简述
为了练习简单的Pandas操作,我用Scrapy爬取了豆瓣Top250的电影信息。Top250页面展现的电影信息和具体电影页面所呈现的内容有些不同(比如演员信息),所以爬取总共用了两部分代码。此外为了防止被ban,还进行了一些简单的配置。
第一部分代码:
# -*- coding:utf-8 -*-
# 爬虫类需要继承scrapy下的Spider类。
import scrapy
class douban_movie_spider(scrapy.Spider):
# 项目的启动名
name = "douban_movie"
# 如果网站设置有防爬措施,需要添加上请求头信息,不然会爬取不到任何数据
headler = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 '
'Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'
}
# 开始链接
start_urls = [
'https://movie.douban.com/top250'
]
# start_requests方法为scrapy的方法,我们对它进行重写。
def start_requests(self):
# 将start_url中的链接通过for循环进行遍历。
for url in self.start_urls:
# 通过yield发送Request请求。
# 这里的Reques注意是scrapy下的Request类。注意不到导错类了。
# 这里的有3个参数:
# 1、url为遍历后的链接
# 2、callback为发送完请求后通过什么方法进行处理,这里通过parse方法进行处理。
# 3、如果网站设置了防爬措施,需要加上headers伪装浏览器发送请求。
yield scrapy.Request(url=url, callback=self.parse, headers=self.headler)
# 重写parse对start_request()请求到的数据进行处理
def parse(self, response):
# 这里使用scrapy的css选择器,既然数据在class为item的div下,那么把选取范围定位div.item
for quote in response.css('div.item'):
# 通过yield对网页数据进行循环抓取
yield {
# 我们抓取排名、电影名、导演、主演、上映日期、制片国家 / 地区、类型,评分、评论数量、一句话评价以及电影链接
"排名": quote.css('div.pic em::text').extract(),
"电影名": quote.css('div.info div.hd a span.title::text')[0].extract(),
"上映年份": quote.css('div.info div.bd p::text')[1].extract().split('/')[0].strip(),
"制片国家": quote.css('div.info div.bd p::text')[1].extract().split('/')[1].strip(),
"类型": quote.css('div.info div.bd p::text')[1].extract().split('/')[2].strip(),
"评分": quote.css('div.info div.bd div.star span.rating_num::text').extract(),
"评论数量": quote.css('div.info div.bd div.star span::text')[1].re(r'\d+'),
"引言": quote.css('div.info div.bd p.quote span.inq::text').extract(),
"电影链接": quote.css('div.info div.hd a::attr(href)').extract_first()
}
next_url = response.css('div.paginator span.next a::attr(href)').extract()
if next_url:
next_url = "https://movie.douban.com/top250" + next_url[0]
print(next_url)
yield scrapy.Request(next_url, headers=self.headler)爬取结果展示:

第二部分代码:
# -*- coding:utf-8 -*-
import scrapy
class AuthorSpider(scrapy.Spider):
name = 'douban2'
start_urls = ['https://movie.douban.com/top250']
headler = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 '
'Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'
}
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse, headers=self.headler)
def parse(self, response):
# follow links to author pages
for href in response.css('div.item div.info div.hd a::attr(href)').extract():
yield scrapy.Request(href,headers=self.headler,
callback=self.parse_author)
# follow pagination links
next_url = response.css('div.paginator span.next a::attr(href)').extract()
if next_url:
next_url = "https://movie.douban.com/top250" + next_url[0]
print(next_url)
yield scrapy.Request(next_url, headers=self.headler, callback=self.parse)
def parse_author(self, response):
# 通过yield对网页数据进行循环抓取
yield {
'排名' : response.css('.top250-no::text').extract(),
'电影名': response.xpath('//span[contains(@property,"v:itemreviewed")]/text()').extract(),
'导演': response.xpath('//div[contains(@id,"info")]/span[1]/span[contains(@class,"attrs")]/a/text()').extract(),
'编剧': response.xpath('//div[contains(@id,"info")]/span[2]/span[contains(@class,"attrs")]/a/text()').extract(),
'主演': response.xpath('//div[contains(@id,"info")]/span[3]/span[contains(@class,"attrs")]/a/text()').extract(),
'语言': response.xpath('//div[contains(@id,"info")]/span[contains(@class,"pl")][3]/following::text()[1]').extract(),
'上映日期': response.xpath('//div[contains(@id,"info")]/span[contains(@property,"v:initialReleaseDate")]/text()').extract(),
'片长' : response.xpath('//div[contains(@id,"info")]/span[contains(@property,"v:runtime")]/text()').extract()
}爬取结果展示:

- 此外为了便于在PyCharm上查看程序运行时的情况而不是在控制台,我们加了一个run.py,如下:
from scrapy import cmdline
# name='douban_movie -o douban.csv'
# cmd = 'scrapy crawl {0}'.format(name)
# cmdline.execute(cmd.split())
name='douban2 -o demo.csv'
cmd = 'scrapy crawl {0}'.format(name)
cmdline.execute(cmd.split())- 为了防止被ban,我们在前面代码中设置了请求头,除此之外,我还在settings.py中调整参数如下:
DOWNLOAD_DELAY = 1 # 下载的等待时间间隔一秒
# COOKIES_ENABLED = False 不向web server发送cookies
# ROBOTSTXT_OBEY = False 无视robot.txt当我在查看信息时发现第二个爬取结果并不是250行:
于是查看程序返回信息,发现具体电影链接存在404:
经过查证发现Top250确实确实有4部电影链接失效了,比如:《搏击俱乐部》、《熔炉》等
为了便于数据分析,我们通过Pandas将两个CSV文件做merge操作
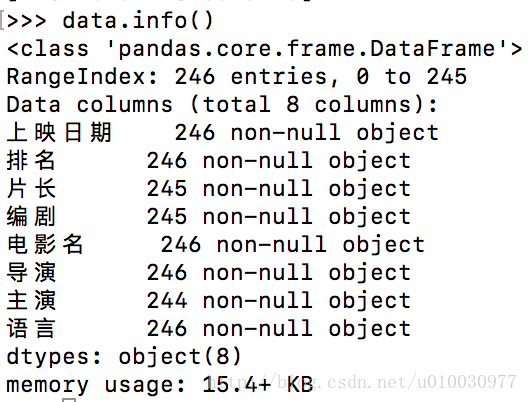


pd.merge(data_origin_1,data_origin_2,how='outer',on=u'排名')- 这样我们就完成了电影详细信息的爬取。
