Python Spark RDD
RDD(Resilient Distributed Dataset)弹性分布式数据集是Spark的核心,RDD能与其他系统兼容,可以导入外部存储系统的数据集,例如HDFS、HBase或其他Hadoop数据源。
RDD的三种基本运算
- transformation“转换”运算:RDD执行“转换”运算会产生另外一个RDD;RDD具有lazy特性,“转换”运算并不会立刻执行,等到执行“动作”运算才实际执行
- action“动作”运算:RDD执行“动作”运算后不会产生另一个RDD,而是产生数值,数组或写入文件系统;“动作”运算会立刻执行,并且连同之前的“转换”运算一起执行。
- persistence“持久化”运算:对于会重复使用的RDD,可以将RDD“持久化”在内存中作为后续使用,以提高执行性能。
Lineage机制具备容错的特性
- RDD本身具有Lineage机制,记录每个RDD与其父代RDD之间的关联,还会记录通过什么操作才由父代RDD得到该RDD信息。
- RDD本身的immutable(不变性),加上Lineage机制,使得Spark具备容错的特性。如果某节点的机器出现故障,那么存储于该节点的RDD损毁后就会重新执行一连串“转换”命令,产生新的输出数据,以避免因为特定节点的故障而造成整个系统无法运行的问题。
基于IPython Notebook 进行基本的Spark RDD运算
首先,终端切换ipynotebook工作目录
cd ~/pythonwork/ipynotebook
运行IPython Notebook 使用Spark
PYSPARK_DRIVER_PYTHON=ipython PYSPARK_DRIVER_PYTHON_OPTS="notebook" pyspark
打开IPython Notebook后
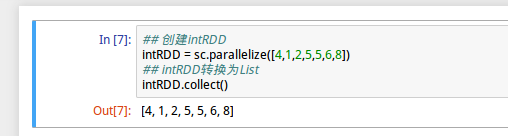
1、创建intRDD
intRDD = sc.parallelize([4,1,2,5,5,6,8])上述命令使用parallelize方法输入一个List的参数的方式定义intRDD,是一个“转换”运算,不会立即执行
2、intRDD转换为List
intRDD.collect()上述命令,intRDD执行collect()方法之后会转换为List,是一个“动作”运算,会立即执行。
执行结果
3、创建stringRDD并转换
stringRDD=sc.parallelize(["Apple", "Google", "Facebook", "Apache"])
stringRDD.collect()4、map运算
map运算通过传入的函数将每个元素经过函数运算产生另外一个RDD。如下图:
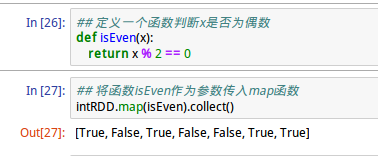
上图,函数isEven作为参数传入map命令,map使得每个元素作为实参传入函数并返回结果,从而产生另一个RDD,map本身是一个“转换”运算,不会立即执行,后面加上collect()方法(“动作”运算)才立即执行出结果。
map运算也可以不传入函数名,即匿名函数,例如:
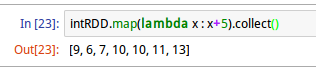
上述命令中,lamba语句表示匿名函数(anonymous functions),其中指定x为形参,x+5为要执行的命令
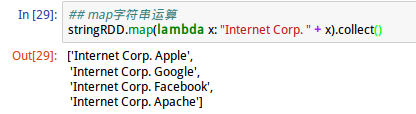
map字符串运算,针对字符串RDD执行map运算:
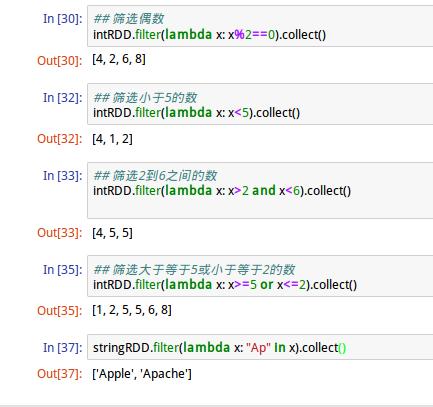
5、filter运算
顾名思义,filter“滤波运算”对RDD内每个元素进行筛选,并产生另一个RDD
6、distinct运算
distinct运算会删除重复元素intRDD.distinct().collect()
7、randomSplit运算
randomSplit运算可以将整个集合元素以随机数的方式按照比例分为多个RDD

