[判别学习]Discriminative Transfer Learning for General Image Restoration 文章翻译与分析
文章翻译与分析)
本文来自
Xiao, Lei & Heide, Felix & Heidrich, Wolfgang & Schölkopf, Bernhard & Hirsch, Michael. (2017). Discriminative Transfer Learning for General Image Restoration. IEEE Transactions on Image Processing. PP. 10.1109/TIP.2018.2831925.
本文较长,可以直接跳到 related work
Abstract
Recently, several discriminative learning approaches have been proposed for effective image restoration, achieving convincing trade-off between image quality and computational efficiency. However, these methods require separate training for each restoration task (e.g., denoising, deblurring, demosaicing) and problem condition (e.g., noise level of input images). This makes it time-consuming and difficult to encompass all tasks and conditions during training. In this paper, we propose a discriminative transfer learning method that incorporates formal proximal optimization and discriminative learning for general image restoration. The method requires a single-pass training and allows for reuse across various problems and conditions while achieving an efficiency comparable to previous discriminative approaches. Furthermore, after being trained, our model can be easily transferred to new likelihood terms to solve untrained tasks, or be combined with existing priors to further improve image restoration quality.
近年来,人们提出了几种判别学习方法来进行有效的图像恢复,从而在图像质量和计算效率之间取得令人信服的平衡。然而,这些方法需要对每个恢复任务(如去噪、去模糊、去噪)和问题条件(如输入图像的噪声水平)进行单独的训练。这就使得在训练中包含所有的任务和条件既耗时又困难。
本文提出了一种结合常规的近端优化和判别学习的判别转移学习方法,用于一般图像的恢复。
该方法需要单次训练,允许跨各种问题和条件进行重用,与以前的判别方法相比更加有效率。此外,经过训练后,我们的模型可以很容易地转换成新的似然项来解决未经训练的任务,或者与现有的先验相结合来进一步提高图像的恢复质量。
Introduction
Low-level vision problems, such as denoising, deconvolution and demosaicing, have to be addressed as part of most imaging and vision systems. Although a large body of work covers these classical problems, low-level vision is still a very active area. The reason is that, from a Bayesian perspective, solving them as statistical estimation problems does not only rely on models for the likelihood (i.e. the reconstruction task), but also on natural image priors as a key component.
Low-Level的视觉问题,如去噪、反卷积和去噪,必须作为大多数成像和视觉系统的一部分加以解决。虽然有大量的工作涉及这些经典问题,但Low-Level视觉仍然是一个非常活跃的领域。原因是,从贝叶斯的角度来看,将它们作为统计估计问题来解决,不仅依赖于似然模型(即重建任务),还依赖于自然图像先验作为关键成分。
A variety of models for natural image statistics have been explored in the past. Traditionally, models for gradient statistics [27, 17], including total-variation, have been a popular choice. Another line of works explores patch-based image statistics, either as per-patch sparse model [11, 35] or modeling non-local similarity between patches [9, 10, 13]. These prior models are general in the sense that they can be applied for various likelihoods, with the image formation and noise setting as parameters. However, the resulting optimization problems are prohibitively expensive, rendering them impractical for many real-time tasks especially on mobile platforms.
在过去,人们探索了各种各样的自然图像统计模型。传统上,包括全变差(total-variation)在内的梯度统计模型[27,17]一直是流行的选择。另一项工作是研究基于patch的图像统计,可以是每个patch的稀疏模型[11,35],也可以是对patch之间的非局部相似性建模[9,10,13]。这些先前的模型是通用的,因为它们可以应用于各种可能性,以图像形成和噪声设置为参数。然而,由此产生的优化问题代价高昂,对于许多实时任务来说是不切实际的,尤其是在移动平台上。
Recently, a number of works [29, 8] have addressed this issue by truncating the iterative optimization and learning discriminative image priors, tailored to a specific reconstruction task (likelihood) and optimization approach.
While these methods allow to trade-off quality with the computational budget for a given application, the learned models are highly specialized to the image formation model and noise parameters, in contrast to optimization-based approaches. Since each individual problem instantiation requires costly learning and storing of the model coefficients, current proposals for learned models are impractical for vision applications with dynamically changing (often continuous) parameters. This is a common scenario in most realworld vision settings, as well as applications in engineering and scientific imaging that rely on the ability to rapidly prototype methods.
最近,许多文献[29,8]通过截断迭代优化和学习有区别的图像先验,针对特定的重建任务(似然)和优化方法,解决了这一问题。
虽然这些方法允许在给定应用程序的计算预算中权衡质量,但与基于优化的方法相比,所学习的模型高度专门化于图像形成模型和噪声参数。由于每个单独的问题实例化都需要昂贵的模型系数的学习和存储,因此对于具有动态变化(通常是连续的)参数的视觉应用程序来说,当前对学习模型的建议是不切实际的。这对于大多数现实世界的视觉设置是一个常见的场景,以及在工程和科学成像的应用,依赖于快速原型方法的能力。
In this paper, we combine discriminative learning techniques with formal proximal optimization methods to learn generic models that can be truly transferred across problem domains while achieving comparable efficiency as previous discriminative approaches. Using proximal optimization methods [12, 23, 3] allows us to decouple the likelihood and prior which is key to learn such shared models. It also means that we can rely on well-researched physically motivated models for the likelihood, while learning priors from example data. We verify our technique using the same model for a variety of diverse low-level image reconstruction tasks and problem conditions, demonstrating the effectiveness and versatility of our approach. After training, our approach benefits from the proximal splitting techniques, and can be naturally transferred to new likelihood terms for untrained restoration tasks, or it can be combined with existing state-of-the-art priors to further improve the reconstruction quality. This is impossible with previous discriminative methods. In particular, we make the following contributions:
• We propose a discriminative transfer learning technique for general image restoration. It requires a single-pass training and transfers across different restoration tasks and problem conditions.
• We show that our approach is general by demonstrating its robustness for diverse low-level problems, such as denoising, deconvolution, inpainting, and for varying noise settings.
• We show that, while being general, our method achieves comparable computational efficiency as previous discriminative approaches, making it suitable for processing high-resolution images on mobile imaging systems.
