DCA(Decision Curve Analysis)临床决策曲线是一种用于评价诊断模型诊断准确性的方法,在2006年由AndrewVickers博士创建,我们通常判断一个疾病喜欢使用ROC曲线的AUC值来判定模型的准确性,但ROC曲线通常是通过特异度和敏感度来评价,实际临床中我们还应该考虑,假阳性和假阴性对病人带来的影响,因此在DCA曲线中引入了阈概率和净获益的概念。
我们在既往文章中已经介绍了如何通过R语言绘制逻辑回归、cox回归及竞争回归模型的决策曲线。不少粉丝私信问如何绘制随机森林的决策曲线,今天我们来演示一下如何手动绘制随机森林决策曲线,对于其他模型的决策曲线绘制方法,也是通用的。
决策曲线是什么?
其实决策曲线就是3条线,我们相当于画3条线图。它的X轴表示的是阈值概率,Y轴表示的是净获益,可以看出算出净获益是关键,需要算出3个净获益,all,none,还有我们模型的净获益。
净获益是什么?

净获益需要算出真阳性人数和假阳性人数,所以我们需要算出一个关键的东西,就是预测概率,还有就是实际的结局,这样才能获取相关数据。下面我们通过一个例子来演示一下,通过文章《基于R语言做决策树和随机森林(2)》的数据作为例子,我们先导入数据和R包
library(randomForest)
library(pROC)
library(foreign)
bc <- read.spss("E:/r/test/bankloan_cs.sav",
use.value.labels=F, to.data.frame=T)
删除部分多余的变量,得到如下数据
Age年龄, employ在职雇主的年限,address在这个地方住的时间,income收入,debtinc债务收入比,creddebt信用卡债务,othdebt其他债务,最后一个default是我们的结局指标,即是否是高风险客户。公众号回复:银行客户数据,可以获得该数据。
bc<-bc[,c(-1:-3,-13:-15,-5)]
head(bc,6)
## age employ address income debtinc creddebt othdebt default
## 1 28 7 2 44 17.7 2.990592 4.797408 0
## 2 64 34 17 116 14.7 5.047392 12.004608 0
## 3 40 20 12 61 4.8 1.042368 1.885632 0
## 4 30 11 3 27 34.5 1.751220 7.563780 0
## 5 25 2 2 30 22.4 0.759360 5.960640 1
## 6 35 2 9 38 10.9 1.462126 2.679874 1
bc$default<-as.factor(bc$default)
把数据分为训练集和预测集(就是一个建模,一个验证),要先设一个种子,这样有可重复性
###设置训练和预测集
set.seed(1)
index <- sample(2,nrow(bc),replace = TRUE,prob=c(0.7,0.3))
traindata <- bc[index==1,]
testdata <- bc[index==2,]
###拟合随机森林模型,默认的mtry的值是自变量除以3
def_ntree<- randomForest(default ~age+employ+address+income+debtinc+creddebt
+othdebt,data=traindata,
ntree=500,important=TRUE,proximity=TRUE)
使用验证集生成预测概率(我这里只是演示一下,你使用预测集也是可以的),这里def_pred生成了2个概率是0和1的概率,我们只需要1的概率,所以需要转化一下。
def_pred<-predict(def_ntree, newdata=testdata,type = "prob")##生成概率
def_pred<-as.data.frame(def_pred)
testdata$def_pred<-def_pred$`1`
我们先要生成验证集人数和算出实际发生结果的发生率,就是拿验证集的发生人数(就是1的部分)除以总人数,等下计算要用。
N=dim(testdata)[1]
testdata$default<-as.numeric(testdata$default)-1
event.rate=mean(testdata$default)
那未发生率就是
1-event.rate
## [1] 0.6391982
接下来我们要建一个净获益的预测数据表,到时会显示为X轴,范围肯定是0-1了,步长可以由我们自己设定,通常是0.01
nb=data.frame(threshold=seq(from=0, to=1, by=0.01))
head(nb,6)
## threshold
## 1 0.00
## 2 0.01
## 3 0.02
## 4 0.03
## 5 0.04
## 6 0.05
根据净获益公式可以得到如下,这样nb就有3个数据了
nb["all"]=event.rate - (1-event.rate)*nb$threshold/(1-nb$threshold)
nb["none"]=0
head(nb,6)
## threshold all none
## 1 0.00 0.3608018 0
## 2 0.01 0.3543452 0
## 3 0.02 0.3477569 0
## 4 0.03 0.3410328 0
## 5 0.04 0.3341685 0
## 6 0.05 0.3271598 0
接下来就是算出真阳性和假阳性的人数(tp和fp),因为需要算的是不同预测下的真阳性和假阳性的人数(tp和fp),所以每个阈值都要跑一下,这里要写一个循环。tp等于数据中预测概率在大于阈值概率的部分的发生率,再乘以这部分的人数,fp刚好相反,体会一下。
for(t in 1:length(nb$threshold)){