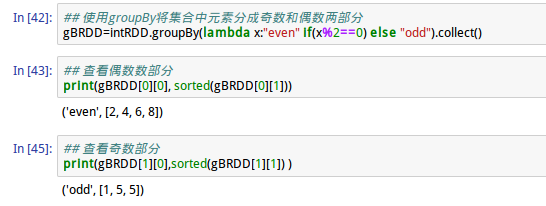
8、groupBy运算
groupBy运算可以按照传入匿名函数规则将数据分为多个List
多个RDD“转换”运算
创建多个RDD范例:
intRDD1 = sc.parallelize([1,3,5,7,9])
intRDD2 = sc.parallelize([2,4,6,8,10])
intRDD3 = sc.parallelize([3,1,5,2])
1、union并集运算

2、intersection交集及subtract差集运算

3、cartesian笛卡儿积运算 intRDD1.cartesian(intRDD3).collect()
基本“动作”运算
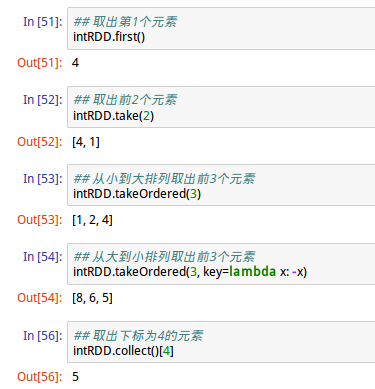
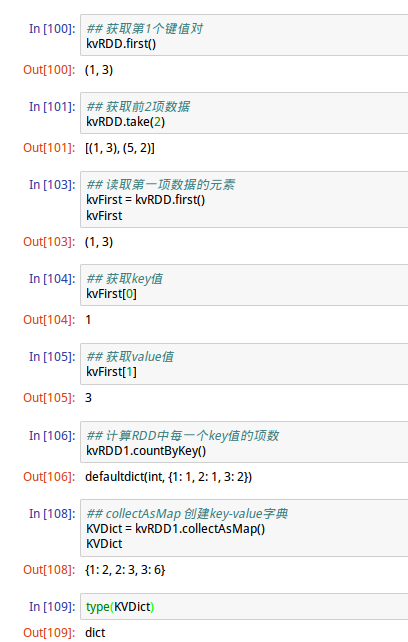
1、读取RDD元素
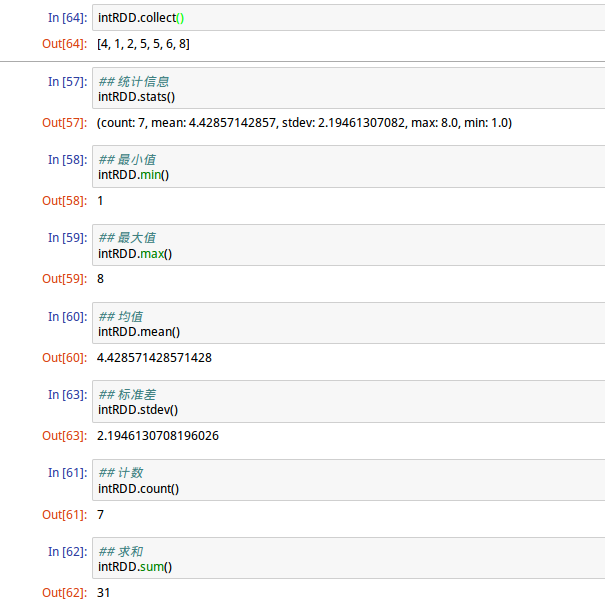
2、统计功能
将RDD内的元素进行统计运算
RDD Key-Value基本“转换运算”
1、创建Key-Value RDD范例
kvRDD = sc.parallelize([(1,3),(5,2),(5,6),(4,7)])
kvRDD.collect()其中,第一个字段是Key,第二个字段是Value
2、列出全部key值和value值

