编译原理 LL(1)分析 实验报告 C++实现
一、实验目的
根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
二、实验要求
- 手动输入文法(从文件读取)
- 显示文法的非终结符的First集
- 显示文法的非终结符的Follow集
- 显示规则的Select集合
- 构造预测分析表
- 对任意输入的符号串进行分析
三、理论依据
3.1 自顶向下分析与LL(1)分析法
自顶向下分析:从文法的开始符号出发,根据当前的输入串,确定下一步选择什么样的产生式替换对应的非终结符以向下推导。(如何从根节点出发根据当前输入串如何构造一棵语法树)
上图就是从开始符号S开始,根据输入串W使用自顶向下分析推导的语法树

LL(1)分析法是一种自顶向下语法分析方法,它的含义是:
第一个L:从左向右扫描输入串;
第二个L:分析过程中使用最左推导;
括号中的1:只需要向右看一个字符就可以确定如何推导。
3.2 开始符号集First
定义: First(β)是β的所有可能推导的开头终结符或可能的є
First(β)={a︱β -> ay,a∈Vt,y∈V* }
意义:若关于同一非终结符有多条产生式,可以根据输入符号是属于哪一产生式右部的first集来唯一确定。(first集合不相交)
3.3 后跟符号集Follow
定义:Follow(U)为所有含有U的句型中紧跟在U之后的终结符号或#组成的集合。
FOLLOW(A)={
a | S… Aa …,a∈VT }
意义:若关于同一非终结符有多条产生式,如果右部为空,也可以根据输入符号是属于哪一产生式左部的follow集合来唯一确定。(follow集合不相交)
3.4 可选符号集Select
定义:可以选用该产生式进行推导的输入符号的集合。
Select(A→β)=
(1)First(β),当β不为空符号串
(2)Follow(A),当β为空符号串
意义:比如上面式子表示,First(β)或者Follow(A)集合中的元素,可以使用A→β这条产生式进行推导。
用于判定:必须唯一确定产生式才能成功地推导下去,所以同一个非终结符开始的产生式的select集合不能有交集。
3.5 预测分析表
定义:根据分析栈栈顶元素,以及当前输入串字符,可以唯一确定一条产生式。把所有可能的情况总结成为一张表,就是预测分析表。
不能推导的格子写成ERR。分析输入串的时候就只需要查询这张表。前面求的几个非终结符集合都是构建起这个表的基础。

四、实验步骤
4.1 求解开始符号集First
总体思路:
- 1、如果X∈Vt,FIrst(X)=X;
- 2、如果X∈Vn,X→a…,FIrst(X)=a;
- 3、如果X∈Vn,X→ε,则ε∈FIrst(X)
- 4、如果X∈Vn,X→ Y 1 Y_1 Y1 Y 2 Y_2 Y2 Y 3 Y_3 Y3,
- 如果 Y 1 Y_1 Y1, Y 2 Y_2 Y2→ε,则FIrst( Y 1 Y_1 Y1)∪FIrst( Y 2 Y_2 Y2)-{ε}∈FIrst(X)
- 如果 Y 1 Y_1 Y1, Y 2 Y_2 Y2, Y 3 Y_3 Y3→ε,则FIrst( Y 1 Y_1 Y1)∪FIrst( Y 2 Y_2 Y2)∪FIrst( Y 3 Y_3 Y3)∪{ε}∈FIrst(X)
- Y更多就以此类推
- 5、重复上述步骤直到First集合不再增大
求解思路:以vn为例
遍历文法的非终结符集合,逐个求解,将结果插入到FIRST集合。
结果使用一个set<char>进行存储。
FIRST集合使用一个unordered_map哈希表存储,键为非终结符,值为所求得的结果。
- 逐个求解:
- 1、获取vn的所有右部,进行分析
- 2、遍历右部,一个个右部分析,各自求解first集加入到results
- 2.1 遍历当前右部(一个个字符分析)
- 如果第一个字符是终结符,加入first集合并且跳出循环;(这里会添加多余的空符)
- 如果是非终结符,则递归处理;
- 如果非终结符可以推空还需要循环处理该右部的下一字符(如果有)
- 3、遍历结束,最后如果该字符不能推空,就要删除results中的空符;返回result
流程图:大体如下,详细实现见代码。

4.2 求解后跟符号集Follow
总体思路:
- 1、如果X是开始符号,#∈Follow(X);
- 2、如果A→αXβ,则First(β) - {ε} ∈ Follow(X);如果β可以推空,Follow(A)∈Follow(X)
- 3、重复上述步骤直到Follow集合不再增大
求解思路:
遍历文法的非终结符集合,逐个求解,将结果插入到FOLLOW集合。然后完善follow集合直到follow集合不再增大。
结果使用一个set进行存储。
FOLLOW集合也使用一个unordered_map哈希表存储,键为非终结符,值为所求得的结果。
- 逐个求解:
- 1、对于开始符号,把#加到results
- 2、遍历当前文法所有的右侧表达式,
- 遍历当前右部进行分析,如果发现了vn,则可进行下一步骤以获取results元素
- 如果当前字符vn是最后一个字符,说明位于句尾,则把#加入,否则遍历vn后的字符
- 如果遇到终结符,直接加入到results,并break退出循环
- 否则就是非终结符,那么求其first集合,去掉空后加入到results;此时还要考虑是继续循环还是跳出循环:
如果当前字符可以推空,而且不是最后一个字符,说明还要继续分析下一个字符
如果可以推空但是是最后一个字符,那么把#加入results
如果不可以推空,直接跳出循环即可(可以推空,后面字符的first集合才有可能作为vn的follow集合)- 3、遍历完成,返回results;
- 4、完善follow集合:对于所有非终结符,若遇到后面没有字符,或者是一个可推空的字符,还要把左部的follow集合加入结果集。
- 5、往复第4步直到follow集不再变大。(这个地方使用递归求解时会由于文法的右递归陷入死循环,所以就先求一遍不考虑思路2中β推空的情况,求解第一遍follow,然后在完善follow集合的过程中考虑进去)
流程图

完善Follow集合流程图

4.3 求解可选符号集Select
总体思路
对一条产生式:A→β
- 如果β不可以推空,select(A→β) = first(β)
- 如果β可以推空,select(A→β) = (first(β)-{ε})∪follow(A)
求解思路
- 得到产生式的left和right
- 遍历右部产生式,首先分析右部第一个字符:right[0]
2.1 如果是终结符:(如果为空符,则把follow(left)加入results,否则直接把该符号加入到results),然后break
