由逻辑回归的基本原理,我们将客户违约的概率表示为p,则正常的概率为1-p。因此,可以得到:
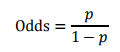
此时,客户违约的概率p可表示为:
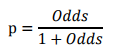
评分卡设定的分值刻度可以通过将分值表示为比率对数的线性表达式来定义,即可表示为下式:
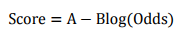
其中,A和B是常数。式中的负号可以使得违约概率越低,得分越高。通常情况下,这是分值的理想变动方向,即高分值代表低风险,低分值代表高风险。
逻辑回归模型计算比率如下所示:
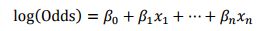
其中,用建模参数拟合模型可以得到模型参数
式中的常数A、B的值可以通过将两个已知或假设的分值带入计算得到。通常情况下,需要设定两个假设:
(1)给某个特定的比率设定特定的预期分值;
(2)确定比率翻番的分数(PDO)
根据以上的分析,我们首先假设比率为x的特定点的分值为P。则比率为2x的点的分值应该为P+PDO。代入式中,可以得到如下两个等式:
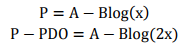
假设 设定评分卡刻度使得比率为{1:20}(违约正常比)时的分值为50分,PDO为10分,代入式中求得:B=14.43,A=6.78
则分值的计算公式可表示为:
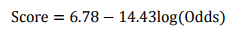
评分卡刻度参数A和B确定以后,就可以计算比率和违约概率,以及对应的分值了。通常将常数A称为补偿,常数B称为刻度。
则评分卡的分值可表达为:
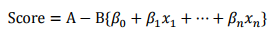
式中:变量
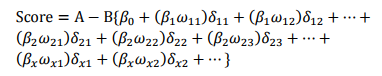
式中
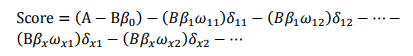
此式即为最终评分卡公式。如果
表3.20表明,变量
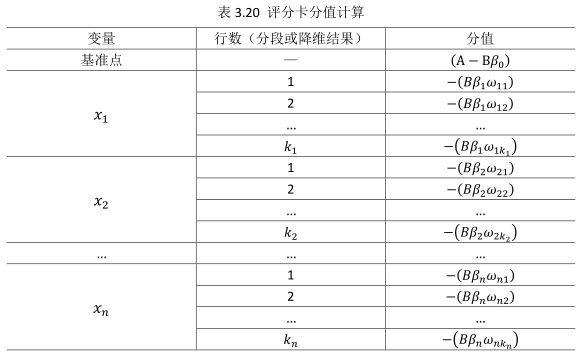
(1)刻度因子B;
(2)逻辑回归方程的参数
(3)该行的WOE值,
综上,我们详细讲述了模型开发及生成标准评分卡各步骤的处理结果,自动生成标准评分卡的R完整代码:
library(klaR)
library(InformationValue)
data(GermanCredit)
train_kfold<-sample(nrow(GermanCredit),800,replace = F)
train_kfolddata<-GermanCredit[train_kfold,] #提取样本数据集
test_kfolddata<-GermanCredit[-train_kfold,] #提取测试数据集
credit_risk<-ifelse(train_kfolddata[,"credit_risk"]=="good",0,1)
#将违约样本用“1”表示,正常样本用“0”表示。
tmp<-train_kfolddata[,-21]
data<-cbind(tmp,credit_risk)
quant_vars<-c("duration","amount","installment_rate","present_residence","age",
"number_credits","people_liable","credit_risk")
#获取定量指标
quant_GermanCredit<-data[,quant_vars] #提取定量指标
#逐步回归法,获取自变量中对违约状态影响最显著的指标
base.mod<-lm(credit_risk~1,data = quant_GermanCredit)
#获取线性回归模型的截距
all.mod<-lm(credit_risk~.,data = quant_GermanCredit)
#获取完整的线性回归模型
stepMod<-step(base.mod,scope = list(lower=base.mod,upper=all.mod),
direction = "both",trace = 0,steps = 1000)
#采用双向逐步回归法,筛选变量
shortlistedVars<-names(unlist(stepMod[[1]]))
#获取逐步回归得到的变量列表
shortlistedVars<-shortlistedVars[!shortlistedVars %in%"(Intercept)"]
#删除逐步回归的截距
print(shortlistedVars)
#输出逐步回归后得到的变量
quant_model_vars<-c("duration","amount","installment_rate","age")
#完成定量入模指标
#提取数据集中全部的定性指标
factor_vars<-c("status","credit_history","purpose","savings","employment_duration",
"personal_status_sex","other_debtors","property",
"other_installment_plans","housing","job","telephone","foreign_worker")
#获取所有名义变量
all_iv<-data.frame(VARS=factor_vars,IV=numeric(length(factor_vars)),
STRENGTH=character(length(factor_vars)),stringsAsFactors = F)
#初始化待输出的数据框
for(factor_var in factor_vars)
{
all_iv[all_iv$VARS==factor_var,"IV"]<-InformationValue::IV(X=
data[,factor_var],Y=data$credit_risk)
#计算每个指标的IV值
all_iv[all_iv$VARS==factor_var,"STRENGTH"]<-attr(InformationValue::IV(X=
data[,factor_var],Y=data$credit_risk),"howgood")
