开篇导读
首先复习下前面聊天机器人系列:
《一》聊天机器人/翻译系统系列一梳理了聊天机器人网络设计模型原理
(理论篇—图文解锁seq2seq+attention模型原理)
《二》翻译系统系列二开启实战代码篇:代码是设计思路的呈现,在这里我们把聊天机器人整体模型拆分为三块,循序渐进方便大家理解消化。
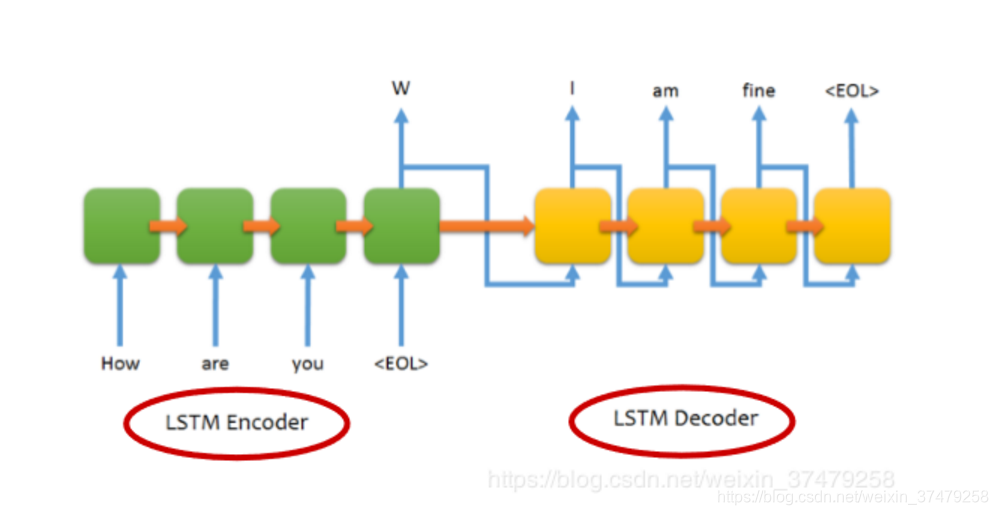
第一块——聊天机器人地基模型LSTM的手把手代码搭建。注意聊天机器人是由编码模型和解码模型这两块构成的。而编码模型和解码模型的网络设计都是采用LSTM。所以剖析捋顺LSTM模型的实现,是我们整个聊天机器人网络设计代码的硬核地基。
第二块——理解并敲完第一块地基砖,相对可以轻松地开始着手实现seq2seq整体模型的网络搭建工作了。那么这两个LSTM模型分别在编码过程和解码过程中,该如何实现呢?如何运转起来整个seq2seq模型并实现预测功能?这也是咱们本文重点要手把手带大家搭建的。(本文主旨)
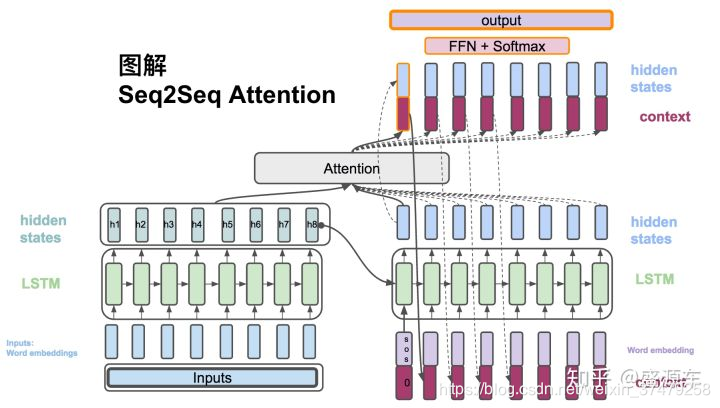
第三块——顺带预告下后面的章节安排。如果理解了LSTM模型,敲出了seq2seq整体模型这块砖,进阶到第三块就顺利轻松多了。本节主要是带大家敲出含有attention的seq2seq模型,为什么带有attention的会相对好呢,可以回到系列一重新复习下原理篇。
到此seq2seq模型+attention代码篇基本完成了,敲出一个撩妹子的聊天机器人基本没问题。
《对话系统系列三》我们将综合对比各家平台目前的智能客服系统,聊天机器人,包含两个维度:1横向综合客服系统+行业垂直业务客服机器人,2不同任务场景,客服系统技术设计侧重点与模型重点问题解决策略。从前线业务场景与技术应用中,探讨客服系统技术与用户体验提升,客服系统的任务完成度,业绩目标贡献。
以上是聊天机器人系列回顾与后面的章节安排计划。捋顺后我们开始进入本章节重点:
《聊天机器人系列二》——代码篇2之seq2seq完整模型搭建
一、seq2seq网络模型设计核心要点:
1.网络结构设计:编码LSTM,解码LSTM。
【1.1】编码过程LSTM输出时需要保存中间变量
 encorder_states[encorder_states_h,encorder_states_c],会进入解码过程作为预测输入的中间变量。因此需要保留,设定LSTM模型里的return_states=true。
encorder_states[encorder_states_h,encorder_states_c],会进入解码过程作为预测输入的中间变量。因此需要保留,设定LSTM模型里的return_states=true。
【1.2】解码过程的LSTM输入层主要是两部分构成:上一时刻预测输出的单个字符+中间变量states。

2.编码网络的输入向量构建:我们的聊天语句文本如何用向量表示,方便输入计算机模型里呢?注意此处与文本分类常使用的词频词袋模型不同,翻译系统和对话系统要实现句子里每个词语的甄别,所以每个字都需要在输入时编码进来。不再是像IFDIF一样,只选择高频词生成词向量。这里可以理解每个字背后由一串向量表示。一句话20个字,相应的第1个字 shape=(0,array01)第N个字,shape=(N-1,arrayN) 由于输入样本一般由几千句几万句,于是我们用相同原理,构建输入向量,如下:
第1句中的第1个字用向量表示为:
(0,0,array01)
第A句中的第B个字用向量表示为:
(A-1,B-1,array0B)
这里array01,array0B都是基于输入文本构建词典生成的字向量。例如输入文本1000句,汇总统计不相同的字共有M个。这M个字构成了我们编码字向量的字典。对应的字在字典的位置,我们就标记为1,其他设为0,例如:
【中】字向量:000…000100…0
【华】字向量:0010…0000…0
基于以上编码过程文本输入词向量化的编码思路,下面是embedding的解决方案:
a构建字典:encoder_input_dict{i:char}
b构建输入文本的三维数组:
encoder_input_data=np.zeros(样本包含的句子数x,最长的句子包含的字数y,样本包含的不重复字数z)
3.解码网络的输入向量构建:
注意1:和编码过程不同,seq2seq模型的编码过程,不仅需要输入向量,还需要输出向量,才能完成整个模型model.fit([encoder_input_data,decoder_input_data],decoder_output_data)拟合过程。
