在高层次面上,每个spark应用有一个驱动程序组成,驱动程序运行用户的主函数,在集群上执行很多并行操作。Spark提供的主要抽象是RDD,可以进行并行操作的跨节点分散的元素集。RDDs可以由Hadoop文件系统中的一个文件创建,或在驱动程序中已经存在的scala集,然后转换它。用户会要求spark在内存中保留一个RDD,允许它被高效地跨并行操作重利用。最终RDD自动从节点失败中恢复。
spark中的第二个抽象是并行操作中可以使用的共享变量。默认情况下,当spark在不同节点作为一个任务集并行运行函数是,spark把每个函数中使用的每个变量副本传送给每个任务。有时,一个变量需要跨任务分享,或者在任务和驱动程序间。spark支持两种类型的共享变量:广播变量(在所有节点上内存缓冲一个值)和累加器(只增加的变量,比如计数器、汇总器)。
这个指南展示了spark支持的语言的这些特色。启动spark的互动shell,无论是scala的bin/spark-shell还是python的bin/pyspark,是很容易跟进的。
链接Spark —JAVA
Spark2.2.1支持lambda表达式来简明编写函数,反之你可以使用org.apache.spark.api.java.function包中的类。
注意Spark2.2.0中取消了对JAVA 7的支持。
为了用Java编写Spark应用,你需要增加对Spark的依赖。Spark可以通过Maven中心来获得:
groupId=org.apache.spark
artifactId=spark-core_2.11
version=2.2.1另外,如果如果你想访问HDFS集群,你需要增加你的HDFS版本对应的Hadoop-client依赖。
groupId=org.apache.hadoop
artifactId=hadoop-client
version=<your-hdfs-version>最后,你需要引入一些Spark类。增加以下行:
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.SparkConf;初始化Spark
一个Spark程序要做的第一件事是建立一个JavaSparkContext对象,告诉Spark如何访问一个集群。为了建立一个SparkConttext,你首先需要建立一个SparkConf对象,SparkConf对象包含你的应用的信息。
SparkConf conf=new SparkConf().setAppName(appName).setMaster(master);
JavaSparkContext sc=new JavaSparkContext(conf);appName参数是显示在集群界面上的应用的名字。master是一个Spark/Mesos或YARN集群URL,或在一个特别的‘local’字符串表示运行在本地模式。实际中,当你运行在集群中时,你不并不想硬编码master到程序中,而是用spark-submit启动应用并在启动时得到master。然而,为了本地测试和单元测试,你可以传递local来在进程中运行Spark。
使用shell –python
在python shell中,一个特别的已翻译的SparkContext已经创建,称为sc。自己创建SparkContext不会生效。你可以使用–master参数来设置连接的集群,你还可以通过以逗号为分隔符–py-files参数增加Python .zip或.py文件清单到运行时目录。你也可以通过提供以逗号为分隔符的Maven coordinates清单到–package参数,增加依赖(比如Spark包)到shell session。任何存在依赖的额外的代码库都可以传递给–repositories参数。如果需要,Spark包包含的Python依赖(在包的requirements.txt文件中有清单)必须手工使用pip安装。比如,用4核运行bin/pyspark,使用:
$./bin/pyspark --master local[4]或者,增加code.py来搜索路径(为了后续能够import code),使用:
$./bin/pyspark --master local[4] --py-files code.py运行pyspark –help可以获取完整的选项清单。在这后面,pyspark触发了更通用的spark-submit脚本。
也可以在IPython(增强性的python翻译器)中运行pyspark。pyspark适用于IPython1.0.0及以后版本。为了使用IPython,使用bin/pyspark时需要设置PYSPARK_DRIVER_PYTHON变量为ipython:
$PYSPARK_DRIVER_PYTHON=ipython ./bin/pyspark为了使用Jupyter notebook(之前称为IPython notebook),
