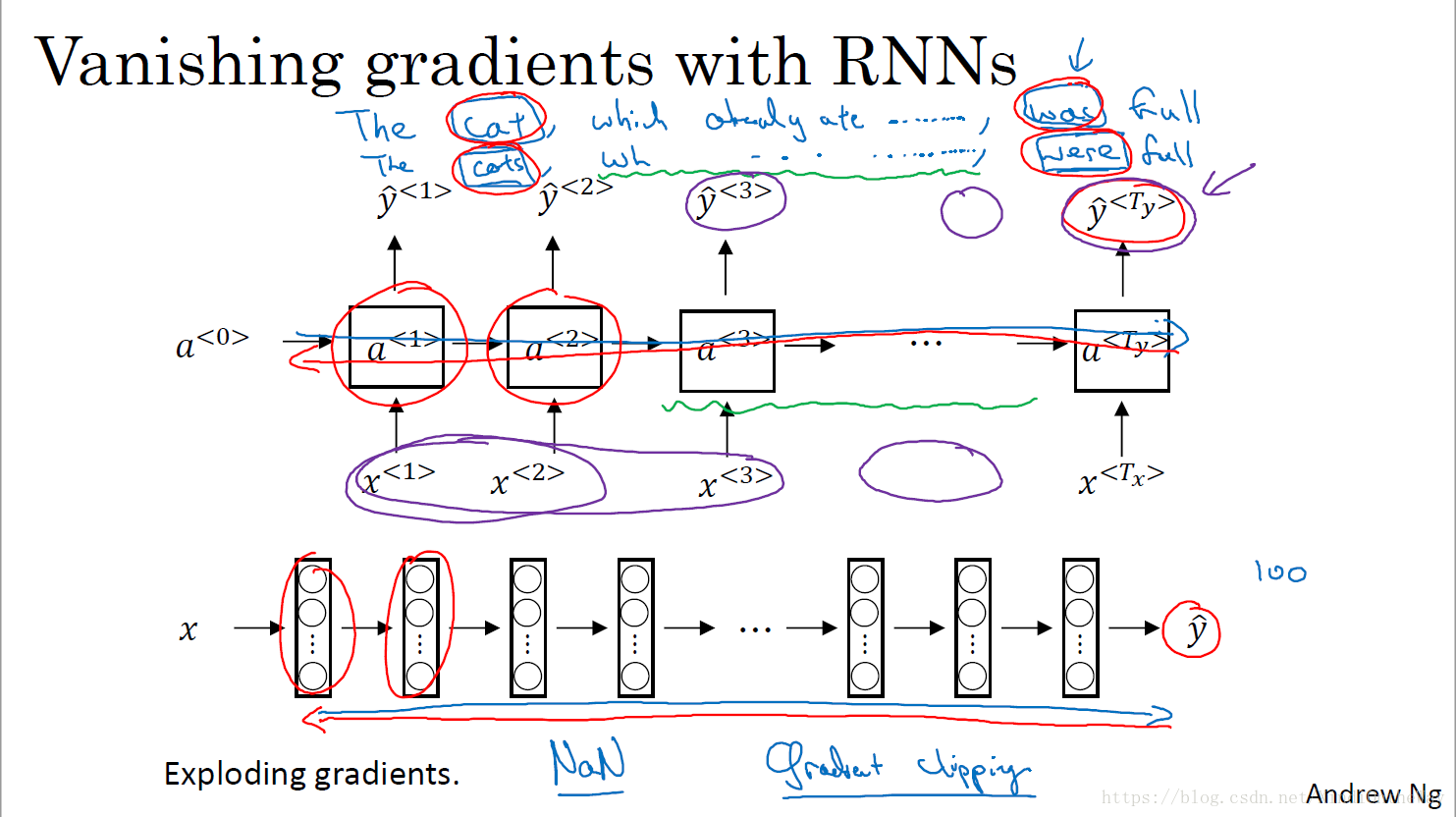
Vanishing gradients with RNNs
梯度消失和梯度爆炸本质上是因为矩阵的高次幂。

对于:
The cat, which already ate …, ?(was/were) full.