#提取每个IV指标的描述
}
all_iv<-all_iv[order(-all_iv$IV),] #排序IV
qual_model_vars<-subset(all_iv,STRENGTH=="Highly Predictive")[1:5,]
qual_model_vars<-c("status","credit_history","savings","purpose","property")
#连续变量分段和离散变量降维
#1.变量duration
library(smbinning)
result<-smbinning(df=data,y="credit_risk",x="duration",p=0.05)
result$ivtable
duration_Cutpoint<-c()
duration_WoE<-c()
duration<-data[,"duration"]
for(i in 1:length(duration))
{
if(duration[i]<=8)
{
duration_Cutpoint[i]<-"<= 8"
duration_WoE[i]<--1.5670
}
if(duration[i]<=33&duration[i]>8)
{
duration_Cutpoint[i]<-"<= 33"
duration_WoE[i]<--0.0924
}
if(duration[i]> 33)
{
duration_Cutpoint[i]<-"> 33"
duration_WoE[i]<-0.7863
}
}
#2.变量amount
result<-smbinning(df=data,y="credit_risk",x="amount",p=0.05)
result$ivtable
amount_Cutpoint<-c()
amount_WoE<-c()
amount<-data[,"amount"]
for(i in 1:length(amount))
{
if(amount[i]<= 3913)
{
amount_Cutpoint[i]<-"<= 3913"
amount_WoE[i]<--0.2536
}
if(amount[i]<= 9283&amount[i]> 3913)
{
amount_Cutpoint[i]<-"<= 9283"
amount_WoE[i]<-0.4477
}
if(amount[i]> 9283)
{
amount_Cutpoint[i]<-"> 9283"
amount_WoE[i]<-1.3109
}
}
#3.变量age
result<-smbinning(df=data,y="credit_risk",x="age",p=0.05)
result$ivtable
age_Cutpoint<-c()
age_WoE<-c()
age<-data[,"age"]
for(i in 1:length(age))
{
if(age[i]<= 34)
{
age_Cutpoint[i]<-"<= 34"
age_WoE[i]<-0.2279
}
if(age[i] > 34)
{
age_Cutpoint[i]<-" > 34"
age_WoE[i]<--0.3059
}
}
#4.变量installment_rate等距分段
install_data<-data[,c("installment_rate","credit_risk")]
tb1<-table(install_data)
total<-list()
for(i in 1:nrow(tb1))
{
total[i]<-sum(tb1[i,])
}
t.tb1<-cbind(tb1,total)
goodrate<-as.numeric(t.tb1[,"0"])/as.numeric(t.tb1[,"total"])
badrate<-as.numeric(t.tb1[,"1"])/as.numeric(t.tb1[,"total"])
gb.tbl<-cbind(t.tb1,goodrate,badrate)
Odds<-goodrate/badrate
LnOdds<-log(Odds)
tt.tb1<-cbind(gb.tbl,Odds,LnOdds)
WoE<-log((as.numeric(tt.tb1[,"0"])/700)/(as.numeric(tt.tb1[,"1"])/300))
all.tb1<-cbind(tt.tb1,WoE)
all.tb1
installment_rate_Cutpoint<-c()
installment_rate_WoE<-c()
installment_rate<-data[,"installment_rate"]
for(i in 1:length(installment_rate))
{
if(installment_rate[i]==1)
{
installment_rate_Cutpoint[i]<-"=1"
installment_rate_WoE[i]<-0.06252036
}
if(installment_rate[i]==2)
{
installment_rate_Cutpoint[i]<-"=2"
installment_rate_WoE[i]<-0.1459539
}
if(installment_rate[i]==3)
{
installment_rate_Cutpoint[i]<-"=3"
installment_rate_WoE[i]<--0.03937517
}
if(installment_rate[i]==4)
{
installment_rate_Cutpoint[i]<-"=4"
installment_rate_WoE[i]<--0.1657562
}
}
#定性指标的降维和WoE
discrete_data<-data[,c("status","credit_history","savings","purpose",
"property","credit_risk")]
summary(discrete_data)
#对purpose指标进行降维
x<-discrete_data[,c("purpose","credit_risk")]
d<-as.matrix(x)
for(i in 1:nrow(d))
{
#合并car(new)、car(used)
