一、Inception V3结构介绍
1、Inception网络结构
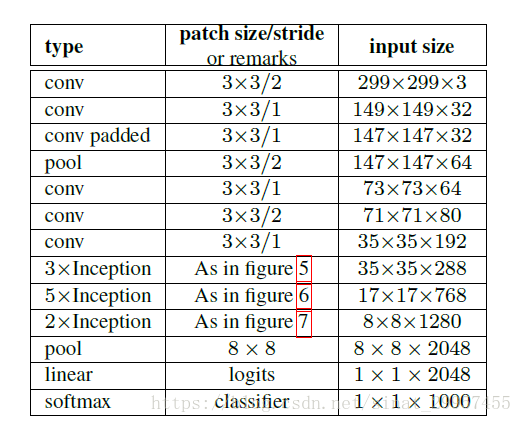
在上图中下一层的输入是上一层的输出,在Inception V3中采用下面两种结构来减少图片的尺寸
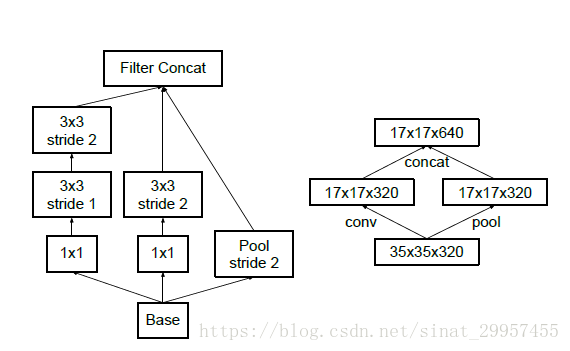
在Inception V3中,卷积没有使用padding-0来填充边界,通过将卷积的步长设置为2能够将图片的输出尺寸变为输入尺寸的一半。
2、Inception V3 model模块结构
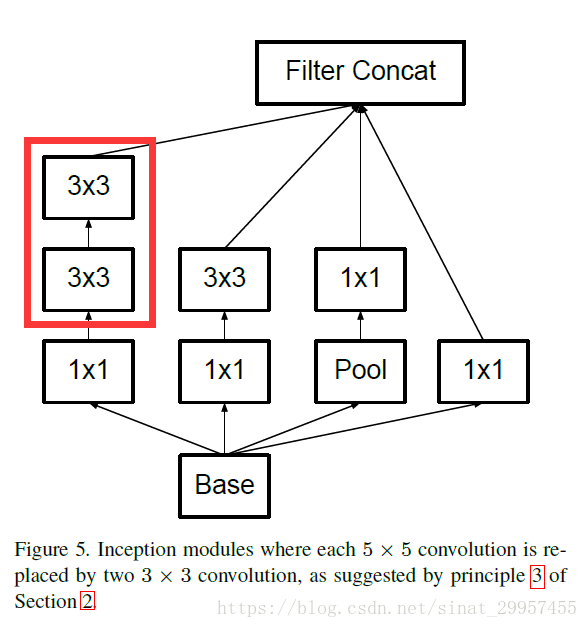
在原始的Inception Net中,上图红色框内是一个5×5的卷积,在Incpetion V3中将5×5的卷积替换成了两个3×3的卷积,上图的Inception Module是使用在一个35×35大小的图片上。
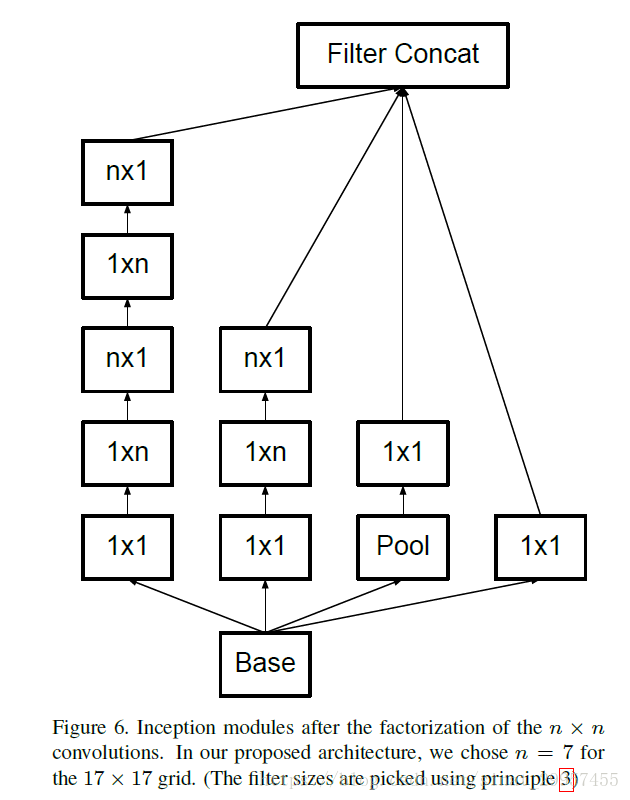
figure 6中的Inception module是使用在尺寸为17×17的图片上,而且在这个module中还是用了卷积的分解,将一个7×7的卷积拆分成了一个1×7的卷积和一个7×1的卷积,不仅能够大大节省参数降低模型的过拟合,还能比一个7×7的卷积多一个非线性的变换。

figure7中的输入是一个8×8图片,在Inception V3中没有使用全连接,而是使用平均池化来替代全连接降低模型的过拟合。
二、 tensorflow实现Inception V3
本文主要通过tensorflow的contrib.slim模块来实现Google Inception V3来减少设计Inception V3的代码量,使用contrib.slim模块便可以通过少量的代码来构建有42层深的Inception V3。
1、调用slim模块,声明一个产生截断正态分布的函数
#调用slim模块
slim = tf.contrib.slim
#定义一个产生截断正态分布的函数
trunc_normal = lambda std:tf.truncated_normal_initializer(0.0,std)2、产生默认参数
'''
定义产生默认参数的函数
'''
def inception_v3_arg_scope(weight_decay=4e-4,std=0.1,batch_norm_var_collection="moving_vars"):
batch_norm_params = {"decay":0.9997,"epsilon":0.001,"updates_collections":tf.GraphKeys.UPDATE_OPS,
"variables_collections":{"beta":None,"gamma":None,
"moving_mean":[batch_norm_var_collection],"moving_variance":[batch_norm_var_collection]}}
with slim.arg_scope([slim.conv2d,slim.fully_connected],weights_regularizer=slim.l2_regularizer(weight_decay)):
with slim.arg_scope([slim.conv2d],weights_initializer=tf.truncated_normal_initializer(stddev=std),
activation_fn=tf.nn.relu,normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params) as sc:
return sc
slim.arg_scope可以给函数的参数自动赋予某些默认值,如:with slim.arg_scope([slim.conv2d,slim.fully_connected],
weights_regularizer=slim.l2_regularizer(weight_decay)),会对[slim.conv2d,slim.fully_connected]这两个函数的参数自动赋值,将参数weights_regularizer的值默认设置为slim.l2_regularizer(weight_decay)。使用slim.arg_scope后就不需要每次都重复设置参数,只需要对修改的参数进行重新赋值。
3、定义卷积层
#保存关键节点
end_points = {}
with tf.variable_scope(scope,"InceptionV3",[inputs]):
with slim.arg_scope([slim.conv2d,slim.max_pool2d,slim.avg_pool2d],stride=1,padding="VALID"):
net = slim.conv2d(inputs,32,[3,3],stride=2,scope="Conv2d_1a_3x3")
net = slim.conv2d(net,32,[3,3],scope="Conv2d_2a_3x3")
net = slim.conv2d(net,64,[3,3],padding="SAME",scope="Conv2d_2b_3x3")