• We show that our method can naturally be combined with existing likelihood terms and priors after being trained. This allows our method to process untrained restoration tasks and take advantage of previous successful work on image priors (e.g., color and non-local similarity priors)
在本文中,我们将判别学习技术与形式近似优化方法相结合,以学习能够真正跨问题域转移的通用模型,同时获得与以前的判别方法相当的效率。使用近似优化方法[12,23,3]允许我们解耦似然和先验,这是学习此类共享模型的关键。这也意味着,我们可以依靠研究充分的物理动机模型来获得可能性,同时从示例数据中学习先验。我们验证了我们的技术使用相同的模型,用于各种不同的低水平图像重建任务和问题条件,证明了我们的方法的有效性和通用性。经过训练,我们的方法受益于近端分割技术,可以很自然地转化为新的似然项,用于未经训练的恢复任务,也可以与现有的最先进的先验相结合,进一步提高重建质量。这是不可能的与以前的区别方法。我们作出以下贡献:
•提出了一种用于一般图像恢复的判别转移学习方法。它需要单次训练,并在不同的恢复任务和问题条件之间进行转换。
•我们展示了我们的方法是通用的,通过展示它对各种低级问题的鲁棒性,如去噪、反卷积、图像修补和各种噪声设置。
•我们证明,虽然我们的方法是通用的,但与以前的判别方法相比,我们的计算效率是类似的,这使得它适用于处理移动成像系统上的高分辨率图像。
•我们证明,经过训练,我们的方法可以很自然地与现有的似然项和先验相结合。这使得我们的方法可以处理未经训练的恢复任务,并利用以前在图像先验(例如,颜色和非局部相似先验)上的成功工作。
Related Work
Image restoration aims at computationally enhancing the quality of images by undoing the adverse effects of image degradation such as noise and blur. As a key area of image and signal processing it is an extremely well studied problem and a plethora of methods exists, see for example [22] for a recent survey. Through the successful application of machine learning and data-driven approaches, image restoration has seen revived interest and much progress in recent years. Broadly speaking, recently proposed methods can be grouped into three classes: classical approaches that make no explicit use of machine learning, generative approaches that aim at probabilistic models of undegraded natural images and discriminative approaches that try to learn a direct mapping from degraded to clean images. Unlike classical methods, methods belonging to the latter two classes depend on the availability of training data.
图像恢复的目的是通过消除图像退化的负面影响,如噪声和模糊,从而在计算上提高图像的质量。作为图像和信号处理的一个关键领域,它是一个研究非常充分的问题,存在大量的方法,如[22]最近的调查。近年来,随着机器学习和数据驱动方法的成功应用,图像恢复引起了人们的兴趣,并取得了很大的进展。广义地说,最近提出的方法可以分为三类:不明确使用机器学习的经典方法,针对未退化自然图像概率模型的生成方法,以及试图学习从退化图像到清晰图像的直接映射的鉴别方法。与经典方法不同,属于后两个类的方法依赖于训练数据的可用性。
Classical models focus on local image statistics and aim at maintaining edges. Examples include total variation [27], bilateral filtering [32] and anisotropic diffusion models [34]. More recent methods exploit the non-local statistics of images [1, 9, 21, 10, 13, 31]. In particular the highly successful BM3D method [9] searches for similar patches within the same image and combines them through a collaborative filtering step.
(1)经典模型侧重于局部图像统计,以保持边缘为目标。
例如全变差[27]、双向滤波[32]和各向异性扩散模型[34]。最近的方法利用图像的非局部统计[1,9,21,10,13,31]。特别是非常成功的BM3D方法[9]在相同的图像中搜索相似的补丁,并通过一个协作过滤步骤将它们组合在一起。
Generative learning models seek to learn probabilistic models of undegraded natural images. A simple, yet powerful subclass include models that approximate the sparse gradient distribution of natural images [19, 17, 18]. More expressive generative models include the fields of experts (FoE) model [26], KSVD [11] and the EPLL model [35]. While both FoE and KVSD learn a set of filters whose responses are assumed to be sparse, EPLL models natural images through Gaussian Mixture Models. All of these models have in common that they are agnostic to the image restoration task, i.e. they are transferable to any image degradation and can be combined in a modular fashion with any likelihood and additional priors at test time.
(2)生成式学习模型试图学习未退化的自然图像的概率模型。
一个简单而强大的子类包括近似自然图像的稀疏梯度分布的模型[19,17,18]。更具表现力的生成模型包括fields of experts (FoE)模型[26]、KSVD[11]和EPLL模型[35]。FoE和KVSD都学习了一组假设响应为稀疏的滤波器,而EPLL通过高斯混合模型对自然图像进行建模。所有这些模型的共同之处在于,它们对图像恢复任务是不可知的,也就是说,它们可以转移到任何图像退化中,并且可以在测试时以模块化的方式与任何可能性和附加先验相结合。
Discriminative learning models have recently become increasingly popular for image restoration due to their attractive tradeoff between high image restoration quality and efficiency at test time. Methods include trainable random field models such as cascaded shrinkage fields (CSF) [29], regression tree fields (RTF) [16], trainable nonlinear reaction diffusion (TRD) models [8], as well as deep convolutional networks [15] and other multi-layer perceptrons [4]. Discriminative approaches owe their computational efficiency at run-time to a particular feed-forward structure whose trainable parameters are optimized for a particulartask during training. Those learned parameters are then kept fixed at test-time resulting in a fixed computational cost. On the downside, discriminative models do not generalize across tasks and typically necessitate separate feed-forward architectures and separate training for each restoration task (denoising, demosaicing, deblurring, etc.) as well as every possible image degradation (noise level, Bayer pattern, blur kernel, etc.).
(3)由于判别学习模型在图像恢复质量和测试效率之间具有良好的折衷性,近年来在图像恢复领域得到了广泛的应用。
方法包括可训练的随机场模型,如级联收缩场(CSF)[29]、回归树场(RTF)[16]、可训练的非线性反应扩散(TRD)模型[8]、深度卷积网络[15]等多层感知机[4]。判别方法在运行时的计算效率取决于特定的前馈结构,该结构的可训练参数在训练过程中针对特定的任务进行了优化。这些学习参数在测试时保持不变,从而产生固定的计算成本。
In this work, we propose the discriminative transfer learning technique that is able to combine the strengths of both generative and discriminative models: it maintains the flexibility of generative models, but at the same time enjoys the computational efficiency of discriminative models.
While in spirit our approach is akin to the recently proposed method of Rosenbaum and Weiss [25], who equipped the successful EPLL model with a discriminative prediction step, the key idea in our approach is to use proximal optimization techniques that allow the decoupling of likelihood and prior and therewith share the full advantages of a Bayesian generative modeling approach. Table 1 summarizes the properties of the most prominent state-of-the-art methods and puts our own proposed approach into perspective.
在这项工作中,我们提出了判别转移学习技术,它能够结合生成模型和判别模型的优点:既保持生成模型的灵活性,又能享受到判别模型的计算效率。
我们的方法类似于最近提议Rosenbaum和维斯[25]的方法,成功的EPLL模型装备有识别力的预测步骤,
我们的方法中关键的想法是使用近端优化技术,解耦似然和先验,带来完整的贝叶斯生成模型方法的优势。
表1总结了最著名的、最先进的方法的特性,并对我们自己提出的方法进行了分析。
分析最先进的方法。表中“可转移”表示模型可用于不同的恢复任务和问题条件;“模块化”意味着该方法可以在测试时与其他现有的先验相结合。