2.2 如果是非终结符:把first(right[0])-’~'加入到results;如果还可以推空,则要继续往后看(continue)。如果是最后一个字符,则把follow(left)加入results
流程图

4.4 求解预测分析表
总体思路
Select(A→BC)={a,b,c}表示:
栈顶元素为A的时候,如果输入串当前字符是a或b或c,就可以确定选用A→BC进行推导。
预测分析表就是遍历所有select将所有情况一一存储得到的。
求解思路
- 遍历select集合
- 获取left和->right;以及对应的终结符集合chars
- 遍历chars,获取单个字符ch:
把left和ch配对作为TABLE的键,而->right作为值
流程图

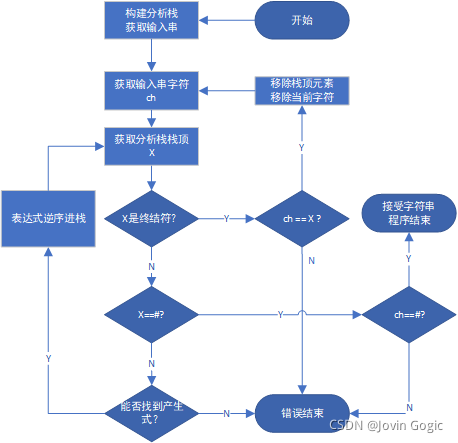
4.5 求解分析输入串
总体思路
- 首先把#和开始符S放入分析栈,设输入串的字符ch,进入分析,过程中:
- 对于栈顶元素X进行分析,如果是和ch一样的终结符说明匹配成功,否则要看能否推导(查预测分析表是否有东西)。如果能推导,产生式逆序进栈,否则文法不能接受该字符串,分析完成。
- 最后如果分析栈和输入串都只剩下#,就说明匹配成功,当前文法接受该字符串。
求解思路
- 构建先进后出栈,将#、S进栈
- 遍历句子,一个个符号送a;和栈顶送X,进入分析
- 2.1 如果X是终结符
如果和a相等,说明匹配成功:X出栈,并读取下一个字符;
否则是无法匹配:失败退出- 2.2 如果X是末尾符
a也是末尾符,接受分析字符串:成功退出
a不是末尾符,不接受分析字符串,失败退出- 2.3 否则X就是非终结符
查找预测分析表,看是否有表达式
如果没有,分析出错,失败退出
如果有,X元素出栈,表达式逆序进栈,继续循环句子且要重复分析a
- 遍历完成,程序结束
流程图
4.6 运行结果
文法 grammar.txt:
E->TG
G->+TG
G->~
T->FS
S->*FS
S->~
F->(E)
F->i
输入串:
i*(i+i)
结果图:

五、实验代码
#include <iostream>
#include <iomanip>
#include <stdio.h>
#include <fstream> // 文件流
#include <string> // 字符串
#include <algorithm> // 字符串处理
#include <unordered_map> // 哈希表
#include <map> // 图
#include <stack> // 栈
#include <set> // 集
#include <vector> //向量
using namespace std;
// 主要的全局变量定义
unordered_map<string,string> grammar;// 文法集合哈希表
string S; // 开始符
set<string> Vn; // 非终结符集
set<string> Vt; // 终结符集
set<string> formulas; // 产生式集。求解select时方便遍历
unordered_map<string, set<char>> FIRST;// FIRST集合
unordered_map<string, set<char>> FOLLOW;// FOLLOW集合
unordered_map<string, set<char>> SELECT;// Select集合
map<pair<char,char>, string> TABLE;// 预测分析表
// 函数预定义
// 功能函数
void readFile(); // 读取文件
void pretreatment(); // 预处理,简化、符号分类等
set<char> findFirstBV(string vn); // 某个非终结符的First集合(递归求解)
void findFirst(); // 使用哈希表存储
set<char> findFollowBV(string vn); // 某个非终结符的Follow集合(递归求解)
void findFollow(); // 使用哈希表存储
set<char> findSelectBF(string formula); // 某个产生式的Select集合(递归求解)
void findSelect(); // 使用哈希表存储
void isLL1(); // 判断是否为LL(1)分析
void makeTable(); // 构造预测分析表
void LL1Analyse(); // 分析字符串
// 工具函数
// 根据左部获取产生式的右部(集合)
vector<string> getRights(string left);
// 判断是终结符还是非终结符
bool isVn(char v);
bool isVt(char v);
// 判断某个非终结符能否推出空
bool canToEmpty(char v);
//判断两个字符set的交集是否为空
bool isIntersect(set<char> a, set<char> b);
// 输出分析表
void printTable();
// 得到逆序字符串
string getStackRemain(stack<char> stack_remain);
// 显示输出一个char集
void printSet(set<char> sets);
// 求FOLLOW集合中的元素个数(用于判断:直到follow集合不再增大)
int getFS();
// =====================================主函数===================================
int main() {
cout <<setw(75)<<right<<setfill('=')<< "LL(1)分析器====================" << endl << endl;
// =====================================进入核心代码:LL(1)分析==================================
// =====================================1、读取文法并且简单处理==================================
readFile();
// =====================================2、找First集=============================================
