大三上学期学的《编译原理》,当时学的也是迷迷糊糊的,很多原理都不懂。看了慕课上哈工大陈鄞老师的《编译原理》后受益匪浅,从中学到了很多,只可惜最后学校的期末考试题量太大,也没时间写了。
下面是我们学校的编译原理的实验,只做了前三个:词法分析、LL1分析、LR1分析。LR1分析因为那段时间考试周临近,忙不过来,就只写了个总控程序,没有写自动生成分析表。程序只是针对老师布置的实验来做的,没有过多测试,所以运行结果可能会有错误,仅供参考。
另外,大二下初学C#,用的还是以前C++面向过程的思想,所以会有点乱。。。
词法分析
一、实验目的和要求
通过本实验的编程实践,使学生了解词法分析的任务,掌握词法分析程序设计的原理和构造方法,使学生对编译的基本概念、原理和方法有完整的和清楚的理解,并能正确地、熟练地运用。
1、编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。
2、将标识符填写的相应符号表须提供给编译程序的以后各阶段使用。
3、根据测试数据进行测试。测试实例应包括以下三个部分:
全部合法的输入。
各种组合的非法输入。
由记号组成的句子。
4、词法分析程序设计要求输出形式:
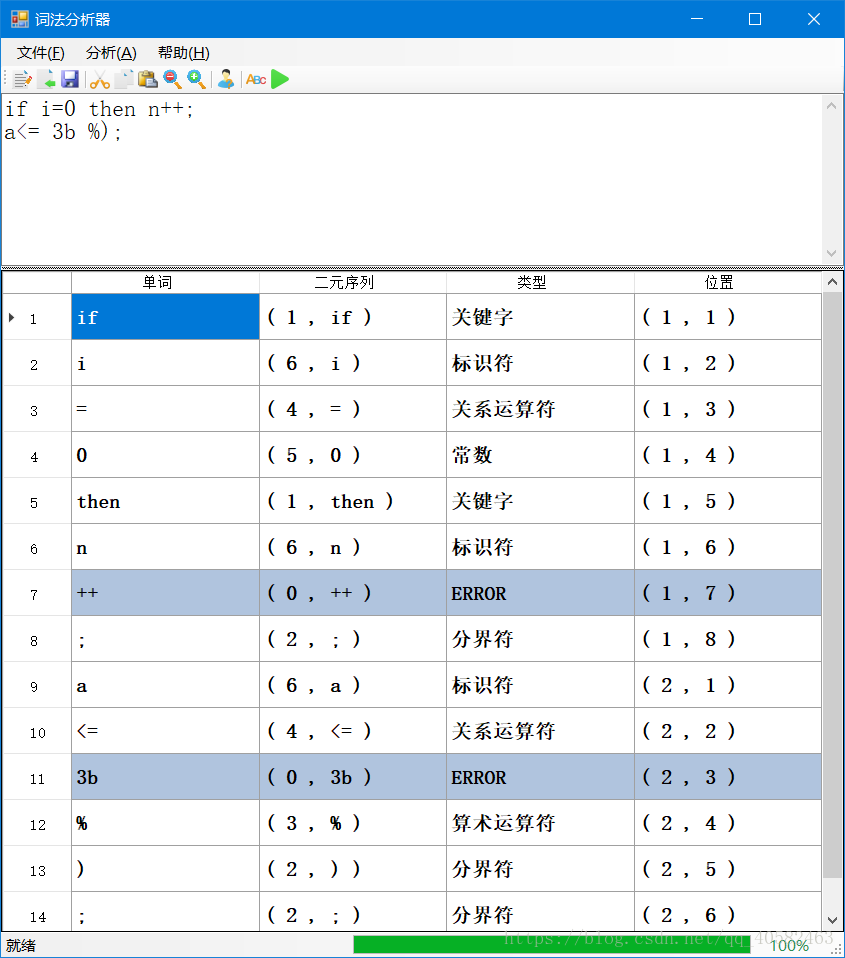
例:输入VC++语言的实例程序:
If i=0 then n++;
a﹤= 3b %);输出形式为:
| 单词 | 二元序列 (单词种别,单词属性) |
类 型 | 位置(行,列) |
| for | (1,for) | 关键字 | (1,1) |
| i | (6,i) | 标识符 | (1,2) |
| = | (4,=) | 关系运算符 | (1,3) |
| 0 | (5,0) | 常数 | (1,4) |
| then | (1,then) | 关键字 | (1,5) |
| n | (6,n) | 标识符 | (1,6) |
| ++ | Error | Error | (1,7) |