if(as.character(d[i,"purpose"])=="car (new)")
{
d[i,"purpose"]<-as.character("car(new/used)")
}
if(as.character(d[i,"purpose"])=="car (used)")
{
d[i,"purpose"]<-as.character("car(new/used)")
}
#合并radio/television、furniture/equipment
if(as.character(d[i,"purpose"])=="radio/television")
{
d[i,"purpose"]<-as.character("radio/television/furniture/equipment")
}
if(as.character(d[i,"purpose"])=="furniture/equipment")
{
d[i,"purpose"]<-as.character("radio/television/furniture/equipment")
}
#合并others、repairs、business
if(as.character(d[i,"purpose"])=="others")
{
d[i,"purpose"]<-as.character("others/repairs/business")
}
if(as.character(d[i,"purpose"])=="repairs")
{
d[i,"purpose"]<-as.character("others/repairs/business")
}
if(as.character(d[i,"purpose"])=="business")
{
d[i,"purpose"]<-as.character("others/repairs/business")
}
#合并retraining、education
if(as.character(d[i,"purpose"])=="retraining")
{
d[i,"purpose"]<-as.character("retraining/education")
}
if(as.character(d[i,"purpose"])=="education")
{
d[i,"purpose"]<-as.character("retraining/education")
}
}
new_data<-cbind(discrete_data[,c(-4,-6)],d)
#替换原数据集中的“purpose”指标的值
woemodel<-woe(credit_risk~.,data = new_data,zeroadj=0.5,applyontrain=TRUE)
woemodel$woe
#1.status
status<-as.matrix(new_data[,"status"])
colnames(status)<-"status"
status_WoE<-c()
for(i in 1:length(status))
{
if(status[i]=="... < 100 DM")
{
status_WoE[i]<--0.8671300
}
if(status[i]=="0 <= ... < 200 DM")
{
status_WoE[i]<--0.4240681
}
if(status[i]=="... >= 200 DM / salary for at least 1 year")
{
status_WoE[i]<-0.4129033
}
if(status[i]=="no checking account")
{
status_WoE[i]<-1.2237524
}
}
#2.credit_history
credit_history<-as.matrix(new_data[,"credit_history"])
colnames(credit_history)<-"credit_history"
credit_history_WoE<-c()
for(i in 1:length(credit_history))
{
if(credit_history[i]=="no credits taken/all credits paid back duly")
{
credit_history_WoE[i]<--1.53771824
}
if(credit_history[i]=="all credits at this bank paid back duly")
{
credit_history_WoE[i]<--1.00079000
}
if(credit_history[i]=="existing credits paid back duly till now")
{
credit_history_WoE[i]<--0.09646414
}
if(credit_history[i]=="delay in paying off in the past")
{
credit_history_WoE[i]<--0.01996074
}
if(credit_history[i]=="critical account/other credits existing")
{
credit_history_WoE[i]<-0.77276102
}
}
#3.savings
savings<-as.matrix(new_data[,"savings"])
colnames(savings)<-"savings"
savings_WoE<-c()
for(i in 1:length(savings))
{
if(savings[i]=="... < 100 DM")
{
savings_WoE[i]<--0.3051490
}
if(savings[i]=="100 <= ... < 500 DM")
{
savings_WoE[i]<--0.2267733
}
if(savings[i]=="500 <= ... < 1000 DM")
{
savings_WoE[i]<-0.8340112
}
if(savings[i]=="... >= 1000 DM")
{
savings_WoE[i]<-1.1739617
}
if(savings[i]=="unknown/no savings account")
{
savings_WoE[i]<-0.7938144
