
随机森林可处理大量输入变量,并且可以得到变量重要性排序,在实际中,有广泛应用。本文简要展示R语言实现随机森林的示例代码,并通过F值判断模型效果。
随机森林
随机森林是一种常用的集成学习算法,基分类器为决策树。每棵树随机选择观测与变量进行分类器构建,最终结果通过投票得到。一般每棵树选择logN个特征(N为特征数),如果每棵树都选择全部特征,则此时的随机森林可以看成是bagging算法。R语言中,可通过randomForest包中的randomForest()函数完成随机森林算法。
R语言实现
导入包与数据,并根据3:7将数据分为测试集和训练集。
target.url <- 'https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data'
data <- read.csv(target.url,header = F)
set.seed(17)
index <- which( (1:nrow(data))%%3 == 0 )
train <- data[-index,]
test <- data[index,]
library(randomForest)
进行随机森林训练。randomForest()函数中的两个重要参数为ntree和mtry,其中ntree为包含的基分类器个数,默认为500;mtry为每个决策树包含的变量个数,默认为logN,数据量不大时可以循环选择最优参数值。
err<-as.numeric()
for(i in 1:(length(names(train)))-1){
mtry_test <- randomForest(V61~., data=train, mtry=i)
err<- append( err, mean( mtry_test$err.rate ) )
}
print(err)
mtry<-which.min(err)
ntree_fit<-randomForest(V61~., data=train, mtry=mtry, ntree=1000)
plot(ntree_fit)
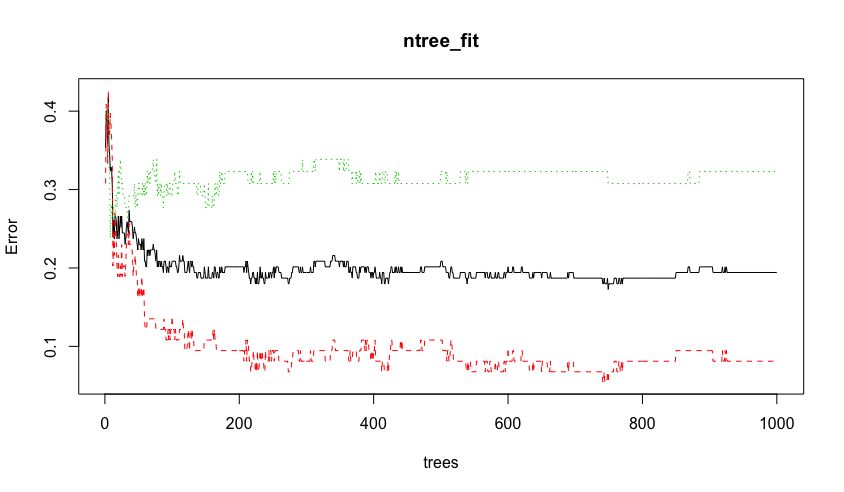
发现mtry取7时err最小,ntree取900时误差稳定。
得到最终分类器,并观察模型效果和变量重要性。
rf<-randomForest(V61~., data=train, mtry=mtry, ntree=900, importance=T )
rf
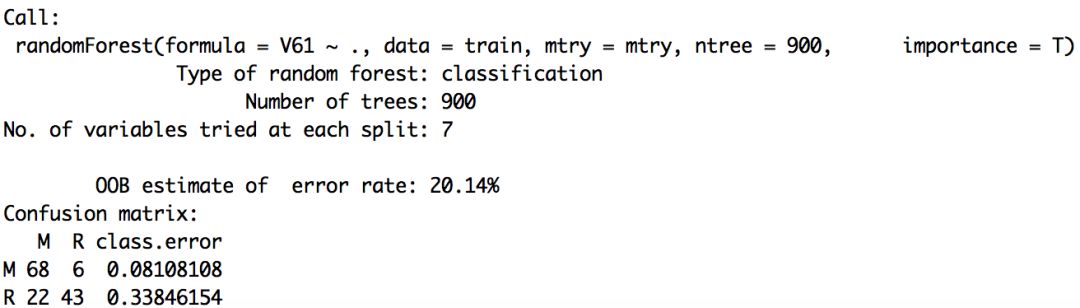
模型误差为20.14%。然后可以通过精确度和基尼系数,判断变量重要性。
importance(rf)
varImpPlot(rf)
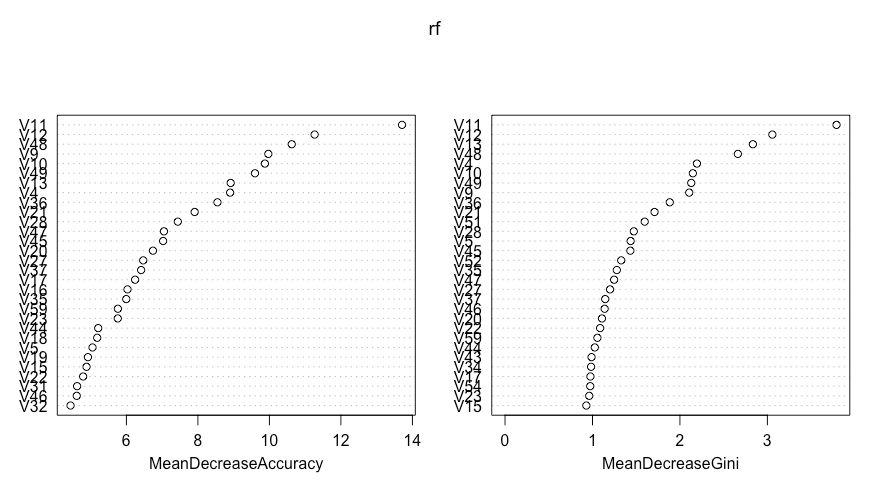
对测试集进行预测,并计算F值,用来判断模型效果。
pred1<-predict(rf,newdata=test)
Freq1<-table(pred1,test$V61)
tp<-as.data.frame(Freq1)[4,3]
tn<-as.data.frame(Freq1)[1,3]
fn<-as.data.frame(Freq1)[2,3]
fp<-as.data.frame(Freq1)[3,3]
p<-tp/(tp+fp)
r<-tp/(tp+fn)
f<-2/(1/p+1/r)

最终发现,F值为0.87。