$PYSPARK_DRIVER_PYTHON=jupyter PYSPARK_DRIVER_PYTHON_OPTS=notebook ./bin/pyspark你可以通过设置PYSPARK_DRIVER_PYTHON_OPTS来自定义ipython或jupyter。在Jupter Notebook server启动后,你可以从“Files”选项页中建立一个新的“Python 2” notebook。在notebook中,在你开始从Jupyter notebook尝试Spark前,你可以输入%pylab inline命令作为notebook的一部分。
RDDs(Resilient Distributed Datasets)
spark围绕着RDD的概念,RDD是有容错的可以并行操作的元素集合。有两种方式创建RDDs:并行化在驱动程序中已存在的集合,或引用外部存储系统中的数据集,比如共享文件系统、HDFS、HBase或在任何提供Hadoop InputFormat的数据源。
并行化集合 —Java
并行化的集合通过对驱动程序中已存在的Collection调用JavaSparkContext‘s parallelize方法来创建。集合中的元素被复制来组成一个可以并行操作的分布式的数据集。比如,以下是如何创建一个包含数字1-5的并行化集合:
List<Integer> data=Arrays.asList(1,2,3,4,5);
JavaRDD<Integer> distData=sc.parallelize(data);一旦创建,分布式数据集(distData)能够并行操作。比如,我们可以调用distData.reduce((a,b) -> a+b)来加起来列表中的元素。我们稍后描述对分布式数据集的操作。
并行集合的一个重要参数是把数据集分成分区的数量。Spark会对集群中每个分区运行一个任务。典型情况下,你希望集群中每个cpu2-4个分区。正常情况下,Spark自动根据你的集群设置分区的数量。然而,你也可以手动传递parallelize()第二个参数(比如sc.parallelize(data,10))来设置。注意:代码中有些地方使用slices(分区partitions的同义词)术语来维护向后兼容。
外部数据集 —Java
Spark可以从任何Hadoop支持的存储数据源创建分布式数据集,包括本地文件系统、HDFS、Cassandra、HBase、Amazon S3等等。Spark支持文本文件、SequenceFiles序列文件和任何Hadoop InputFormat。
文本文件RDDs可以使用SparkContext‘s textFile方法创建。这个方法使用文件(本机上的路径,或者hdfs://,s3n://,等等)的URI,然后作为行集合读取。以下是一个例子:
JavaRDD<String> distFile=sc.textFile("data.txt");一旦创建,distFile可以通过数据集操作。比如,我们可以使用map和reduce操作把所有行的数量加起来:distFile.map(s -> s.length()).reduce((a,b) -> a+b).
Spark读取文件时需要注意:
- 如果使用本地文件系统的路径,文件必须在工作节点的相同路径可访问。要么复制文件到所有节点,要么使用网络加载的共享文件系统。
- spark所有以文件为基础的输入方法,包括textFile,支持运行在目录、压缩文件和通配符。比如,你可以使用textFile(“/my/directory”),textFile(“/my/directory/.txt”)和textFile(“/my/directory/.gz”)。
- textFile方法也可以选带第二个参数来控制文件的分区数量。默认Spark为文件的每个块(HDFS中块默认是128MB)创建一个分区。但是你可以通过传递更大的值来申请更多的分区。注意你不能分配比块更少的分区。
除了文本文件,Spark的Java API也支持其他数据格式: - JavaSparkContext.wholeTextFiles可以让你读取包含大量小文本文件的目录,并为每个文件返回(文件名称,内容)对。而tetFile则为文件中每行返回一条记录。
- 对于序列文件,则使用SparkContext‘s sequenceFile[K,V]方法,其中K 和V 是文件中key和values的类型。这些应该是Hadoop’s Writable接口的子类,比如IntWritable和Text。
- 对于其他的Hadoop InputFormats,你可以使用JavaSparkContext.hadoopRDD方法,该方法包含任意的JobConf和input format类,key类和value类。设置这些和你设置hadoop job的输入源是一样的。你也可以对基于新的MapReduce API(org.apache.hadoop.mapreduce) 的InputFormats使用JavaSparkContext.newAPIHaddopRDD。
- JavaRDD.saveAsObjectFile和JavaSparkContext.objectFile支持以包含序列花Java对象的简单方式保存一个RDD。然而这样没有专门格式像Avro那样高效,Avro提供了一种很简单的方式保存任何RDD。
RDD操作