The cats, which already ate …, ?(was/were) full.
传统的RNN没有办法捕获长期的依赖关系(Long term dependency)
对于一个深度神经网络,输出端
的梯度很难传回到前面的层去影响前面层权重的计算。
And we said that, if this is a very deep neural network, then the gradient from just output y, would have a very hard time propagating back to affect the weights of these earlier layers, to affect the computations in the earlier layers.
对RNN也有类似的问题。
And for an RNN with a similar problem, you have forward prop came from left to right, and then back prop, going from right to left. And it can be quite difficult, because of the same vanishing gradients problem, for the outputs of the errors associated with the later time steps to affect the computations that are earlier.
And so in practice, what this means is, it might be difficult to get a neural network to realize that it needs to memorize the just see a singular noun or a plural noun, so that later on in the sequence that can generate either was or were, depending on whether it was singular or plural.
因此在RNN模型中,影响都是局部传输的。
So because of this problem, the basic RNN model has many local influences, meaning that the output
is mainly influenced by values close to
. And a value here is mainly influenced by inputs that are somewhere close. And it's difficult for the output here to be strongly influenced by an input that was very early in the sequence. And this is because whatever the output is, whether this got it right, this got it wrong, it's just very difficult for the area to backpropagate all the way to the beginning of the sequence, and therefore to modify how the neural network is doing computations earlier in the sequence. So this is a weakness of the basic RNN algorithm.
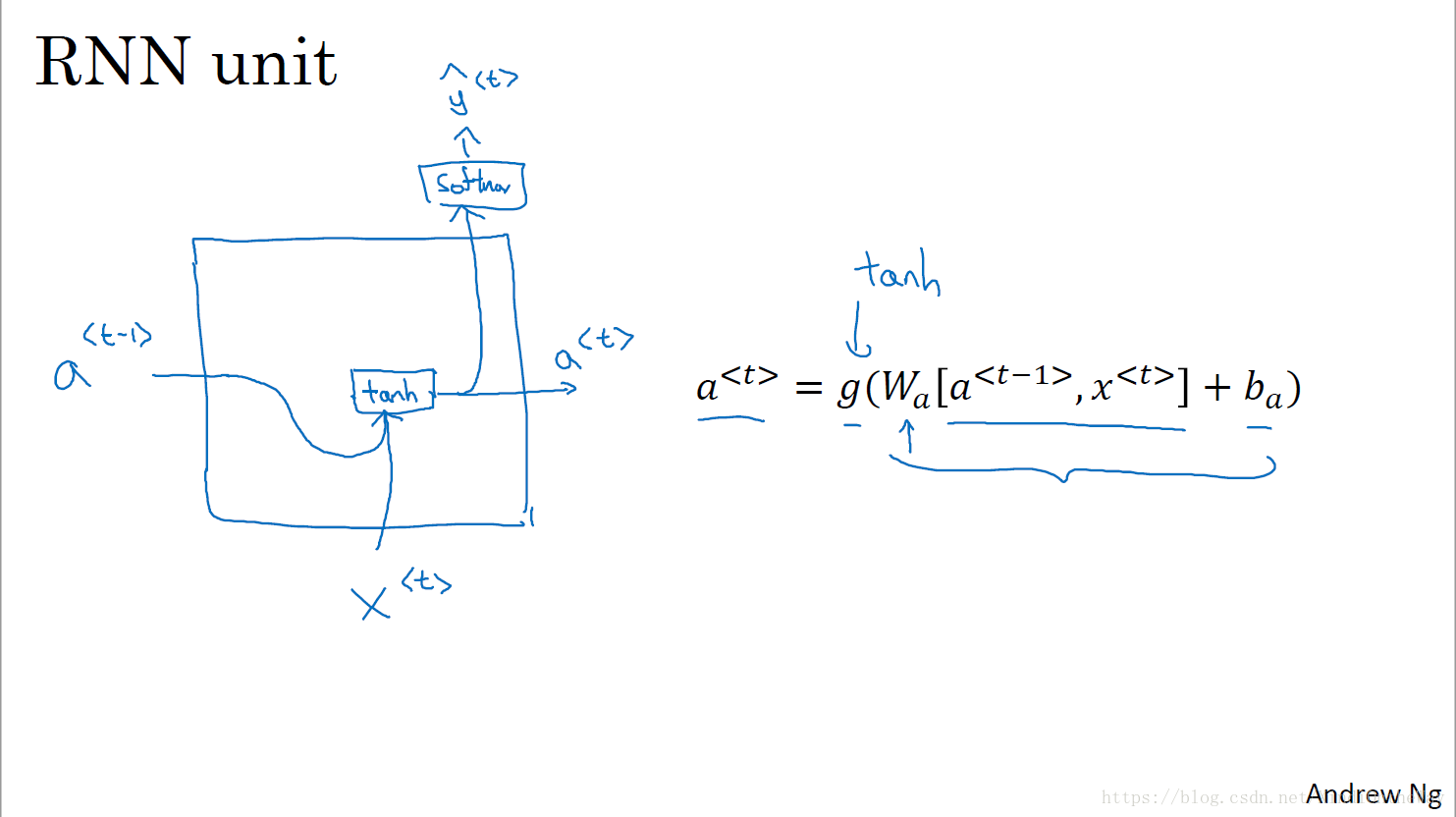
GRU单元

RNN单元的可视化呈现:
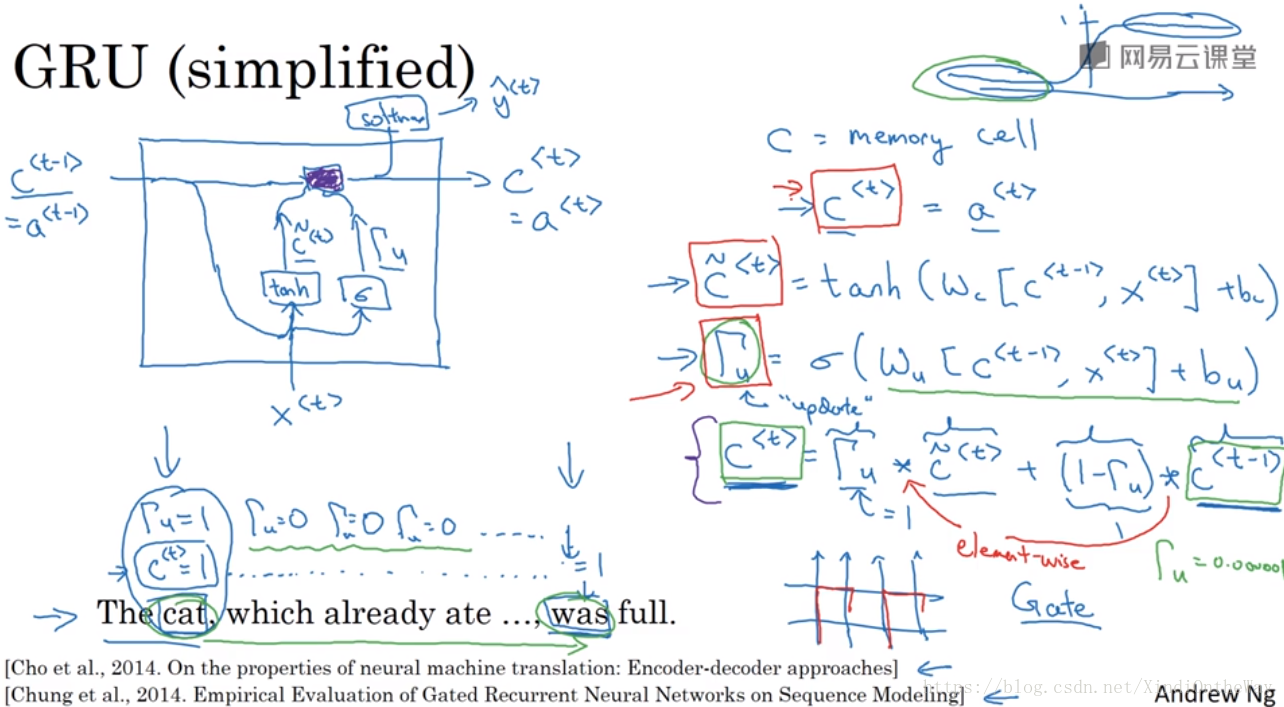
The Gated Recurrent Unit which is a modification to the RNN hidden layer that makes it much better capturing long range connections and helps a lot with the vanishing gradient problems.


