编译原理-LL1语法分析器(消除左递归+消除回溯)
实验要求:
要求一
1、 给出文法如下:
G[E]:
E->T|E+T;
T->F|T*F;
F->i|(E);
2、 根据该文法构造相应的LL(1)文法及LL(1)分析表,并为该文法设计预测分析程序,利用C语言或C++语言或Java语言实现;
3、 利用预测分析程序完成下列功能:
1) 手工将测试的表达式写入文本文件,每个表达式写一行,用“;”表示结束;
2) 读入文本文件中的表达式;
3) 调用实验一中的词法分析程序搜索单词;
4) 把单词送入预测分析程序,判断表达式是否正确(是否是给出文法的语言),若错误,应给出错误信息;
5) 完成上述功能,有余力的同学可以进一步完成通过程序实现对非LL(1)文法到LL(1)文法的自动转换
要求二
1、 将一个可转换的非LL(1)文法转换为LL(1)文法,要经过两个阶段,1)消除文法左递归,2)提取左因子,消除回溯。
2、 提取文法左因子算法:
1)对文法G的所有非终结符进行排序
2)按上述顺序对每一个非终结符Pi依次执行:
for( j=1; j< i-1;j++)
将Pj代入Pi的产生式(若可代入的话);
消除关于Pi的直接左递归:
Pi -> Piα|β ,其中β不以Pi开头,则修改产生式为:
Pi —> βPi′
Pi′—> αPi′|ε
3)化简上述所得文法。
3、 提取左因子的算法:
A —> δβ1|δβ2|…|δβn|γ1|γ2|…|γm
(其中,每个γ不以δ开头)
那么,可以把这些产生式改写成
A —> δA′|γ1| γ2…|γm
A′—>β1|β2|…|βn
4、 利用上述算法,实现构造一个LL(1)文法:
1) 读入文法,利用实验二附加资料2的实验要求将文法存入设计的数据结构;
2) 设计函数remove_left_recursion()和remove_left_gene()实现消除左递归和提取左因子算法,分别对文法进行操作,消除文法中的左递归和提出左因子;
3) 整理得到的新文法;
4) 在一个新的文本文件输出文法,文法输出按照一个非终结符号一行,开始符号引出的产生式写在第一行,同一个非终结符号的候选式用“|”分隔的方式输出。
要求三
1、 了解文法定义的4个部分:
G(Vn, Vt, S, P)
Vn 文法的非终结符号集合,在实验中用大写的英文字母表示;
Vt 文法的终结符号集合,在实验中用小写的英文字母表示;
S 开始符号,在实验中是Vn集合中的一个元素;
P 产生式,分左部和右部,左部为非终结符号中的一个,右部为终结符号或非终结符号组成的字符串,如S->ab|c
2、 根据文法各个部分的性质,设计一个合理的数据结构用来表示文法,
1) 若使用C语言编写,则文法可以设计成结构体形式,结构体中应包含上述的4部分,
2) 若使用C++语言编写,则文法可以设计成文法类形式,类中至少含有4个数据成员,分别表示上述4个部分
文法数据结构的具体设计由学生根据自己想法完成,并使用C或C++语言实现设计的数据结构。
3、 利用完成的数据结构完成以下功能:
1) 从文本文件中读入文法(文法事先应写入文本文件);
2) 根据文法产生式的结构,分析出文法的4个部分,分别写入定义好的文法数据结构的相应部分;
3) 整理文法的结构;
4) 在计算机屏幕或者文本框中输出文法,文法输出按照一个非终结符号一行,开始符号引出的产生式写在第一行,同一个非终结符号的候选式用“|”分隔的方式输出。
代码
#include <iostream>
#include <string>
#include <fstream>
#include <set>
#include <map>
#include <iomanip>
#include <stack>
using namespace std;
const int maxnlen = 1e4;
class Grammar {
private:
set<char>Vn;
set<char>Vt;
char S;
map<char, set<string> > P;
map<char,set<char> >FIRST;
map<char,set<char> >FOLLOW;
map<string, string>Table;
public:
Grammar(string filename) {
Vn.clear();
Vt.clear();
P.clear();
FIRST.clear();
FOLLOW.clear();
ifstream in(filename);
if (!in.is_open()) {
cout << "文法 文件打开失败" << endl;
exit(1);
}
char *buffer = new char[maxnlen];