RDDs支持两种类型的操作:转换(从一个已存在的创建一个新的数据集)和动作(对数据集进行计算后返回给驱动程序一个值)。比如,map是一种转换操作,把每个数据集元素通过一个函数并返回一个新RDD代表结果。另一方面,reduce是一种动作,使用每个函数合计RDD 的所有元素并返回给驱动程序最终的结果(虽然也有一个并行的reduceByKey返回一个分布式的数据集)。
Spark 的所有转换是惰的,即它们不立即计算结果。而是记住对基础数据集(比如一个文件)的转换。当动作需要返回结果给驱动程序时,转换才开始计算。这样设计使Spark运行更高效。比如,我们意识到一个通过map创建的数据集会在一个reduce中使用并只返回reduce的结果给驱动,而不是更大的mapped的数据集。
默认情况下,每个转换的RDD每次运行动作都会重新计算。但是你也可以使用persist(或cache)方法将RDD保留在内存中,这样Spark使集群种的元素在下次查询时保持更快的访问速度。也支持将RDDs持久化到硬盘,或在跨多个节点复制。
Basics —Java
说明RDD基础,可以考虑如下简单程序:
JavaRDD<String> lines=sc.textFile("data.txt");
JavaRDD<Integer> lingLengths=lines.map(s -> s.length());
int totalLength =lineLengths.reduce((a,b) -> a+b);第一行从外部文件定义一个基本的RDD。数据集不加载在内存中,不进行操作,lines仅仅是指向文件的指针。第二行定义lineLengths作为map转换的结果。同样,lineLengths没有立即计算出来,由于惰性。最后我们运行reduce,这是一个动作,Spark把计算分成任务在不同的机器上运行,每台机器运行map的部分和本地的reduction,返回自己的结果给驱动程序。
如果我们想再次使用lineLengths,我们可以在reduce之前增加:
lineLengths.persist(StorageLevel.MEMORY_ONLY());这样会在第一次计算后把lineLengths保存在内存中。
传递函数给Spark —Java
Spark‘s API严重依赖在驱动程序中传递函数来运行在集群中。Java中,实现org.apache.spark.api.java.function包中接口的类代表函数。有两种创建这样函数的方法:
- 用自己的类实现函数接口,要么作为一个匿名内部类要么一个有命名类,然后传递实例给Spark。
- 使用lambda表达式简明地定义实现。
虽然本指南多数使用简明的lambda句法,使用长格式的相同API 也是很简单的。比如,我们可以按如下编写上述的代码:
JavaRDD<String> lines=sc.textFile("data.txt");
JavaRDD<Integer> lineLengths=lines.map(new Function<String,Integer>(){
public Integer call(String s){return s.length();}
});
int totalLength =lineLengths.reduce(new Function2<Integer,Integer,Integer>(){
public Integer call(Integer a,Integer b){return a+b;}
});或者如果行内函数比较笨重,也可以:
class GetLength implements Function<String,Integer>{
public Integer call(String s){return s.length();}
}
class Sum implements Function2<Integer,Integer,Integer>{
public Integer call(Integer a,Integer b){return a+b;}
}
JavaRDD<String> lines=sc.textFile("data.txt");
JavaRDD<Integer> lineLengths=lines.map(new GetLength());
int totalLength =lineLengths.reduce(new Sum());注意Java匿名内部类也可以访问enclosing范围的变量,只要变量是final的。Spark会把这些变量复制到每个工作节点,正如Spark为其他语言做的。
理解闭包closures
Spark的比较难的一点是理解跨集群执行代码时变量和方法的作用范围和生命周期。在作用范围之外更改变量的RDD操作是混乱的常见来源。在下面的示例我们来看下使用foreach()来增加累加器的代码,但是相同的问题也会发生在其他操作上。
Example —Java
考虑下面简单的RDD元素汇总,会依赖是否在同一个JVM中而表现不同。常见的例子是当运行Spark在本地模式(–master =local [n])和部署Spark应用到集群中(比如通过spark-submit到YARN)。
int counter=0;
JavaRDD<Integer> rdd=sc.parallelize(data);
//wrong:Don't do this!!
