本篇文章主要讲解Spark 的编程模型以及作业执行调度流程。对于spark 来说,其核心是RDD(Resilient Distributed Dataset,弹性分布式数据集),它是一种特殊的集合,支持多种来源,有容错机制,可以被缓存支持并行操作。下面来看看RDD这一抽象数据集的核心。
Spark编程模型
RDD的特征
RDD总共有五个特征,三个基本特征,两个可选特征。
(1)分区(partition):有一个数据分片列表,可以将数据进行划分,切分后的数据能够进行并行计算,是数据集的原子组成部分。
(2)函数(compute):对于每一个分片都会有一个函数去迭代/计算执行它。
(3)依赖(dependency):每一个RDD对父RDD有依赖关系,源RDD没有依赖,通过依赖关系建立来记录它们之间的血统(关系,lineage)。
(4)优先位置(可选):每一个分片会优先计算位置(prefered location)。即要执行任务在哪几台机器上好一点(数据本地性)。
(5)分区策略(可选):对于key-value的RDD可以告诉它们如何进行分片。可以通过repartition函数进行指定。
RDD的依赖
RDD的依赖关系分为两种模型,一种是窄依赖(narrow dependency)和宽依赖(wide dependency)。
1.窄依赖
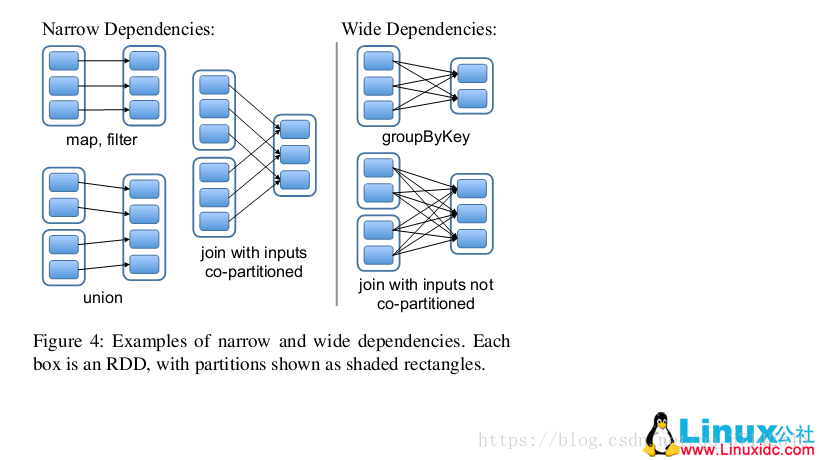
值父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区(第一类),或者是多个父RDD的分区对应于一个RDD的分区(第二类),也就是说一个父RDD的一个分区不可能对应于一个子RDD的多个分区。
如下图所示,对输入进行协同划分(co-partitioned)的join属于第二类。当子RDD的分区依赖于单个父RDD的分区的时候,分区的结构不会发生改变,如下图中的map,filter等操作,相反的,对于一个子RDD的分区依赖于多个RDD的分区的时候,分区的结构会发生改变,如下图的union操作。
2.宽依赖
宽依赖是值子RDD的每一个分区都要依赖于所有父RDD的所有分区或者多个分区。也就是说存在一个父RDD的一个分区对应着一个子RDD的多个分区。如下图的groupByKey就属于宽依赖。其中宽依赖会出发shuffle操作,下面会详细讲到。
创建RDD
RDD的创建有两种方式:
- Parallelized Collections(并行化计算一个集合)
External Datasets(引用外部数据)
Parallelized Collections
scala> val data=Array(1,2,3,4,5)
data: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val distData=sc.parallelize(data)
distData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[8] at parallelize at <console>:23
scala> distData.reduce((a,b)=>a+b)
res5: Int = 15External Datasets
以读取HDFS文件系统上的文件,统计单词频率为例:
scala> val rdd = sc.textFile("hdfs://hadoop-senior.shinelon.com:8020/user/shinelon/spark/wc.input")
scala> val wordRdd = rdd.flatMap(_.split(" "))
scala> val kvRdd = wordRdd.map((_,1))
scala> val wordCountRdd = kvRdd.reduceByKey(_ + _)
scala> wordCountRdd.collect
//将结果保存到HDFS文件系统中
scala> wordCountRdd.saveAsTextFile("hdfs://hadoop-senior.ibeifeng.com:8020/user/beifeng/mapreduce/wordcount/sparkOutput")在上述RDD的操作中,通常将应用程序的操作分为两种操作,转换(transformation)和执行(active),在默认情况下,spark的所有转换操作都是惰性的(lazy),对于每一个转换得到的RDD结果不会立即计算出结果,只是记下该转换操作的一些基础数据集,可以有多个转换结果,一旦遇到active操作就 会执行之前的所有transformation操作,最后得到结果(spark的作业执行其实就是构建DAG(有向无环图),下面会讲到),所有的RDD被清除,如果下一个JOB中会用到其他JOB中的RDD,会引发该RDD的再次计算,因此,为了避免重新计算,我们可以使用persist或者cache操作进行“持久化”一个RDD到内存当中,也可以缓存到磁盘当中