| ; | (2,;) | 分界符 | (1,8) |
| a | (6,a) | 标识符 | (2,1) |
| <= | (4,<=) | 关系运算符 | (2,2) |
| 3b | Error | Error | (2,3) |
| % | Error | Error | (2,4) |
| ) | (2,)) | 分界符 | (2,5) |
| ; | (2,;) | 分界符 | (2,6) |
二、实验原理
(1)实验数据结构说明
/// <summary>
/// 枚举各种符号的类型
/// </summary>
public enum Type
{
Error,//错误类型
KeyWord,//关键字
Delimiter,//分界符
ArithmeticOperator,//算术运算符
RelationalOperator,//关系运算符
Constant,//常数
Identifier,//标识符
}
//存储单词符号的位置
public struct Position
{
public int x { get; set; }
public int y { get; set; }
}
//识别出的单词符号
public class Tokens
{
public string word { get; set; }//单词
public Position position;//符号所在的位置
public Type type { get; set; }//识别出的符号的类型
//public int pointer;//指针
}
/**********************************全局字段********************************/
ArrayList tokenList = new ArrayList();//该列表存放已识别出的符号
string[] keyWordsList ={"bool","break","case","char","continue","do",
"double","else","float","for","goto","if","int","long","return",
"short","signed","sizeof","switch","tyepdef","unsigned",
"void","while","end","printf","scanf","then","default"};
string[] delimiterList = { "#","(", ")", "[", "]", "\"", ";", ":", "{", "}", "\\", ",","." ,"'"};
string[] relationalOperatorList ={"=","<",">","<>","<=",">=","==","!="};
string[] arithmeticOperatorList = { "+", "-", "*", "/","%"};
char[] inStream;//存放待分析的文本
char ch;//每次读取一个字符存到全局变量
int index = 0;//输入字串的下标指示器
static int r = 1, c = 1;//记录当前读取的字符的行列信息
/***************************************************************************/(2)实验算法描述
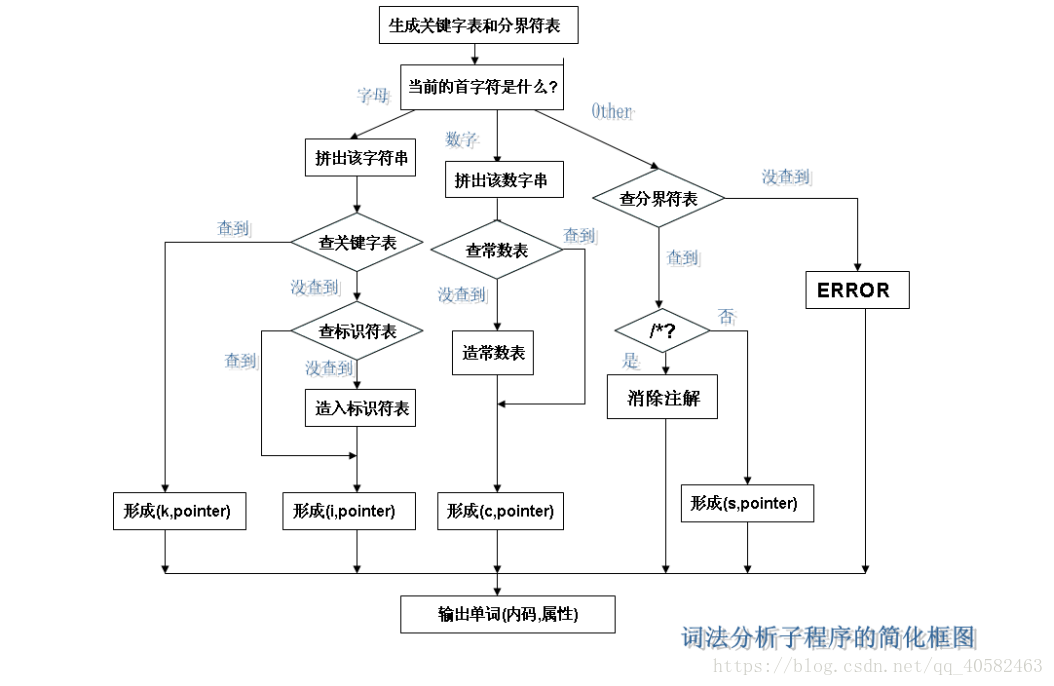
主程序每次读入一个字符,判断该字符的类型,然后调用对应的子程序继续读入字符进行处理。
如果是空白字符,调用GetBC()继续读取直到不为空白字符。
如果是字母或下划线,调用letter()子程序,拼写出该单词后,查找关键字表,判断其类型是关键字还是标识符,最后将其插入到符号表中。
如果是数字,调用digit()子程序,拼写出该符号串,若串中包含字母或一个以上的小数点,则出错,否则识别出一个常数。
