写在开头
当老师说这个实验最好写成图形界面时,我笑了(滑稽),心想终于可以用到python了,python真香,用python的数据结构可以很方便的表示LL1的某些东西(当然有利也有弊,方便的同时也会有一些坑)。当然Java也牛逼,Java的图形库有些东西用起来比python的还要方便。只是本人当前最熟的就是python。
准备工作
(熟悉python的可以跳过)首先至少得会基础的python语法,图形化界面的一些术语得熟悉,比如控件啊,窗口啊,事件循环啊等等。
这里用到图形库是最简单的python自带库tkinter,个人认为应付这次实验足以,没必要用其他高端的库比如Qt(其实是不熟)。
python版本是3.7,IDE是用的PyCharm专业版,用它还能生成一个简单的类图(没有表示关系的各种箭头)。想用专业版的小伙伴可以出门左拐搜搜怎么破解,或者去学校注册个学生邮箱,用这个邮箱申请个jetbrain账号,然后jetbrain全家桶就能免费使用一年啦。
先看看功能
(1)判断所选文法是否含直接或间接左递归,若有,则消除左递归;
(2)判断该文法是否含最左公因子,若有,提取左公因子并修改文法;
(3)求该文法所有非终结符的FIRST集和FOLLOW集;
(4)判断所选文法是否符合LL(1)文法的三个条件;
(5)由FIRST集和FOLLOW集建立该文法的预测分析表;
(6)利用分析表对该文法的一个句型进行分析;
(7)在图形界面上执行所有操作,并对可能出现的异常进行处理。
干货开始
先贴一个示例文法:
E->TG
G->+TG|-TG|ε
T->FS
S->*FS|/FS|ε
F->(E)|i
后面都以此文法为例。
在一个py文件里,放定义三个类,文法类Grammar,图形界面类LL1GUI,堆栈类Stack。文法类对象作为图形界面类对象的一个变量,堆栈类对象也作为图形界面类的一个变量。先看一个类图:
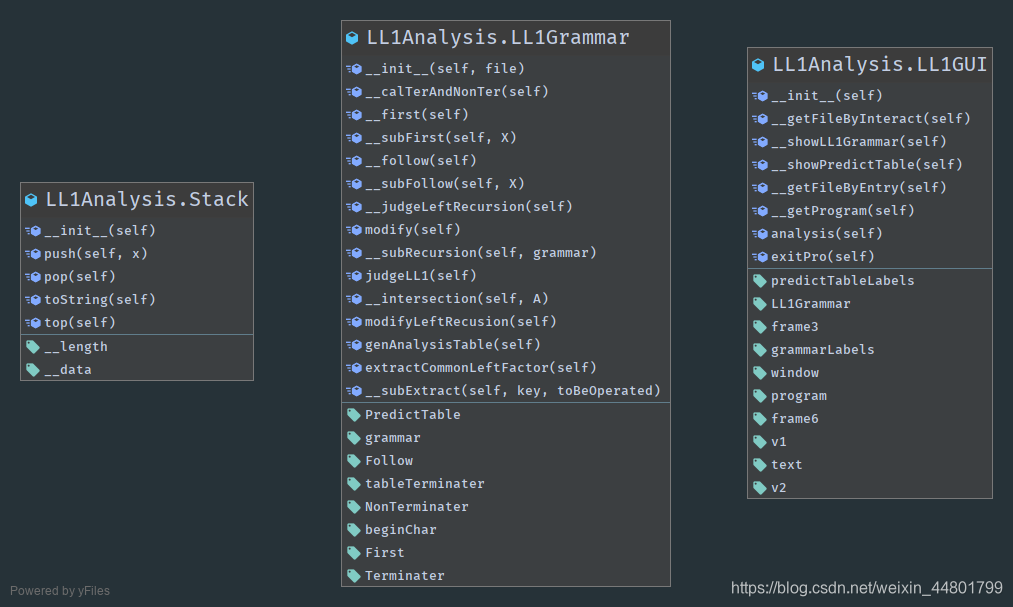
总控程序在GUI类里面。程序整体思路是:
打开文法文件->求终结符和非终结符->判断文法是否左递归并修改->求FIRST集和FOLLOW集->判断是否符合LL1文法条件->生成预测分析表->等待输入待分析句型->执行分析。
先看一下初始化界面:
选择文法后界面:
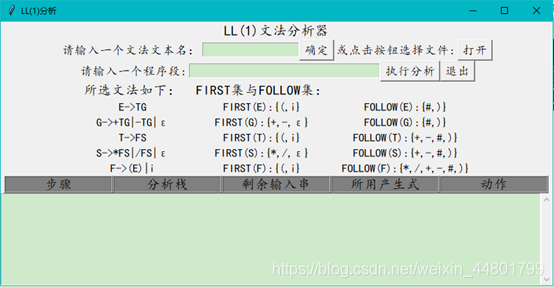
核心算法思路
文法表示:用python的字典来表示,以非终结符作为键,产生式组成的列表为值。程序里变量定义为self.grammar。
求FIRST集
书上的FIRST集求法是循环法,一直迭代迭代,反复求,直到所有符号的FIRST集大小不再变化为止。我觉得可能实现起来会有一些麻烦,于是就使用了递归的思路,遍历每个产生式,如果产生式右边第一个字符是非终结符(比如T->FS),就递归的去求它的FIRST集,求完后再看符号F和S的FIRST集里面有没有空字,再给T的FIRST集赋值。
python代码:
# 求一个文法的所有first集,定义成私有方法,只在创建对象时由初始化函数调用
def __first(self):
for nT in self.NonTerminater: #先赋值一个空列表
self.First[nT] = []
# 后面要用到递归,所以分开两个循环
for T in self.Terminater: # 终结符的first集就是他自己
self.First[T] = [T]
for nT in self.NonTerminater:
self.__subFirst(nT)
# 求first集的递归子方法
def __subFirst(self, X):
tmpSize = len(self.First[X]) # 求之前的大小
if X in self.Terminater and X not in self.First[X]: #如果X在终结符里, 则X属于first(X)
self.First[X].append(X)
else : # else X就不是终结符,对X的每个推导,依次判断推导的字符是什么
for derivation in self.grammar[X]:
# 先判断是不是空字,是空字就加入
if derivation == '':
if '' not in self.First[X]:
self.First[X].append('')
# 再判断每个推导的第一个字符是不是终结符,是则加入
elif derivation[0] in self.Terminater:
if derivation[0] not in self.First[X]:
self.First[X].append(derivation[0])
else:
# else,就全是非终结符,
# 再遍历他们,递归的求每个字符的first集
for subDe in derivation:
self.__subFirst(subDe)
# 对每个推导都处理完后,把每个推导的first集放到first(x)中
for derivation in self.grammar[X]:
if derivation == '' or derivation[0] in self.Terminater:
continue
# 找每个推导串中第一个不能推导出空字的非终结符
location = -1
for i in range(len(derivation)):
if '' not in self.grammar[derivation[i]]:
location = i
break
if location == -1: # 如果都能推出空字,
# 就把所有推导式子字符的first集加入first(X)
for subDe in derivation:
for ele in self.First[subDe]:
if ele not in self.First[X]:
self.First[X].append(ele)
else : # 否则从第一个不能推导出空字的非终结符开始
for i in range(location + 1):
for ele in self.First[derivation[i]]:
if ele != '' and ele not in self.First[X]:
self.First[X].append(ele)
if len(self.First[X]) == tmpSize: # 长度不变就返回
return
求FOLLOW集
基本思路跟跟求FIRST集差不多,不过这次变成循环法。还是用两个方法来求,第一个方法用一个循环,调用第二个方法求每个非终结符X的FOLLOW集。先把‘#’放到开始符号的FOLLOW集中,遍历每个产生式,看产生式右边,再遍历产生式的每个字符,如果碰到X,再看它后面的字符,是终结符a就加入FOLLOW(X)中,否则就是非终结符Y,把FIRST(Y)中除空字以外的字符都给FOLLOW(X)。
python程序:
def __follow(self):
for nT in self.NonTerminater:
self.Follow[nT] = [] # 同样赋值一个空列表
self.Follow[self.NonTerminater[0]].append('#') # 将’#‘加入开始符号的follow集中
for nT in self.NonTerminater:
self.__subFollow(nT)
# 求follow集的递归子程序
def __subFollow(self, X):
for key in self.grammar.keys(): # 遍历每个推导式子
for derivation in self.grammar[key]: # 对每个推导式,遍历子字符
lenOfDe = len(derivation)
for i in range(lenOfDe):
if X == derivation[i]: # 在产生式中找到要求的
if i == lenOfDe - 1: # 如果他在推导式的最后一个字符
for f in self.Follow[key]:
if f not in self.Follow[X] and f is not '':
self.Follow[X].append(f)
# 否则如果他后面跟的不是非终结符,就把这个符号放到follow(X)里
elif derivation[i + 1] not in self.NonTerminater:
# print(X, '后面是', derivation[i + 1])
if derivation[i + 1] not in self.Follow[X]:
self.Follow[X].append(derivation[i + 1])
# 如果后面跟了一个非终结符Y
elif derivation[i + 1] in self.NonTerminater:
# 就把first(Y)给它
for f in self.First[derivation[i + 1]]:
if f not in self.Follow[X] and f is not '':
self.Follow[X].append(f)