rdd.foreach(x -> counter += x);
println("Counter value:" + counter);本地模式 vs. 集群模式
上述代码的行为没有定义,不会按意图工作。为了执行工作,Spark把RDD操作的处理分解成任务,每个任务被执行者执行。在执行之前,Spark计算任务的闭包。闭包是那些变量和方法,他们对于执行者在RDDshang (在这里就是foreach())执行计算必须是可见的。闭包序列化后发送给每个执行者。
发送给每个执行者的闭包内的变量是副本,这样当counter在foreach函数中引用时它不再是驱动程序中的counter。在驱动节点的内存中仍然有一个counter,但它不再对执行者可见!执行者只会看到序列化闭包中的副本。这样,counter的最终值仍然时0,因为所有对counter的操作引用的是序列化闭包中的值。
在本地模式中某些环境下,foreach函数确实在和驱动相同的JVM 中执行,会引用相同的原始counter,然后确实更新它。
为了保证在这些类型的场景下定义完好的行为,应该使用Accumulator。在Spark中accumulator被专门用来提供当执行分散在集群中跨工作节点时安全更新变量的机制。本指南中accumulator部分会详细讨论这些。
一般而言,闭包(其构造像循环或本地定义的方法)不应该被用来修改全局状态。Spark不定义、不保证闭包外部引用的对象修改行为。一些代码这样做在本地模式下生效,但那只是碰巧,这样的代码在分布式模式下不会按预想的生效。如果需要全局的愈合,需要使用accumulator。
打印RDD元素
另一个惯用语法是尝试使用rdd.foreach(println)或rdd.map(println)打印RDD的元素。在一台机器上,这会产生预想的输出,打印所有的RDD元素。然而在集群模式下,执行者调用的stdout的输出会写到执行者的stdout,而不会写到驱动的stdout,所以驱动的stdout不会显示这些。为了在驱动上打印所有的元素,可以使用collect()方法首先把RDD带到驱动节点:rdd.collect().foreach(println)。因为collect()会把整个RDD取到单独的机器,驱动会run out of memory从内存中运行;如果你只需要打印RDD 的一些元素,一个跟甘泉的方法是使用take():rdd.take(100).foreach(println)。
使用键-值对 —Java
虽然大多数Spark操作作用于包含任何类型的RDDs,有一些特殊的操作只能
作用于键值对类型的RDDs。最常见的是分布式shuffle操作,比如按一个键对元素进行分组和愈合。
在Java中,键值对使用Scala标准库中的scala.Tuple2类来表示。你可以简单调用new Tuple2(a,b)来创建一个tuple,用tuple._1()和tuple._2()来访问它的字段。
键值对RDDs使用JavaPairRDD类来表示。你可以使用特殊版本的map操作,像mapToPair和flatMapToPair,从JavaRDDs中构造。JavaPairRDD同时具有标准RDD函数和键值对特殊的函数。
比如,以下代码对键值对使用reduceByKey操作来计算每行文本在文件中出现了几次:
JavaRDD<String> lines=sc.textFile("data.txt");
JavaPairRDD<String,Integer> pairs=lines.mapToPair(s -> new Tuple2(s,1));
JavaPairRDD<String,Integer> counts=pairs.reduceByKey((a,b) -> a+b);我们可以使用counts.sortByKey(),比如,来按字母表排序键值对,最后使用counts.collect()来把他们以对象数组形式带回驱动程序。
注意:当使用custom对象作为键值对操作中的键时,你必须确保custom的equals方法有对应的hashCode方法。全部细节参见Object.hashCode()文档。
转换
