Bleu
One of the challenges of machine translation is that, given a French sentence, there could be multiple English translations that are equally good translations of that French sentence. So how do you evaluate a machine translation system if there are multiple equally good answers, unlike, say, image recognition where there’s one right answer? You just measure accuracy. If there are multiple great answers, how do you measure accuracy? The way this is done conventionally is through something called the BLEU score.

What the BLEU score does is given a machine generated translation, it allows you to automatically compute a score that measures how good is that machine translation. And the intuition is so long as the machine generated translation is pretty close to any of the references provided by humans, then it will get a high BLEU score. BLEU, by the way, stands for bilingual evaluation, Understudy.
So, the intuition behind the BLEU score is we’re going to look at the machine generated output and see if the types of words it generates appear in at least one of the human generated references.
So one way to measure how good the machine translation output is, is to look at each the words in the output and see if it appears in the references. And so, this would be called a precision of the machine translation output. And in this case, there are seven words in the machine translation output. And every one of these 7 words appears in either Reference 1 or Reference 2, right? So the word the appears in both references. So each of these words looks like a pretty good word to include.
So this will have a precision of 7 over 7. It looks like it was a great precision. This is not a particularly useful measure, because it seems to imply that this MT output has very high precision.
So instead, what we’re going to use is a modified precision measure in which we will give each word credit only up to the maximum number of times it appears in the reference sentences.
在reference 1中,单词the出现了两次,在reference 2中,单词the只出现了一次。而2比1大,所以我们会说,单词the的得分上限为2。有了这个改良后的精确度,我们就说,这个输出句子的得分为2/7,因为在7个词中,我们最多只能给它2分。所以这里分母就是7个词中单词the总共出现的次数,而分子就是单词the出现的计数。我们在达到上限时截断计数,这就是改良后的精确度评估(the modified precision measure)。


对每个二元组,可以统计其在机器翻译结果(
)和人工翻译结果(
)出现的次数,计算 Bleu 得分。
以此类推,以 n 个单词为单位的集合称为n-gram(多元组),对应的 Blue(即翻译精确度)得分计算公式为:
This allows you to
measure the degree to which the machine translation output is similar or maybe overlaps with the references.

BP: brevity penalty. It turns out that if you output very short translations, it’s easier to get high precision. Because probably most of the words you output appear in the references. But we don’t want translations that are very short. So the BP, or the brevity penalty,
is an adjustment factor that penalizes translation systems that output translations that are too short.
So the BLEU score is a useful single real number evaluation metric to use whenever you want your algorithm to generate a piece of text. And you want to see whether it has similar meaning as a reference piece of text generated by humans. This is not used for speech recognition, because in speech recognition, there’s usually one ground truth. And you just use other measures to see if you got the speech transcription on pretty much, exactly word for word correct. But for things like image captioning, and multiple captions for a picture, it could be about equally good or for machine translations. There are multiple translations, but equally good. The BLEU score gives you a way to evaluate that automatically and therefore speed up your development.
Attention Model Intuition

Long sentences, it doesn’t do well on because it’s just difficult to get in your network to memorize a super long sentence.