}
}
#4.property
property<-as.matrix(new_data[,"property"])
colnames(property)<-"property"
property_WoE<-c()
for(i in 1:length(property))
{
if(property[i]=="real estate")
{
property_WoE[i]<-0.49346566
}
if(property[i]=="building society savings agreement/life insurance")
{
property_WoE[i]<--0.16507975
}
if(property[i]=="car or other")
{
property_WoE[i]<-0.08054425
}
if(property[i]=="unknown/no property")
{
property_WoE[i]<--0.65586969
}
}
#5.purpose
purpose<-as.matrix(new_data[,"purpose"])
colnames(purpose)<-"purpose"
purpose_WoE<-c()
for(i in 1:length(purpose))
{
if(purpose[i]=="car(new/used)")
{
purpose_WoE[i]<--0.11260594
}
if(purpose[i]=="domestic appliances")
{
purpose_WoE[i]<-0.53602528
}
if(purpose[i]=="others/repairs/business")
{
purpose_WoE[i]<--0.09146793
}
if(purpose[i]=="radio/television/furniture/equipment")
{
purpose_WoE[i]<--0.23035114
}
if(purpose[i]=="retraining/education")
{
purpose_WoE[i]<--0.43547619
}
}
#入模定量和定性指标
model_data<-cbind(data[,quant_model_vars],data[,qual_model_vars])
#入模定量和定性指标的WOE
credit_risk<-as.matrix(data[,"credit_risk"])
colnames(credit_risk)<-"credit_risk"
model_data_WOE<-as.data.frame(cbind(duration_WoE,amount_WoE,age_WoE,
installment_rate_WoE,status_WoE,credit_history_WoE,
savings_WoE,property_WoE,purpose_WoE,credit_risk))
#入模定量和定性指标“分段”
model_data_Cutpoint<-cbind(duration_Cutpoint,amount_Cutpoint,age_Cutpoint,
installment_rate_Cutpoint,status,credit_history,
savings,property,purpose)
#逻辑回归
m<-glm(credit_risk~.,data=model_data_WOE,family = binomial())
alpha_beta<-function(basepoints,baseodds,pdo)
{
beta<-pdo/log(2)
alpha<-basepoints+beta*log(baseodds)
return(list(alpha=alpha,beta=beta))
}
coefficients<-m$coefficients
#通过指定特定比率(1/20)的特定分值(50)和比率翻番的分数(10),来计算评分卡的系数alpha和beta
x<-alpha_beta(50,0.05,10)
#计算基础分值
basepoint<-round(x$alpha-x$beta*coefficients[1])
#1.duration_score
duration_score<-round(as.matrix(-(model_data_WOE[,"duration_WoE"]*
coefficients["duration_WoE"]*x$beta)))
colnames(duration_score)<-"duration_score"
#2.amount_score
amount_score<-round(as.matrix(-(model_data_WOE[,"amount_WoE"]*
coefficients["amount_WoE"]*x$beta)))
colnames(amount_score)<-"amount_score"
#3.age_score
age_score<-round(as.matrix(-(model_data_WOE[,"age_WoE"]*
coefficients["age_WoE"]*x$beta)))
colnames(age_score)<-"age_score"
#4.installment_rate_score
installment_rate_score<-round(as.matrix(-(model_data_WOE[,"installment_rate_WoE"]*
coefficients["installment_rate_WoE"]*x$beta)))
colnames(installment_rate_score)<-"installment_rate_score"
#5.status_score
status_score<-round(as.matrix(-(model_data_WOE[,"status_WoE"]*
coefficients["status_WoE"]*x$beta)))
colnames(status_score)<-"status_score"
#6.credit_history_score
credit_history_score<-round(as.matrix(-(model_data_WOE[,"credit_history_WoE"]*
