版权声明:本文为博主原创文章,未经博主允许不得转载。作为分享主义者(sharism),本人所有互联网发布的图文均采用知识共享署名 4.0 国际许可协议(https://creativecommons.org/licenses/by/4.0/)进行许可。转载请保留作者信息并注明作者Jie Qiao专栏:http://blog.csdn.net/a358463121。商业使用请联系作者。 https://blog.csdn.net/a358463121/article/details/79421476
很多时候,我们都要最大化似然度来求得一个参数
θ
的最优值。但是,很多时候,当我们的模型中存在隐变量的时候(比如,一个词所属的主题,聚类问题中样本的类别, etc.),我们的似然度是很难求的。下面是该似然度的式子,其中z表示不可观测的变量,x表示可观测的变量,由于z是不可观测的,所以,要求似然度,我们必须要对z求和或求积分(连续的时候求积分,离散的时候求和)。
L(θ)=∑i=1Nlogp(xi|θ)=∑i=1Nlog[∑zip(xi,zi|θ)]
可以看到上面的这个式子,如果不存在隐变量的话,那么那个log是直接作用与p的,如果p恰好是指数族分布,那么这个似然度就非常好求,但是有隐变量的时候,log被一个
∑z
给截断的,这就使得这个式子变得很难优化。
这个问题的关键在于,
logp(xi|θ)
很难优化,但是
p(xi,zi|θ)
却很好优化,比如说聚类的时候,你提前知道所有样本的类别了,那你计算每个类别的中心距离就太简单了,但是要优化
p(xi,zi|θ)
的前提是,你要看得到隐变量的取值才行啊,然而隐变量是看不到的。EM算法通过一个巧妙的构造,让
p(xi,zi|θ)
和似然度
p(xi|θ)
的下界联系起来,这是我们只要优化下界就能代替优化似然度本身。
接下来我们看一下对于单个样本
p(xi)
似然度的下界是什么东西。在这里我们引入了
zi
的分布
qi(zi)
logp(xi|θ)=logp(xi,zi)−logp(zi|xi)=log(p(xi,zi)qi(zi))−log(p(zi|xi)qi(zi))=logp(xi,zi)−logqi(zi)−log(p(zi|xi)qi(zi))=∫qi(zi)logp(xi,zi)dz−∫qi(zi)logq(zi)dz−∫qi(zi)log(p(zi|xi)qi(zi))dz(两边同时对z求期望)=Ezi(logp(xi,zi))−H(qi)ELOBi+KL(qi(zi)||p(zi|xi))
我们知道
KL(q(zi)||p(zi|xi))⩾0
,所以这个似然度一定有
logp(xi)⩾Ezi(logp(xi,zi))−H(qi)
可以看到对数似然度被分解成了两部分,一个是evidence lower bound(ELOB),似然度的下界,另一个是KL距离,不管q是什么分布,这两部分加起来肯定是一样的。
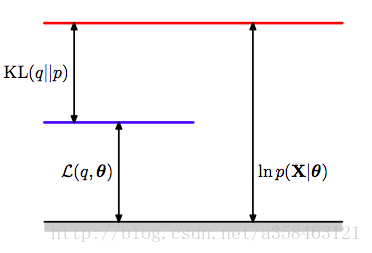
图中的L是我们的ELOB。
也就是说,只要我们令KL距离为0,此时
q(z)=p(z|x)
,那么ELOB就等于似然度的值了。这就意味着我们最大化
θ
的时候,不再需要对
logp(x|θ)
做,只需要找到
θ
使得这个ELOB最大不就相当于在“最大化我们的似然度”吗。而最大化这个ELOB太简单了,在这里
H(q)
是q的熵,与
θ
无关只与分布q有关,所以不用管。于是我们把
q(z)=p(z|x)
代入到ELOB中得到
ELOBi=Ezi(logp(xi,zi))+const=∫qi(zi)logp(xi,zi)dz+const=∫p(zi|xi)logp(xi,zi)dz+const=∑zip(zi|xi)logp(xi,zi)+const(如果z是离散的)
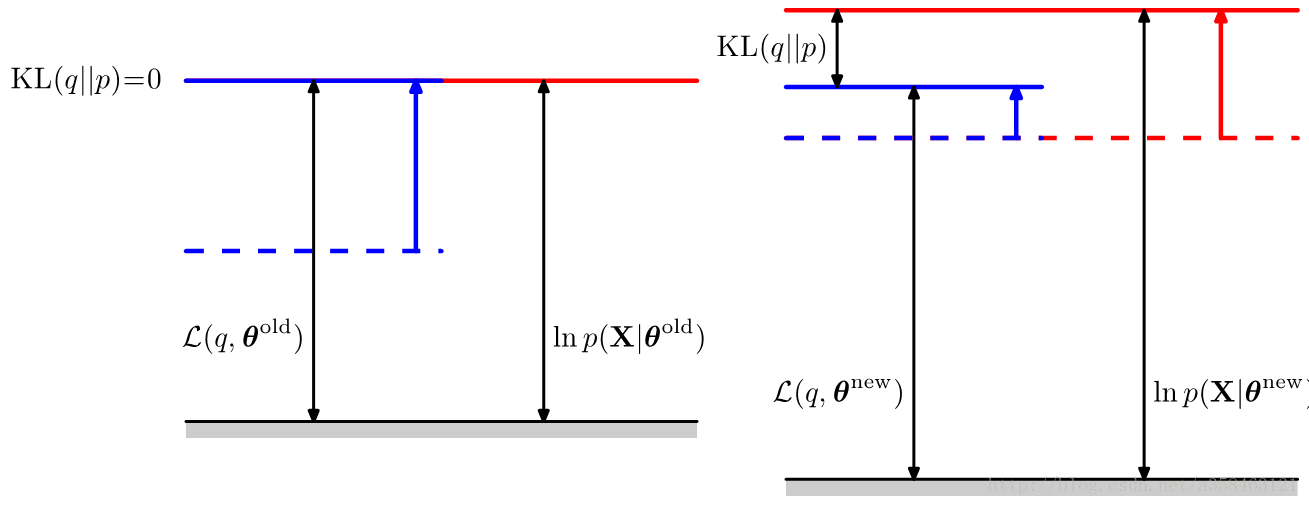
EM算法,示意图,E步,把KL设为0,蓝色的线往上移,使得ELOB=似然度,M步,最大化ELOB,使得似然度增大,红色的线往上移,然后我们不断重复直到收敛。
考虑所有样本,正式的EM框架:
E步:把
qi(zi)=p(zi|xi)
代入到下界中,再把常数项剔除,
Q(θ,θt−1)=∑i=1N∑zip(zi|xi,θt−1)logp(xi,zi,θ)=∑i=1NE[logp(xi,zi|θ)|xi,θt−1]
M步:最大化下界ELOB
θt=argmaxθQ(θ,θt−1)
M步2:我们还可以做MAP估计,只需要在Q加上参数的对数先验就可以轻松完成,E步没有任何变化
θt=argmaxθQ(θ,θt−1)+logp(θ)
在MAP估计的时候,不仅需要考虑下界的最大化,还需要考虑先验对参数的影响。
作为分享主义者(sharism),本人所有互联网发布的图文均遵从CC版权,转载请保留作者信息并注明作者a358463121专栏:http://blog.csdn.net/a358463121,如果涉及源代码请注明GitHub地址:https://github.com/358463121/。商业使用请联系作者。