findFirst();
// =====================================3、找Follow集============================================
findFollow();
// =====================================4、找Select集============================================
findSelect();
// =====================================5、判断是否是LL1文法=====================================
isLL1();
// =====================================6、构建分析表============================================
makeTable();
// =====================================7、分析字符串============================================
LL1Analyse();
return 0;
}
// =====================================功能函数===================================
// 读取文件
void readFile() {
// 输入文件名
cout << endl << "请输入文件名:";
char file[100];
cin >> file;
// 首先展示文件所有内容
cout << endl << setw(75) << right << setfill('=') << "文法读取====================" << endl;
// ifstream文件流打开文件
ifstream fin(file);
if (!fin.is_open())
{
cout << "打开文件失败";
exit(-1); // 直接退出
}
string line;
bool isGet = false;
while (getline(fin, line)) // 逐行读取
{
if (!isGet)
{
// 得到开始符
S = line[0];
isGet = true;
}
formulas.insert(line); // 得到所有表达式
cout << line << endl; // 输出
// 如果哈希表中已经存在该键,加在后面
for (auto iter = grammar.begin(); iter != grammar.end(); ++iter) {
if (iter->first == string(1, line[0]))
{
iter->second = iter->second + "|" + line.substr(3);
break;
}
}
// 往存储文法的哈希表中插入键值对
grammar.insert(pair<string, string>(string(1, line[0]), line.substr(3)));
}
cout << "请注意~表示空" << endl;
fin.close(); // 关闭文件流
pretreatment();
}
// 简单处理:符号分类、输出显示
void pretreatment() {
cout << endl << setw(75) << right << setfill('=') << "文法简化====================" << endl;
// 遍历文法哈希表
for (auto iter = grammar.begin(); iter != grammar.end(); ++iter) {
// 输出
cout << iter->first << "→" << iter->second << endl;
// ========================================符号分类==================================
Vn.insert(iter->first); // 非终结符集
// 终结符集合
string str = iter->second;
for (size_t i = 0; i < str.length(); i++)
{
if (str[i] != '|' && (str[i] < 'A' || str[i] > 'Z'))
{
Vt.insert(string(1, str[i]));
}
}
}
cout << endl << setw(75) << right << setfill('=') << "符号分类====================" << endl;
// 输出终结符和非终结符集合
cout << "开始符号:" << S << endl;
cout << "非终结符集Vn = " << "{";
for (auto iter = Vn.begin(); iter != Vn.end(); ) {
cout << *iter;
if ((++iter) != Vn.end())
{
cout << ",";
}
}
cout << "}" << endl;
cout << "终结符集Vt = " << "{";
for (auto iter = Vt.begin(); iter != Vt.end(); ) {
cout << *iter;
if ((++iter) != Vt.end())
{
cout << ",";
}
}
cout << "}" << endl;
}
// 求某一个非终结符的First集合
set<char> findFirstBV(string vn) {
// 求解思路
//1、获取vn的右部,进行分析
//2、遍历右部,一个个右部分析,各自求解first集加入到results
//2.1 遍历当前右部(一个个字符分析)
//如果第一个字符是终结符,加入first集合并且跳出;(这里会添加多余的空符)
//如果是非终结符,则递归处理;
//如果非终结符可以推空还需要循环处理该右部的下一字符(如果有)
//3、遍历结束,最后如果该字符不能推空,就要删除results中的空符;返回结果
set<char> results; // first集存储
vector<string> rights = getRights(vn); // 获取右部
if (!rights.empty()) // 如果右部不为空
{
