Noise2Noise: Learning Image Restoration without Clean Data
ICML 2018
1 Introduction
基于 corrupted or incomplete measurements 进行信号重构是一个很重要的课题。今年随着深度学习快速发展,自然也将CNN网络引入来解决图像去噪问题。 training a regression model(一个CNN网络),一般来说需要大量的训练图像: corrupted inputs 及对应的 clean targets, minimizing the empirical risk
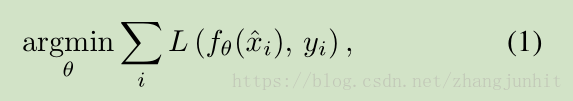
这个思路主要的问题是: obtaining clean training targets is often difficult or tedious,真值图像很难获取
这里我们提出一个方法不需要 clean training targets ,只需要 corrupted inputs
we observe that we can often learn to turn bad images into good images by only looking at bad images, and do this just as well – sometimes even better – as if we were using clean examples
2 Theoretical Background
假定对于一个房间的温度,我们有一组不可靠的测量数据(y1,y2,…)。估计房间温度这个未知真值一个常用的策略是,寻找一个数值 z,在一定损失函数下 满足最小平均偏差
A common strategy for estimating the true unknown temperature is to find a number z that has the smallest average deviation from the measurements according to some loss function L:
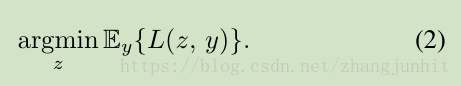
对于 L2损失函数,最小值位于观测值的 算数均值,对于 L1损失函数,最小值位于观测值的中值, its optimum at the median of the observations
The general class of deviation-minimizing estimators are known as M-estimators
From a statistical viewpoint, summary estimation using these common loss functions can be seen as ML estimation by interpreting the loss function as the negative log likelihood.
从统计角度来看,使用这些常见的损失函数进行求和估计可以被看作是一个 ML估计(最大相似估计),用 the loss function as the negative log likelihood
Training neural network regressors is a generalization of this point estimation procedure
训练一个神经网络回归器可以看作是 点估计流程的扩展。对于一组输入输出数据对的典型学习任务的形式如下,其中网络函数有 theta 参数化表示
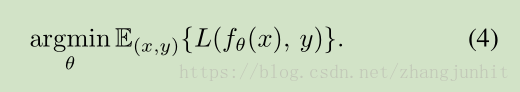
实际上,如果我们去除对输入数据的依赖性,使用一个简单的函数来表示一个学习到的标量输出,那么任务退化为 公式(2)。相反,完整训练任务可以分解为对每个训练样本进行最小化问题,公式(4)等同于下面的公式:
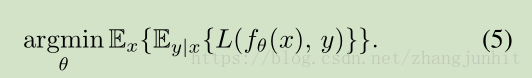
理论上,网络最小化这个损失函数可以通过如下实现:对每个输入样本进行独立的点估计问题求解。所以潜在损失函数的特性被神经网络学习继承了。
上面主要讨论的是 点估计问题和 神经网络学习之间的内在联系。
对一组有限的输入输出数据对使用 公式(1)进行常规的回归器学习,这隐藏了一个微妙的点:这个学习过程隐含的是一对一的映射学习,但是实际的映射是 一对多的问题。例如在超分辨问题中,一个低分辨率的图像 x 可以有 很多不同的 高分辨率图像 y 表示,因为边缘和纹理的一些关键点和方向信息的丢失。 换句话说,p(y|x) 是自然图像与低分辨率图像 x 的高复杂分布。 使用 低分辨率图像和高分辨率图像对 ,基于 L2 损失函数 训练一个神经网络回归器, 网络最终的输出是 所有可能的解释的平均,这就导致网络预测的空间模糊化。 已经有大量工作针对这个显著的 tendency 展开,例如使用学习到的 discriminator functions 作为损失函数。
我们的观察是对于特定的问题,这个 tendency 有一个意想不到的的 好处。
A trivial, and, at first sight, useless, property of L2 minimization is that on expectation, the estimate remains unchanged if we replace the targets with random numbers whose expectations match the targets
输入图像可以被随机数替换,估计的结果不会变,只要这个随机数的期望和 输入图像的期望是一样的。
显而易见, 公式(3)是成立的,无论 y 是从哪个特定分布提取的。 所以公式(5)中 最优网络参数 theta 是保持不变的,只要输入分布具有相同的 条件期望值
This implies that we can, in principle, corrupt the training targets of a neural network with zero-mean noise without changing what the network learns.
