摘要
本文介绍了UNIPUS-Flaubert团队的混合系统,用于NLPTEA 2020中国语法错误检测(CGED)的共同任务。作为一项具有挑战性的NLP任务,CGED最近引起了越来越多的关注,但尚未充分受益于功能强大的基于BERT的预训练模型。我们通过试验三种类型的模型来探索这一点。位置标记模型和纠正标记模型是在预先训练的基于BERT的模型上进行了微调的序列标记模型,其中前者侧重于检测,定位和分类错误,而后者侧重于校正错误。通过将BERT-fused模型转移到纠正任务,我们还利用了基于BERT的模型的丰富表示,并通过对大量无监督的合成数据进行了预训练进一步提高了性能。据我们所知,我们是第一个将BERT融合的NMT模型和序列标记模型引入并将其转移到中文语法纠错领域的公司。我们的工作在检测错误时获得了第二高的F1分数,在纠正top1子任务中获得了最佳的F1分数,并且在纠正top3子任务中获得了第二高的F1分数。
1.介绍
最近,经过预训练的语言模型(例如BERT)在各种自然语言处理(NLP)任务(例如文本分类,阅读理解,机器翻译)上获得了最新的结果。英语语法错误纠正(GEC)任务也受益于预训练的语言模型。例如,在Kaneko et al. (2020)工作中,他们不仅遵循Zhu et al. (2020)将BERT合并到GEC的EncoderDecoder模型中,还通过在BERT上对GEC语料库(以BERT-fuse mask方式)进行训练或将BERT作为GED模型进行微调(以BERT-fuse GED方式)来最大化性能。改善GEC性能的另一种方法是使用BERT作为编码器并将其作为序列标注模型。
在中文NLP社区中,已经提出了多种预训练的中文语言模型并公开可用。事实证明,这些模型在各种下游任务(包括阅读理解,自然语言推理,情感分类等)上都有了显着改进。
在本文中,我们将最先进的英语GEC模型应用于CGED任务。我们的CGED系统包含三种类型的模型。我们提出位置标注模型,它是带有BERT编码器的序列标注模型,以集中于错误定位任务。输出类别由8种类型的标签组成,指示输入句子中每个错误的开始和结束,但是在S(单词选择)和M(丢失单词)错误的情况下,它不会告诉我们如何纠正它。纠正标注模型专注于纠错任务,并且输出标签包含8772种标签。标签显示了每个汉字的编辑操作,例如 K E E P KEEP KEEP, D E L E T E DELETE DELETE, A P P E N D APPEND APPEND和 R E P L A C E REPLACE REPLACE。 A P P E N D APPEND APPEND标签(共3788个)和 R E P L A C E REPLACE REPLACE标签(共4982个)覆盖了大多数汉字。
针对神经机器翻译(NMT)任务提出了BERT-fused模型,并通过注意力机制来自适应控制BERT表示和Transformer各层之间的交互。(Kaneko et al., 2020)将BERT-fused模型转移到了英语GEC任务中,并进一步提升了它。由于时间限制,我们仅遵循(Zhu et al., 2020)中的训练设置。此外,我们通过在大量无错误的语料库上引入合成错误,然后将合成错误句和原始句子配对,从而在预训练的Transformers上执行无监督数据增强。
本文的组织结构如下:第2节总结了CGED领域的最新发展。第3部分介绍了我们用于训练模型的数据集,包括人工注释数据和合成数据。第4部分概述了系统的每个组件,包括BERT-fused NMT,位置标注模型,纠正标注模型和错误注释工具。第5节介绍了我们的训练和联合解码过程。第6节讨论了我们模型的结果,第7节对论文进行了总结。
2.相关工作
Zhao et al. (2015) 对CGED任务使用了一种统计机器翻译方法,并探索了包括基于语法和基于层次短语模型在内的可替代的翻译模型。Zheng et al. (2016), Yang et al. (2017) 和Liao et al. (2017) 将CGED任务视为序列标注问题以检测语法错误。Li and Qi (2018) 将策略梯度LSTM模型应用于CGED任务。Fu et al. (2018b) 建立了一个基于BiLSTM-CRF模型的CGED系统,并与基于规则的模板相结合以引入语法知识。Hu et al. (2018) 采用了seq2seq模型,并使用伪造数据对模型进行了预训练。Li et al. (2018) 设计了一个用于CGED的系统,该系统由BiLSTM-CRF模型,NMT模型和统计机器翻译模型组成,以检测和纠正语法错误。类似的系统在NLPCC 2018共享任务中取得了竞争优势。Fu et al. (2018a) 也将CGED任务视为翻译问题,并使用基于字符和基于子词的NMT来纠正语法错误。Li et al. (2019) 和Ren et al. (2018) 将卷积序列到序列模型引入CGED任务。
3.数据集
(1)训练数据