net = slim.max_pool2d(net,[3,3],stride=2,scope="MaxPool_3a_3x3")
net = slim.conv2d(net,80,[1,1],scope="Conv2d_3b_1x1")
net = slim.conv2d(net,192,[3,3],scope="Conv2d_4a_3x3")
net = slim.max_pool2d(net,[3,3],stride=2,scope="MaxPool5a_3x3")上面是Inception module前的卷积层,字典end_points是用来保存关键节点的信息,以便于后面继续使用。 通过使用slim.arg_scope函数对slim.conv2d、slim.max_pool2d和avg_pool2d这三个函数的参数设置默认值,将stride设置为1,padding设置为VALID。使用slim.conv2d来定义卷积操作,conv2d的第一个参数为输入的tensor,第二个参数为输出的通道数,第三个参数为卷积核的尺寸,第四个参数为步长stride,第五个参数为padding。在上面的卷积层中,第一个卷积的输出通道数为32,卷积核的大小为3×3,步长为2,padding参数则是使用默认的VALID。后面的几个卷积都是采用这种模式进行定义的。
在Inception V3中,主要使用了3×3的卷积核,这里主要是借鉴了VGGNet的思想。在Inception V3中还充分利用了Factorization into small convolutions的思想,利用了两个1维卷积来模拟2维卷积,如将7×7的卷积使用1×7和7×1来代替,减少参数量的同时还能增加非线性。在Inception V3中还存在不少的1×1的卷积,在Inception V3中通过使用1×1的卷积来进行低成本的跨通道对特征进行组合。除了第一层卷积步长为2,其余的卷积层步长均为1,而池化层则是采用3×3的卷积核使用步长为2的重叠最大池化,这里是借鉴了AlexNet中使用的结构。在Inception V3中,卷积层的输入是299×299×3,在经历3个步长为2的层之后,最后将输出尺寸缩小为35×35×192,图片的空间尺寸大大降低,但是输出通道增加了很多。卷积层一共包含了5个卷积,2个池化层,实现了对输入图片数据的尺寸压缩,并对图片特征进行了抽象。
4、Inception Module的定义
在Inception V3中包含了三个Inception Module,这三个Inception Module中还包含了很多个Inception Module,被称为NetWork in NetWork。这三个模块就是Inception V3的精华所在,每个Inception模块组内部的几个Inception Module结构非常相似,但是实现的细节有所不同。
a、第一个Inception Module
第一个Inception Module一共由三个小的Inception模块组成,每一个小的Inception模块又由多个分支所组成。
1)、Mixed_5b
Mixed_5b是第一个小的Inception Module,一共由四个分支,从Branch_0到Branch_3,第一个分支由64个1×1的卷积组成;第二个分支由48个1×1的卷积,连接64个5×5的卷积;第三个分支由64个1×1的卷积,连接2个有96输出通道的3×3的卷积;第四个分支为3×3的平均池化,连接32输出通道的1×1的卷积。最后,通过tf.concat将4个分支的输出合并在一起(在第三个维度上进行合并,即输出通道上合并)作为Inception module的最终输出。因为卷积的步长均,padding被设置为SAME,所以输入图片的尺寸和输出图片的尺寸不会减少,输出依然是一个35×35的图片,输出的通道数为64+64+96+32=256。
with tf.variable_scope("Mixed_5b"):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net,64,[1,1],scope="Conv2d_0a_1x1")
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net,48,[1,1],scope="Conv2d_0a_1x1")
branch_1 = slim.conv2d(branch_1,64,[5,5],scope="Conv2d_0b_5x5")
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net,64,[1,1],scope="Conv2d_0a_1x1")
branch_2 = slim.conv2d(branch_2,96,[3,3],scope="Conv2d_0b_3x3")
branch_2 = slim.conv2d(branch_2,96,[3,3],scope="Conv2d_0c_3x3")
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net,[3,3],scope="AvgPool_0a_3x3")