// 遍历右部集合(每一个右部分别求解first,加入到该非终结符的first集合中)
for (auto iter = rights.begin(); iter != rights.end();++iter) {
string right = *iter;
// 遍历当前右部: //如果第一个字符是终结符,加入first集合并且跳出循环;
//如果是非终结符,则递归处理;
//如果非终结符可以推空还需要循环处理该右部的下一字符(如果有)
for (auto ch = right.begin(); ch != right.end(); ++ch) {
if (isVn(*ch)) // 如果是非终结符,就要递归处理
{
//先查first集合。如果已经有了就不需要重复求解
if (FIRST.find(string(1, *ch)) == FIRST.end()) // fisrt集合中不存在
{
// 递归调用自身!!!
set<char> chars = findFirstBV(string(1, *ch));
// 将结果存入结果
results.insert(chars.begin(),chars.end());
FIRST.insert(pair<string,set<char>>(string(1,*ch),chars));
}
else {
// 存在就把该集合全部加到firsts(提高效率)
set<char> chars = FIRST[string(1, *ch)];
results.insert(chars.begin(), chars.end());
}
// 如果这个字符可以推空,且后面还有字符,那么还需要处理下一个字符
if (canToEmpty(*ch) && (iter + 1) != rights.end())
{
continue;
}
else
break; // 否则直接退出遍历当前右部的循环
}
else {
// 如果不是非终结符,直接把这个字符加入first集合,并且跳出
// 这一步会把前面的空也加进去(后面会删除)
results.insert(*ch);
break;
}
}
}
}
// 最后,如果该终结符不能推空,就删除空
if (!canToEmpty(vn[0]))
{
results.erase('~');
}
return results;
}
// 求解First集,使用哈希表存储
void findFirst() {
// 遍历非终结符集合,构建哈希表,便于后续查询
for (auto iter = Vn.begin(); iter != Vn.end(); ++iter) {
string vn = *iter; // 获取非终结符
set<char> firsts = findFirstBV(vn); // 存放一个Vn的first集
FIRST.insert(pair<string, set<char>>(vn, firsts));
}
// 显示输出
cout << endl << setw(75) << right << setfill('=') << "FISRT集分析====================" << endl;
for (auto iter = FIRST.begin(); iter != FIRST.end();++iter) {
cout <<"FIRST("<< iter->first<<")" << "= ";
set<char> sets = iter->second;
printSet(sets);
}
}
// 单个非终结符符求解其Follow集合
set<char> findFollowBV(string vn) {
//求解思路:
//1、对于开始符号,把#加到results
//2、遍历当前文法所有的右侧表达式,
//2.1 遍历当前右部进行分析,如果发现了vn,则可进行下一步骤以获取results元素
//如果当前字符vn是最后一个字符,说明位于句尾,则把#加入
//否则遍历vn后的字符
// 如果再次遇到vn,回退并退出循环进入外部循环
// 如果遇到终结符,直接加入到results,并break退出循环
// 否则就是非终结符,那么求其first集合,去掉空后加入到results
// 此时还要考虑是继续循环还是跳出循环:
//如果当前字符可以推空,而且不是最后一个字符,说明还要继续分析下一个字符
//如果可以推空但是是最后一个字符,那么把#加入results
//如果不可以推空,直接跳出循环即可(可以推空,后面字符的first集合才有可能作为vn的follow集合)
//3、遍历完成,返回results;具体代码如下:
set<char> results; // 存储求解结果
if (vn == S) // 如果是开始符号
{
results.insert('#'); // 把结束符加进去,因为有语句#S#
}
// 遍历文法所有的右部集合
for (auto iter = formulas.begin(); iter != formulas.end(); ++iter)
{
string right = (*iter).substr(3); // 获取当前右部
// 遍历当前右部,看是否含有当前符号
for (auto i_ch = right.begin(); i_ch != right.end();)
{
if (*i_ch == vn[0]) {
// 如果vn出现在了当前右部
if ((i_ch+1)==right.end()) // vn是当前右部最后一个字符
{
results.insert('#'); // 加入结束符
break;
}
else {
// vn后面还有字符,遍历他们(除非又遇到vn:i_ch回退一个并且进入跳出循环)
while (i_ch != right.end())
{
++i_ch;// 指针后移
if (*i_ch == vn[0])
{
--i_ch;
break;
}
if (isVn(*i_ch)) // 如果该字符是非终结符,把first集中的非空元素加进去
{
set<char> tmp_f = FIRST[string(1, *i_ch)];
tmp_f.erase('~'); // 除去空
results.insert(tmp_f.begin(), tmp_f.end());
// 还要该字符可否推空,需要考虑是否继续循环
if (canToEmpty(*i_ch))
{
if ((i_ch + 1) == right.end()) // 如果是最后一个字符,加入#
{
results.insert('#');
break;// 跳出循环
}
// 继续循环