下面的表格列出了Spark支持的常见的转换。更多细节参见RDD API doc和pairRDD函数doc文档。
| 转换 | 意义 |
|---|---|
| map(func) | 每个元素通过一个函数func,组成新的分布式数据集,并返回 |
| filter(func) | 筛选那些func函数返回值为true的元素,组成新的数据集,并返回 |
| flatMap(func) | 类似于map,但是每个输入项会被映射成0或更多输出向(所以func应该返回一个序列而非单一项) |
| mapPartition(func) | |
| mapPartitionWithIndex(func) | |
| sample(withReplacement,fraction,seed) | |
| union(otherDataset) | |
| intersection(otherDataset) | |
| distinct([numTasks]) | |
| groupByKey([numTasks]) | |
| reduceByKey(func,[numTasks]) | |
| aggregateByKey(zeroValue)(seqOp,combOp,[numTasks]) | |
| sortByKey | |
| join | |
| cogroup | |
| cartesian | |
| pipe | |
| coalesce | |
| repartition | |
| repartitionAndSortWithinPartitions |
动作Actions
下面的表格列出了Spark支持的常见动作。细节参见RDD API doc和piar RDD函数doc文档。
| 动作 | 含义 |
|---|---|
| reduce(func) | |
| collect() | |
| count() | |
| first() | |
| take(n) | |
| takeSample | |
| takeOrdered | |
| saveATextFile | |
| saveAsSequnenceFile | |
| saveAsObjectFile | |
| countByKey | |
| foreach(func) |
Spark RDD API也暴露了一些动作的异步版本,比如foreachAsync 对应foreach,foreachAsync立即返回FutureAction给调用者而不是阻塞到动作完成。这可以被用来管理或者等待动作的异步执行。
Shuffle操作
Spark内特定的操作引发一个事项叫做shuffle。shuffle是Spark再分配数据的机制,实现跨分区不同的分组。典型地会涉及跨执行者和机器复制数据,使得shuffle是一个复杂、高成本的操作。
背景
为了了解shuffle期间发生了什么,我们可以考虑下reduceByKey操作示例。reduceByKey操作生成一个新的RDD,一个单独key对应的所有值整合进一个tuple-键和执行reduce函数的结果against所有和那个key相关的值。挑战是一个单独key的所有的值不在相同的分区,甚至不在同一个机器,但是他们必须合起来计算出结果。
在Spakr中,数据一般跨区分布,不是为某个操作而存在于必要位置。在计算期间,一个单独的人物在一个单独的分区上操作,这样,为了组织一个单独的reduceByKey任务的所有的数据去执行,Spark需要执行all-to-all操作。它必须读取所有分区找到所有key的所有值,然后跨分区把所有值放在一起来计算每个key的最终结果,这被称作shuffle。(–想想wordcount要作的事–)
虽然新shuffled的数据每个分区的元素集是确定的,分区自身的顺序也是确定的,但是这些元素的顺序却不是。如果想要有顺序的数据执行shuffle,可能会使用:
- mapPartitions 来分类每个分区使用,比如,.sorted
- repartitionAndSortWithinPartitions来高效分类分区同时再分区
- sortBy来产生一个全局有序RDD