RDD中国有一系列的转换操作,下面给出一个案例,详细介绍可以参考spark官方文档。
//初始化list
scala> val data=List(("a",1),("b",1),("c",1),("a",2),("b",2),("c",2))
//并行化数组创建RDD
scala> val rdd=sc.parallelize(data)
//进行reduceByKey操作
scala> val rbk=rdd.reduceByKey(_+_).collect
rbk: Array[(String, Int)] = Array((b,3), (a,3), (c,3))
//进行groupByKey操作
scala> val grk=rdd.groupByKey().collect
grk: Array[(String, Iterable[Int])] = Array((b,CompactBuffer(1, 2)), (a,CompactBuffer(1, 2)), (c,CompactBuffer(1, 2)))
//进行sortByKey
scala> val srk=rdd.sortByKey().collect
srk: Array[(String, Int)] = Array((a,1), (a,2), (b,1), (b,2), (c,1), (c,2))RDD的控制操作
RDD的控制操作主要包括故障恢复,数据持久化以及数据移除等操作。
故障恢复
对于一个集群,spark会做出两种假设:
- 处理的时间有限。
- 保持数据持久化是外部数据的职责,主要让处理过程中数据保护稳定。
spark基于假设会折中选择方案,基于RDD之间的依赖关系,如果一个RDD坏掉,则会重新执行其父RDD的相应分区,不需要重新执行全部的JOB。
宽依赖的再执行涉及到多个父RDD(因为宽依赖会出发shuffle操作,也就是说宽依赖跨多个stage),从而引发整个JOB重新执行,为了避免这一点,spark会保持Map阶段的中间数据输出的持久,在发生故障时,只需回溯到mapper执行的相应分区即可获取中间数据。
RDD持久化
RDD持久化分为主动持久化和自动持久化。
自动持久化就是不需要用户调用持久化操作,spark自动保存一些shuffle操作的中间结果(保存到磁盘中)来避免节点崩溃时重新计算所有的输入。
主动持久化需要用户自己在需要持久化的RDD调用persist操作或者cache操作缓存数据到内存中(默认),持久化的等级选择是通过一个Storage Level对象传递给persist方法进行确定的,cache方法调用persist()的默认级别是MEMORY_ONLY(内存)。下面是官网的持久化等级选择选项:

RDD数据移除
RDD可以在内存中进行缓存,spark会坚持每一个节点上使用的缓存,如果集群中没有足够的内存时,spark会根据LRU算法(最近最少使用算法,操作系统内存管理章节内容)对数据分区进行删除。
如果想手动删除,可以在指定RDD中调用unpersist方法删除,立即生效。
二、Spark作业执行调度
1.Spark组件
从架构层面来看,每一个spark application包括一个主空节点master,集群资源管理的cluster manager,执行具体任务调度的worker节点和执行单元executor进程,负责作业提交的client客户端和负责作业调度控制的Driver进程组成。
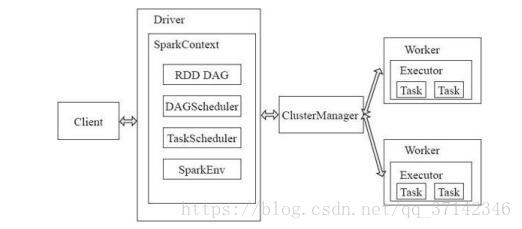
client负责提交用户的作业,Driver进程通过用户定义的main函数在集群上执行各种并行计算和操作,其中SparkContext是应用程序与集群交互的唯一通道,主要包括:获取数据,构建RDD的DAG图,通过TaskScheduler调度任务等操作。
当用户提交一个任务,Driver处理之后将所有有依赖关系的RDD组织起来构建成一个DAG图,当执行Active操作的时候,TaskScheduler就会调度所有的RDD执行任务,通过ClusterManager进行资源的同一分配管理,具体的任务会在Worker节点执行,由Task Threads负责具体任务的执行,由BlockManager进行存储管理,数据可以在内存中保存多份,一方面可以进行备份,也可以防止某个RDD丢失避免重新计算整个任务而执行RetryTask和StragglingTask快速恢复数据。