CGED的NLPTEA 2014〜2018和2020共享任务的数据集是由汉语作为外语(CFL)学习者写的句子及其纠正句子组成的平行语料库。源句选自基于计算机的TOCFL(汉语作为外语考试)的论文部分和基于书面的HSK(汉语水平考试的汉语拼音汉译水准)。2016年之前,只有使用繁体中文撰写的TOCFL数据。在2016年的数据集中,我们同时拥有TOCFL和HSK数据。我们使用opencc软件包将TOCFL语料库的繁体中文转换为简体中文。自2017年以来,仅提供全部以简体中文编写的HSK数据。
语法错误由中文为母语的人手动注释。错误有四种:R(冗余单词),M(丢失单词),S(单词拼写错误)和W(单词顺序错误)。每种错误类型在语料库中所占的比例不同,每个句子可能包含多个错误。例如,在CGED 2020训练集中,W / S / R / M分别占总错误的7%,42%,23%和28%。在1641个句子中有2909个手动注释的错误,只有2个句子没有错误。
我们还从NLPCC 2018 GEC和其他资源中收集了一些外部数据集。NLPCC 2018 GEC数据包含大约700000个句子,每个句子可能是正确的或具有一个或多个候选更正。
(2)合成数据
我们在预训练模式和非预训练模型下训练BERT-fused的NMT模型。对于预训练模式,该模型在大量合成数据上进行了预训练。而其他模型未使用该合成数据。
我们首先使用中文分词工具将每个无错误的句子分割成多个单词,然后为每个句子随机选择几个单词。所选单词的数量是根据正态分布中采样的概率与句子中单词数量的乘积。对于每个选定的单词,以0.5、0.2、0.2、0.1的概率执行包括替换,删除,插入和换位在内的四个操作之一,它模拟CGED数据中S,M,R,W错误的比例 。
替换操作。为了进行替换,将所选单词替换为具有相似语义,发音或形状的单词。为了模拟相似含义,我们从以下来源中随机选择一个替换:(1)所选单词的相似度大于0.75的同义词;(2)中文字典,我们可以搜索包含至少一个与所选单词相同的字符的单词;(3)混淆字典由日语和汉语单词对组成,可能会被日语学习者误用。为了模仿相似发音,我们将所选单词替换为拼音相同的单词。当从相似形状引入混淆时,我们通过其四角号码定义两个字符之间的相似性。
删除操作。为了进行删除,我们只需删除所选单词。
插入操作。为了进行插入,我们在选定单词之后添加从集合中随机抽取的单词。该集合由停用词和过去CGED数据集中来自R错误的冗余词组成。
换位操作。为了进行换位,我们将所选单词与下一个单词或句子中的随机单词交换。我们跳过命名实体进行替换和删除操作。
将单词级错误引入每个无错句子后,我们通过类似的方法引入字符级错误。
我们用于生成合成数据的语料库是wiki2019zh(964万个句子),news2016zh(5140万个句子),webtext2019zh(106万个句子)和SogouCA(94万个句子)。
4.系统
我们的系统由专注于错误检测子任务的序列标记模型和旨在生成候选纠正的两种错误纠正模型组成。
4.1 位置标记模型
位置标记模型是旨在定位语法错误的序列标记模型。我们使用RoBERTa作为模型的编码器,然后在训练过程中对其进行微调。通过在编码器的logit上应用softmax层来生成输出标签。
给定一系列汉字作为输入,该模型将预测每个字的标签。 输出标签由8种类别组成,包括O(正确),B-S(S开头),I-S(S中间),B-W(W开头),I-W(W中间),B-M(M开头),B-R(R开头)和I-R(R中间)。我们直接从输出标签中提取每个错误的位置和类型。 对于S和M错误,模型无法给出任何候选校正。
4.2 BERT-fused NMT
(Zhu et al., 2020) 中提出的BERT-fused NMT模型针对NMT任务,我们将原始工作转移到语法纠正任务。BERT-fused NMT模型由两个模块组成:NMT模块和BERT模块。两个模块都将错误的句子作为输入。我们首先从头训练Transformer,直到收敛。然后,我们使用此Transformer的编码器和解码器初始化NMT模块的编码器和解码器。BERT模块与现成的预训练BERT模型相同。
融合NMT模块和BERT模块的方法是将来自BERT模块的表示(即BERT模块最后一层的输出)带入到NMT模块的每一层。以NMT编码器为例,将BERT编码器的自注意力引入每个NMT编码器层,并处理来自BERT模块的表示。每个NMT编码器层的原始自注意力仍然处理来自先前NMT编码器层的表示。编码器层的原始前馈网络会进一步处理BERT编码器注意力输出和原始自注意力的输出。通过将BERT解码器的自注意力引入每个NMT解码器层,NMT解码器的工作原理相似。
BERT编码器注意力和BERT解码器注意力的参数是随机初始化的。在训练BERT-fused的NMT模型期间,BERT模块的参数是固定的。
4.3 纠正标记模型
纠正标记模型是特定于GEC任务的序列标记模型。输出标签由8772个类别组成,这些标签形成较大的编辑空间。我们通过以下方式获得纠正结果:将句子迭代地输入模型,获取每个字符的编辑操作,然后编辑句子。
为了准备训练数据,我们首先将目标句子转换为标签序列,其中每个标签代表对每个源字符的编辑操作。以下面的句子对为例:

我们使用最小编辑距离算法将源标记与目标标记对齐。对于对齐的每个映射,我们收集从源字符到目标子序列的编辑步骤:

最后,对于每个源字符,我们只保留一个编辑,因为在训练阶段,每个字符只能有一个标签。在上述示例中,

纠正标记模型是经过预训练的类似BERT的Transformer编码器,在顶部堆叠有两个线性层和softmax层。
在推理阶段,我们迭代标记和编辑句子以获得完全正确的句子。在每次迭代中,我们根据输入句子上的输出标签应用编辑,然后将编辑后的句子发送到下一个迭代。
4.4 错误分类
对于BERT-fused的NMT和纠正标记模型,最终输出为更正后语句。为了与正式提交格式相匹配,我们将目标句子与源句子对齐,以定位错误的开始和结束并对错误类型进行分类。
在GED领域,有一种广泛使用的错误注释工具-errant,该工具会自动注释平行英语句子的错误类型信息。但是,CGED任务中没有此类工具。我们开发了一个简单的基于规则的注释工具来查找错误并分类错误类型。我们的工具首先使用Jieba将源句子和目标句子分成单词,然后根据最小编辑距离算法将源句子和目标单词对齐。在每个映射中,如果源词和目标词的块不相同,我们的工具会将此映射判断为语法错误,并确定此错误的位置和类型。
但是,即使我们有经过修正的golden句子,在对错误进行定位和分类时也存在一些歧义。例如,在CGED 2020训练集中,给定以下句子对:

官方结果是S错误,从第24个字符开始,到第27个字符(“相受拥着”)结束,更正为“拥有”。但是可能有许多可能的解决方案取决于分词。例如,如果将“相受拥着”分为“相受”和“拥着”,结果将成为R错误,从第24个字符开始,终止于第25个字符,S错误从第26个字符开始, 将第27个字符(“拥着”)替换为“拥有”。因此,由于不同的分词规则,很难准确地定位和分类错误。
我们在CGED 2020训练数据集上测试了注释工具,如表2所示。当注释来自并行语句的错误信息时,错误注释工具在检测,识别和定位子任务上损失了一些精度和召回率。

5.实验
5.4 模型ensemble

我们采用Li et al. (2018) 启发的加权投票策略。位置标记模型的输出提供每个错误的位置和类型,但是缺少对S和M错误的校正。BERT-fused的NMT模型和纠正标记模型的输出是经过纠正后的句子,并使用第4.4节中的注释工具转换为正式提交格式。
首先,我们暂时忽略对S和M错误的更正,然后投票确定所有错误的位置和类型的结果。仅当投票数超过阈值时,我们才会接受错误提议。如果不接受所有错误建议,那么该句子将被视为正确。然后,我们进行更正。对于每个接受的S和M错误,我们根据票数对BERT-fused NMT模型和纠正标记模型中的候选纠正进行排序。我们将前三个候选者作为最终更正。图1展示了我们的整体策略。
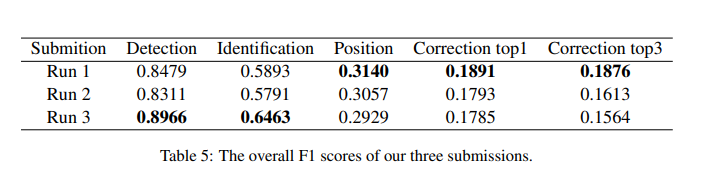
每组模型在投票期间具有不同的权重。使用网格搜索在CGED 2018测试集上调整所有阈值和权重,旨在在纠正top1子任务中获得最佳F1分数。表5中描述了我们对这三个提交的正式评估。Run 1在纠正top1子任务中排名第一,在纠正top3子任务中排名第二。Run 1和Run 2之间的区别在于,在BERT-fused的NMT模型中,n-best的超参数分别设置为1和8。对于Run 2(n最佳为8),每个BERT-fused的NMT模型都会生成8个候选语句,并且全部参与投票。Run 3尝试了一种不同的集成模型,该模型主要侧重于提高查全率,并在检测子任务中排名第二。