运算符和分界符的识别同理。先识别出第一个字符,然后读取下一个字符,接着查表,判断是否为双字符运算符(>=,<>等等),最后把它插入到符号表。
(3)算法流程图
(4) 运行结果
LL1分析
一、实验目的和要求
通过完成预测分析法的语法分析程序,了解预测分析法和递归子程序法的区 别和联系。使学生了解语法分析的功能,掌握语法分析程序设计的原理和构造方 法,训练学生掌握开发应用程序的基本方法。有利于提高学生的专业素质,为培养适应社会多方面需要的能力。
1、编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。
2、如果遇到错误的表达式,应输出错误提示信息。
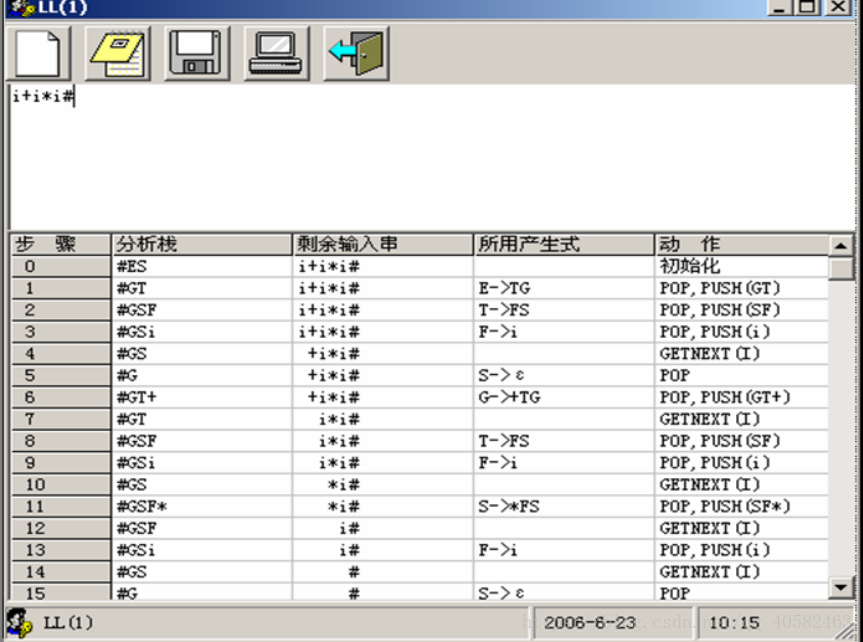
3、对下列文法,用 LL(1)分析法对任意输入的符号串进行分析:
(1)E->TG
(2)G->+TG|—TG
(3)G->ε
(4)T->FS
(5)S->*FS|/FS
(6)S->ε
(7)F->(E)
(8)F->i
输出的格式如下:
二、实验原理
(1)实验数据结构说明
List<char> Vt = new List<char>();//终结符集合
List<char> Vn = new List<char> ();//非终结符集合
List<string> production = new List<string>();//产生式集合
string[][] table;//预测分析表
Stack<char> symbolStack = new Stack<char>();//分析栈
char[] inString;//输入符号串
int index;//当前输入符号的指针
public class Log
{
public string strStack; //分析栈中的符号串
public string strRemain; //剩余输入串
public string strProduction; //所用产生式