Proposed method
1.Diversity of data likelihood
The seminal work of fields-of-experts (FoE) [26] generalizes the form of filter response based regularizers in the objective function given in Eq. 1. The vectors b and x represent the observed and latent (desired) image respectively, the matrix A is the sensing operator, Fi represents 2D convolution with filter fi, and φi represents the penalty function on corresponding filter responses Fix. The positive scalar λ controls the relative weight between the data fidelity (likelihood) and the regularization term.
Fields-of-experts(FoE)[26]的开创性工作概括了在Eq. 1给出的目标函数中基于滤波器响应的正则化器的形式。向量b和x代表观察到的和潜在的(理想的)图像分别矩阵A是感知算子 过滤器Fi代表二维卷积,φi代表相应的滤波器响应修正的罚函数。正标量λ控制之间的相对重量数据保真度(可能性)和正则化项。
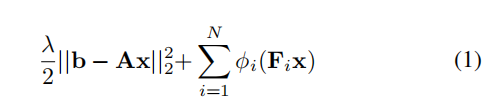
While there are various types of restoration tasks (e.g.,denoising, deblurring, demosaicing) and problem parameters (e.g., noise level of input images), each problem has its own sensing matrix A and optimal fidelity weight λ. For example, A is an identity matrix for denoising, a convolution operator for deblurring, a binary diagonal matrix for demosaicing, and a random matrix for compressive sensing [5]. λ depends on both the task and its parameters in order to produce the best quality results.
虽然有各种类型的修复任务(如去噪、去模糊,demosaicing)和问题参数(例如,输入图像的噪声水平),每个问题都有自己的传感矩阵和最优保真权重λ。例如,A是一个用于去噪的单位矩阵,一个用于去模糊的卷积运算符,一个用于去噪的二元对角矩阵,一个用于压缩感知[5]的随机矩阵。λ取决于任务及其参数以提供最好质量的结果。
The state-of-the-art discriminative learning methods (CSF[29], TRD[8]) derive an end-to-end feed-forward model from Eq. 1 for each specific restoration task, and train this model to map the degraded input images directly to the output. These methods have demonstrated a great tradeoff between high-quality and time-efficiency, however, as an inherent problem of the discriminative learning procedure, they require separate training for each restoration task and problem condition. Given the diversity of data likelihood of image restoration, this fundamental drawback of discriminative models makes it time-consuming and difficult to encompass all tasks and conditions during training.
目前最先进的判别学习方法(CSF[29], TRD[8])从Eq. 1中推导出每个具体恢复任务的端到端前馈模型,并训练该模型将退化的输入图像直接映射到输出。这些方法证明了在高质量和时间效率之间的巨大权衡,但是,作为区别学习过程的一个固有问题,它们需要对每个恢复任务和问题条件进行单独的训练。考虑到图像恢复的数据似然的多样性,判别模型的这一基本缺点使得训练过程中包含所有的任务和条件既耗时又困难。
2. Decoupling likelihood and prior
这段主要是建立模型、使用HQS算法,重点是使用new splitting tragedy,产生先验近端算子Prior proximal operator和数据近端算子Data proximal operator两个重要概念。