下面我们来看下编码过程的输入和输出向decoder_input_data与decoder_output_data如何构建。
注意解码的输入和输出是同样的句子向量target_seq。t-1时刻的输出,会随着网络模型进入下一个时刻变成t时刻的输入。
考虑到目标句子向量target_seq第一个字未知待预测,我们需要在目标向量target_seq开头加入字符‘t’,完成第一次预测输出:target_seq=‘t’+target_seq
基于以上解码过程文本输入词向量化的编码思路,下面是embedding的解决方案:
a构建编码目标句子字典:decoder_dict{i:char}
b构建编码目标句子的三维数组:
decoder_input_data = np.zeros(
(样本包含的句子数n, 最长的句子包含的字数m, 样本包含的不重复字数z)
具体编码过程文本向量化如下例:
目标句子第1句中的第1个字用向量表示为:
(0,0,array01)【array01与decoder_dict映射】
第A句中的第B个字用向量表示为:
(A-1,B-1,array0B)
由于 t-1时刻的target_seq+states预测生成t时刻的target_seq输出,t时刻的target_seq又作为t+1时刻的输入。编码过程的输入向量和输出向量相差一个时序。
4.测试样本预测:
训练完的模型,我们在测试阶段,要重新拆分组合编码模型encoder_model和解码模型decoder_model,输入测试数据进入encoder_model得到states,然后和目标句子向量target_seq共同输入到decoder_model进行预测,注意每次预测完成一次后,需要更新重置目标句子输入向量和中间变量。
二、seq2seq实战代码:
seq2seq训练模型构建与拟合
from keras.models import Model
from keras.layers import Input,LSTM,Dense
# 定义编码模型LSTM encoder_model
##encoder_word_nums:编码过程输入文本不重复的字数(字典size)
##sys_dim神经元个数,return_state 编码过程需要传递中间变量state 因此设为true
encoder_inputs=Input(shape=(None,encoder_tokens_nums),name='enc_input')
encoder_lstm=LSTM(sys_dim,return_state=true)
_,state_h,state_c=encoder_lstm(encoder_inputs)#编码过程不需要输出预测值
encoder_states=[state_h,state_c]
# 定义解码模型LSTM decoder_model
decoder_inputs=Input(shape=(None,decoder_tokens_nums),name='dec_input')
decoder_lstm=LSTM(sys_dim,return_sequences=true,return_state=true,name='dec_lstm'),initial_states=encoder_states)
decoder_dense=Dense(decoder_tokens_nums,Activation='softmax',name='decoder_dense')
decoder_output_tokens=decoder_dense(decoder_output_tokens)
seq2seq_model=Model([encoder_inputs,decoder_inputs],decoder_output_tokens)
print(seq2seq_model.summary())
# seq2seq训练
seq2seq_model.compile(loss='categorical_crossentropy',optimizer='rmsprop')
seq2seq_model.fit([encoder_input_data,decoder_input_data],decoder_target_seq,epochs=epochs,batch_size=batch_size,validition_split=0.2)
seq2seq_model 训练中:

预测部分代码:
def define_models(n_input, n_output, n_units):