3、filter运算

4、mapValues运算
mapValues运算针对RDD内每一个(key,value)键值对进行运算,产生另外一个RDD

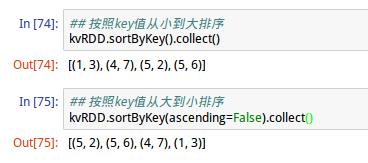
5、sortByKey运算
6、reduceByKey运算
按照Key值进行reduce运算
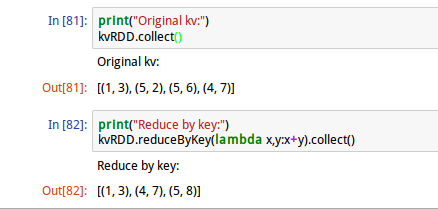
上述命令,key值为5的value进行了“+”运算的合并操作。
多个RDD Key-Value “转换”运算
创建多个Key-Value RDD 范例
kvRDD1 = sc.parallelize([(2,3),(3,5),(4,6),(1,2)])
kvRDD2 = sc.parallelize([(3,5),(5,4)])
kvRDD1.collect()
kvRDD2.collect()
1、join运算
join运算将两个RDD按照相同的key值join起来

2、subtractByKey运算
subtractByKey运算会删除相同key值的数据

Key-Value RDD “动作”运算
key-value lookup运算
可以使用lookup输入key值查找value值

Broadcast 共享变量
Shared variable共享变量可用于节省内存与运行时间,提升并行处理的执行效率。共享变量包括Broadcast和accumulator
不使用共享变量的一般RDD范例在并行处理中每执行一次转换都必须将数据(列表或字典)传送到WorkerNode,才能执行转换,如果字典(对照表)很大,需要转换的列表RDD也很大,会耗费很多内存与时间。
1、Broadcasti广播变量使用规则
- 可以使用SparkContext.broadcast([初始值])创建
- 使用.value方法读取Broadcasti广播变量的值
- Broadcasti广播变量被创建后不能修改
2、Broadcasti广播变量范例
创建kvCorp key-value RDD
kvCorp=sc.parallelize([(1,"Apple"),(2,"Google"),(3,"Facebook"),(4,"Apache")])
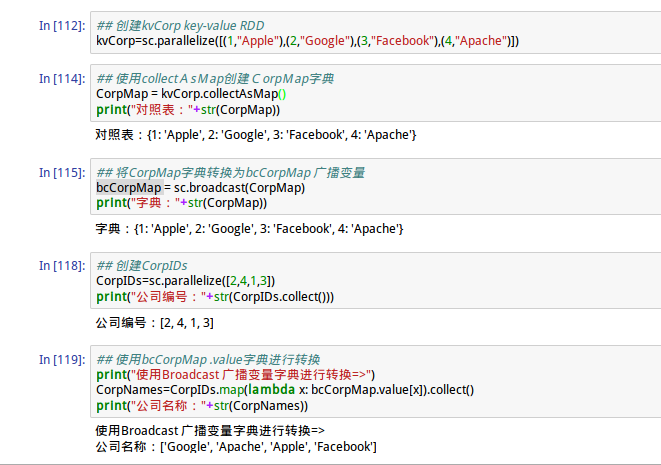
在并行处理中,bcCorpMap广播变量会传送到WorkerNode机器中,并存储在内存中,且后续在此worker Node都可以使用该广播变量执行转换,节省了内存和时间。
accumulator 累加器
1、accumulator 累加器共享变量规则
- accumulator 累加器可以使用SparkContext.accumulator([初始值])创建
- 使用方法.add()进行累加
- 在task中,例如foreach循环中,不能读取累加器的值
- 只有驱动程序(循环外),才可以使用.value来读取累加器的值
2、accumulator累计器范例
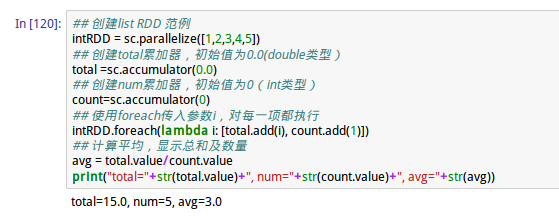
RDD Persistence持久化
Spark RDD 持久化机制可以将需要重复运算的RDD存储在内存中,以便大幅提升运算效率。
Spark RDD持久化使用方法如下:
- RDD.persist(存储等级)——指定存储等级,默认是MEMORY_ONLY(存储在内存中)。
- RDD.unpersist()——取消持久化。
