对于给定的训练样本
{xi,di}i=1N,最小二乘估计的正则化代价函数由下式定义:
ε(w)=21i=1∑N(di−wTXi)2+21λ∣∣w∣∣2
正则化项以w的形式简单地定义:
∣∣DF∣∣2=∣∣W∣∣2=WTW
关于权值向量
W^都正则化解的预期响应d的表达式有:
W^=(Rxx+λI)−1rdx
Rxx=i=1∑Nj=1∑NXiXjT
rdx=i=1∑NXidi
以训练样本
{xi,di}i=1N的形式重申
W^,有:
W^=(XTX+λI)−1XTd
X为输入数据矩阵
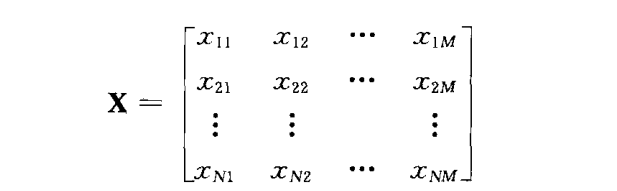
把最小二乘估计看成一个"核机器",把它的核表示成内积的形式:
k(X,Xi)=<X,Xi>=XTXi,i=1,2,...,N
定义正则化最小二乘估计表示逼近函数:
Fλ(X)=i=1∑Naik(X,Xi)