开发环境:(Windows)eclipse+pydev
网址:https://book.douban.com/top250?start=0
from lxml import etree #解析提取数据 import requests #请求网页获取网页数据 import csv #存储数据 fp = open('D:\Pyproject\douban.csv','wt',newline='',encoding='UTF-8') #创建csv文件 writer = csv.writer(fp) writer.writerow(('name','url','author','publisher','date','price','rate','comment')) #写入表头信息,即第一行 urls = ['https://book.douban.com/top250?start={}'.format(str(i)) for i in range(0,250,25)] #构建urls headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'} for url in urls: #循环url,先抓大,后抓小(!!!重要,下面详解) html = requests.get(url,headers = headers) selector = etree.HTML(html.text) infos = selector.xpath('//tr[@class="item"]') for info in infos: name = info.xpath('td/div/a/@title') url = info.xpath('td/div/a/@href') book_infos = info.xpath('td/p/text()')[0] author = book_infos.split('/')[0] publisher =book_infos.split('/')[-3] date = book_infos.split('/')[-2] price = book_infos.split('/')[-1] rate = info.xpath('td/div/span[2]/text()') comments = info.xpath('td/p/span/text()') comment = comments[0] if len(comments) != 0 else '' writer.writerow((name,url,author,publisher,date,price,rate,comment)) #写入数据 fp.close() #关闭csv文件,勿忘
成果展示:
#乱码错误,用记事本打开,另存为UTF-8文件可解决

本例主要学习csv库的使用与数据批量抓取方式(即先抓大,后抓小,寻找循环点)
csv库创建csv文件及写入数据方式:
import csv fp = ('C://Users/LP/Desktop/text.csv','w+') writer = csv.writer(fp) writer.writerow('id','name') writer.writerow('1','OCT') writer.writerow('2','NOV') #写入行 fp.close()
数据批量抓取:
通过类似于BeautifulSoup中的selector()删除谓语部分不可行,思路应为“先抓大,后抓小,寻找循环点”(手写,非copy xpath)
打开chrome浏览器进行“检查”,通过“三角形符号”折叠元素,找到完整的信息标签,如下图
(selector()获取数据集中最大区域,遵循路径表达式,第一个字符串前置)
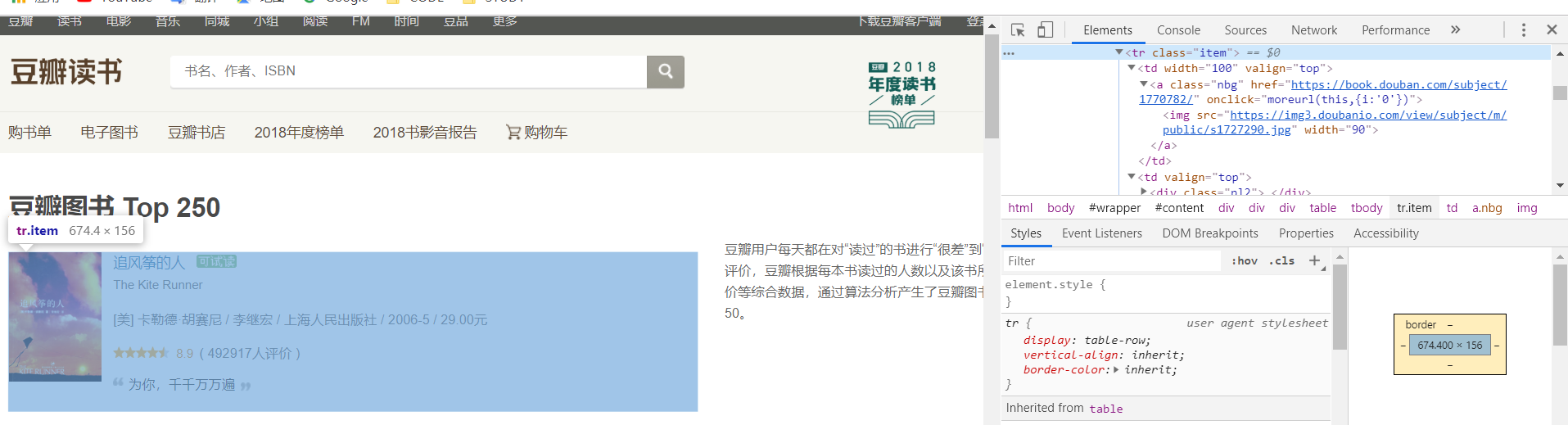
后每个单独的数据(名字,价格等)另取:
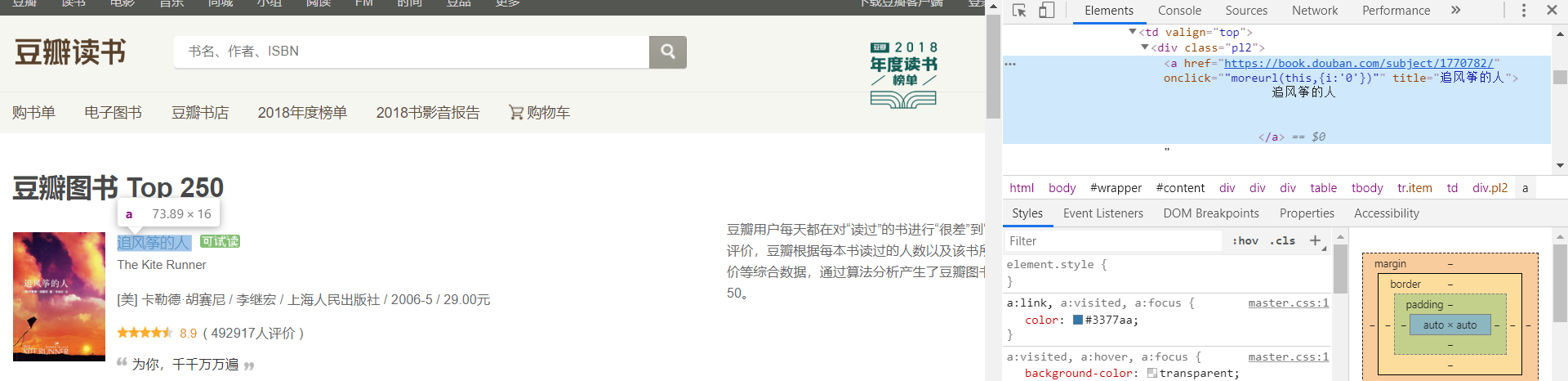
如 name,归属:<a>—><div>—><td>
所以:(当归属指向不变时,取小范围的)
name = info.xpath('td/div/a/@title')