Path-Restore: Learning Network Path Selection for Image Restoration
概述
问题:图像恢复任务中计算资源过度消耗。
核心思想:一张图像中的不同位置具有不同的恢复难度,而简单区域可以为我们节约计算资源。
解决方法:一张图像中的不同位置要通过一个网络的不同路径恢复;路径搜索通过一个路径搜索器(pathfinder)解决。
效果:在realistic Darmstadt Noise Dataset(DND)上,与CBDNet相比,dpsnr高0.94 dB,速度快29%。(选择真实噪声是因为,真实噪声更容易spatially variant within an image)
思想很直接;方法比较简单;效果好。
待改进:
- 图像按\(63 \times 63\)分区域,比较死板。
- 引入RL,超参数较主观且无法end-to-end。
动机
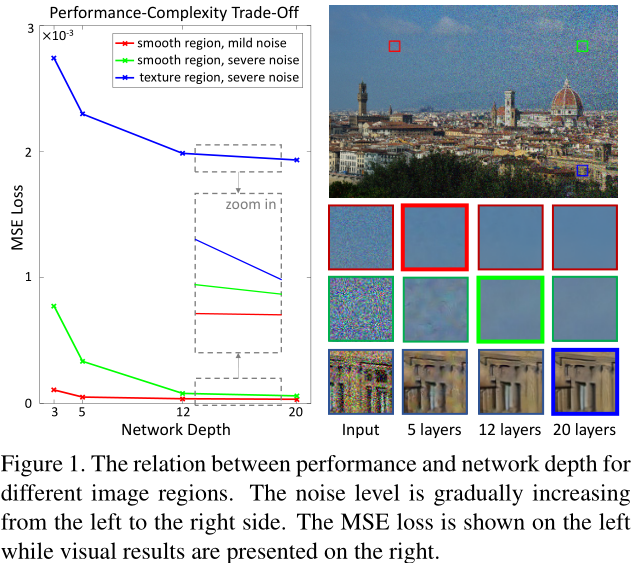
如图,红色区域噪声最小,5层CNN就能达到不错的效果,且继续增加层数并不会带来明显增益;绿色区域需要12层CNN效果较好,而蓝色区域需要更深的CNN。
因此,我们需要一个网络,能够为每一个区域选择合适的网络路径(optimal network path),基于该区域的失真和内容。
解决方法
本文提出的框架称为Path-Restore(PR)。PR由一个pathfinder和multi-path CNN组成。
在训练时,两个组分共同训练。由于路径选择是不可差分的,因此pathfinder借助强化学习方法训练。其reward既鼓励高性能,又鼓励低功耗。
主要有两大挑战:
- 该multi-path CNN能低功耗处理多种失真;
- reward设计合理。
为此,作者的解决方案是:
- 提出的CNN将dynamic block作为基本单元。一个block内有一个共享路径和多个不同计算复杂度的独立路径。
- 提出的reward是一个difficulty-regulated reward,即对于困难样本,reward侧重高性能。而困难程度由MSE loss来衡量(loss越大说明越难)。
总体
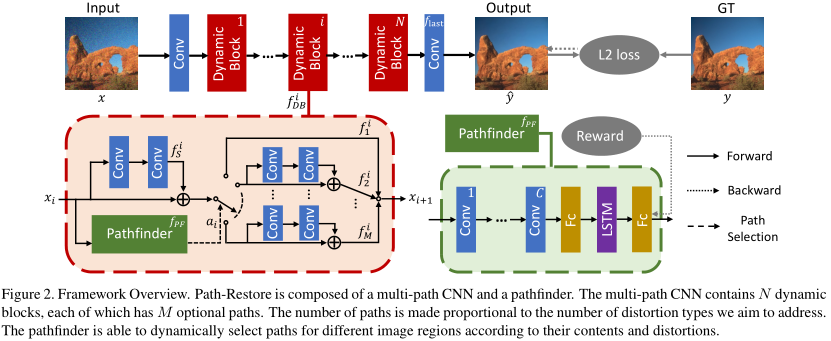
- 由\(N\)个dynamic block组成。
- 每个block内有\(M\)个可选路径。\(M\)与失真类型数量成比例。
- block内的路径选择由pathfinder控制。
- 除了第一个可选路径为bypass connection,其余路径都是一个residual block。
- 每个dynamic block的参数都是不同的,而所有pathfiner的参数是共享的。
设计思想:图像的不同区域/多种失真有共性也有特性。共性通过前面的shared path(\(f_S\))建模,特性通过后面的可选路径分别建模。
注:\(M\)的设置将在实验部分说明。
Pathfiner
- 设置LSTM,使得不同dynamic block可以相互联系、共同决策。
- Pathfinder的计算量不到总体的3%。
- 这种单刀多置机制不可差分,无法使用BP算法。因此,作者假设该序列化的路径选择问题为马尔科夫决策过程(MDP),并使用RL建模。
MDP
- 设第\(i\)个dynamic block的输入为\(x_i\),LSTM隐藏层状态为\(h_i\)。统称二者为该block的状态\(s_i = \{x_i, h_i\}\)。
- 给定状态\(s_i\),pathfinder就会输出路径决策\(a_i\)。其分布可以表示为\(\pi(a|s_i)\)。
- 在训练阶段,我们从该分布中采样:\(a_i \sim \pi(a|s_i)\);在测试阶段,我们取概率最大的采样:\(a_i = \arg\max_a \pi(a | x_i)\)。
