Improvise a Jazz Solo with an LSTM Network
实现使用LSTM生成音乐的模型,你可以在结束时听你自己的音乐,接下来你将会学习到:
-
使用LSTM生成音乐
-
使用深度学习生成你自己的爵士乐
现在加载库,其中,music21可能不在你的环境内,你需要在命令行中执行pip install msgpack以及pip install music21来获取。
from __future__ import print_function
import IPython
import sys
from music21 import *
import numpy as np
from grammar import *
from qa import *
from preprocess import *
from music_utils import *
from data_utils import *
from keras.models import load_model, Model
from keras.layers import Dense, Activation, Dropout, Input, LSTM, Reshape, Lambda, RepeatVector
from keras.initializers import glorot_uniform
from keras.utils import to_categorical
from keras.optimizers import Adam
from keras import backend as K
1. 问题描述(Problem statement)
使用LSTM生成爵士音乐

1.1 Dataset
IPython.display.Audio('./data/30s_seq.mp3')

我们已经对音乐数据进行了预处理,以按照音乐“值”来呈现它。你可以非正式地将每个“值”视为一个音符,其中包括振幅和持续时间。
-
例,如果你按下特定的钢琴键0.5秒,那么你刚刚弹奏了一个音符。在音乐理论中,“值”实际上比这更复杂 - 具体而言,它还收集了同时播放多个音符所需的信息。
-
例如,在播放乐曲时,你可以同时按下两个钢琴键(同时播放多个音符会产生所谓的“和弦”)。但是我们不需要担心音乐理论的细节。
这个作业目标,你需要知道的是我们将获得值的数据集,并将学习RNN模型以 生成值序列。
我们的音乐生成系统将使用78个独特的值。运行以下代码以加载原始音乐数据,并将其预处理为值。这可能需要几分钟时间。
X, Y, n_values, indices_values = load_music_utils()
print('shape of X:', X.shape)
print('number of training examples:', X.shape[0])
print('Tx (length of sequence):', X.shape[1])
print('total # of unique values:', n_values)
print('Shape of Y:', Y.shape)
shape of X: (60, 30, 78)
number of training examples: 60
Tx (length of sequence): 30
total # of unique values: 78
Shape of Y: (30, 60, 78)
简单解释下数据集:
-