本文的new splitting tragedy:

3.Discriminative transfer learning
We observed that, while the data proximal operator in Eq. 4 is task-dependent because both the sensing matrix A and fidelity weight λ are problem-specific as explained in Sec. 3.1, the prior proximal-operator (i.e. zt-update step in Eq. 3) is independent of the original restoration tasks and problem conditions.
我们观察到,因为传感矩阵A和保真权重 λ 是特定的(解释在3.1节),数据近端算子Eq.4是任务依赖的,但是,Eq.3是独立于原始恢复任务和问题的条件的。
This leads to our main insight: Discriminative learned models can be made transferable by using them in place of the prior proximal operator, embedded in a proximal optimization algorithm. This allows us to generalize a single discriminative learned model to a very large class of problems, i.e. any linear inverse imaging problem, while simultaneously overcoming the need for problem-specific retraining. Moreover, it enables learning the task-dependent parameter λ in the data proximal operator for each problem in a single training pass, eliminating tedious hand-tuning at test time.
We also observed that, benefiting from our new splitting strategy, the prior proximal operator in Eq. 3 can be interpreted as a Gaussian denoiser on the intermediate image xtt 1 , since the least-squares consensus term is equivalent to a Gaussian denoising term. This inspires us to utilize existing discriminative models that have been successfully used for denoising (e.g. CSF, TRD).
这就引出了我们的主要观点:
通过使用不同的学习模型来代替先验近端算子(代替Eq.3,笔者注),嵌入到近似优化算法中,使其可转移。
这使我们能够将一个单一的区别学习模型推广到一个非常大的问题类别,即任何线性逆成像问题,同时克服了特定问题再培训的需要。此外,它使学习task-dependent参数λ在每个问题的数据近端操作符在一个训练,消除繁琐的手工调整测试时间。
我们还观察到,得益于我们新的分割策略,Eq. 3中的先验近端算子可以被解释为对中间图像 的高斯去噪,因为最小二乘一致项等价于高斯去噪项。这启发我们利用现有的已成功用于去噪的判别模型(如CSF、TRD)。
实际上,为了更新先验近端算子(更新
),只需要
和
即可。