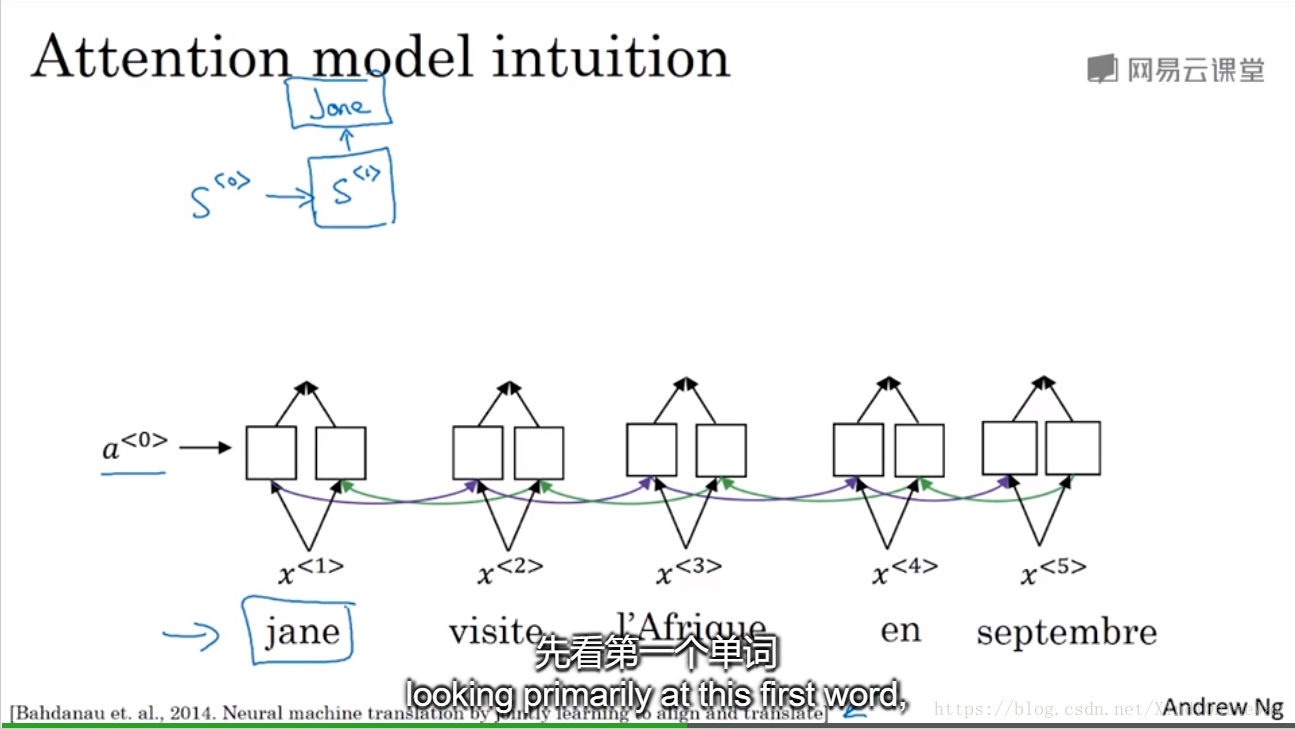
Now, the question is, when you’re trying to generate this first word, this output, what part of the input French sentence should you be looking at? Seems like you should be looking primarily at this first word, maybe a few other words close by, but you don’t need to be looking way at the end of the sentence.
What the Attention Model would be computing is a set of attention weights.
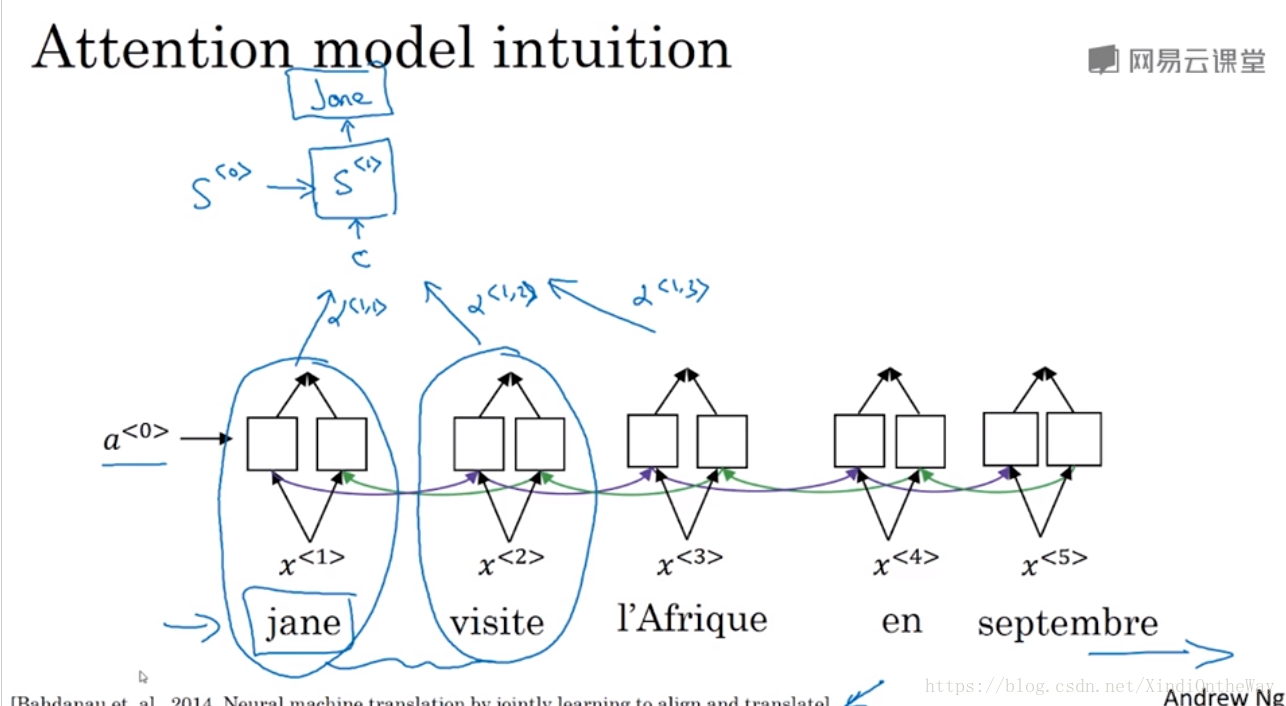
: when you’re generating the first words, how much should you be paying attention to this first piece of information here
: what we’re trying to compute the first work of Jane, how much attention we’re paying to this second work from the inputs
: what is exactly the context from denoter C that we should be paying attention to, and that is input to this RNN unit to then try to generate the first word.