in.getline(buffer, maxnlen, '#');
string temps = "";
bool is_sethead = 0;
for (int i = 0; i < strlen(buffer); i++) {
if (buffer[i] == '\n' || buffer[i] == ' ')continue;
if (buffer[i] == ';') {
if (!is_sethead) {
this->setHead(temps[0]);
is_sethead = 1;
}
this->add(temps);
temps = "";
}
else
temps += buffer[i];
}
delete buffer;
/*
输出Vn,Vt,set
*/
}
void setHead(char c) {
S = c;
}
void add(string s) {
char s1 = s[0];
string s2="";
int num = 0;
for (int i = 0; i < s.length() ; i++) {
if (s[i] == '>')num=i;
if (num == 0)continue;
if (i > num)
s2 += s[i];
}
s2 += ';';
Vn.insert(s1);
string temp = "";
for (char s : s2) {
if (!isupper(s) && s != '|'&&s != ';'&&s!='@')Vt.insert(s);
if (s == '|' || s == ';') {
P[s1].insert(temp);
temp = "";
}
else {
temp += s;
}
}
}
void print() {
cout << "当前分析文法为:" << endl << endl;
for (set<char>::iterator it = Vn.begin(); it != Vn.end(); it++) {
char cur_s = *it;
for (set<string>::iterator it1 = P[cur_s].begin(); it1 != P[cur_s].end(); it1++) {
string cur_string = *it1;
cout << cur_s << "->" << cur_string << endl;
}
}
}
void getFirst() {
FIRST.clear();
//判断迭代次数
int iter = 4;
while (iter--) {
for (set<char>::iterator it = Vn.begin(); it != Vn.end(); it++) {
char cur_s = *it;
/*
cur_s->cur_string[0]
a加到A的FIRST集
cur_s->cur_string[0]
B的FITRST集加到A的FIRST集
*/
for (set<string>::iterator it1 = P[cur_s].begin(); it1 != P[cur_s].end(); it1++) {
string cur_string = *it1;
if (!isupper(cur_string[0])) {
FIRST[cur_s].insert(cur_string[0]);
}
else {
char nxt_s = cur_string[0];
for (set<char>::iterator it2 = FIRST[nxt_s].begin(); it2 != FIRST[nxt_s].end(); it2++) {
if ((*it2) != '@') {
FIRST[cur_s].insert(*it2);
}
}
}
}
}
}
//输出FIRST集
cout << "FIRST集为:" << endl << endl;
for (set<char>::iterator it = Vn.begin(); it != Vn.end();it++) {
char cur_s = *it;
cout << "FIRST() " << cur_s ;
for (set<char>::iterator it1 = FIRST[cur_s].begin(); it1 != FIRST[cur_s].end(); it1++) {
cout<<" " << *it1 ;
}
cout << endl;
}
}
void getFollow() {
FOLLOW.clear();
FOLLOW[S].insert('#');
//判断迭代次数
int iter = 4;
while (iter--) {