branch_3 = slim.conv2d(branch_3,32,[1,1],scope="Conv2d_0b_1x1")
net = tf.concat([branch_0,branch_1,branch_2,branch_3],3)2)、Mixed_5c
Mixed_5c与Mixed_5b的结构相似,唯一不同的是第四个分支,在Mixed_5c中将Mixed_5b中的第四个分支的最后输出32通道的1×1的卷积改成了64通道的1×1的卷积。相对于Mixed_5b最终Mixed_5c的输出通道数增加了32。
with tf.variable_scope("Mixed_5c"):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net,64,[1,1],scope="Conv2d_0a_1x1")
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net,48,[1,1],scope="Conv2d_0b_1x1")
branch_1 = slim.conv2d(branch_1,64,[5,5],scope="Conv_1_0c_5x5")
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net,64,[1,1],scope="Conv2d_0a_1x1")
branch_2 = slim.conv2d(branch_2,96,[3,3],scope="Conv2d_0b_3x3")
branch_2 = slim.conv2d(branch_2,96,[3,3],scope="Conv2d_0c_3x3")
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net,[3,3],scope="AvgPool_0a_3x3")
branch_3 = slim.conv2d(branch_3,64,[1,1],scope="Conv2d_0b_1x1")
net = tf.concat([branch_0,branch_1,branch_2,branch_3],3)3)、Mixed_5d
Mixed_5d与Mixed_5b组成结构完全相同,最终输出为35×35×288。
with tf.variable_scope("Mixed_5d"):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net,64,[1,1],scope="Conv2d_0a_1x1")
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net,48,[1,1],scope="Conv2d_0a_1x1")
branch_1 = slim.conv2d(branch_1,64,[5,5],scope="Conv2d_0b_5x5")
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net,64,[1,1],scope="Conv2d_0a_1x1")
branch_2 = slim.conv2d(branch_2,96,[3,3],scope="Conv2d_0b_3x3")
branch_2 = slim.conv2d(branch_2,96,[3,3],scope="Conv2d_0c_3x3")
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net,[3,3],scope="AvgPool_0a_3x3")
branch_3 = slim.conv2d(branch_3,64,[1,1],scope="Conv2d_0b_1x1")
net = tf.concat([branch_0,branch_1,branch_2,branch_3],3)b、第二个Inception module
第二个Inception module是三个module中最大的一个,包含了5个Inception Module。在这个Inception module中会将输入图片进行压缩,由原来的35×35缩小为17×17,同时通道数会增加,由288增加到768。
1)、Mixed_6a
Mixed_6a是第一个Inception module,它一共包含了3个分支。第一个分支是一个384输出通道的3×3的卷积,步长为2,padding为VALID,所以输出的图片尺寸会被缩小,由原来的35×35缩小为17×17;第二个分支由三层组成,第一层是一个64通道的1×1的卷积和两个96通道的3×3的卷积。最后一层最大池化层的步长为2,padding为VALID,所以图片尺寸也会被压缩。
with tf.variable_scope("Mixed_6a"):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net,384,[3,3],stride=2,padding="VALID",scope="Conv2d_1a_1x1")
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net,64,[1,1],scope="Conv2d_0a_1x1")