: when we generate in the second word. I guess this will be “visits” maybe that being the ground trip label. How much should we paying attention to the first word in the french input
: when you’re trying to generate the
, English word, how much should you be paying attention to the
French words. And this allows it on every time step to look only maybe within a local window of the French sentence to pay attention to, when generating a specific English word.
Attention Model

is going to be a feature vector for time step t.
I’m going to use
to index into the words in the French sentence.
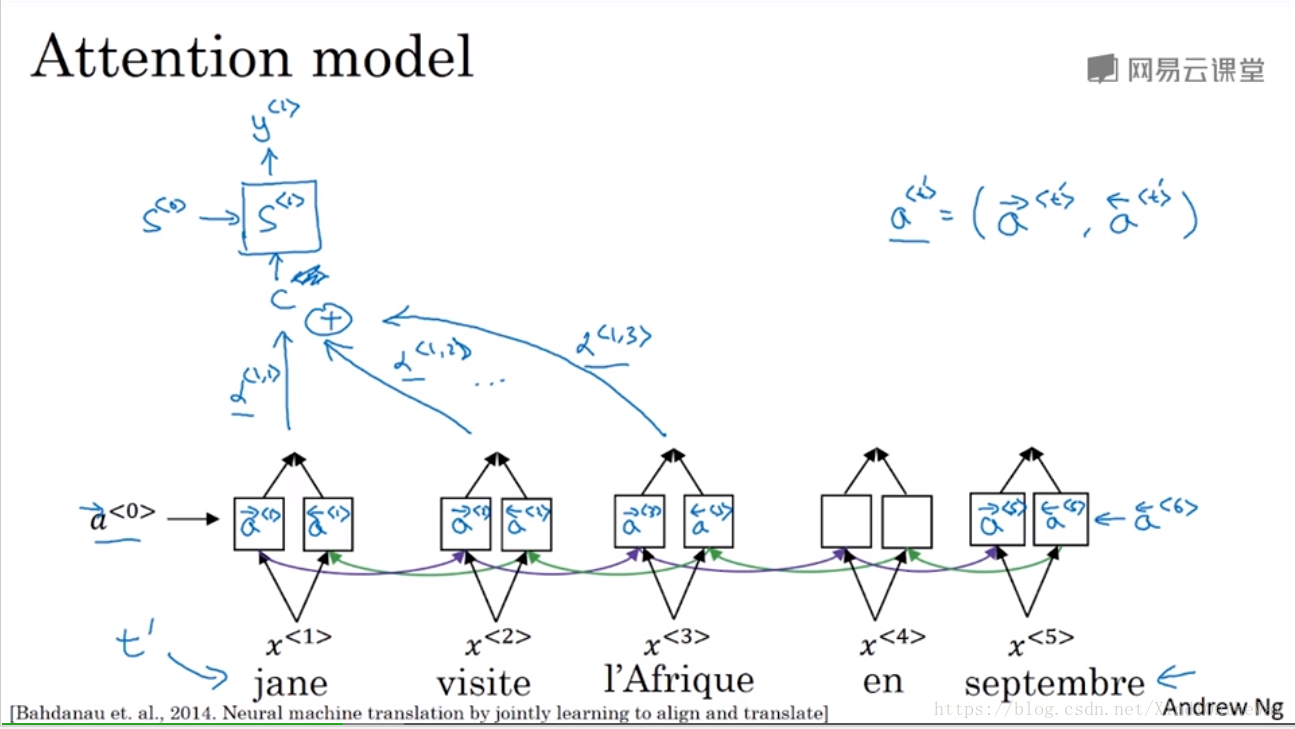
These alpha parameters tell us how much the context would depend on the features we’re getting or the activations we’re getting from the different time steps. And so the way we define the context is actually be a way to some of the features from the different time steps weighted by these attention waits.