}
else // 否则跳出循环
break;
}
else {
// 如果该字符是终结符
results.insert(*(i_ch)); // 加入该字符
break; // 跳出循环
}
}
}
}
else {
++i_ch;
}
}
}
return results;
}
// 完善Follow集合
void completeFollow(string vn) {
// 遍历文法所有的右部集合
for (auto iter = formulas.begin(); iter != formulas.end(); ++iter)
{
string right = (*iter).substr(3); // 获取当前右部
// 遍历当前右部,看是否含有当前符号
for (auto i_ch = right.begin(); i_ch != right.end();)
{
char vn_tmp = *i_ch;
if (vn_tmp == vn[0]) {
// 如果vn出现在了当前右部
if ((i_ch + 1) == right.end()) // vn是当前右部最后一个字符
{
char left = (*iter)[0];
set<char> tmp_fo = FOLLOW[string(1,left)]; // 获取左部的follow集合
set<char> follows = FOLLOW[string(1,vn_tmp)]; // 获取自己的原来的follow集合
follows.insert(tmp_fo.begin(),tmp_fo.end());
FOLLOW[vn] = follows; // 修改
break;
}
else {
// 不是最后一个字符,就要遍历之后的字符看是否可以推空
while (i_ch != right.end())
{
++i_ch; // 注意指针后移了!!!
if (canToEmpty(*i_ch))
{
if ((i_ch+1)!=right.end()) // 不是最后一个元素,就要继续看后面有没有可以推空的
{
continue;
}
else {
// 最后一个也能推空,则把左部加进去
char left = (*iter)[0];
set<char> tmp_fo = FOLLOW[string(1, left)]; // 左部的follow集合
set<char> follows = FOLLOW[string(1, vn_tmp)]; // 当前符号的follow集合
follows.insert(tmp_fo.begin(), tmp_fo.end());
FOLLOW[vn] = follows; // 修改原值
break;
}
}
else // 如果不能推空,就退出循环
break;
}
}
}
++i_ch; // 遍历寻找vn是否出现
}
}
}
// 求解Follow集,使用哈希表存储
void findFollow() {
// 遍历所有非终结符,依次求解follow集合
for (auto iter = Vn.begin(); iter != Vn.end(); ++iter) {
string vn = *iter; // 获取非终结符
set<char> follows = findFollowBV(vn); // 求解一个Vn的follow集
FOLLOW.insert(pair<string, set<char>>(vn, follows)); // 存储到哈希表,提高查询效率
}
// 完善follow集合直到follow不再增大
int old_count = getFS();
int new_count = -1;
while (old_count != new_count) // 终结符在变化,反复这个过程直到follow集合不再增大
{
old_count = getFS();
// 再次遍历非终结符,如果出现在右部最末端的,把左部的follow集加进来
for (auto iter = Vn.begin(); iter != Vn.end(); ++iter) {
string vn = *iter; // 获取非终结符
completeFollow(vn);
}
new_count = getFS();
}
// 显示输出
cout << endl << setw(75) << right << setfill('=') << "FOLLOW集分析====================" << endl;
for (auto iter = FOLLOW.begin(); iter != FOLLOW.end(); ++iter) {
cout << "FOLLOW(" << iter->first << ")" << "= ";
set<char> sets = iter->second;
printSet(sets);
}
}
// 单个表达式求解Select集合
set<char> findSelectBF(string formula) {
// 求解思路
// 1、得到产生式的left和right
// 2、遍历右部产生式,首先分析右部第一个字符:right[0]
// 如果是终结符:(如果为空符,则把follow(left)加入results,否则直接把该符号加入到results),然后break
// 如果是非终结符:把first(right[0])-'~'加入到results;如果还可以推空,则要继续往后看(continue)
set<char> results; // 存储结果
// 1、得到产生式的left和right
char left = formula[0]; // 左部
string right = formula.substr(3); // 右部
//cout << "Select集合分析" << left << "->" << right << endl;// 调试用
// 2、遍历右部产生式,首先分析右部第一个字符:right[0]
for (auto iter = right.begin(); iter != right.end(); ++iter)
{
//cout << "遍历右部" << *iter << endl; // 调试用
// 如果是非终结符:把first(right[0])-'~'加入到results;如果还可以推空,则要继续往后看(continue)
if (isVn(*iter))
{
set<char> chs = FIRST.find(string(1, *iter))->second; // 得到该符号的first、
chs.erase('~'); // 去除空符