# 再额外判断空字是否属于first(Y)
if '' in self.First[derivation[i + 1]]:
for f in self.Follow[key]:
if f not in self.Follow[X] and f is not '':
self.Follow[X].append(f)
求预测分析表
有了FIRST集和FOLLOW集,就能求预测分析表了,预测分析表用二维字典来表示,第一维的键是非终结符,第二维的键是终结符。这样就能像二维数组那样来索引某一个值了,例如表名叫table,table[‘S’][’/’] = ‘S->/FS’。
求法:对每个非终结符X而言,把FIRST(X)里的字符对应的位置的值设为相应的产生式,例如FIRST(E)= {(, i},则table[‘E’][’(’]和table[‘E’][‘i’]的值都为’E->TG’,如果空字∈FIRST(X),则把FOLLOW(X)里的终结符对应的位置的值设为‘X->ε’。
python代码:
def genAnalysisTable(self):
# 用一个二维字典来表示分析表,这样索引的时候好查
self.PredictTable = {
}
# 先定义一个分析表终结符
self.tableTerminater = self.Terminater.copy()
for first in self.First.values():
for f in first:
if f not in self.tableTerminater:
self.tableTerminater.append(f)
for follow in self.Follow.values():
for f in follow:
if f not in self.tableTerminater:
self.tableTerminater.append(f)
if '' in self.tableTerminater: # 把空字去掉,因为空字不能出现在follow集中
self.tableTerminater.remove('')
# print('预测分析表如下:')
for nT in self.NonTerminater:
self.PredictTable[nT] = {
}
for T in self.tableTerminater:
derivation = self.grammar[nT]
if T in derivation: # 先判断是不是能直接推导
self.PredictTable[nT][T] = nT + '->' + T
elif T in self.First[nT]: # 否则再判是不是在first集中
find = False
for de in derivation:
if T in de:
self.PredictTable[nT][T] = nT + '->' + de
find = True
break
if not find:
for de in derivation:
for subDe in de:
if T in self.First[subDe]:
self.PredictTable[nT][T] = nT + '->' + de
find = True
break
if find:
break
elif T in self.Follow[nT]: # 如果出现在follow集中,再看空子是不是他的推导式其中之一
if '' in derivation:
for fo in self.Follow[nT]:
self.PredictTable[nT][fo] = nT + '->ε'
else:
self.PredictTable[nT][T] = ''
else:
self.PredictTable[nT][T] = ''
其他算法
其他算法比如消除左递归、判断LL1文法等见后面完整程序,程序里面有详细注释。
看一下结果
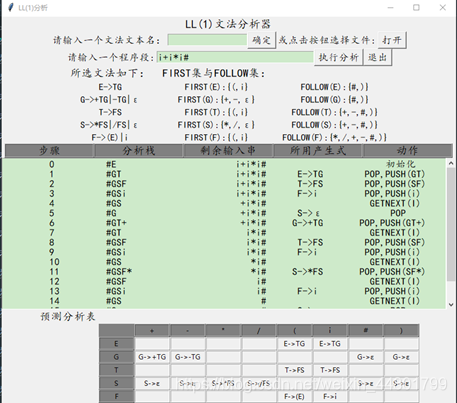
示例文法的FIRST集和FOLLOW集还有预测分析表求出来如下:
完整代码
代码、文法、类图都放到了GitHub上,连接:
https://github.com/pip-install-zjj/complie

总结
程序中用到的python的一些数据结构因为独特的对象机制,编写代码过程很容易出现莫名其妙的错误,我在调试时就碰到了好多,改了几次才改出来 。还有就是GUI的一些位置设置不是太好,感兴趣的可以修改修改,让它更好看。
如果对你有帮助,点个赞或者打个赏吧,嘿嘿。