coefficients["credit_history_WoE"]*x$beta)))
colnames(credit_history_score)<-"credit_history_score"
#7.savings_score
savings_score<-round(as.matrix(-(model_data_WOE[,"savings_WoE"]*
coefficients["savings_WoE"]*x$beta)))
colnames(savings_score)<-"savings_score"
#8.property_score
property_score<-round(as.matrix(-(model_data_WOE[,"property_WoE"]*
coefficients["property_WoE"]*x$beta)))
colnames(property_score)<-"property_score"
#9.purpose_score
purpose_score<-round(as.matrix(-(model_data_WOE[,"purpose_WoE"]*
coefficients["purpose_WoE"]*x$beta)))
colnames(purpose_score)<-"purpose_score"
#输出最终的CSV格式的打分卡
#1.基础分值
r1<-c("","basepoint",20)
m1<-matrix(r1,nrow = 1)
colnames(m1)<-c("Basepoint","Basepoint","Score")
#2.duration的分值
duration_scoreCard<-cbind(as.matrix(c("Duration","",""),ncol=1),
unique(cbind(duration_Cutpoint,duration_score)))
#View(duration_scoreCard)
#3.amount的分值
amount_scoreCard<-cbind(as.matrix(c("Amount","",""),ncol=1),
unique(cbind(amount_Cutpoint,amount_score)))
#View(amount_scoreCard)
#4.age的分值
age_scoreCard<-cbind(as.matrix(c("Age",""),ncol=1),
unique(cbind(age_Cutpoint,age_score)))
#View(age_scoreCard)
#5.installment_rate的分值
installment_rate_scoreCard<-cbind(as.matrix(c("Installment_rate","","",""),ncol=1),
unique(cbind(installment_rate_Cutpoint,installment_rate_score)))
#View(installment_rate_scoreCard)
#6.status的分值
status_scoreCard<-cbind(as.matrix(c("Status","","",""),ncol=1),
unique(cbind(status,status_score)))
#View(status_scoreCard)
#7.credit_history的分值
credit_history_scoreCard<-cbind(as.matrix(c("Credit_history","","","",""),ncol=1),
unique(cbind(credit_history,credit_history_score)))
#View(credit_history_scoreCard)
#8.savings的分值
savings_scoreCard<-cbind(as.matrix(c("Savings","","","",""),ncol=1),
unique(cbind(savings,savings_score)))
#View(savings_scoreCard)
#9.property的分值
property_scoreCard<-cbind(as.matrix(c("Property","","",""),ncol=1),
unique(cbind(property,property_score)))
#View(property_scoreCard)
#10.purpose的分值
purpose_scoreCard<-cbind(as.matrix(c("Purpose","","","",""),ncol=1),
unique(cbind(purpose,purpose_score)))
#View(purpose_scoreCard)
scoreCard_CSV<-rbind(m1,duration_scoreCard,amount_scoreCard,age_scoreCard,
installment_rate_scoreCard,status_scoreCard,credit_history_scoreCard,
savings_scoreCard,property_scoreCard,purpose_scoreCard)
#将标准评分卡输出到项目文件中,且命名为ScoreCard.CSV,调整格式即可得到标准评分卡
write.csv(scoreCard_CSV,"C:/Users/ZL/Desktop/creditcard_model/ScoreCard.CSV")需要特别说明的是,上述开发的信用风险评级模型只包含定量和定性两部分,在实际的使用中还要充分考虑到信用风险的特定,增加综合调整部分,以应对可能对客户信用影响较大的突发事件,如客户被刑事起诉、遭遇重大疾病等。完整的信用风险标准评分卡模型,如表3.21所示:
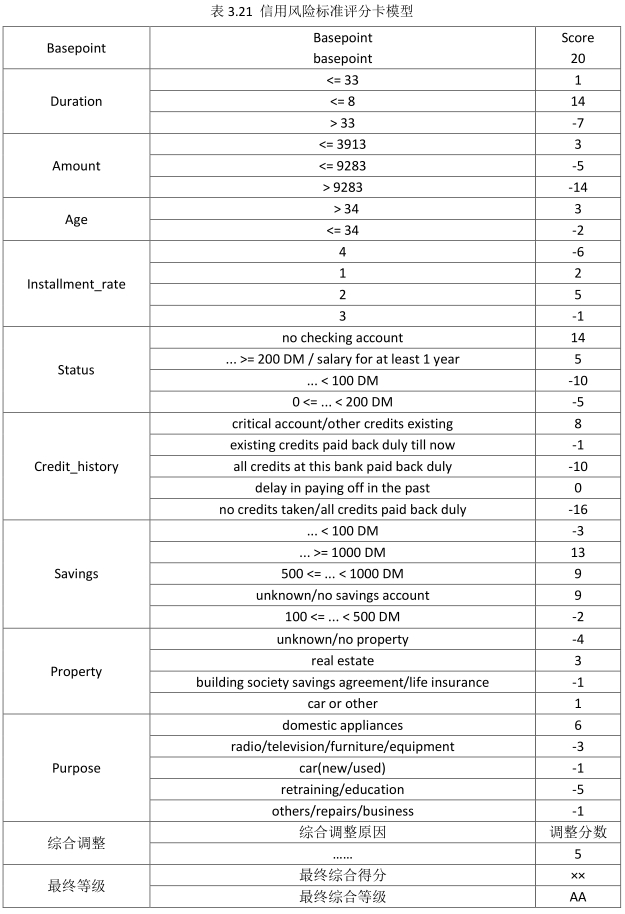
使用小样本开发信用风险评级模型时,通常采用交叉验证(如五折交叉验证)的方法以提高模型的稳定性。由于上述代码采用的是随机抽样,每次抽取样本总体的80%作为样本集,来进行模型开发,剩余样本总体的20%用作模型测试。模型开发过程中,只需要运行上述代码4次,并对得到的标准评分卡、模型中每项的分值取平均值,即可得到最终的标准评分卡模型。