for (set<char>::iterator it = Vn.begin(); it != Vn.end(); it++) {
char cur_s = *it;
/*
cur_s->cur_string[0]
a加到A的FIRST集
cur_s->cur_string[0]
B的FITRST集加到A的FIRST集
*/
for (set<string>::iterator it1 = P[cur_s].begin(); it1 != P[cur_s].end(); it1++) {
string cur_string = *it1;
for (int i = 0; i < cur_string.length() - 1; i++) {
/*
B->Ac
将c加到A的follow集
*/
if (isupper(cur_string[i]) && !isupper(cur_string[i + 1])) {
FOLLOW[cur_string[i]].insert(cur_string[i + 1]);
}
/*
B->AC
将C的first集加到A的follow集
*/
if (isupper(cur_string[i]) && isupper(cur_string[i + 1])) {
//遍历C的first去除@,加到A的follow集
for (auto it2 = FIRST[cur_string[i + 1]].begin(); it2 != FIRST[cur_string[i + 1]].end(); it2++) {
if((*it2)!='@')
FOLLOW[cur_string[i]].insert(*it2);
}
}
}
/*
AC/ACK为最后两个或者三个
B->AC
B->ACK(K的first集含有@)
将B的follow集加入到C的follow集
*/
int len = cur_string.length();
if ( (len>=1&&isupper(cur_string[len - 1])) ) {
for (auto it2 = FOLLOW[cur_s].begin(); it2 != FOLLOW[cur_s].end(); it2++) {
if(isupper(cur_string[len - 1]))
FOLLOW[cur_string[len - 1]].insert(*it2);
}
}
if ((len >= 2 && isupper(cur_string[len - 2]) && isupper(cur_string[len - 1]) && FIRST[cur_string[len - 1]].count('@') > 0)) {
for (auto it2 = FOLLOW[cur_s].begin(); it2 != FOLLOW[cur_s].end(); it2++) {
FOLLOW[cur_string[len - 2]].insert(*it2);
}
}
}
}
}
//输出FOLLOW集
cout << "FOLLOW集为:" << endl << endl;
for (set<char>::iterator it = Vn.begin(); it != Vn.end(); it++) {
char cur_s = *it;
cout << "FOLLOW() " << cur_s;
for (set<char>::iterator it1 = FOLLOW[cur_s].begin(); it1 != FOLLOW[cur_s].end(); it1++) {
cout << " " << *it1;
}
cout << endl;
}
}
void getTable() {
set<char>Vt_temp;
for (char c : Vt) {
Vt_temp.insert(c);
}
Vt_temp.insert('#');
for (auto it = Vn.begin(); it != Vn.end(); it++) {
char cur_s = *it;
for (auto it1 = P[cur_s].begin(); it1 != P[cur_s].end(); it1++) {
/*
产生式为
cur_s->cur_string
*/
string cur_string = *it1;
if (isupper(cur_string[0])) {
char first_s = cur_string[0];
for (auto it2 = FIRST[first_s].begin(); it2 != FIRST[first_s].end(); it2++) {