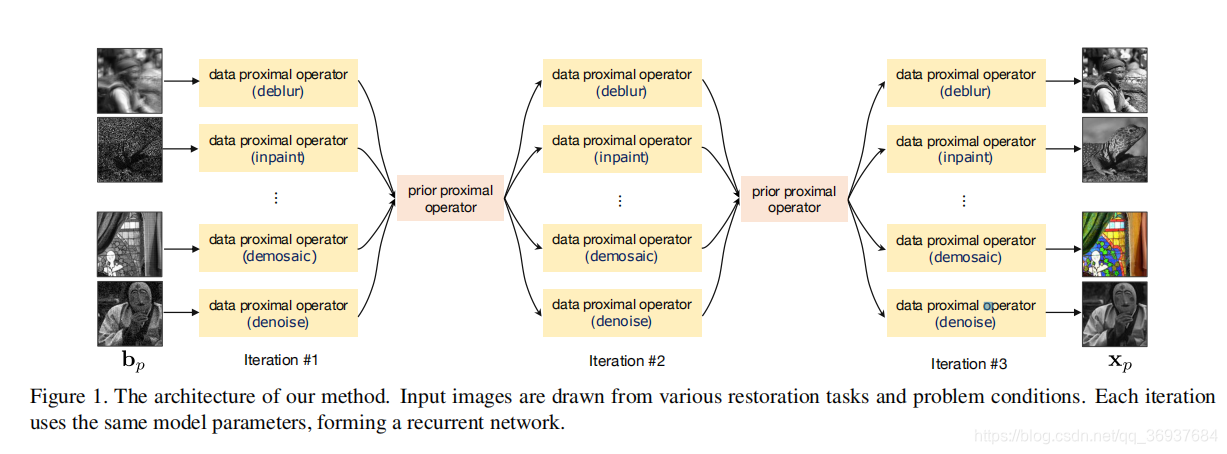
分析:就是用同一个先验近端算子由
更新
, 不同的数据近端算子 由
更新
来处理不同的任务。
每次迭代,不同任务的图像用各自的数据近端算子,共享相同的先验近端算子

Recurrent network. Note that in Fig. 1 each HQS iteration uses exactly the same model parameters, forming a recurrent network. This is in contrast to previous discriminative learning methods including CSF and TRD, which form feed-forward networks. Our recurrent network architecture maintains the convergence property of the proximal optimization algorithm (HQS), and is critical for our method to transfer between various tasks and problem conditions.
注意,在图1中,每个HQS迭代使用完全相同的模型参数,形成一个递归网络。这与之前形成前馈网络的CSF、TRD等判别学习方法形成对比。我们的递归网络架构保持了近似优化算法(HQS)的收敛性,并且对于我们的方法在不同任务和问题条件之间的转移是至关重要的。
接下来详细介绍如何更新共享的先验近端算子部分(也就是如何更新 )。注意,每次迭代 ,它的 更新了 个阶段:

先验近端算子部分,更新
需要的模型参数
,
,以及数据近端算子部分需要训练
,以及参数
的选取:

算法流程图分析:在每一次迭代(
),首先更新共享的先验近端算子部分:将上一次迭代的
传给
,然后使用公式6不断更新
,得到
。这里需要训练不同
的模型参数
,
。
然后使用最新得到的
去更新数据近端算子部分(对于不同的任务,在第四小节有不同的算法):得到新的
。这里要用到
和
。
是训练的,
是人工选取的。

4.Training
这段介绍不同任务下的数据近端算子是如何更新的(也就是算法流程图里第10步更新
):
(1)去噪任务更新

(2)解卷积任务更新
(用到了FFT,应该是为了避免当图像尺寸比较大的时候,
的尺寸也会比较大,直接做矩阵乘法运算较慢,内存大带来的一系列问题.)