c=memory cell
What the memory cell do is it will provide a bit of memory to remember, for example, whether cat was singular or plural, so that when it gets much further into the sentence it can still work under consideration whether the subject of the sentence was singular or plural
: the value of the memory cell at time t
Every time-step, we’re going to consider overwriting the memory cell with
. So this is going to be a candidate for replacing
.
And then the key, really the important idea of the GRU it will be that we have a gate.
It’s value is always between zero and one. And for most of the possible ranges of the input, the sigmoid function is either very, very close to zero or very, very close to one. So for intuition, think of gamma as being either zero or one most of the time.
The key part of the GRU is this equation which is that we have come up with a candidate where we’re thinking of updating
using
, and then the gate will decide whether or not we actually update it.
(element wise)
If
,
,更新memory cell;
If
,
, maintaining the memory cell.

注意到
对于sigmoid来说,只要里面的值是一个很负的值,
也就是说记忆单元中的值会保留好多好多步。
the value of
is maintained pretty much exactly even across many many many many time-steps. So this can help significantly with the vanishing gradient problem and therefore allow a neural network to go on even very long range dependencies.
What these element wise multiplications do is it just element wise tells the GRU unit which other bits in your- It just tells your GRU which are the dimensions of your memory cell vector to update at every time-step. So you can choose to keep some bits constant while updating other bits. So, for example, maybe you use one bit to remember the singular or plural cat and maybe use some other bits to realize that you’re talking about food. And so because you’re talk about eating and talk about food, then you’d expect to talk about whether the cat is four letter, right. You can use different bits and change only a subset of the bits every point in time.

You can think of r as standing for relevance. So this gate
tells you how relevant is
to computing the next candidate for
.
LSTM


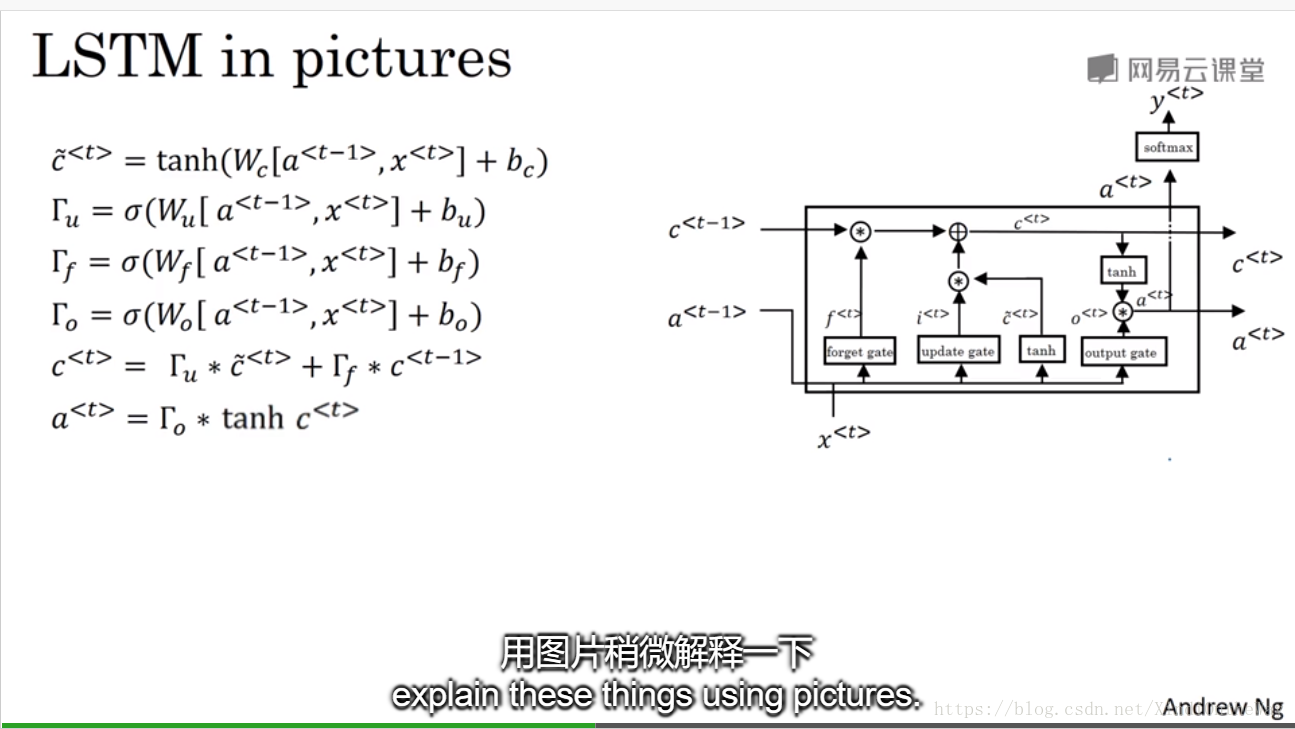
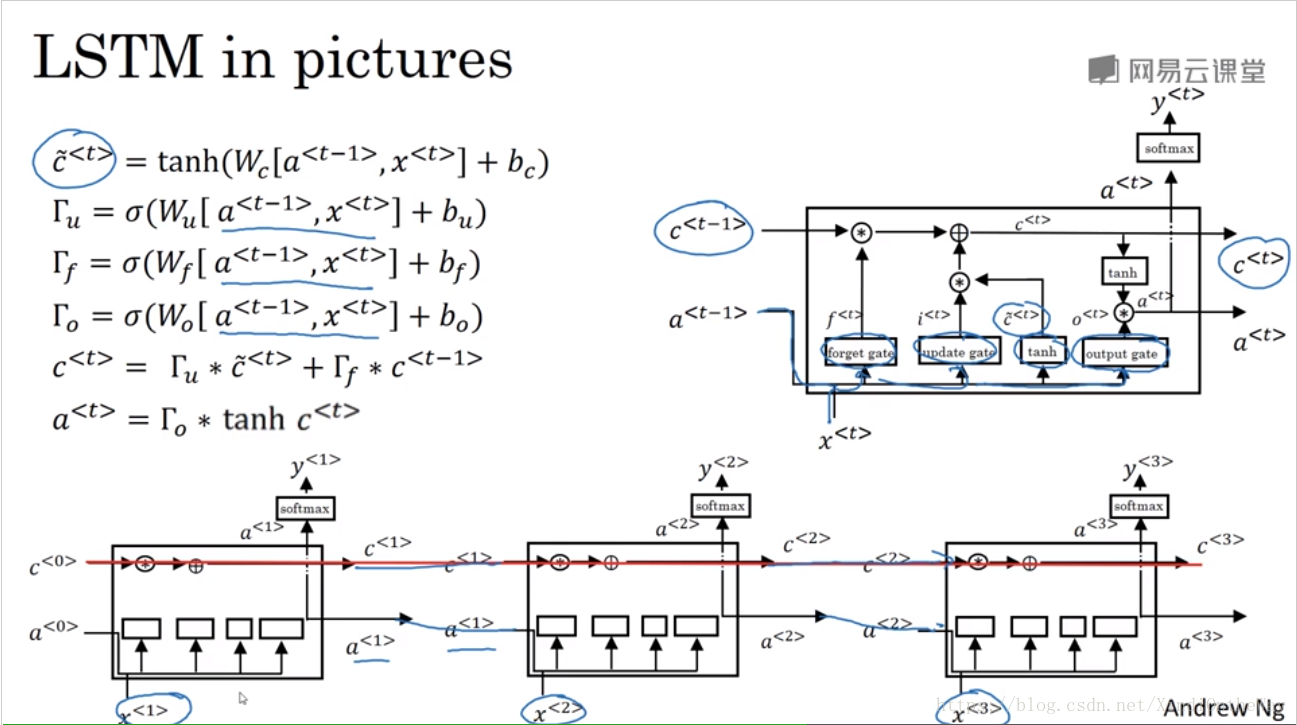
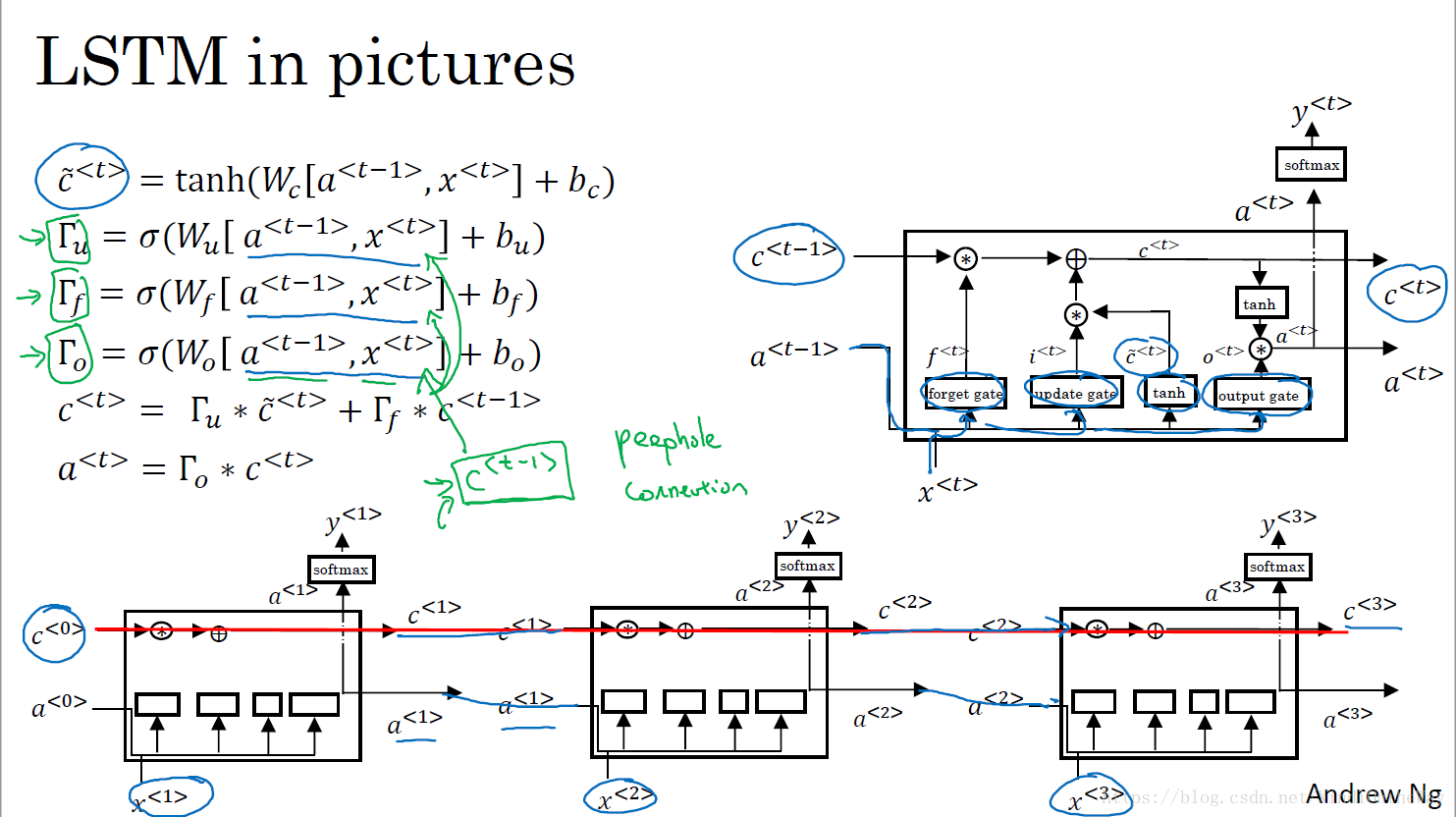
peephole connection:
在计算各个门的值时,不仅利用
,还会使用上一个记忆单元
的信息。
is used to affect the gate value as well