string TableLeft = "";
TableLeft = TableLeft +cur_s + *it2;
Table[TableLeft] = cur_string;
}
}
else {
string TableLeft = "";
TableLeft = TableLeft+ cur_s + cur_string[0];
Table[TableLeft] = cur_string;
}
}
if (FIRST[cur_s].count('@') > 0) {
for (auto it1 = FOLLOW[cur_s].begin(); it1 != FOLLOW[cur_s].end(); it1++) {
string TableLeft = "";
TableLeft =TableLeft+ cur_s + *it1;
Table[TableLeft] = "@";
}
}
}
/*
检查出错信息:即表格中没有出现过的
*/
for (auto it = Vn.begin(); it != Vn.end(); it++) {
for (auto it1 = Vt_temp.begin(); it1 != Vt_temp.end(); it1++) {
string TableLeft = "";
TableLeft =TableLeft+ *it + *it1;
if (!Table.count(TableLeft)) {
Table[TableLeft] = "error";
}
}
}
/*
显示Table
*/
cout << "显示table表:" << endl << endl;
cout.setf(std::ios::left);
for (auto it1 = Vt_temp.begin(); it1 != Vt_temp.end(); it1++) {
if (it1 == Vt_temp.begin())cout << setw(10) << " ";
cout << setw(10) << *it1;
}
cout << endl;
for (auto it = Vn.begin(); it != Vn.end(); it++) {
for (auto it1 = Vt_temp.begin(); it1 != Vt_temp.end(); it1++) {
string TableLeft="";
if (it1 == Vt_temp.begin())cout << setw(10) << *it;
TableLeft =TableLeft+ *it + *it1;
cout << *it << "->" << setw(7) << Table[TableLeft];
}
cout << endl;
}
}
/*
每一次分析一个输入串
Sign为符号栈,出栈字符为x
输入字符串当前字符为a
*/
bool AnalyzePredict(string inputstring){
stack<char>Sign;
Sign.push('#');
Sign.push(S);
int StringPtr = 0;
char a = inputstring[StringPtr++];
bool flag = true;
while (flag) {
char x = Sign.top();
Sign.pop();
//如果是终结符,直接移出符号栈
if (Vt.count(x)) {
if (x == a)a = inputstring[StringPtr++];
else
return false;
}
else {
//如果不是终结符,
//如果是末尾符号
if (x == '#') {
if (x == a)flag = false;
else
return false;
}
else {
//如果是非终结符,需要移进操作
string left = "";
left += x;
left += a;
if (Table[left] != "error") {
string right = Table[left];
// cout << left << "---->" << right << endl;
for (int i = right.length() - 1; i >= 0; i--) {
Sign.push(right[i]);
}
}
else {
return false;
}
}
}
}
return true;
}
/*
消除左递归
*/
void remove_left_recursion(){
string tempVn = "";
for (auto it = Vn.begin(); it != Vn.end(); it++) {
tempVn += *it;