branch_1 = slim.conv2d(branch_1,96,[3,3],scope="Conv2d_0b_3x3")
branch_1 = slim.conv2d(branch_1,96,[3,3],stride=2,padding="VALID",scope="Conv2d_1a_1x1")
with tf.variable_scope("Branch_2"):
branch_2 = slim.max_pool2d(net,[3,3],stride=2,padding="VALID",scope="MaxPool_1a_3x3")
net = tf.concat([branch_0,branch_1,branch_2],3)2)、Mixed_6b
Mixed_6b由4个分支所组成,第一个分支是一个简单的192输出通道的1×1的卷积;第二个分支由三层卷积组成,第一层是128输出通道的1×1的卷积,第二层是一个128通道的1×7的卷积,第三层是一个192通道的7×1的卷积。通过串联1×7的卷积和7×1的卷积来替代7×7的卷积,不仅可以减少参数减轻过拟合,同时还增加了一层非线性特征变换;第三个分支由五个卷积层组成,分别是128通道的1×1的卷积,128通道的7×1的卷积,128通道的1×7的卷积,128通道的7×1卷积和192通道的1×7卷积;第四个分支是一个3×3的平均池化层,再连接192通道的1×1的卷积。
with tf.variable_scope("Mixed_6b"):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net,192,[1,1],scope="Conv2d_0a_1x1")
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net,128,[1,1],scope="Conv2d_0a_1x1")
branch_1 = slim.conv2d(branch_1,128,[1,7],scope="Conv2d_0b_1x7")
branch_1 = slim.conv2d(branch_1,192,[7,1],scope="Conv2d_0c_7x1")
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net,128,[1,1],scope="Conv2d_0a_1x1")
branch_2 = slim.conv2d(branch_2,128,[7,1],scope="Conv2d_0b_7x1")
branch_2 = slim.conv2d(branch_2,128,[1,7],scope="Conv2d_0c_1x7")
branch_2 = slim.conv2d(branch_2,128,[7,1],scope="Conv2d_0d_7x1")
branch_2 = slim.conv2d(branch_2,192,[1,7],scope="Conv2d_0e_1x7")
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net,[3,3],scope="AvgPool_0a_3x3")
branch_3 = slim.conv2d(branch_3,192,[1,1],scope="Conv2d_0b_1x1")
net = tf.concat([branch_0,branch_1,branch_2,branch_3],3)3)、Mixed_6c到Mixed6_e与Mixed_6b的结构都差不多,只是在卷积核的数量上稍有不同,这里就省略了,具体的请看最下面的源码链接。
c、第三个Inception module
第三个Inception module包含了3个Inception module,最后两个Inception module的结构非常相似。
1)、Mixed_7a
with tf.variable_scope("Mixed_7a"):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net,192,[1,1],scope="Conv2d_0a_1x1")
branch_0 = slim.conv2d(branch_0,320,[3,3],stride=2,padding="VALID",scope="Conv2d_1a_3x3")
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net,192,[1,1],scope="Conv2d_0a_1x1")
branch_1 = slim.conv2d(branch_1,192,[1,7],scope="Conv2d_0b_1x7")
branch_1 = slim.conv2d(branch_1,192,[7,1],scope="Conv2d_0b_7x1")
branch_1 = slim.conv2d(branch_1,192,[3,3],stride=2,padding="VALID",scope="Conv2d_1a_3x3")
with tf.variable_scope("Branch_2"):
