版权声明:转载请注明出处,非法必究! https://blog.csdn.net/jinyuan7708/article/details/81909549
要点:
该教程为基于Kears的Attention实战,环境配置:
Wn10+CPU i7-6700
Pycharm 2018
python 3.6
numpy 1.14.5
Keras 2.0.2
Matplotlib 2.2.2
强调:各种库的版本型号一定要配置对,因为Keras以及Tensorflow升级更新比较频繁,很多函数更新后要么更换了名字,要么没有这个函数了,所以大家务必重视。
相关代码我放在了我的代码仓库里哈,欢迎大家下载,这里附上地址:基于Kears的Attention实战
笔者信息:Next_Legend QQ:1219154092 人工智能 自然语言处理 图像处理 神经网络
——2018.8.21于天津大学
一、导读
最近两年,尤其在今年,注意力机制(Attention)及其变种Attention逐渐热了起来,在很多顶会Paper中都或多或少的用到了attention,所以小编出于好奇,整理了这篇基于Kears的Attention实战,本教程仅从代码的角度来看Attention。通过一个简单的例子,探索Attention机制是如何在模型中起到特征选择作用的。
二、代码实战(一)
1、导入相关库文件
import numpy as np
from attention_utils import get_activations, get_data
np.random.seed(1337) # for reproducibility
from keras.models import *
from keras.layers import Input, Dense, merge
import tensorflow as tf2、数据生成函数
def get_data(n, input_dim, attention_column=1):
"""
Data generation. x is purely random except that it's first value equals the target y.
In practice, the network should learn that the target = x[attention_column].
Therefore, most of its attention should be focused on the value addressed by attention_column.
:param n: the number of samples to retrieve.
:param input_dim: the number of dimensions of each element in the series.
:param attention_column: the column linked to the target. Everything else is purely random.
:return: x: model inputs, y: model targets
"""
x = np.random.standard_normal(size=(n, input_dim))
y = np.random.randint(low=0, high=2, size=(n, 1))
x[:, attention_column] = y[:, 0]
return x, y3、模型定义函数
将输入进行一次变换后,计算出Attention权重,将输入乘上Attention权重,获得新的特征。
def build_model():
inputs = Input(shape=(input_dim,))
# ATTENTION PART STARTS HERE
attention_probs = Dense(input_dim, activation='softmax', name='attention_vec')(inputs)
attention_mul =merge([inputs, attention_probs], output_shape=32, name='attention_mul', mode='mul')
# ATTENTION PART FINISHES HERE
attention_mul = Dense(64)(attention_mul)
output = Dense(1, activation='sigmoid')(attention_mul)
model = Model(input=[inputs], output=output)
return model4、主函数
if __name__ == '__main__':
N = 10000
inputs_1, outputs = get_data(N, input_dim)
m = build_model()
m.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
print(m.summary())
m.fit([inputs_1], outputs, epochs=20, batch_size=64, validation_split=0.5)
testing_inputs_1, testing_outputs = get_data(1, input_dim)
# Attention vector corresponds to the second matrix.
# The first one is the Inputs output.
attention_vector = get_activations(m, testing_inputs_1,
print_shape_only=True,
layer_name='attention_vec')[0].flatten()
print('attention =', attention_vector)
# plot part.
import matplotlib.pyplot as plt
import pandas as pd
pd.DataFrame(attention_vector, columns=['attention (%)']).plot(kind='bar',
title='Attention Mechanism as '
'a function of input'
' dimensions.')