tp=mean(testdata[testdata["def_pred"]>=nb$threshold[t],"default"])*sum(testdata["def_pred"]>=nb$threshold[t])
fp=(1-mean(testdata[testdata["def_pred"]>=nb$threshold[t],"default"]))*sum(testdata["def_pred"]>=nb$threshold[t])
if (sum(testdata["def_pred"]>=nb$threshold[t])==0) {
tp=0
fp=0
}
nb[t,"def_pred"]=tp/N - fp/N*(nb$threshold[t]/(1-nb$threshold[t])) #净获益公式
}
这样跑完循环后就得出了不同阈值下模型的净获益,就可以画图了
head(nb,6)
## threshold all none def_pred
## 1 0.00 0.3608018 0 0.3608018
## 2 0.01 0.3543452 0 0.3546827
## 3 0.02 0.3477569 0 0.3487569
## 4 0.03 0.3410328 0 0.3433747
## 5 0.04 0.3341685 0 0.3376949
## 6 0.05 0.3271598 0 0.3323174
我们这里使用ggplot来画图,需要调整一下数据格式
library(reshape2)
library(ggplot2)
把长数据变成宽数据
plotdat <- melt(nb,id="threshold",measure=c("def_pred","all","none"))
head(plotdat,6)
## threshold variable value
## 1 0.00 def_pred 0.3608018
## 2 0.01 def_pred 0.3546827
## 3 0.02 def_pred 0.3487569
## 4 0.03 def_pred 0.3433747
## 5 0.04 def_pred 0.3376949
## 6 0.05 def_pred 0.3323174
绘制图形
ggplot(plotdat,aes(x=threshold,y=value,colour=variable))+geom_line()+
coord_cartesian(xlim=c(0,1), ylim=c(-0.05,0.5))+
labs(x="Threshold probability (%)")+labs(y="Net benefit")+
scale_color_discrete(name="Model",labels=c("RF","all","none"))+
theme_bw()+
theme(panel.grid.major=element_blank(),
panel.grid.minor=element_blank(),
legend.title=element_blank())
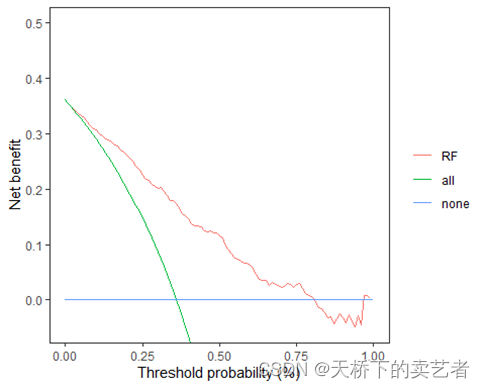
这样图形就绘制好了,就几步,也是不难把,这个方法只要得出预测概率后,适用于各种模型包括lasso回归、机器学习等,其实和模型关系不大,主要是要算出预测概率,如果基础不好或者想图方便的朋友,也可以使用别人写好的函数,dca.r和stdca.r都可以.
我这里使用dca.r简单演示一下。
前面的步骤是一样的,一样要算出概率
set.seed(1)
index <- sample(2,nrow(bc),replace = TRUE,prob=c(0.7,0.3))
traindata <- bc[index==1,]
testdata <- bc[index==2,]
###拟合随机森林模型,默认的mtry的值是自变量除以3
def_ntree<- randomForest(default ~age+employ+address+income+debtinc+creddebt
+othdebt,data=traindata,
ntree=500,important=TRUE,proximity=TRUE)
def_pred<-predict(def_ntree, newdata=testdata,type = "prob")##生成概率
def_pred<-as.data.frame(def_pred)
testdata$def_pred<-def_pred$`1`
这里结局变量需转成数字,不然会报错。
testdata$default<-as.numeric(testdata$default)-1 ##这里结局变量需转成数字0和1
绘图,需要指定结局变量和预测概率,我们这里是结局是default,得到的预测概率是def_pred,
out<- dca(data = testdata, outcome = "default",
predictors = c("def_pred"),
xstart = 0, xstop = 1, ymin = -0.05)
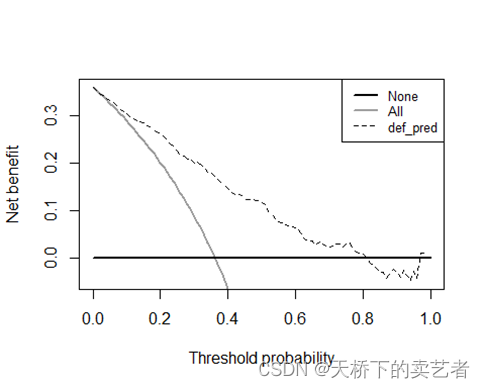
也可以把数据提取出来绘图
out$net.benefit
## threshold all none def_pred
## 1 0.00 0.360801782 0 0.3608017817
## 2 0.01 0.354345234 0 0.3546826843
## 3 0.02 0.347756920 0 0.3487568747
## 4 0.03 0.341032765 0 0.3433747388
使用ggolot绘图上面已经演示过了,这里就不演示了。我把dca.r和stdca.r进行打包,需要这两个函数的请把公众号的本文章转发朋友圈集10个赞,截图发给我,嫌麻烦的给我打赏5元截图发给我也可以。