}
for (int i = 0; i < tempVn.length(); i++) {
char pi = tempVn[i];
set<string>NewPRight;
for (auto it = P[pi].begin(); it != P[pi].end(); it++) {
bool isget = 0;
string right = *it;
for (int j = 0; j < i; j++) {
char pj = tempVn[j];
if (pj == right[0]) {
isget = 1;
for (auto it1 = P[pj].begin(); it1 != P[pj].end(); it1++) {
string s = *it1 + right.substr(1);
NewPRight.insert(s);
}
}
}
if (isget == 0) {
NewPRight.insert(right);
}
}
/*
for (int j = 0; j < i; j++) {
char pj=tempVn[j];
for (auto it = P[pi].begin(); it != P[pi].end(); it++) {
string right = *it;
if (right[0] == pj) {
for (auto itpj = P[pj].begin(); itpj != P[pj].end(); itpj++) {
string s = *itpj + right.substr(1);
NewPRight.insert(s);
}
}
else {
NewPRight.insert(right);
}
}
}
*/
if(i!=0)
P[pi] = NewPRight;
remove_left_gene(pi);
}
}
/*
提取左因子
*/
void remove_left_gene(char c) {
char NewVn;
for (int i = 0; i < 26; i++) {
NewVn = i + 'A';
if (!Vn.count(NewVn)) {
break;
}
}
bool isaddNewVn = 0;
for (auto it = P[c].begin(); it != P[c].end(); it++) {
string right = *it;
if (right[0] == c) {
isaddNewVn = 1;
break;
}
}
if (isaddNewVn) {
set<string>NewPRight;
set<string>NewPNewVn;
for (auto it = P[c].begin(); it != P[c].end(); it++) {
string right = *it;
if (right[0] != c) {
right += NewVn;
NewPRight.insert(right);
}
else {
right = right.substr(1);
right += NewVn;
NewPNewVn.insert(right);
}
}
Vn.insert(NewVn);
NewPNewVn.insert("@");
P[NewVn] = NewPNewVn;
P[c] = NewPRight;
}
}
void ShowByTogether() {
for (auto it = Vn.begin(); it != Vn.end(); it++) {
cout << *it << "->";
char c = *it;
for (auto it1 = P[c].begin(); it1 != P[c].end(); it1++) {
if (it1 == P[c].begin())cout << *it1;
else
cout << "|" << *it1;
}
cout << endl;
}
}
};
int main() {
/*
文法测试
E->T|E+T;
T->F|T*F;
F->i|(E);
A->+TA|@;
B->*FB|@;
E->TA;
F->(E)|i;
T->FB;
直接将上面两个测试样例放在Gramar_test.txt中
*/
string filename_gramer = "D:\\c++Project\\fundamentals_of_compiling\\Parsing\\Gramar_test.txt";
Grammar *grammar=new Grammar(filename_gramer);
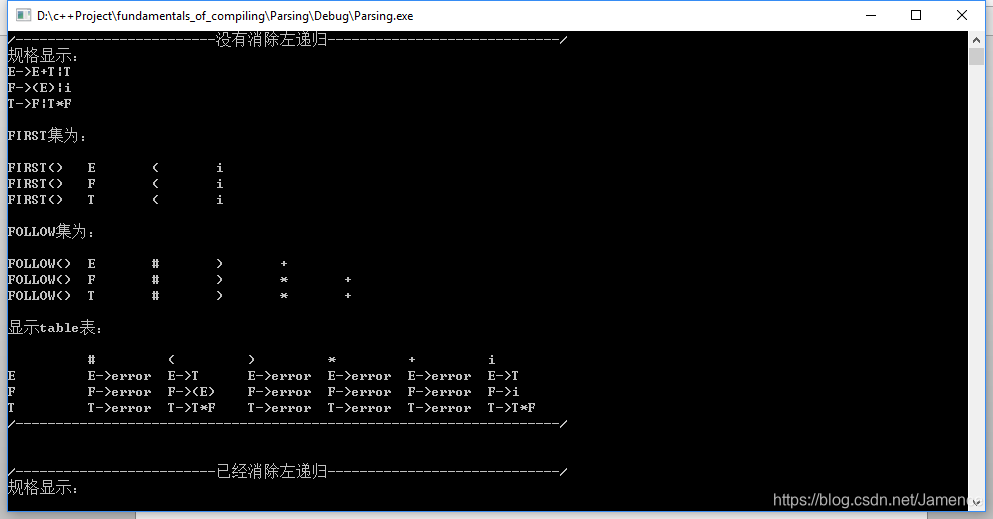