public string strAction; //动作
}
List<Log> log = new List<Log>();//记录分析过程
List<HashSet<char>> firstSets = new List<HashSet<char>>();//利用集合中元素的互异性可以避免first集元素重复。这是一个数组,每个数组单元里存放的是某一个符号的first集
List<HashSet<char>> followSets =new List<HashSet<char>>();//follow集
(2)实验算法描述
表驱动的预测分析法:
最初,语法分析器的格局如下:
输入缓冲区中是w#,G的开始符号位于栈顶,其下面是#。下面的程序使用预测分析表M生成了处理这个输入的预测分析过程。
设置ip使它指向w的第一个符号,其中ip 是输入指针;
令X=栈顶符号;
while ( X≠#){ /* 栈非空 */
if ( X 等于ip所指向的符号a) 执行栈的弹出操作,将ip向前移动一个位置;
else if (M是一个终结符号) error ( ) ;
else if (M[X,a]是一个报错条目) error ( ) ;
else if (M[X,a] = X→Y1Y2 … Yk){
输出产生式 X→Y1Y2 … Yk ;
弹出栈顶符号;
将Yk,Yk-1…,Yi 压入栈中,其中
Y1位于栈顶。 }
令X=栈顶符号
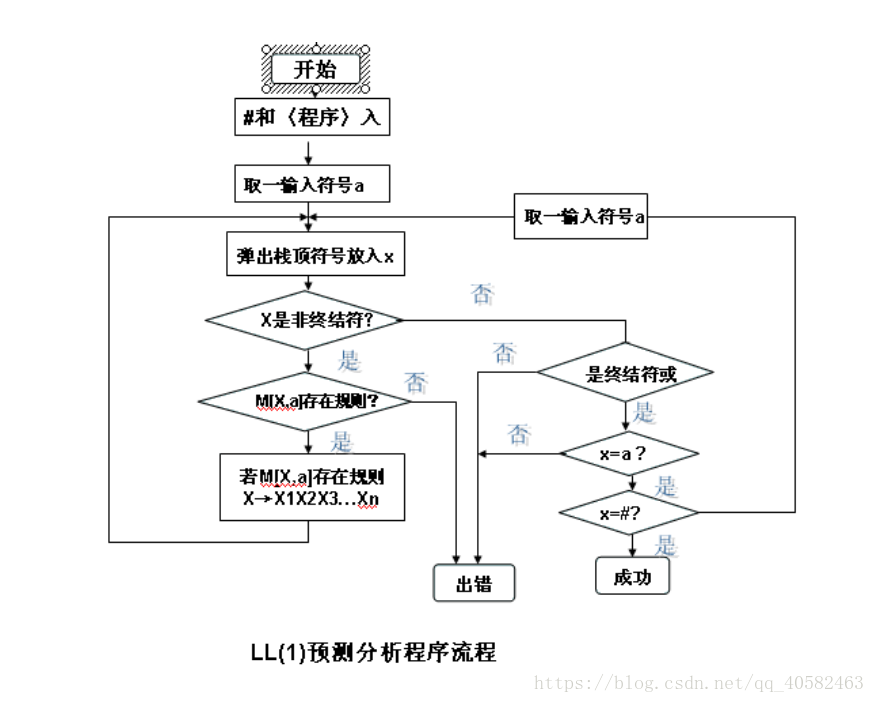
}(3)算法流程图
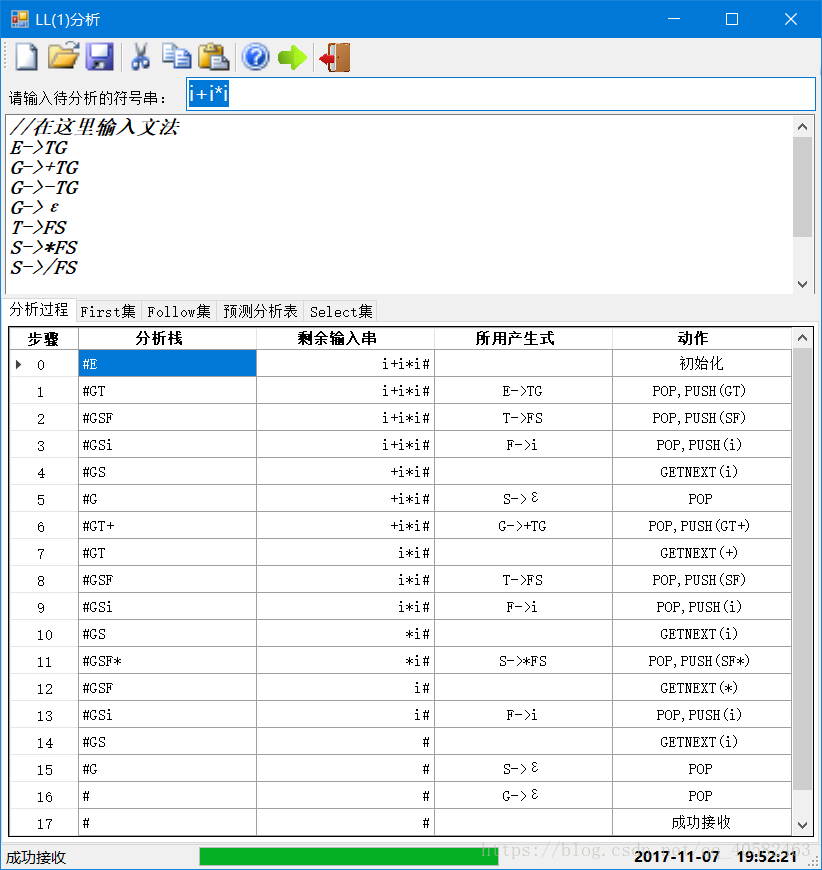
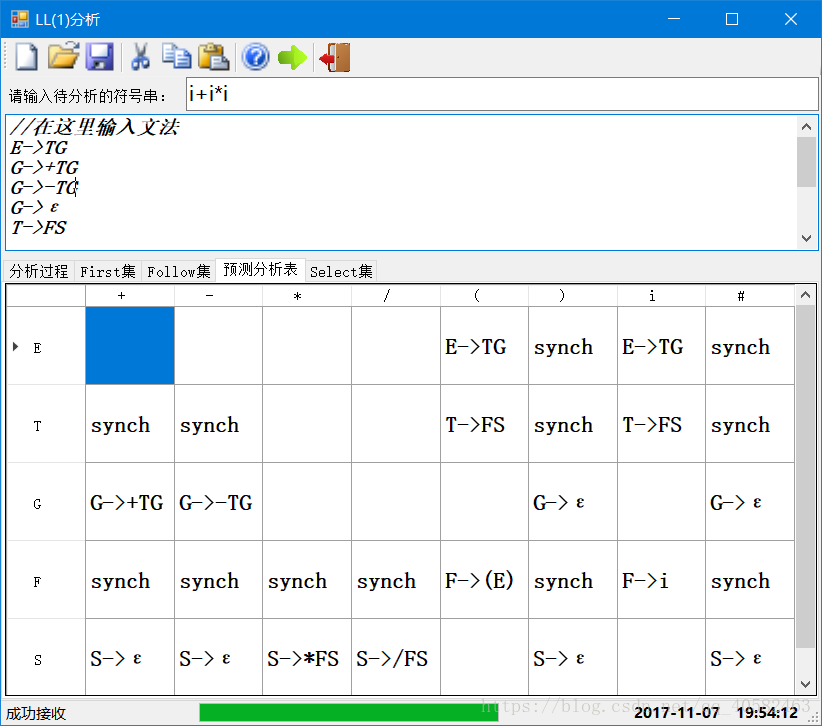
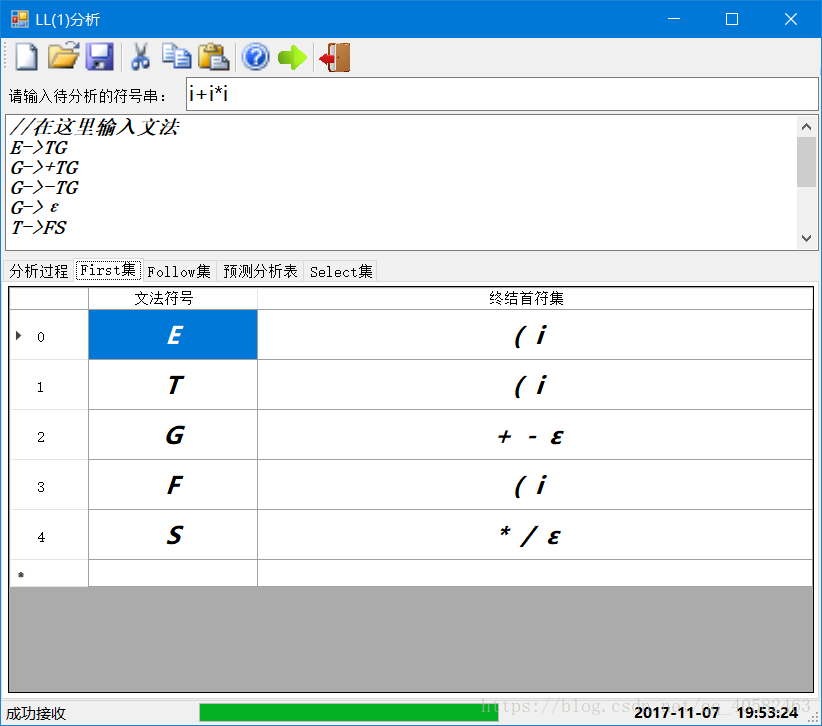
(4) 运行结果
LR1分析
一、实验目的和要求
构造 LR(1)分析程序,利用它进行语法分析,判断给出的符号串是否为该文 法识别的句子,了解 LR(K)分析方法是严格的从左向右扫描,和自底向上的 语法分析方法。