Difficulty-regulated reward
第\(i\)个dynamic block的reward定义为:
\[ r_i = \begin{cases} -p (1 - I_{\{1\}}(a_i)),\quad 1 \le i <N,\\ -p (1 - I_{\{1\}}(a_i)) + d(- \Delta L_2),\quad i=N. \end{cases} \]
- \(p\)是用来惩罚选择复杂路径的系数,\(I\)是示性函数。显然,只有当\(a_i = 1\)时,该惩罚才为0。
- 前\(N-1\)个block都只考虑计算复杂度,只有第\(N\)个block考虑增强难度。原因如下。
其中\(d(\cdot)\)定义如下:
\[ d = \begin{cases} L_d / L_0,\quad 0 \le L_d \le L_0,\\ 1,\quad L_d \ge L_0, \end{cases} \]
其中\(L_d\)是定义的损失函数的输出,\(L_0\)是一个阈值。当损失大于阈值时,其输出就是1;否则,其输出为二者比值。\(L_d\)可以定义为MSE或VGG loss等。
当\(L_d\)趋于0时,说明当前图像区域比较容易增强。此时\(d\)也较小。因此,\(r_i\)受计算复杂度的影响相对更大。
这里出现了矛盾。\(d(-\Delta L_2)\)想表达PSNR增益,但\(d(\cdot)\)只考虑当前损失\(L_d\)。
训练
由于RL的加入,整体过程无法end-to-end。分两步:
- 首先训练multi-path CNN,其路径选择策略是随机的。
- 同时训练multi-path CNN和pathfinder。
第一步训练的损失由两部分组成:
\[ L_1 = \Vert y - \hat{y} \Vert^2 + \alpha \sum_{i=1}^N \Vert y - f_{\text{last}}(x_i) \Vert^2 \]
解释一下第二项。\(f_{\text{last}}(x_i)\)是第\(i\)个block的输出。这相当于一个deep supervision,让每一个block的输出都受到监督。作者声称,若没有第二项损失,每个block的输出都迥然不同,使得后续pathfinder难以学习。
接下来是第二步训练。Multi-path CNN的损失函数仍然是上式,但\(\alpha = 0\),即没有连续性输出约束。RL训练方式如下:

- 增量\(\Delta \theta\)是在\(N\)个block上求和得到的,并对\(K\)张图像样本取平均。
- \(b^{(k)}\)是一个用来降低梯度方差、稳定训练的基准。确定方法是:当所有block都走bypass时的\(\Delta \theta\)值。
减一个常数没法降低方差吧。类似于去中心化的效果,让数值整体更小。
实验和效果
首先网络结构中有三个重要超参数:dynamic block的数目\(N\),可选路径数目\(M\)和pathfinder内的卷积层数目\(C\)。作者做法很简单,说是在验证集上选择的:
These parameters are chosen empirically on the validation set for good performance and also for fair comparison with baseline methods.
很重要的一点:图像区域是按\(63 \times 63\)划分的,步长是53。
关于路径选择,作者选择可视化展示:

上图是均匀噪声。可见,长路径集中在复杂区域。下图是spatially variant噪声,且从左到右线性增长。可见从左到右路径也大致上越来越长。
其余略。