词法分析实验报告
文章目录
一、实验目的
设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验原理
词法分析程序的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
三、实验要求
- 1、写出某个语言的词法分析程序,要求能识别出关键字,标识符,常数,运算符和分界符等常用语言单词符号。
- 2、词法分析程序的输入为文件格式(包含要分析的源程序),输出为文件格式(单词符号的二元组序列)。
- 3、空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
- 4、对词法分析程序的每个函数给出注释,说明函数的主要功能。针对代码中的关键部分适当给出注释解释。
四、实验步骤(利用Java语言来进行词法分析)
① 待分析的语言词法
(1)关键字: int short long char class finally public
(2)运算符和界符:* / + - = ; ( ) : := > >= < <= #
(3)其他单词是标识符 (ID) 和整型常数 (NUM),通过以下正规式定义:
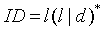
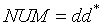
(4)空格由空白字符组成,用来分隔ID,NUM,运算符,界符和关键字,词法分析阶段通常被忽略。
② 单词符号对应的种别码
| 单词符号 | 种别码 | 单词符号 | 种别码 |
|---|---|---|---|
| int | 1 | - | 23 |
| short | 2 | = | 24 |
| long | 3 | ; | 25 |
| char | 4 | ( | 26 |
| class | 5 | ) | 27 |
| finally | 6 | : | 28 |
| public | 7 | := | 29 |
| l(l|d)* | 10 | > | 30 |
| dd* | 11 | >= | 31 |
| * | 20 | < | 32 |
| / | 21 | <= | 33 |
| + | 22 | # | 0 |
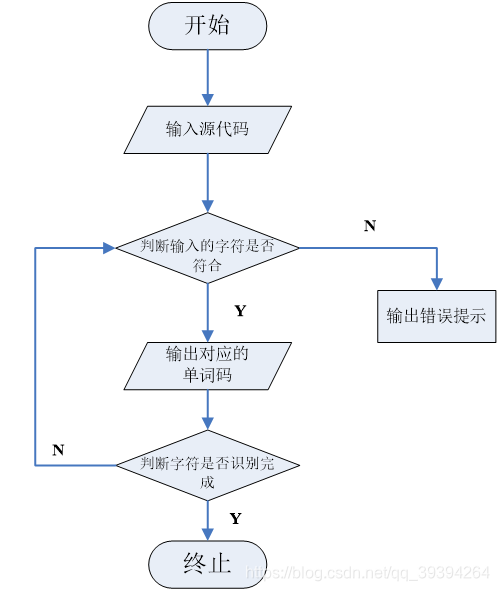
③ 词法分析程序流程图
④ 编写程序(见源程序代码文件)
import java.io.*;
import java.util.ArrayList;
import java.util.List;
public class Hyn {
public static void main(String[] args) throws IOException {
//指定关键字
String[] KeyWords = {"int", "short", "long", "char", "class", "finally","public"};
//读入要输入的程序文件
BufferedReader reader =
new BufferedReader(new InputStreamReader(new FileInputStream("E://reader.txt")));
//输出结果文件
BufferedWriter writer =
new BufferedWriter(new OutputStreamWriter(new FileOutputStream("E://writer.txt")));
//将文件的第一行生成字符串
String string = reader.readLine();
//限制字符串的最大值
final int length = 100;
//给要分析的数据创建一个字符型数组
char[] chars = new char[length];
//索引值
int Index = 0, key = 0;
//集合存储数据
List mylist = new ArrayList();
System.out.println("词法分析的结果如下:");
do {
String strs = null;
char t = string.charAt(Index);
mylist = Check(t, chars, KeyWords, string, Index, strs);
if (mylist.size() == 0) {
Index++;
continue;
}
//规定List的第一个元素为Index,第二个元素为key
Index = Integer.parseInt((String) mylist.get(0));
key = Integer.parseInt((String) mylist.get(1));
String words = (String) mylist.get(2);
writer.write("(" + words + " , \t"+ key + ")");
writer.newLine();
writer.flush();
System.out.println("(" + words + " , \t"+ key + ")");
} while (key != 0);
}
/**
*
* @param t
* @param chars
* @param KeyWords
* @param string
* @param Index
* @param strs
* @return
*/
public static List Check(char t, char[] chars, String[] KeyWords, String string, int Index, String strs) {
int keyId = -1, find = 0;
List mylist = new ArrayList();
/*
* 第一部分:扫描分类:关键字,数非关键字,数字,关系运算符
*/
//判断下一个读入的字符是否为空格,若读取到空格则跳过,提取下一个字符进行判断