对下列文法,用 LR(1)分析法对任意输入的符号串进行分析:
(1)E-> E+T
(2)E->T
(3)T-> T*F
(4)T->F
(5)F-> (E)
(6)F-> i
1、编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。
2、如果遇到错误的表达式,应输出错误提示信息。
3、程序输入/输出实例: 输入一以#结束的符号串(包括+*()i#):在此位置输入符号串
输出过程如下:
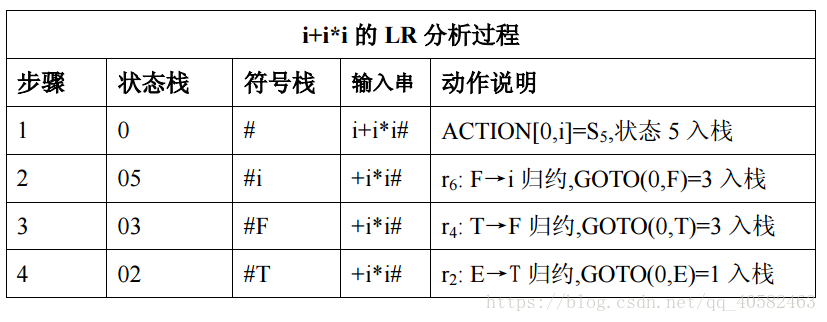
二、实验原理
(1)实验数据结构说明
/*****************************字段*****************************/
private string _inputString;//输入串
private Stack<int> _status=new Stack<int>();//状态栈
private Stack<char> _symbol = new Stack<char>();//符号栈
private List<char> Vt = new List<char> { 'i', '+', '*', '(', ')', '#' };//终结符集合
private List<char> Vn = new List<char> { 'E', 'T', 'F' };//非终结符集合
private List<string> _production = new List<string> {
"","E->E+T","E->T","T->T*F","T->F","F->(E)","F->i"};//为保证序号和下标一致,第一个产生式为空,不使用
private List<List<int>> _goto = new List<List<int>> {//GOTO表
new List<int> {1,2,3 },