cout << "/-------------------------没有消除左递归-----------------------------/" << endl;
cout << "规格显示:" << endl;
grammar->ShowByTogether();
cout << endl;
grammar->getFirst();
cout << endl;
grammar->getFollow();
cout << endl;
grammar->getTable();
cout << "/--------------------------------------------------------------------/" << endl<<endl<<endl;
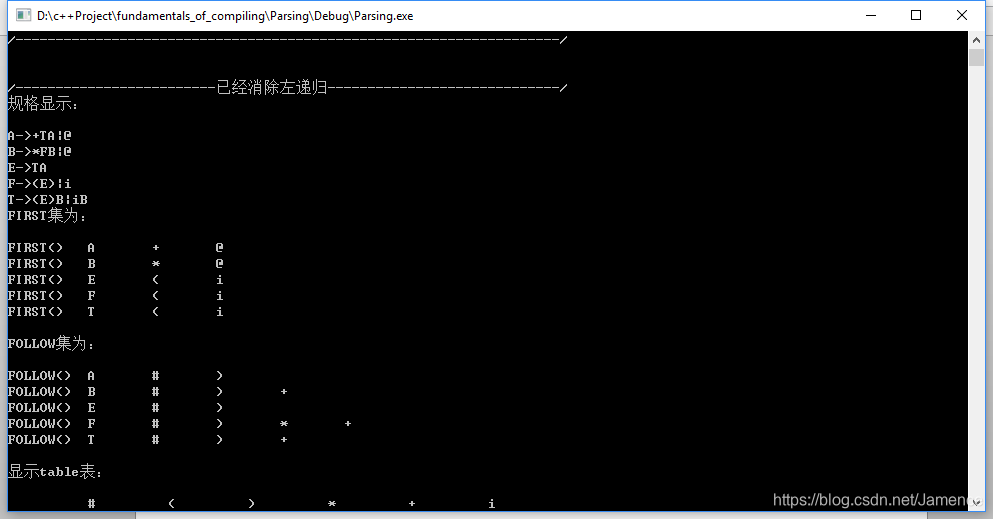
cout << "/-------------------------已经消除左递归-----------------------------/" << endl;
/*
消除左递归之后的判断
*/
grammar->remove_left_recursion();
cout << "规格显示:" << endl;
cout << endl;
grammar->ShowByTogether();
grammar->getFirst();
cout << endl;
grammar->getFollow();
cout << endl;
grammar->getTable();
cout << "/--------------------------------------------------------------------/" << endl << endl << endl;
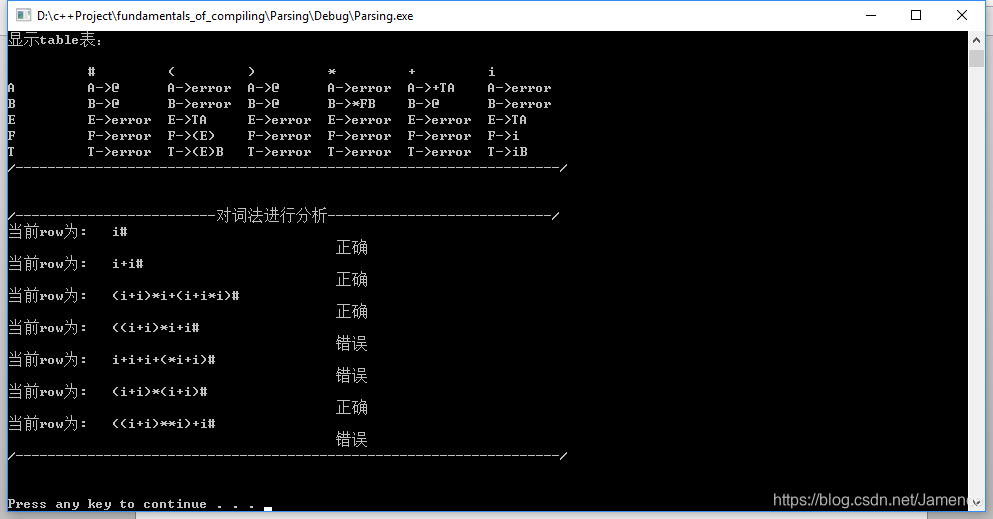
cout << "/-------------------------对词法进行分析----------------------------/" << endl;
/*
目前的想法是使用第一个实验分离出不同的单词,对单词操作,
如果单词为+,*,等于他本身,否则等于i;
以下直接使用实验一的输出文本
*/
string filename= "D:\\c++Project\\fundamentals_of_compiling\\Parsing\\out.txt";
ifstream in(filename);
char buffer[200];
string inf="";
int num = 0;
// cout << "文法分析结果为:" << endl << endl;
if (in.is_open()) {
while (!in.eof()) {
in.getline(buffer, 100);
// cout << buffer << endl;
inf += buffer;
num++;
}
}
string row = "";
for (int i = 0; i < num-1; i++) {
int ptr = i * 13;
string temp = "";
for (int j = 1; j <= 5; j++) {
if (inf[j+ptr] == ' ')continue;
else
temp += inf[ptr+j];
}
if (temp == "+" || temp == "-" || temp == "*" || temp == "/" || temp == ">" || temp == "<" || temp == "=" || temp == "(" || temp == ")") {
row += temp;
}
else {
if (temp == ";") {
row += "#";
cout << "当前row为: " << row << endl;
if (grammar->AnalyzePredict(row)) {
cout << " 正确" << endl;
}
else
cout << " 错误" << endl;
row = "";
}
else {
row += "i";
}
}
}
cout << "/--------------------------------------------------------------------/" << endl << endl << endl;
system("pause");
return 0;
}
实验截图
实验代码结果显示部分非常详细,其中我实现了自动生成FITST集,FOLLOW集,显示table表,消除左递归。
另外为了对比,我将未消除左递归的结果和已经消除的结果做对比,我们会发现不同。