results.insert(chs.begin(), chs.end()); // 加入select
if (canToEmpty(*iter)) // 如果可以推空,继续处理下一个字符加入到select集合
{
if ((iter+1)==right.end()) // 当前是最后一个字符,则把follow(left)加入results,然后break
{
set<char> chs = FOLLOW.find(string(1, left))->second; // 得到左部的follow
results.insert(chs.begin(), chs.end()); // 加入select
}
else {
// 继续处理下一字符
continue;
}
}else
break; // 该字符不可以推空,退出循环
}
else {
// 如果是终结符:(如果为空符,则把follow(left)加入results,否则直接把该符号加入到results),然后break
if (*iter == '~') // 如果是空
{
set<char> chs = FOLLOW.find(string(1, left))->second; // 得到左部的follow
results.insert(chs.begin(), chs.end()); // 加入select
}
else
results.insert(*iter); // 直接加入select
break; // 退出循环
}
}
return results;
}
// 求解Select集,使用哈希表存储
void findSelect() {
// 遍历表达式集合
for (auto iter = formulas.begin(); iter != formulas.end(); ++iter) {
string formula = *iter; // 获取表达式
set<char> selects = findSelectBF(formula); // 存放一个Vn的first集
SELECT.insert(pair<string, set<char>>(formula, selects)); // 插入到哈希表,提高查询效率
}
// 显示输出
cout << endl << setw(75) << right << setfill('=') << "SELECT集分析====================" << endl;
for (auto iter = SELECT.begin(); iter != SELECT.end(); ++iter) {
cout << "SELECT(" << iter->first << ")" << "= ";
set<char> sets = iter->second;
printSet(sets);
}
}
// 判断是否为LL(1)分析
void isLL1() {
// 求解思路:通过嵌套循环SELECT集合,判断不同的表达式但左部相同时的SELECT集合之间相交是否有交集
// 如果有交集说明不是LL1,否则是LL1分析
for (auto i1 = SELECT.begin(); i1 != SELECT.end(); ++i1)
{
for (auto i2 = SELECT.begin(); i2 != SELECT.end(); ++i2)
{
char left1 = (i1->first)[0]; // 获取左部2
char left2 = (i2->first)[0]; // 获取左部2
if (left1 == left2) // 左部相等
{
if (i1->first != i2->first) //表达式不一样
{
if (isIntersect(i1->second, i2->second)) {
// 如果select集合有交集
// 不是LL1文法
cout << "经过分析,您输入的文法不符合LL(1)文法,请修改后重试" << endl;
exit(0); // 直接退出
}
}
}
}
}
// 是LL(1)文法
cout << setw(75) << right << setfill('=') << "进入分析器====================" << endl << endl;
cout << "经过分析,您输入的文法符合LL(1)文法..." << endl;
}
// 构造预测分析表
void makeTable() {
cout << "正在为您构造分析表..." << endl;
// 求解思路:
// 1、遍历select集合,对于键:分为left和->right;对于值,遍历后单个字符ch:
// 把left和ch配对作为TABLE的键,而->right作为值
// map键值对的形式,空间更多,查询效率高点
char left_ch;
string right;
set<char> chars;
for (auto iter = SELECT.begin(); iter != SELECT.end(); ++iter) // 遍历select集合
{
left_ch = iter->first[0]; // 获取左部
right = iter->first.substr(1); // 获取->右部
chars = iter->second;
// 遍历chars.一个个放入
for (char ch : chars) {
// 遍历终结符
TABLE.insert(pair<pair<char, char>,string>(pair<char, char>(left_ch, ch),right));
}
}
/*cout << "分析表调试:" << TABLE.find(pair<char, char>('E', 'i'))->second;*/
// 输出分析表
printTable();
}
// 输出预测分析表
void printTable() {
// 输出分析表
cout << setw(75) << right << setfill('=') << "预测分析表====================" << endl;
cout << setw(9) << left << setfill(' ') << "VN/VT";
set<string> vts = Vt;
vts.erase("~");
vts.insert("#");
for (string str : vts) // 遍历终结符
{
cout << setw(12) << left << setfill(' ') << str;
}
