原论文:《Rethinking the Inception Architecture for Computer Vision》
原论文学习笔记:https://blog.csdn.net/COINVK/article/details/129061046;
原论文在第7节首次提出Label Smoothing概念;
Label Smoothing:一种机制/策略,通过估计训练时的label-dropout的边缘化效应实现对分类器的正则化;
对于每个训练数据 x x x,模型计算对于标签 k k k的概率(就是模型最后的softmax归一化):
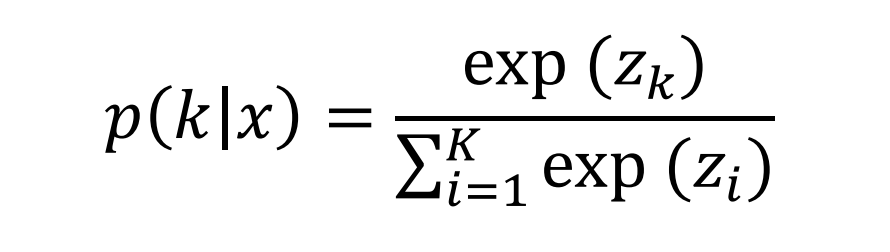
z i z_i zi:logits;
数据的真实标签记为: q ( k ∣ x ) q(k|x) q(k∣x);
softmax归一化之后,概率和加起来为1,即:

为了简洁起见,省略 p p p和 q q q对训练数据 x x x的依赖性,将 p ( k ∣ x ) p(k|x) p(k∣x)写作 p ( k ) p(k) p(k),将 q ( k ∣ x ) q(k|x) q(k∣x)写作 q ( k ) q(k) q(k);
定义交叉熵损失函数(Cross-entropy loss):
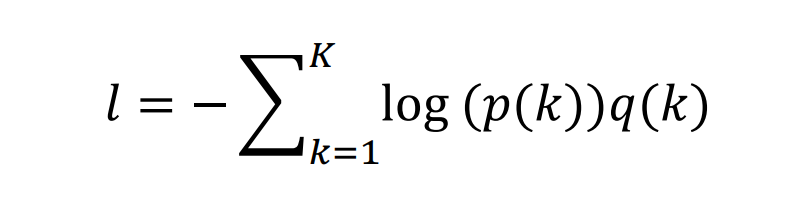
交叉熵损失由极大似然估计推导:最小化上述损失函数相当于最大化标签的预期对数似然性(说人话:最大化每个数据被正确分类的概率);
- 取对数可以保证单调性,把乘法变成加法;
- 取符号把最大化变成最小化;
交叉熵损失相对于logits z k z_k zk是可微的,因此可以用于深度模型的梯度训练。
梯度的一个简单形式,其范围在−1和1之间:

考虑用one-hot独热向量编码时,只有正确的类别对应的标签为1(记为y),其他均为0,
比如:三分类问题,
one-hot编码对应正确答案为:(0, 1, 0);
softmax最终预测结果为:(0.4, 0.5, 0.1);
交叉熵损失: l = − ( 0 ∗ l o g ( 0.4 ) + 1 ∗ l o g ( 0.5 ) + 0 ∗ l o g ( 0.1 ) ) ≈ 0.3 l = -(0 * log(0.4) +1 * log(0.5) + 0 * log(0.1)) ≈0.3 l=−(0∗log(0.4)+1∗log(0.5)+0∗log(0.1))≈0.3;
softmax最终预测结果为:(0.1, 0.8, 0.1);
交叉熵损失: l = − ( 0 ∗ l o g ( 0.1 ) + 1 ∗ l o g ( 0.8 ) + 0 ∗ l o g ( 0.1 ) ) ≈ 0.1 l = -(0 * log(0.1) +1 * log(0.8) + 0 * log(0.1)) ≈0.1 l=−(0∗log(0.1)+1∗log(0.8)+0∗log(0.1))≈0.1;
上述例子说明:正确答案对应的概率越大,交叉熵损失函数就越小;
网络希望正确类别对应的logits无限增大,一直增大的正无穷,才能保证损失函数 l l l最小;