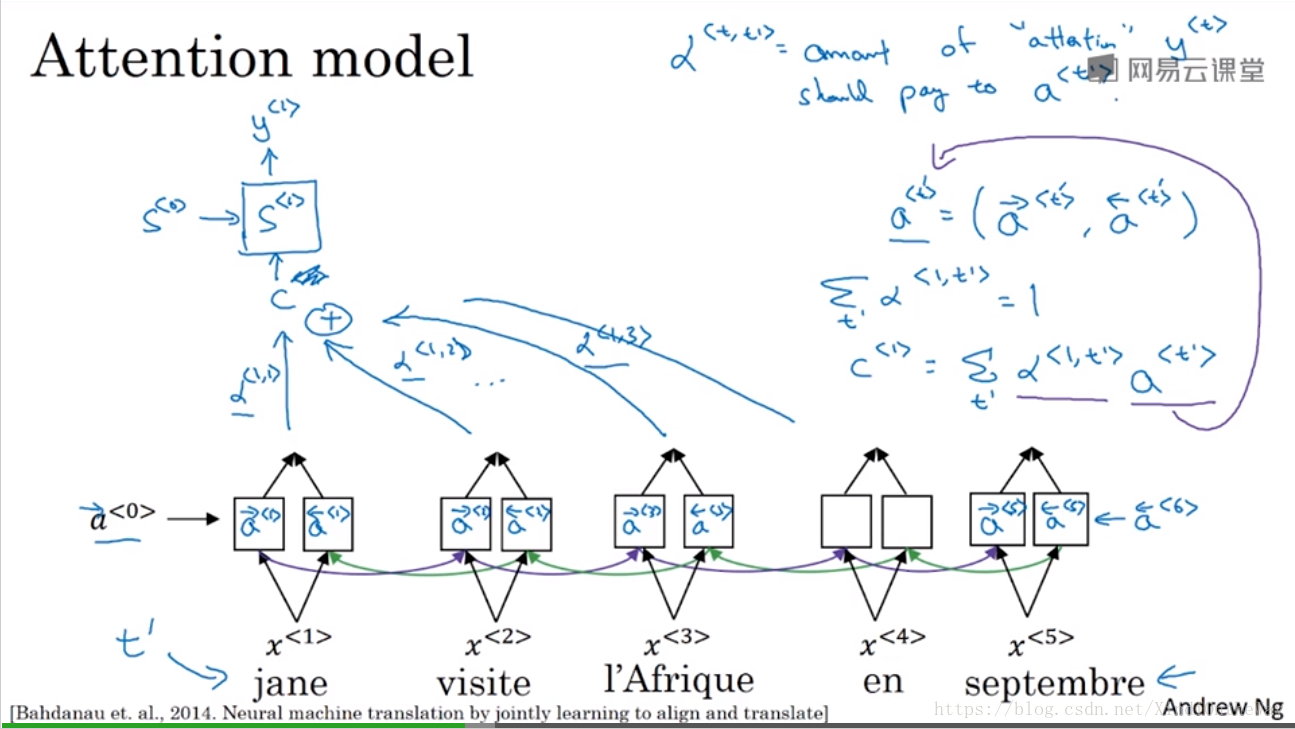
: when you’re generating the of the output words, how much you should be paying attention to the input to word.