plt.show()
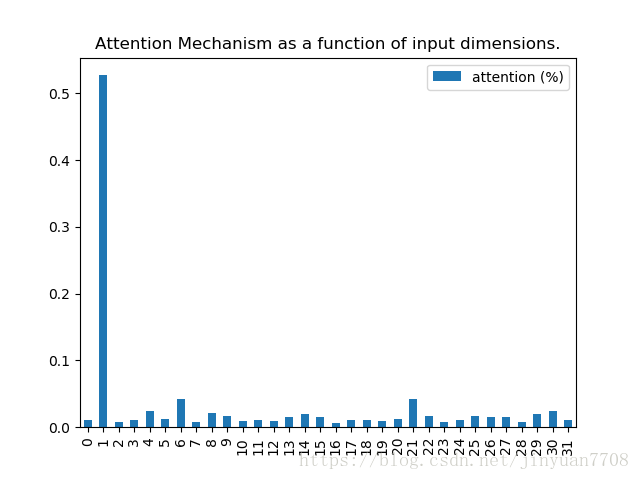
5、运行结果
代码中,attention_column为1,也就是说,label只与数据的第1个特征相关。从运行结果中可以看出,Attention权重成功地获取了这个信息。
三、代码实战(二)
1、导入相关库文件
from keras.layers import merge
from keras.layers.core import *
from keras.layers.recurrent import LSTM
from keras.models import *
from attention_utils import get_activations, get_data_recurrent
INPUT_DIM = 2
TIME_STEPS = 20
# if True, the attention vector is shared across the input_dimensions where the attention is applied.
SINGLE_ATTENTION_VECTOR = False
APPLY_ATTENTION_BEFORE_LSTM = False
2、数据生成函数
def attention_3d_block(inputs):
# inputs.shape = (batch_size, time_steps, input_dim)
input_dim = int(inputs.shape[2])
a = Permute((2, 1))(inputs)
a = Reshape((input_dim, TIME_STEPS))(a) # this line is not useful. It's just to know which dimension is what.
a = Dense(TIME_STEPS, activation='softmax')(a)
if SINGLE_ATTENTION_VECTOR:
a = Lambda(lambda x: K.mean(x, axis=1), name='dim_reduction')(a)
a = RepeatVector(input_dim)(a)
a_probs = Permute((2, 1), name='attention_vec')(a)
output_attention_mul = merge([inputs, a_probs], name='attention_mul', mode='mul')
return output_attention_mul
def model_attention_applied_after_lstm():
inputs = Input(shape=(TIME_STEPS, INPUT_DIM,))
lstm_units = 32
lstm_out = LSTM(lstm_units, return_sequences=True)(inputs)
attention_mul = attention_3d_block(lstm_out)
attention_mul = Flatten()(attention_mul)
output = Dense(1, activation='sigmoid')(attention_mul)
model = Model(input=[inputs], output=output)
return model
def model_attention_applied_before_lstm():
inputs = Input(shape=(TIME_STEPS, INPUT_DIM,))
attention_mul = attention_3d_block(inputs)
lstm_units = 32
attention_mul = LSTM(lstm_units, return_sequences=False)(attention_mul)
output = Dense(1, activation='sigmoid')(attention_mul)
model = Model(input=[inputs], output=output)
return model
4、主函数
if __name__ == '__main__':
N = 300000
# N = 300 -> too few = no training
inputs_1, outputs = get_data_recurrent(N, TIME_STEPS, INPUT_DIM)
if APPLY_ATTENTION_BEFORE_LSTM:
m = model_attention_applied_before_lstm()
else:
m = model_attention_applied_after_lstm()
m.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
print(m.summary())
m.fit([inputs_1], outputs, epochs=1, batch_size=64, validation_split=0.1)
attention_vectors = []
for i in range(300):
testing_inputs_1, testing_outputs = get_data_recurrent(1, TIME_STEPS, INPUT_DIM)
attention_vector = np.mean(get_activations(m,
testing_inputs_1,
print_shape_only=True,
layer_name='attention_vec')[0], axis=2).squeeze()
print('attention =', attention_vector)
assert (np.sum(attention_vector) - 1.0) < 1e-5
attention_vectors.append(attention_vector)
attention_vector_final = np.mean(np.array(attention_vectors), axis=0)
# plot part.
import matplotlib.pyplot as plt
import pandas as pd
pd.DataFrame(attention_vector_final, columns=['attention (%)']).plot(kind='bar',
title='Attention Mechanism as '
'a function of input'
' dimensions.')
plt.show()