new List<int> {-1,-1,-1 },
new List<int> {-1,-1,-1 },
new List<int> {-1,-1,-1 },
new List<int> {8,2,3 },
new List<int> {-1,-1,-1 },
new List<int> {-1,9,3 },
new List<int> {-1,-1,10 },
new List<int> {-1,-1,-1 },
new List<int> {-1,-1,-1 },
new List<int> {-1,-1,-1 },
new List<int> {-1,-1,-1 },
};
private List<List<string>> _action = new List<List<string>> {//ACTION表
new List<string> {"S5",null,null,"S4",null,null },
new List<string> {null,"S6",null,null,null,"acc" },
new List<string> {null,"r2","S7",null,"r2","r2" },
new List<string> {null,"r4","r4",null,"r4","r4" },
new List<string> {"S5",null,null,"S4",null,null },
new List<string> {null,"r6", "r6", null, "r6", "r6" },
new List<string> {"S5",null,null,"S4",null,null },
new List<string> {"S5",null,null,"S4",null,null },
new List<string> {null,"S6",null,null, "S11",null },
new List<string> {null,"r1","S7",null,"r1","r1" },
new List<string> {null,"r3","r3",null, "r3", "r3" },
new List<string> {null,"r5","r5",null, "r5", "r5" },
};
private int ip=0;//输入指针
private class Log
{
public string strStatus;
public string strSymbol;
public string strString;
public string strAction;
}
private List<Log> log = new List<Log>();//记录分析过程
(2)实验算法描述
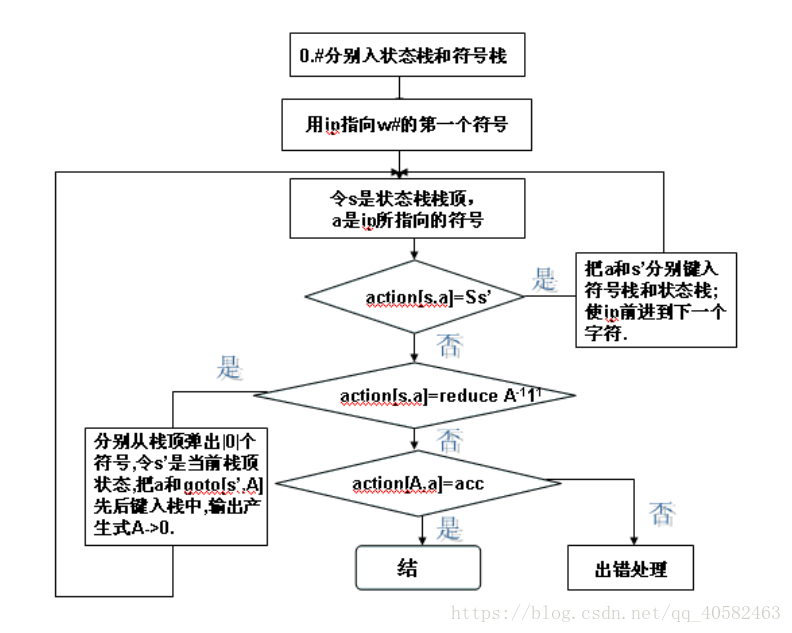
输入:串w和LR语法分析表,该表描述了文法G的ACTION函数和GOTO函数。
输出:如果w在 L(G)中,则输出w的自底向上语法分析过程中的归约步骤;否则给出一个错误指示。
方法:初始时,语法分析器栈中的内容为初始状态s0,输入缓冲区中的内容为w#。然后,语法分析器执行下面的程序:
令a为w#的第一个符号;
while (1)
{ /* 永远重复*/
令s是栈顶的状态;
if (ACTION[s,a] = st)
{
将t压入栈中;
令a为下一个输入符号;
}
else if (ACTION[s,a] = 归约A → β ) {
从栈中弹出│ β │个符号;
将GOTO[t,A]压入栈中;
输出产生式 A → β ;
}
else if (ACTION[s,a] = 接受) break; /* 语法分析完成*/
else 调用错误恢复例程;
}
(3)算法流程图
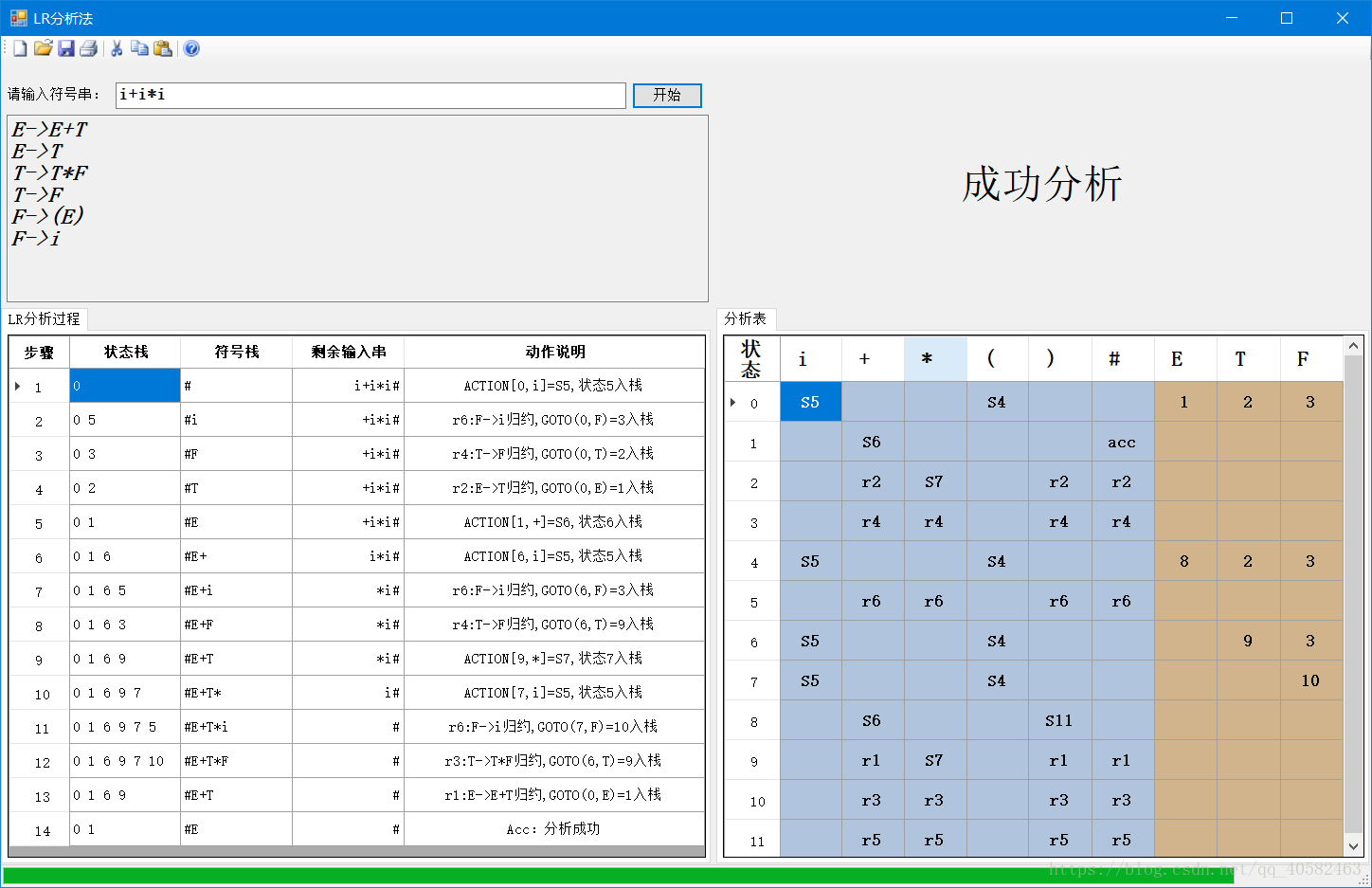
(4) 运行结果:
完整代码:https://download.csdn.net/download/qq_40582463/10645775