引起shuffle的操作包括repartition操作像repartition和coalesce,ByKey操作(除了counting)像groupByKey和reduceByKey,join操作像cogroup和join。
性能影响
Shuffle是高成本的操作,因为它涉及硬盘I/O、数据序列化、网络I/O。为了为shuffle组织数据,Spark生成系列任务-map任务来组织数据、一系列reduce任务来聚合。这个术语来自MapReduce,不直接和Spark的map和reduce操作相关。
从内部看,单独map任务的结果存在内存中直到放不下。然后,这些结果基于目标分区分类后写入单独文件。在reduce方面,任务读取相应的分类的块。
特定shuffle操作会消耗大量的heap内存,因为它们在使transfer数据之前或之后用内存数据结构来组织记录。特别是reduceByKey和aggregateByKey在map侧创建这些结构,ByKey操作在reduce侧产生这些。当数据不能存在内存时,Spark把这些表格输出到硬盘,引发额外的硬盘I/O消耗和垃圾回收。
Shuffle也在硬盘上生成大量的临时文件。从Spark 1.3开始,这些文件一直保存到相应的RDDs不再使用,被作为垃圾回收。这样作是为了如果lineage重新计算,shuffle文件不需要重新创建。如果应用保留对这些RDDs的引用或者垃圾回收没有频繁kick,垃圾回收在很长一段时间之后才发生。者意味着长期运行的spark工作会消耗大量的磁盘空间。配置Spark context时,临时的存储目录由spark.local.dir配置参数指定。
Shuffle行为可以通过调整很多配置参数来调节。具体见Spark Configuration Guide中的‘Shuffle Behavior’章节。
RDD持久化
Spark最重要的能力之一就是在内存中跨操作持久化(或者缓存)一个数据集。当你持久化一个RDD时,每个节点存储在内存中计算的任何分区,然后在数据集(或者从该数据集衍生的数据集)的其他动作中重复使用它们。这样可以使得将来的动作更快(经常会快超过10倍)。缓存是迭代算法和快速交互使用的关键工具。
你可以使用persist()或cache()方法标记要持久化的RDD。第一次在动作中计算后,它会保存在节点的内存中。Spark的缓存是可容错的–如果RDD的任一分区丢失,它会自动使用创建时用的转换重新计算。
另外,每个持久化的RDD可以使用不同的存储级别存储,允许你,比如持久化到硬盘,作为序列化Java对象持久化到内存中(为了节约空间),跨节点复制。这些级别通过传递一个StorageLevel对象(Scala,Java,Python)给persist()来设置。cache()方法是使用默认存储级别的简便技法,即StorageLevel.MEMORY_ONLY(存储序列化对象在内存中)。storage level的全集是:
| Storage Level | Meaning |
|---|---|
| MEMORY_ONLY | |
| MEMORY_AND_DISK | |
| MEMORY_ONLY_SER(Java and scala) | |
| MEMORY_AND_DISK_SER(Java and scala) | |
| DISK_ONLY | |
| MEMORY_ONLY_@,MEMORY_AND_DISK_2,etc | |
| OFF_HEAP(experimental) |
注意:在Python,经常使用Pickle库来序列化存储对象,所以你是否选择一个序列化级别都无所谓。Python中可用的存储级别包括MEMORY_ONLY,MEMORY_ONLY_2,MEMORY_AND_DISK,MEMORY_AND_DISK_2,DISK_ONLY,和DISK_ONLY_2.
Spark也自动持久化一些shuffle操作中的临时数据(比如reduceByKey),甚至不需要用户调用persist。这样作是为了防止重新计算整个输入以防一个节点在shuffle中失败。我们依旧建议用户对结果RDD调用persist,如果计划重新使用它。