在执行DAG有向图的时候,会根据RDD之间的依赖关系,按照窄依赖划分为多个stage,在stage之间就会出发shuffle操作,因此第一个stage阶段会产生中间结果,这个中间结果也是第二个stage的输入结果,那么,这个中间结果如何递交给第二个stage呢?在这些中间结果中,包含着一些计算状态,具体的中间结果会写入磁盘,因此,下一个stage会通过BlockManager去磁盘读取中间结果进行计算。
2.spark作业执行流程
下面是Spark作业执行流程图(自己画的,有点丑,不要介意哈^_^):
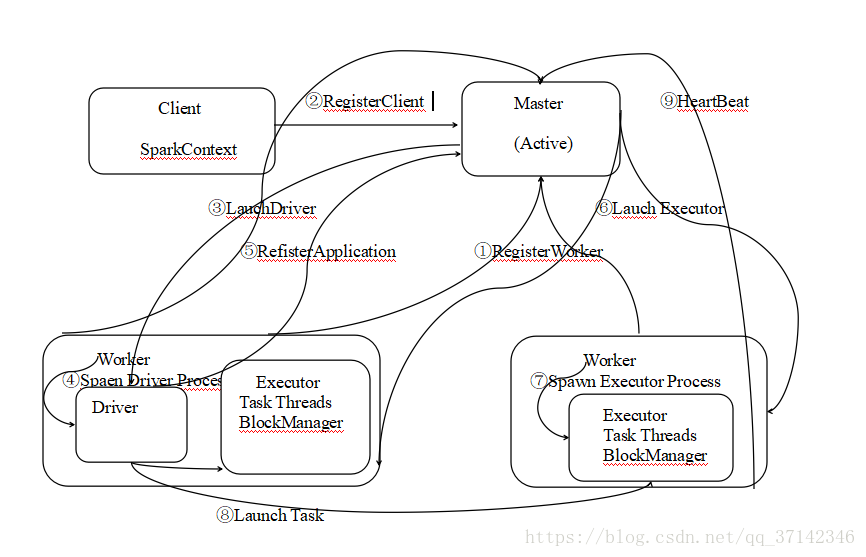
提交一个任务到集群,以standlone模式为例,它有两种模式,通过–deploy-mode进行配置,默认的是client模式(Driver在Client上),上图为cluster模式,即Driver在worker中启动。首先启动Master,然后是Wroker节点,Wroker节点启动后首先要向Master节点注册,然后注册客户端生成SparkContext用于任务生成一系列的RDD,接着master在通知一个Wroker节点上启动Driver进程,该Wroker节点生成相应的Driver Process,由Driver将应用程序注册到Master节点上,Master节点根据提交的任务通知Wroker节点启动Executor(可以类比Java并发库中的Executor框架来理解),接着Worker节点生成相应的Executor Process,Driver会将应用程序生成的RDD按照依赖关系生成DAG图并且生成TaskSet提交给TaskScheduler调度给Worker节点执行,最后每一个Worker节点都要向Master节点发送心跳报告。
由Worker节点向Master发送心跳报告,报告其健康状况,以下有几种故障相应的解决方案:
1.Worker节点发生故障,当worker节点发生故障的时候,会杀死其相应的进程Executor。从而Master没有收到Worker节点的心跳报告判断其出现故障,从而将该节点移除。
2.当Executor发生故障的时候,会由ExecutorRunner发送报告给Master,但是由于Worker是正常的,因此master会给Worker节点发送LaunchExecutor命令再次启动Executor进程。
3.当Master发送故障时,可以 通过zookeeper搭建HA来进行自动故障转移。
下面来看看Spark是如何调度作业生成一系列RDD并且构建DAG图交给Worker节点的,如下图所示:
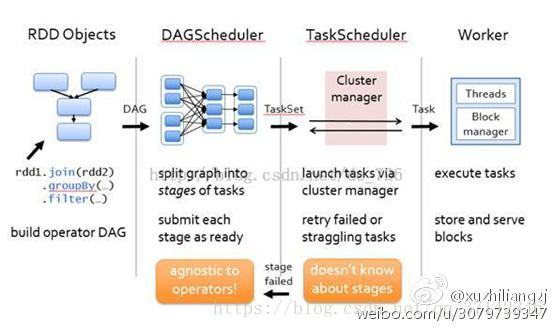
首先用户提交作业时通过一系列操作,如join,groupByKey,filter等操作生成RDD,然后由DAGScheduler根绝RDD的依赖关系构建成一个DAG图,但不不执行作业,只有遇到RDD的action操作时才会触发执行之前的所有任务。DAGScheduler将任务按照依赖关系划分为stage提交TaskSet给TaskScheduler,TaskScheduler根据任务去ClusterManager申请资源分配给Wroker节点,从而提交给Wroker节点去执行。
DAGScheduler调度器首先将构建的DAG图划分为一个完整的stage,然后按照stage中的最后一个RDD起往前回溯,在回溯的过程中不断的判断RDD的依赖关系,如果是窄依赖则继续进行回溯,如果是宽依赖则划分出一个新的stage,从而整个stage被划分为多个新的stage。从而DAG图被划分为多个stage,每一个stage由多个Task组成。
下面总结一下DAGScheduler和TaskScheduler的主要作用如下。
DAGScheduler:
- 接收用户提交的JOB。
- 构建stage,记录那个RDD或者stage输出被物化。
将TaskSet提交给底层调度器。
TaskScheduler:
提交TaskSet(一组Task)到集群运行并且监控。
- 为每一个TaskSet构建一个TaskManager来管理TaskSet的声明周期。
- 数据本地性决定每一个Task的最佳位置。
推测执行,碰到starggle任务要放到其他节点上重新执行,遇到shuffle lost要进行fetch fail报告。
最后来说一下Task,Task是Executor的最小执行单元,Task处理的数据有两个常见的来源:shuffle数据或者外部数据。另外Task可以运行在集群的任意一个节点上,它为了容错会将shuffle输出写到内存或者磁盘当中。