branch_2 = slim.max_pool2d(net,[3,3],stride=2,padding="VALID",scope="MaxPool_1a_3x3")
net = tf.concat([branch_0,branch_1,branch_2],3)2)、Mixed_7b
with tf.variable_scope("Mixed_7b"):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net,320,[1,1],scope="Conv2d_0a_1x1")
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net,384,[1,1],scope="Conv2d_0a_1x1")
branch_1 = tf.concat([
slim.conv2d(branch_1,384,[1,3],scope="Conv2d_0b_1x3"),
slim.conv2d(branch_1,384,[3,1],scope="Conv2d_0b_3x1")
],3)
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net,448,[1,1],scope="Conv2d_0a_1x1")
branch_2 = slim.conv2d(branch_2,384,[3,3],scope="Conv2d_0b_3x3")
branch_2 = tf.concat([
slim.conv2d(branch_2,384,[1,3],scope="Conv2d_0c_1x3"),
slim.conv2d(branch_2,384,[3,1],scope="Conv2d_0d_3x1")
],3)
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net,[3,3],scope="AvgPool_0a_3x3")
branch_3 = slim.conv2d(branch_3,192,[1,1],scope="Conv2d_0b_1x1")
net = tf.concat([branch_0,branch_1,branch_2,branch_3],3)3)、Mixed_7c
with tf.variable_scope("Mixed_7c"):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net,320,[1,1],scope="Conv2d_0a_1x1")
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net,384,[1,1],scope="Conv2d_0a_1x1")
branch_1 = tf.concat([
slim.conv2d(branch_1,384,[1,3],scope="Conv2d_0b_1x3"),
slim.conv2d(branch_1,384,[3,1],scope="Conv2d_0c_3x1")
],3)
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net,448,[1,1],scope="Conv2d_0a_1x1")
branch_2 = slim.conv2d(branch_2,384,[3,3],scope="Conv2d_0b_3x3")
branch_2 = tf.concat([
slim.conv2d(branch_2,384,[1,3],scope="Conv2d_0c_1x3"),
slim.conv2d(branch_2,384,[3,1],scope="Conv2d_0d_3x1")
],3)
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net,[3,3],scope="AvgPool_0a_3x3")
branch_3 = slim.conv2d(branch_3,192,[1,1],scope="Conv2d_0b_1x1")
net = tf.concat([branch_0,branch_1,branch_2,branch_3],3)三、性能测试
源码链接if __name__ == "__main__":
batch_size = 32
height,width = 299,299
inputs = tf.random_uniform((batch_size,height,width,3))
with slim.arg_scope(inception_v3_arg_scope()):
logits,end_points = inception_v3(inputs,is_training=False)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
num_batches = 10
time_tensorflow_run(sess,logits,"Forward",num_batches)类似于VGGNet使用随机产生的图片来测试Inception V3的性能。