X: 这个是维度 (m, \(T_x\), 78) 的数组,我们有 m 个训练样本, 每个样本被分割为 \(T_x =30\) 的音乐值。在每个时间步,输入的是78个不同的可能值之一,表示为一个one-hot向量。 因此,X[i,t,:]是表示 时间t的 第i个样本的值的一个 one-hot 向量。 -
Y: 这与“X”基本相同,但向左移动了一步。类似于恐龙命名,我们感兴趣的是使用先前的值来预测下一个值的网络,因此,我们序列模型在给定 \(x^{\langle 1\rangle}, \ldots, x^{\langle t \rangle}\) 时将尝试预测 \(y^{\langle t \rangle}\)。 但是,数据Y被重排成维度\((T_y, m, 78)\), 且 \(T_y = T_x\),这个格式更方便给LSTM喂数据。 -
n_values: 此数据集中唯一值的数量,这应该是78。 -
indices_values: 字典,0-77的数值映射到音乐值的字典。
1.2 模型预览(Overview of our model)
下面将使用的模型的架构:
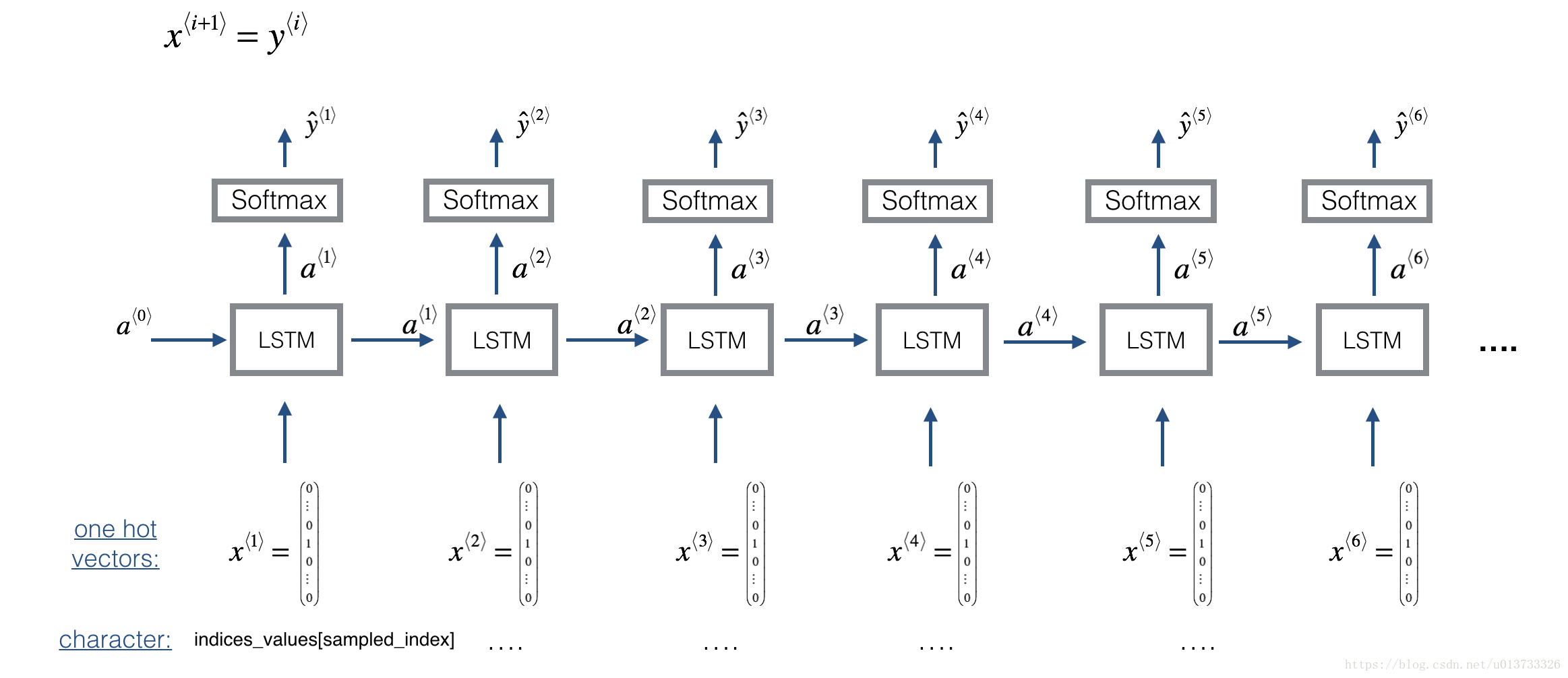
我们将从一段较长的音乐片段中 随机抽取30个值 来训练模型。因此,我们不会设置第一个输入为 \(x^{\langle 1 \rangle} = \vec{0}\),因为现在大部分的音频片段都在一个音乐的中间开始,我们设置每个片段具有相同的长度 \(T_x = 30\) 让向量化更容易。
2. 构建模型(Building the model)
在这里,我们将构建和训练一个学习音乐的模型,输入的是维度为 \((m, T_x, 78)\) 的 X,维度为\((T_y, m, 78)\)的Y,我们使用的是 64维隐藏层的LSTM,所以n_a = 64。
以下是如何创建具有多个输入和输出的Keras模型。如果你正在构建一个RNN网络,即使在测试时也预先给出了整个输入序列 \(x^{\langle 1 \rangle}, x^{\langle 2 \rangle}, \ldots, x^{\langle T_x \rangle}\), 例如,如果输入是单词,输出是一个标签,那么keras有简单的内置函数来构建模型。但是,对于序列生成,在测试时我们并不提前知道 \(x^{\langle t\rangle}\) 的所有值;相反,我们使用 \(x^{\langle t\rangle} = y^{\langle t-1 \rangle}\) 一次生成一个。你需要实现你自己的for循环来迭代不同的时间步。
函数 djmodel() 将使用for循环,调用LSTM层 \(T_x\) 次,并且重要的是,所有 \(T_x\) 副本 具有相同权重。也就是说,它不应该每次都重新初始化权重 - \(T_x\) 步应该具有相同的权重, 在Keras中实现具有可共享权重的层的关键步骤是:
-
定义图层对象(我们将使用全局变量)。
-
在传播输入时,调用这些对象。
我们将需要的layers objects定义为全局变量,运行下面代码,理解这些layers: Reshape(), LSTM(), Dense().
reshapor = Reshape((1, 78)) # Used in Step 2.B of djmodel(), below
LSTM_cell = LSTM(n_a, return_state = True) # Used in Step 2.C
densor = Dense(n_values, activation='softmax') # Used in Step 2.D