while (t != ' ') { //t是扫描到的临时字符
//判断当前字符是字母或者数字和字母的组合
if (t >= 'a' && t <= 'z') {
// 当读取到不是大小写字母或者数字时候判断为一个单词读取完成
while (t >= 'a' && t <= 'z' || t >= 'A' && t <= 'Z' || t >= '0' && t <= '9') {
chars[find++] = t;
strs += t + "";
t = string.charAt(++Index);//读取下一个
}
// 与读取出来的字符判断是否为关键字
strs = strs.substring(4);
//这里的i限制对应指定关键字的数组大小
for (int i = 0; i < 7; i++) {
if (strs.equals(KeyWords[i])) {
keyId = i + 1;
mylist.add(Index + "");
mylist.add(keyId + "");
mylist.add(strs);
return mylist;
}
}
//若为非关键字就当作为标识符
keyId = 10;
mylist.add(Index + "");
mylist.add(keyId + "");
mylist.add(strs);
return mylist;
}
//判断当前字符是否为数字
else if (t >= '0' && t <= '9') {
find = 0;
String tTokens = null;
// 对后面的字符进行判断是否为数字
while (t >= '0' && t <= '9') {
chars[find++] = t;
tTokens += t;
t = string.charAt(++Index);
}
// 不是数字则返回种别码,结束当前方法
keyId = 11;
tTokens = tTokens.substring(4);
mylist.add(Index + "");
mylist.add(keyId + "");
mylist.add(tTokens + "");
return mylist;
}
find = 0;
/*
* 第二部分:扫描分类:关系运算符
*/
//判断当前字符是否为其他关系运算符
String token = null;
switch (t) {
case '>':
chars[find++] = t;
token += t;
if (string.charAt(++Index) == '=') {
keyId = 31;
chars[find++] = t;
token += string.charAt(Index++);
} else {
keyId = 30;
}
mylist.add(Index + "");
mylist.add(keyId + "");
token = token.substring(4);
mylist.add(token);
return mylist;
case '<':
chars[find++] = t;
token += t;
if (string.charAt(++Index) == '=') {
chars[find++] = t;
keyId = 33;
token += string.charAt(Index++);
} else {
keyId = 32;
}
mylist.add(Index + "");
mylist.add(keyId + "");
token = token.substring(4);
mylist.add(token);
return mylist;
case ':':
chars[find++] = t;
token += t;
if (string.charAt(++Index) == '=') {
keyId = 29;
chars[find++] = string.charAt(Index);
token += string.charAt(Index++);
} else {
keyId = 28;
}
mylist.add(Index + "");
mylist.add(keyId + "");
token = token.substring(4);
mylist.add(token);
return mylist;
case '*':
keyId = 20;
break;
case '/':
keyId = 21;
break;
case '+':
keyId = 22;
break;
case '-':
keyId = 23;
break;
case '=':
keyId = 24;
break;
case ';':
keyId = 25;
break;
case '(':
keyId = 26;
break;
case ')':
keyId = 27;
break;
case '#':
keyId = 0;
break;
default:
keyId = -1;
break;
}
chars[find++] = t;
mylist.add(++Index + "");
mylist.add(keyId + "");
mylist.add(t + "");
return mylist;
}
return mylist;
}
}
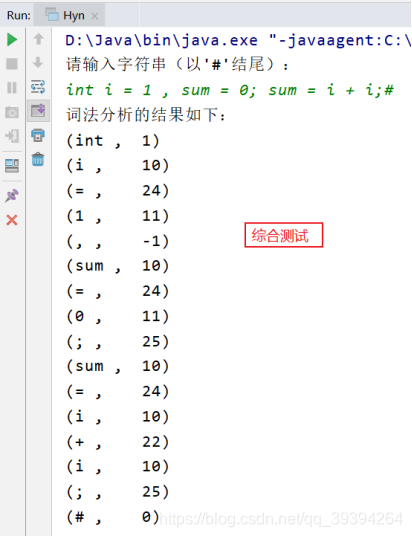
⑤ 测试结果(见输入输出文件)
五、运行结果分析
打开包含源程序的文件,截图:

经过词法分析处理后,打开输出文件,截图:
通过文件输入:

分析结果:

六、总结
刚开始写实验的时候确实无从下手,后面通过看书和查阅资料了解大概,然后开始尝试写步骤、流程和程序,渐入佳境。
通过这次实验让我对词法分析的理解更深了一步,这也是做实验和学习这门课程的目的所在。一步步完善实验的过程也是在增强自己的知识。
- 不足:应该改善程序能识别更多的无相关字符,空白字符,如转行字符等。
- 优点:测试阶段阶段做得比较详细