选择哪个存储级别?
Spark的存储级别意味着在内存使用率和CPU效率中间提供不同的平衡。我们家你通过下面的流程来选者一个:
- 如果你的RDD 适合默认的存储级别(MEMORY_ONLY),继续保持。这是CPU效率最高的选项,使得RDDs上的操作能够尽可能快地运行。
- 如果不是,试着使用MEMORY_ONLY_SER,选择一个快速序列化库来使对象具有更高空间利用效率,但是依然具有很快的访问速度。(Java和Scala)
- 不要输出到硬盘除非计算你数据集的函数成本非常高,或在要过滤大量的数据。否则,重新计算一个分区会和从硬盘上读取它一样快。
- 如果你想快速灾难恢复(比如使用Spark来服务来自web应用的需求),使用复制存储级别。所有的存储级别通过重新计算数据提供全部的容灾
,但是复制存储级别让你继续在RDD上运行任何而不需要等待重新计算丢失的分区。
删除数据
Spark自动检测每个节点上的缓存使用率,然后是哟个LRU(最近最少使用)方式丢弃旧的数据分区。如果你想手动删除RDD而不是等待它从缓存中消失,使用RDD.unpersist()方法。
共享变量
正常情况下,当传递给Spark操作(比如map或reduce)的函数在一个远程集群节点上执行时,它作用于函数中所有变量的各个副本。这些变量被复制到每个机器,在远程机器上的变量更新不回传驱动程序。支持一般情况下,跨任务读写的共享变量会低效率。然而,Spark提供两种限制类型的共享变量用于两种常见用途模式:广播变量和累加器。
广播变量
广播变量允许编程者保持一个只读变量缓存在每个机器,而不是随任务复制。他们可用来,比如,高效地给每个节点复制较大的输入数据集。Spark也尝试使用高效的广播算法分发广播变量来减少沟通成本。
Spark动作通过一系列由分布式shuffle操作分隔的阶段来执行。Spark自动广播每个阶段中任务需要的共同数据。这种方式广播的数据以序列化的方式缓存,在运行每个任务前再进行反序列化。这以为着显式地创建广播变量只有当跨多个阶段的任务需要相同数据或者当以反序列化方式缓存数据很重要时是有用的。
广播变量通过调用SparkContex.broadcast(v)中的变量v创建。广播变量是v的包装类,它的值可以通过调用value方法来访问。下面的代码展示了:
Broadcast<int[]> broadcastVar=sc.broadcast(new int[]{1,2,3});
broadcastVar.value();
// returns [1,2,3]在广播变量创建后,在任何函数中不应该是v在集群中使用,v不会传递给任何节点。另外,在广播后为了使得所有节点得到广播变量的相同值,对象不应该再被修改。
累加器 —Java
累加器是通过联想式和可交换式的操作只“增”的变量,因此高效支持并行。累加器可用来执行计数器(如在MapReduce)或汇总。Spark原生支持数字类型的计算,程序员可以增加对新类型的支持。
作为一个用户,你可以创建命名的或未命名的累加器。像下面的图片展示,命名的累加器(在这个示例中counter)会在web页面呈现累加器修改的各个阶段。Spark展示被任务表格中任务修改的每个累加器的值。
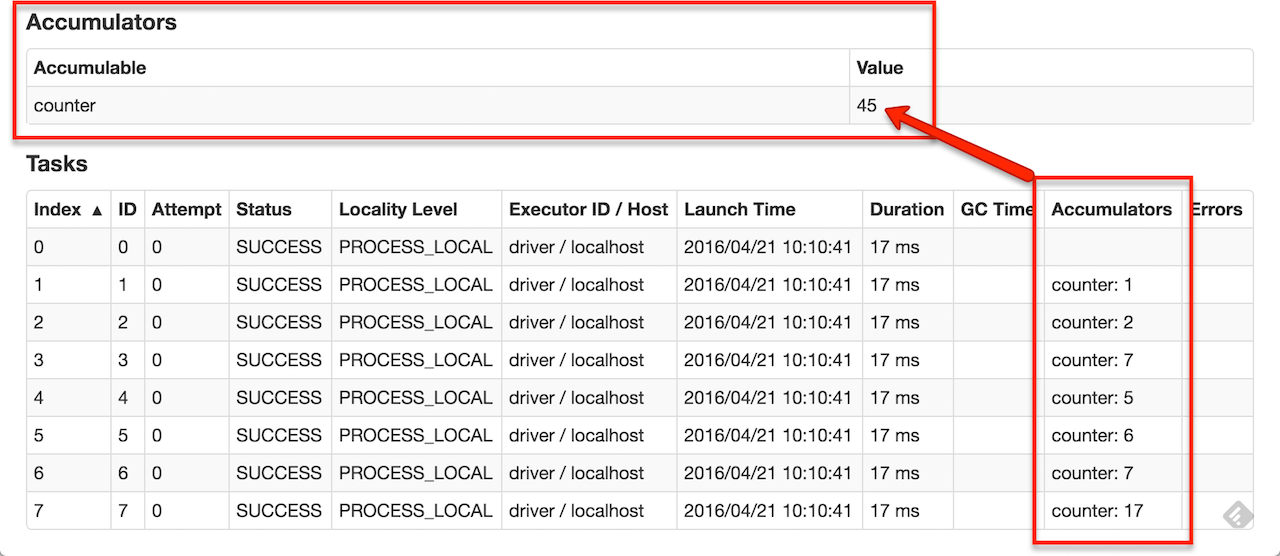
跟踪界面上的累加器对理解运行阶段的过程很有用。(注意:这还没有支持Python)
数字累加器可以通过调用SparkContext.longAccumulator()或者SparkContext.doubleAccumulator()来分别创建Long或Double类型的累加器值。在集群上运行的任务可以使用add方法来增加它。然而,集群无法读取它的值。只有驱动程序可以使用value方法读取累加器的值。
以下代码展示了一个累加器累加一个数组的元素:
LongAccumulator accum=jsc.sc().longAccumulator();
sc.parallelize(Array.asList(1,2,3,4)).foreach(x -> accum.add(x));