# 训练模型中的encoder
encoder_inputs = Input(shape=(None, n_input))
encoder = LSTM(n_units, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
encoder_states = [state_h, state_c] #仅保留编码状态向量
# 训练模型中的decoder
decoder_inputs = Input(shape=(None, n_output))
decoder_lstm = LSTM(n_units, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states)
decoder_dense = Dense(n_output, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# 新序列预测时需要的encoder
encoder_model = Model(encoder_inputs, encoder_states)
# 新序列预测时需要的decoder
decoder_state_input_h = Input(shape=(n_units,))
decoder_state_input_c = Input(shape=(n_units,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model([decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states)
# 返回需要的三个模型
return model, encoder_model, decoder_model
def predict_sequence(infenc, infdec, source, n_steps, cardinality):
# 输入序列编码得到编码状态向量
state = infenc.predict(source)
# 初始目标序列输入:通过开始字符计算目标序列第一个字符,这里是0
target_seq = array([0.0 for _ in range(cardinality)]).reshape(1, 1, cardinality)
# 输出序列列表
output = list()
for t in range(n_steps):
# predict next char
yhat, h, c = infdec.predict([target_seq] + state)
# 截取输出序列,取后三个
output.append(yhat[0,0,:])
# 更新状态
state = [h, c]
# 更新目标序列(用于下一个词预测的输入)
target_seq = yhat
return array(output)
预测结果—英文翻译中文:

感谢本文参考来源:
作者:Data_Driver
链接:
https://blog.csdn.net/qq_42189083/article/details/89356188
作者:DemonHunter211
链接:https://blog.csdn.net/kwame211/article/details/78271042
————————————————
《AI工匠BOOK》持续更新AI算法与最新应用,如果您感兴趣,欢迎关注AI工匠(AI算法与最新应用前沿研究)。
AI工匠不定期发放福利啦~~限时先到先得奥~
CPU训练太慢,GPU加速几个小时搞定3天的模型计算量。稍后我会更博推出手把手教程如何搭建深度学习环境,配置TF1.0-GPU-jupyterbook-CUDNN-CUDA 。也有已经搭建好的TF1.0镜像可以一键分享,直接拎数据跑转模型。
租用服务器GPU的童鞋,福利传送门:
最近特价2折起的云服务器活动收集:
云服务器限时福利价点这里
AI工匠BOOK赠送云服务器通用2000元优惠券链接:领取AIBOOK工匠云服务器2000元优惠券点这里
针对24岁以下的AI爱好者,AI工匠book奉上福利传送门楼主已过福利带宽年龄TOT~
1.轻量应用服务器 1C2G 1000G流量包 5M宽带 40G系统盘 9.5/月 一年仅需114元(官网售价1740元)
✅2.云服务器ECS 1C2G 1M宽带 40G系统盘 9.5/月 一年仅需114元(官网售价1452元)
符合24周岁以下新客要求可享受以上价格~~
轻量应用服务器福利——24岁以下点击这里领取你的福利包拉