cout << endl << endl;
for (string vn : Vn)
{
cout << setw(7) << left << setfill(' ') << vn;
for (string vt : vts) // 遍历终结符
{
if (TABLE.find(pair<char, char>(vn[0], vt[0])) == TABLE.end()) //如果找不到
{
cout << setw(12) << left << "ERR" << " ";
}
else {
cout << setw(12) << left << TABLE.find(pair<char, char>(vn[0], vt[0]))->second << " ";
}
}
cout << endl;
}
cout << setw(75) << setfill('=') << " " << endl;
}
// 分析字符串
void LL1Analyse() {
// 求解思路:
//1、构建先进后出栈,将#、S进栈
//2、遍历句子,一个个符号送a;和栈顶送X,进入分析
// 2.1 如果X是终结符
// 如果和a相等,说明匹配成功:X出栈,并读取下一个字符
// 否则是无法匹配:失败退出
// 2.2 如果X是末尾符
// a也是末尾符,接受分析字符串:成功退出
// a不是末尾符,不接受分析字符串,失败退出
// 2.3 否则X就是非终结符
// 查找预测分析表,看是否有表达式
// 如果没有,分析出错,失败退出
// 如果有,X元素出栈,表达式逆序进栈,继续循环句子且要重复分析a
//3、遍历完成,程序结束
cout << "构造完成,请输入您要分析的字符串..." << endl;
string str; // 输入串
cin >> str;
str.push_back('#'); // 末尾加入结束符
cout << "正在分析..." << endl;
cout << endl << setw(75) << right << setfill('=') << "分析过程====================" << endl;
cout << setw(16) << left << setfill(' ') << "步骤";
cout << setw(16) << left << setfill(' ') << "分析栈";
cout << setw(16) << left << setfill(' ') << "剩余输入串";
cout << setw(16) << left << setfill(' ') << "分析情况" << endl;
stack<char> stack_a; // 分析栈
stack_a.push('#'); // 末尾符进栈
stack_a.push(S[0]); // 开始符号进栈
// 初始化显示数据
int step = 1; // 步骤数
stack<char> stack_remain = stack_a; // 剩余分析栈
string str_remain = str; // 剩余分析串
string str_situation = "待分析"; // 分析情况
// 初始数据显示
cout << setw(16) << left << setfill(' ') << step;
cout << setw(16) << left << setfill(' ') << getStackRemain(stack_remain);
cout << setw(16) << left << setfill(' ') << str_remain << endl;
// 遍历所输入的句子,一个个字符分析
for (auto iter = str.begin(); iter != str.end();) {
char a = *iter; // 当前终结符送a
char X = stack_a.top(); // 栈顶元素送X
if (isVt(X)) // 如果X是Vt终结符,栈顶元素出栈,然后读取下一个字符
{
if (X == a) // 和输入字符匹配
{
stack_a.pop(); // 移除栈顶元素
// 从剩余分析串中移除本元素
for (auto i_r = str_remain.begin(); i_r != str_remain.end(); i_r++)
{
if (*i_r == a) {
str_remain.erase(i_r);
break; // 只删除第一个,
}
}
// 重新组装提示字符串
string msg = "“" + string(1, a) + "”匹配";
str_situation = msg;
// 读取下一个字符
++iter;
}
else {
// 无法匹配,分析出错
cout << "分析出错:" <<X<<"和" <<a<< "不匹配" << endl;
exit(-1); // 出错退出
}
}
else if (X == '#') // 文法分析结束
{
if (a == '#') // 当前符号也是最后一个符号 , 接受分析结果
{
cout << "分析结束,当前文法接受您输入的字符串" << endl;
exit(0); // 成功退出
}
else {
cout << "分析出错,文法结束输入串未结束" << endl;
exit(-1);
}
}
else {
// X 就是非终结符了
// 查看TABLE(X,a)是否有结果
if (TABLE.find(pair<char, char>(X, a)) == TABLE.end()) //如果找不到
{
if (!canToEmpty(X)) // 也不能推空
{
cout << "分析出错,找不到表达式" << endl;
exit(-1); // 失败退出
}
else {
// 可以推空,
stack_a.pop(); // 移除栈顶元素 // 重新组装字符串
str_situation.clear();
str_situation.push_back(X);
str_situation = str_situation + "->";
str_situation = str_situation + "~";
}
}
else {
stack_a.pop();// 先将当前符号出栈
string str = TABLE.find(pair<char, char>(X, a))->second.substr(2); // 获取表达式并且逆序进栈(除去->)
// 重新组装字符串
str_situation.clear();
str_situation.push_back(X);