accum.value();这段代码使用原生支持的Long类型的累加器,程序员可以通过实现子类AccumulatorV2来创建自己的类型。子类AccumulatorV2有一些需要覆盖的方法:用来重置累加器为0的reset,把另一个值加到累加器的add,合并另一个相同类型累加器的merge。其他需要重写的方法参见API 文档。比如,假设我们有一个MyVector类表示数字矢量,我们可以写:
class VectorAccumulatorV2 implements AccumulatorV2<MyVector,Myvector>{
private MyVector myVector=MyVector.createZeroVector();
public void reset(){
myVector.reset();
}
public void add(MyVector v){
myVector.add(v);
}
}
// then create an Accumulator of this type
VectorAccumulatorV2 myVectorAcc=new VectorAccumulatorV2();
//then registere it into spark context
jsc.sc().regiter(myVectorAcc,"MyVectorAcc1");注意,当程序员定义自己类型的AccumulatorV2时,生成的类型可以和增加的元素类型不一样。
对于值在内部动作执行的累加器更新,Spark保证每个任务对累加器的更新只用应用一次,比如,重启的任务不会更新值。在转换中,用户应该意识到如果任务或工作阶段重新执行,每个任务的更新会应用多次。
累加器没有改变Spark的懒评测的模型。如果累加器正在一个RDD的操作中更新,RDD作为动作的一部分被计算,它们的值只会更新一次。所以,当在一个像map()的懒转换中时,累加器更新不保证会被执行。以下代码片段证明了这点:
LongAccumulator accum=jsc.sc().longAccumulator();
data.map(x -> { accum.add(x); return f(x);})
//here, accum is still 0 because no actions have caused the 'map' to be computed.部署一个集群
应用提交指南描述了如何提交应用到集群。简短来说,一旦你打包你的应用成JAR(for Java/Scala)或.py .zip文件集(for python),bin/spark-submit脚本让你可以提交它到任何支持的集群管理器。
从Java/Scala启动Spark工作
org.apache.spark.launcher包提供了使用简单Java API启动Spark jobs作为子进程的类。
单元测试
Spark方便于使用任何流行的单元测试框架进行单元测试。简单地在你的测试中用主机URL设置local创建一个SparkContext,运行你的操作,然后调用SparkContext.stop()来停止。因为Spark不支持两个context在同一个程序中同时运行,确保你在finally块或测试框架的tearDown方法中停止context。
接下来去哪儿
你可以去看一些Spark网站上的Spark程序样例。另外,Spark包括很多样例在example文件夹。你可以通过传递类名称到Spark的bin/run-example脚本来运行Java和Scala样例。比如:
./bin/run-example SparkPi对于Python样例,使用spark-submit脚本:
./bin/spark-submit examples/src/main/python/pi.py对于R样例,使用spark-submit:
./bin/spark-submit examples/src/main/r/dataframe.R为了优化你的程序,配置和调优指南提供最优实践信息。它们特别重要,对于保证你的数据高效存储在内存中。为寻求部署上的帮忙,集群模式概览描述了分布式操作和支持的集群管理器涉及的组件。
最后,全部的API文档参见Scala、Java、Python、R。