存在covariate shift,这种情况会影响训练的精度。而internal covariate shift是指数据通过一层一层网络传播的过程中,由于参数的变化,而引起激活值分布发生变化。而且如果网络非常深,每一层的激活值可能越来越分散,如果用sigmoid激活函数,越来越大的x值可能导致导数接近0,这就是梯度消失的原因,梯度消失会导致训练越来越缓慢而难以收敛。而使用Relu激活并且合适的参数初始化和较小的学习率可以改善这个现象,但是数据仍有发散的可能性。
作者提出的batch normolization,可以缓解Internal Covariate Shift,加速深度神经网络的训练速度。使用BN后可以允许使用更高的学习率,而不会有发散的风险,BN也有轻微正则化模型的效果。并且使用BN后即使是用sigmoid激活函数,也不会有梯度消失的现象。

上图就是batch normalization的公式。第一行是求minibatch的均值,第二行是求minibatch的方差,第三行就是BN的操作,为了防止方差为0而导致除数为0,增加了一个很小的。第四行增加了
和
进行缩放和偏移是为了让隐藏层之间有稍微不同的分布,也增加了非线性效果。另外BN的运算需要在激活函数之前,如果在之后,BN运算可能会抵消了激活函数的效果。
和
跟参数w一样进行梯度下降更新,而由于input的x减去均值会抵消掉bias的效果,所以我们可以不用处理bias的更新了。
如果的值是方差,
的值是均值,那么相当于没有做BN的操作。在训练的过程中
和
控制了数据集的均值和方差,使得数据与上一层的联系降低,每一层能够比较独立的训练。
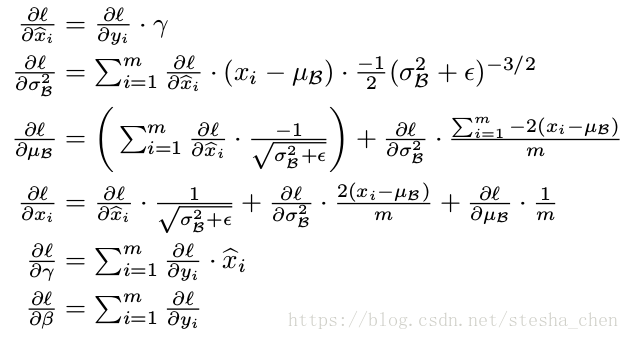
上图是作者根据链式法则计算出来的求导公式。
3.BN带来的好出
- 对每一层的输入做了类似标准化处理,能够预防梯度消失和梯度爆炸,加快训练的速度
- 减少了前面一层参数的变化对后面一层输入值的影响,每一层独立训练,有轻微正则化效果
代码简析
前面说过inception v2的改进主要是两点,第一是用了BN,第二是使用小size的filter来替代大size的filter,可以从代码中体现。
1.使用BN
BN的使用是在代码的最后一行inception_v2_arg_scope = inception_utils.inception_arg_scope中处理的。
在inception_arg_scope中对slim.conv2d方法设置了默认的参数normalizer_fn=slim.batch_norm和normalizer_params=batch_norm_params,所以当我们调用inception_v2之前只需要使用slim.arg_scope(inception_v2_arg_scope)即可对slim.conv2d设置默认的batchnorm操作。默认值设置好后,在运算中tensorflow会自动进行batch normalization的计算。论文中提到的大量公式如果依赖框架来实现网络基本上一两句话就可以搞定,这就是框架带来的便利性。
def inception_arg_scope(weight_decay=0.00004,
use_batch_norm=True,
batch_norm_decay=0.9997,
batch_norm_epsilon=0.001,
activation_fn=tf.nn.relu,
batch_norm_updates_collections=tf.GraphKeys.UPDATE_OPS):
batch_norm_params = {
# Decay for the moving averages.
'decay': batch_norm_decay,
# epsilon to prevent 0s in variance.
'epsilon': batch_norm_epsilon,
# collection containing update_ops.
'updates_collections': batch_norm_updates_collections,
# use fused batch norm if possible.
'fused': None,
}
if use_batch_norm:
normalizer_fn = slim.batch_norm
normalizer_params = batch_norm_params
else:
normalizer_fn = None
normalizer_params = {}
# Set weight_decay for weights in Conv and FC layers.
with slim.arg_scope([slim.conv2d, slim.fully_connected],
weights_regularizer=slim.l2_regularizer(weight_decay)):
with slim.arg_scope(
[slim.conv2d],
weights_initializer=slim.variance_scaling_initializer(),
activation_fn=activation_fn,
normalizer_fn=normalizer_fn,
normalizer_params=normalizer_params) as sc:
return sc2.使用小size的filter
网络结构
下图是根据代码中的实现画出来的网络结构图,跟inception V1对比可以很清晰看出来去掉了5x5的filter,替换成了2个3x3的filter,这个观点在VGG的论文中就提出过,两个3x3的卷积核可以达到5x5的卷积核的效果,而且还减少了参数,增加了非线性。
另外代码实现中用AvgPool来替代FC连接,可以大幅度减少参数量。

代码细节
1. data_format='NHWC'或者'NCHW'表示数据的格式是[number, height, width, channel]还是[number, channel, height, width],tf一般都是NHWC,像theano之类的一般是NCHW
2. 如果use_separable_conv为true,会使用slim.separable_conv2d来替代普通的slim.conv2d,separable_conv2d是mobilenet中提出的一种卷积方式,可以降低计算量。
net = slim.separable_conv2d(
inputs, depth(64), [7, 7],
depth_multiplier=depthwise_multiplier,
stride=2,
padding='SAME',
weights_initializer=trunc_normal(1.0),
scope=end_point)3. depth_multiplier是指output channel为input channel*depth_multiplier
4. tf.squeeze是删除tensor中尺寸为1的尺寸,如果指定位置就删除指定位置尺寸为1的尺寸。比如如果tensor a的shape是[1, 1, 2, 1, 3, 1, 4], 调用tf.squeeze(a)后shape成为[2, 3, 4]。如果调用tf.squeeze(a, [1, 2]),就删除第一和第二位的尺寸,shape成为[2, 1, 3, 1, 4]。代码中调用tf.squeeze是为了将logits由[1, 1, 1000]变成[1000]。
if spatial_squeeze:
logits = tf.squeeze(logits, [1, 2], name='SpatialSqueeze')小结
inception v2总的来说就是应用了BN的技术,加上用小尺寸filter替代大尺寸filter。而小尺寸filter替代大尺寸filter的部分还可以继续改进,在Rethinking the Inception Architecture for Computer Vision文中再详细解读。