网络的输入噪声符合 zero-mean , 网络学习到的输出是不变的。
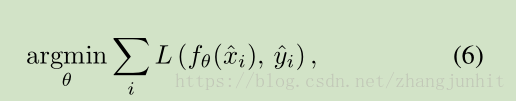
基于噪声输入数据的优化公式如上图所示。
在许多图像修复问题中, 含有噪声的输入数据的期望值是 clean target,这是我们希望得到的无噪声的真值数据。由上面的分析我们可以得出的结论是:我们只需要噪声数据可以恢复出无噪声的数据。
3 Practical Experiments
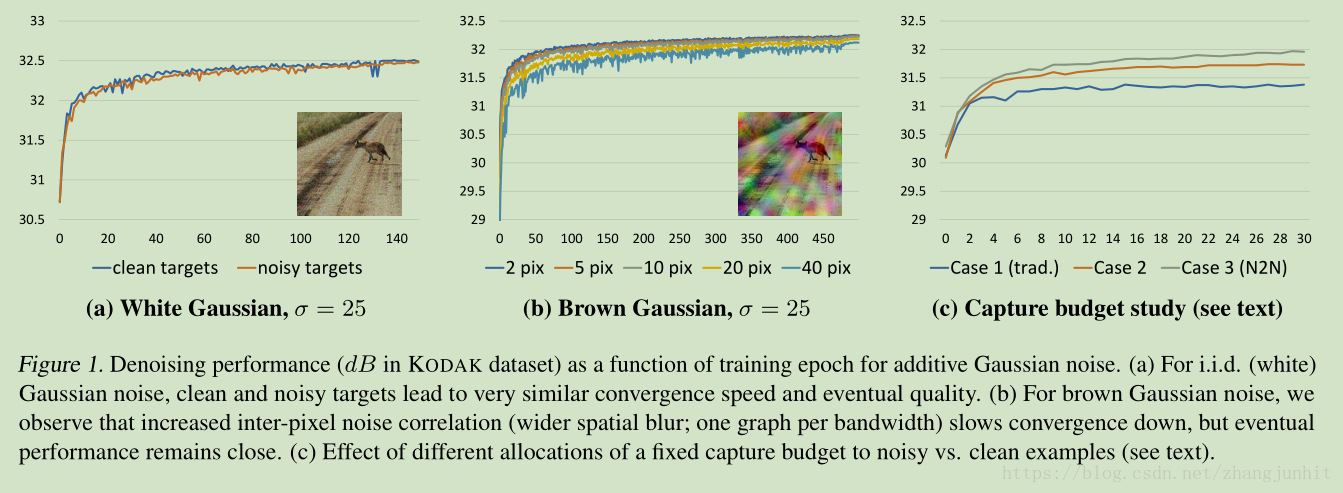
接下来我们通过实验来验证我们上面得出的结论,首先从简单的噪声分布开始,Gaussian, Poisson, Bernoulli,然后我们分析了 Monte Carlo image synthesis noise,最后我们对 MRI 图像进行分析





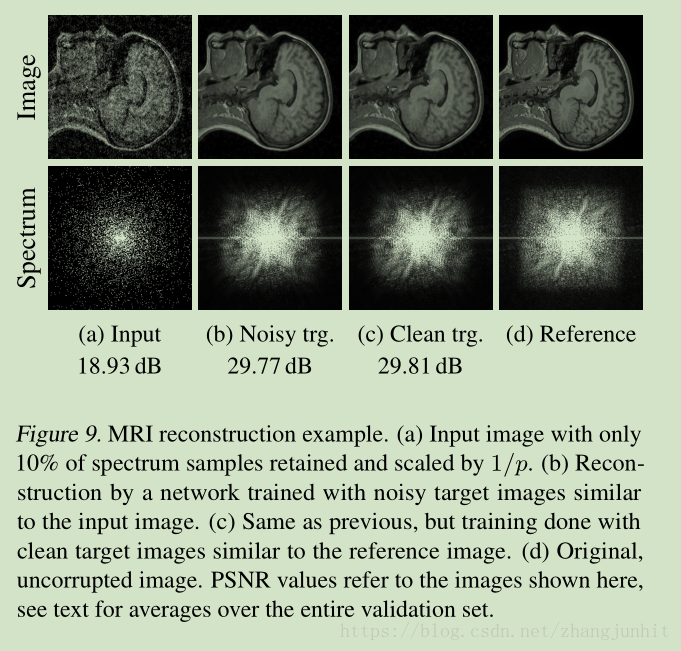
MRI reconstruction example
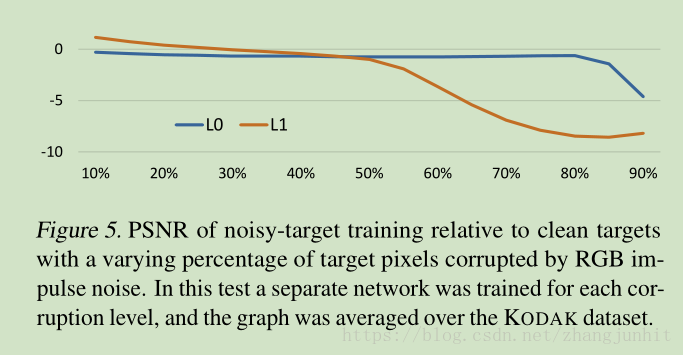
11