这会导致两个问题:
- 过拟合,模型无法泛化;
- 鼓励模型过于自信,不计代价的增大某一类的logits;
基于以上讨论提出label-smoothing regularization(缩写为LSR);
考虑在损失函数中加入一个平滑参数 ε ε ε,将训练数据的标签分布变为:
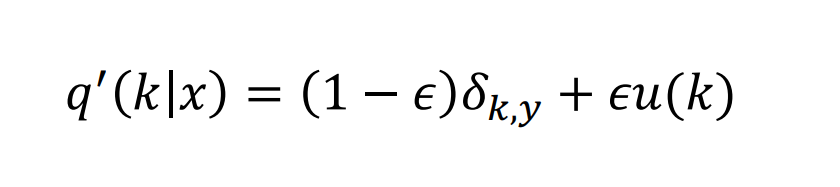
δ k , y δ_{k,y} δk,y:原始真实标签,当y = k时, δ k , y = 1 δ_{k,y}=1 δk,y=1,other, δ k , y = 0 δ_{k,y}=0 δk,y=0;
u ( k ) u(k) u(k):一种分布函数,根据实验,建议选择均匀分布函数,即 u ( k ) = 1 / K u(k)=1/K u(k)=1/K,(K为分类个数);
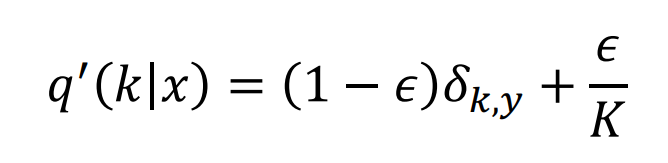
真实的标签变为:
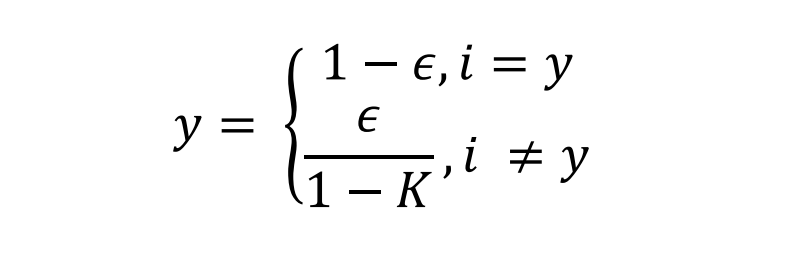
举例:
三分类问题,原始标签为 ( 1 , 0 , 0 , 0 ) (1, 0, 0, 0) (1,0,0,0)=> one-hot编码;
则 K = 4 K = 4 K=4,令 ε = 0.1 ε=0.1 ε=0.1,代入上式,
i = y时,y = 1-0.1 = 0.9;
i != y 时,y = 0.1 / 3 = 0.03333;
则新标签变为:
( 0.9 , 0.03333 , 0.03333 , 0.03333 ) (0.9, 0.03333, 0.03333, 0.03333) (0.9,0.03333,0.03333,0.03333)
交叉熵损失函数+Label Smoothing:
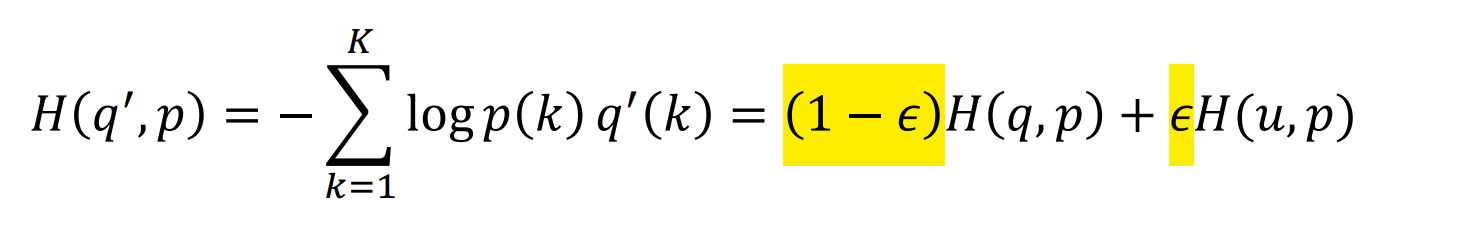
相当于,用 H ( q , p ) H(q,p) H(q,p)和 H ( u , p ) H(u,p) H(u,p)替换了之前的替换单个交叉熵损失 H ( q , p ) H(q,p) H(q,p);
第二项 H ( u , p ) H(u,p) H(u,p)以 ε 1 − ε \frac{ε}{1-ε} 1−εε的相对权重惩罚了预测的标签分布p与先前的u的偏差;

H ( u ) H(u) H(u)是固定的;
H ( u , p ) H(u,p) H(u,p)是预测分布 p p p与均匀分布程度的度量;
Label Smoothing 用 pytorch实现:
import torch
def smooth_one_hot(true_labels: torch.Tensor, classes: int, smoothing=0.0):
"""
if smoothing == 0, it's one-hot method
if 0 < smoothing < 1, it's smooth method
"""
assert 0 <= smoothing < 1
confidence = 1.0 - smoothing
label_shape = torch.Size((true_labels.size(0), classes)) # torch.Size([2, 5])
with torch.no_grad():
true_dist = torch.empty(size=label_shape, device=true_labels.device) # 空的,没有初始化
true_dist.fill_(smoothing / (classes - 1))
_, index = torch.max(true_labels, 1)
true_dist.scatter_(1, torch.LongTensor(index.unsqueeze(1)), confidence) # 必须要torch.LongTensor()
return true_dist
true_labels = torch.zeros(2, 5)
true_labels[0, 1], true_labels[1, 3] = 1, 1
print('标签平滑前:\n', true_labels)
true_dist = smooth_one_hot(true_labels, classes=5, smoothing=0.1)
print('标签平滑后:\n', true_dist)
'''
Loss = CrossEntropyLoss(NonSparse=True, ...)
. . .
data = ...
labels = ...
outputs = model(data)
smooth_label = smooth_one_hot(labels, ...)
loss = (outputs, smooth_label)
...
'''