版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/luyaran/article/details/82785640
在随机森林方法中,创建了大量的决策树,其中,每个观察结果都被送入每个决策树,并且每个观察结果最常用作最终输出。
之后对所有决策树进行新的观察,并对每个分类模型进行多数投票。
对于在构建树时未使用的情况进行错误估计,被称为OOB(Out-of-bag)错误估计,以百分比表示。
在R中的软件包“randomForest”用于创建随机森林,语法如下:
randomForest(formula, data)参数描述如下:
- formula - 是描述预测变量和响应变量的公式。
- data - 是使用的数据集的名称。
我们可以使用名为readingSkills的R内置数据集来创建一个决策树,前提就是我们知道变量:"age","shoesize","score"以及"nativeSpeaker"表示该人员是否为讲母语的人,那么它描述某个人员的阅读技能的得分,样本数据如下:
# Load the party package. It will automatically load other required packages.
library(party)
# Print some records from data set readingSkills.
print(head(readingSkills))
输出结果为:
nativeSpeaker age shoeSize score
1 yes 5 24.83189 32.29385
2 yes 6 25.95238 36.63105
3 no 11 30.42170 49.60593
4 yes 7 28.66450 40.28456
5 yes 11 31.88207 55.46085
6 yes 10 30.07843 52.83124接下来,我们就要使用randomForest()函数来创建决策树并查看它生成的图形,如下:
setwd("D:/r_file")
# Load the party package. It will automatically load other required packages.
library("party")
library("randomForest")
# Create the forest.
output.forest <- randomForest(nativeSpeaker ~ age + shoeSize + score,
data = readingSkills)
# View the forest results.
print(output.forest)
# Importance of each predictor.
print(importance(output.forest,type = 2))输出结果如下:
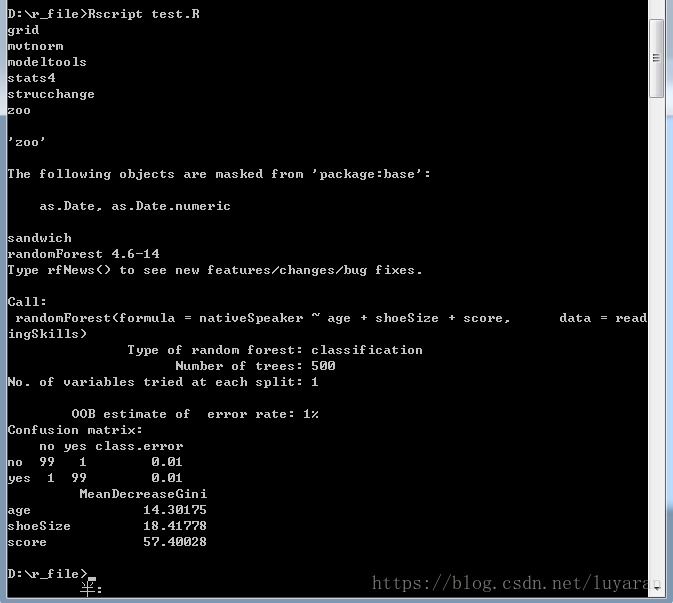
从上图中所示的随机森林,我们可以得出结论,鞋子大小和得分是决定某人是否是母语者的重要因素,此外,该模型只有1%的误差,这意味着我们可以以99%的准确度预测。
好啦,本次记录就到这里了。
如果感觉不错的话,请多多点赞支持哦。。。