str_situation = str_situation + "->";
str_situation = str_situation +str;
reverse(str.begin(),str.end());
for (auto iiter = str.begin(); iiter != str.end(); ++iiter)
{
if (*iiter != '~')
{
stack_a.push(*iiter);
}
}
// (要继续识别该字符)
}
}
// 重置显示数据
++step; // 步骤数加1
stack_remain = stack_a; // 置剩余栈为当前栈
// 每次循环显示一次
cout << setw(16) << left << setfill(' ') << step;
cout << setw(16) << left << setfill(' ') << getStackRemain(stack_remain);
cout << setw(16) << left << setfill(' ') << str_remain;
cout << setw(16) << left << setfill(' ') << str_situation << endl;
}
}
// =====================================工具函数===================================
// 根据左部返回某一产生式的右部集合
vector<string> getRights(string left)
{
vector<string> rights;
if (grammar.find(left)== grammar.end()) // 语法中没有这一项,直接返回空
{
return rights;
}
else {
string str = grammar.find(left)->second;
str = str + '|'; // 末尾再加一个分隔符以便截取最后一段数据
size_t pos = str.find('|');//find函数的返回值,若找到分隔符返回分隔符第一次出现的位置,
//否则返回npos
//此处用size_t类型是为了返回位置
while (pos != string::npos)
{
string x = str.substr(0, pos);//substr函数,获得子字符串
rights.push_back(x); // 存入right容器
str = str.substr(pos + 1); // 更新字符串
pos = str.find('|'); // 更新分隔符位置
}
return rights;
}
}
// 判断是终结符还是非终结符
bool isVn(char v) {
if (v >= 'A' && v <= 'Z') {
// 大写字母就是非终结符
return true;
}
else {
return false;
}
}
bool isVt(char v) {
if (isVn(v) || v == '#' || v == '|') // 如果是非终结符、末尾符号、分隔符,都不是终结符
{
return false;
}
return true;
}
// 判断某个非终结符能否推出空
bool canToEmpty(char vn) {
vector<string> rights = getRights(string(1,vn)); // vn可能推出的右部集
for (auto i = rights.begin();i!=rights.end();++i) // 遍历右部集合(如果前面的右部可以推空可提前跳出,不然就要看到最后)
{
string right = *i; // 此为一个右部
// 遍历这个右部
for (auto ch = right.begin(); ch != right.end(); ++ch) {
if ((*ch)=='~')// 如果ch为空,说明可以推空(因为不可能存在右部是"εb"这样的情况,不需要看是否是最后一个字符)
{
return true;
}
else if (isVn(*ch)) {
// 如果是vn则需要递归
if (canToEmpty(*ch))// 如果可以推空
{
// 而且是最后一个字符,则返回true
//这里可能存在"AD"A->εD不能推空的情况,所以需要看是否最后一个字符
if ((ch + 1) == right.end())
{
return true;
}
continue; // 当前字符可以推空,但不是最后一个字符,无法确定能否推空,还需要看右部的下一个字符
}
else // 如果不可以推空,说明当前右部不可以推空,需要看下一个右部
break;
}
else // 如果是非空vt说明目前右部不能推空,需要看下一个右部
break;
}
}
return false;
}
// 判断两个字符set的交集是否为空
bool isIntersect(set<char> as, set<char> bs) {
for (char a : as) {
for (char b : bs) {
if (a == b)
{
return true;
}
}
}
return false;
}
// 得到逆序字符串
string getStackRemain(stack<char> stack_remain) {
string str;// 剩余分析栈串
while (!stack_remain.empty())
{
str.push_back(stack_remain.top());
stack_remain.pop();// 出栈
}
reverse(str.begin(),str.end());
return str;
}
// 显示输出一个char集
void printSet(set<char> sets) {
cout << "{ ";
for (auto i = sets.begin(); i != sets.end();) {
cout << *i;
if (++i != sets.end())
{
cout << " ,";
}
}
cout << " }" << endl;
}
// 求FOLLOW集合中的元素个数
int getFS() {
int count = 0;
for (auto iter = FOLLOW.begin(); iter != FOLLOW.end(); ++iter) {
count = count + iter->second.size();
}
return count;
}