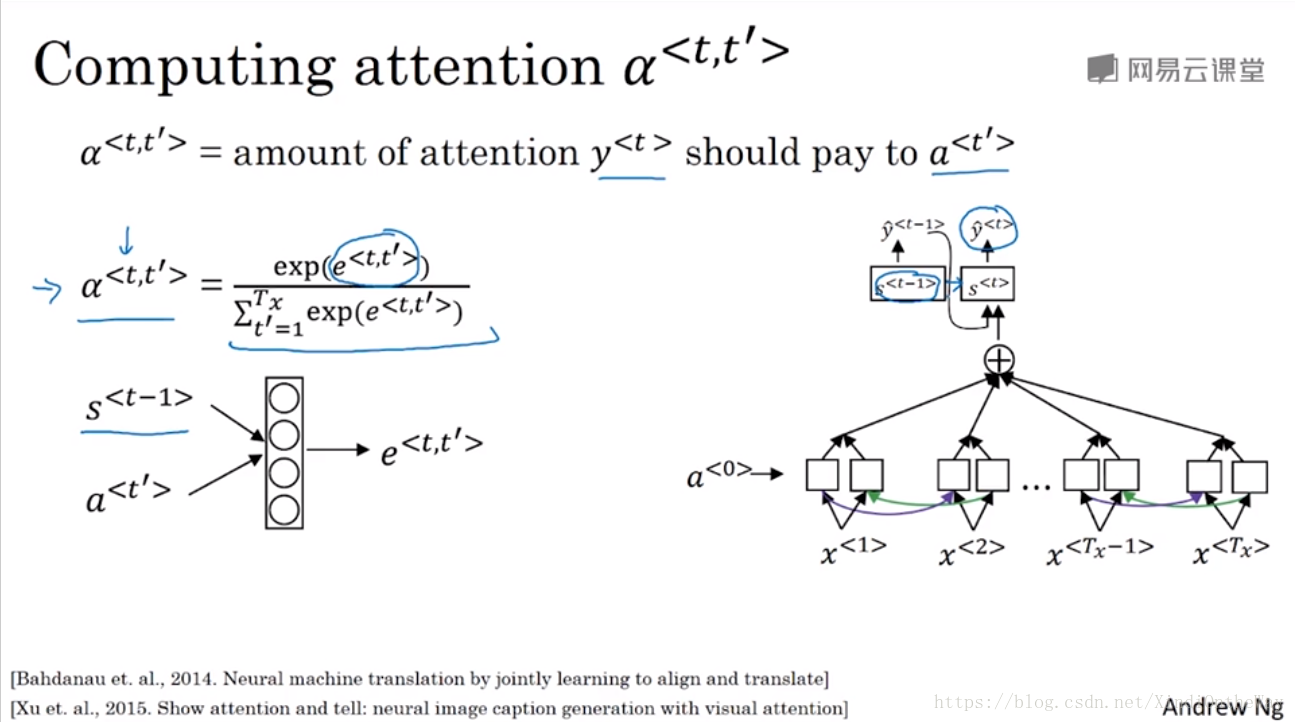
One way to do so is to use a small neural network as follows.
So
was the neural network state from the previous time step.
If you’re trying to generate
then
was the hidden state from the previous step that just fell into
and that’s one input to very small neural network. Usually, one hidden layer in neural network because you need to compute these a lot. And then
the features from time step
is the other inputs. And the intuition is, if you want to decide how much attention to pay to the activation of
. Well, the things that seems like it should depend the most on is what is your own hidden state activation from the previous time step. You don’t have the current state activation yet because of context feeds into this so you haven’t computed that. But look at whatever you’re hidden stages of this RNN generating the upper translation and then for each of the positions, each of the words look at their features. So it seems pretty natural that
and
should depend on these two quantities. But we don’t know what the function is. So one thing you could do is just train a very small neural network to learn whatever this function should be.