然后是Loss

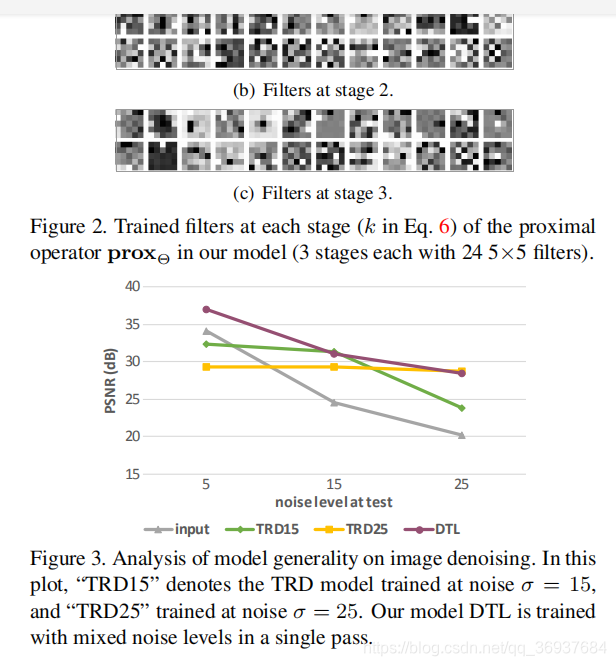
Results
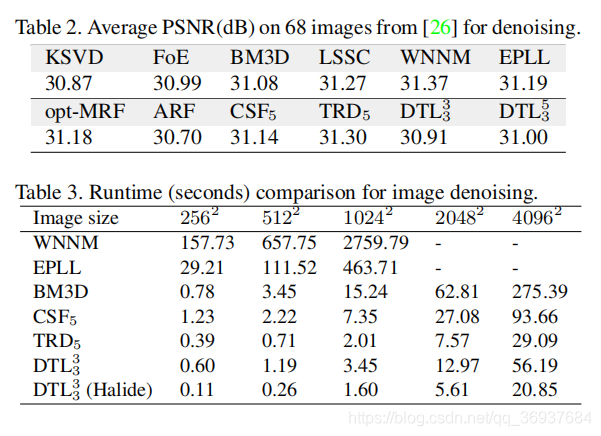
去噪
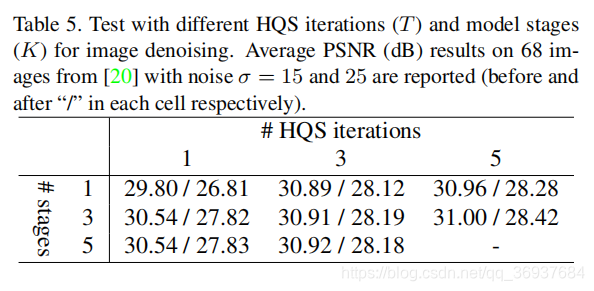
和
的选取


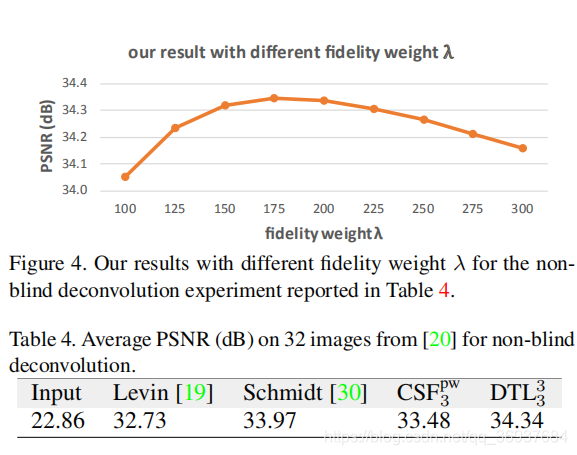
非盲解卷积

去噪+图像修补

