在自然语言处理中最有趣的进步之一就是注意力网络的概念。已成功地用于翻译服务、医疗诊断和其他任务。
今天,我们将学习什么使注意力网络有效,为什么它是特殊的,以及背后的实现细节。
当使用本教程的时候,我假设你对神经网络有一定的了解。
传统的递归神经网络有一些明显的局限性。例如在编码-解码器网络布局中,很难以压缩格式记住整个输入。输入越长,学习就越困难。正如以前的研究表明,这种性能在输入长度大于30字的效果很差。
为了解决这个问题,我们使用有注意力机制网络。灵感来自人类的翻译机制。在翻译句子时,译者在翻译译文之前不会阅读整个文本。相反,他们只阅读部分文本,然后翻译一部分,重复这个过程直工作完成。换句话说,他们一次只关注一部分文本,这是注意力网络的关键思想。
在注意力网络中,每个输入是具有相应注意权重。如果输入与我们当前的工作相关,则为1,否则为0。这些注意力权重在输出后进行重新计算。这使得网络的注意力能随着时间推移而改变。
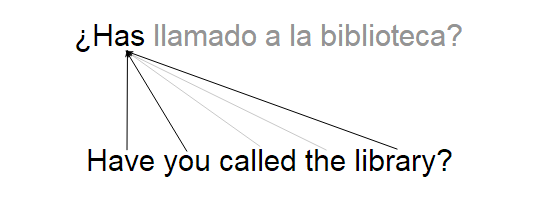
例如,考虑一个将英语句子翻译成西班牙语句子的注意网络。每个输出字取决于输入句子中的多个词,因为共轭、时态、标点等。在t=0时,注意力网络会给“拥有”、“你”和“图书馆”分配高注意力权重。因为每一个词都影响第一个输出字“有”字。它会把低注意力权重分配给所有其他单词,达到忽略它们的目的。
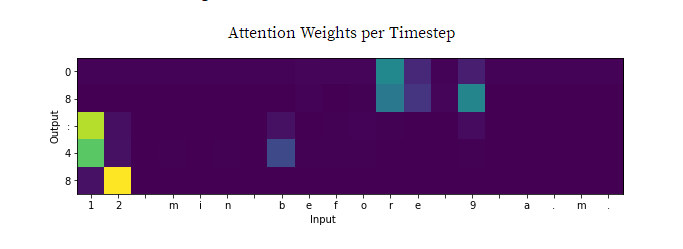
再举一个例子,考虑一个将人类书写时间转换为军事时间的注意力网络。下图显示了每个输出时间步长的注意权重。注意网络正在关注什么。
在继续之前,让我们列出一些符号:

有了这些知识,注意层的图示如下:
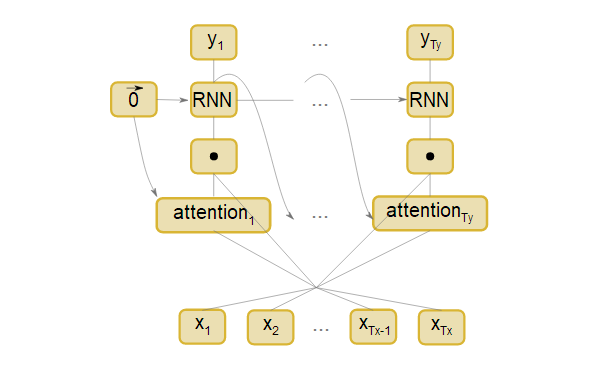

让我们逐一地了解这部分,理解所有的数学运算。第一步是计算$attention_i$,这可以通过多种方式来完成,只要attention和输入有一样的矩阵结构,并且加起来等于一。
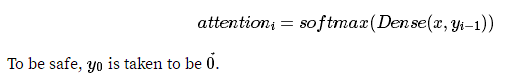
下一步是计算注意力权重和输入之间的加权和。计算值称为上下文,因此速记是c_i:

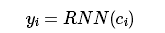
暂停一下,看看注意力和上下文是如何结合到上述例子中的。
为什么RNN层是必需的?
没有RNN层,上下文对于每个输出时间步长都是相同的。这就像是给翻译器一个文本,但是90%的单词被遮住了。因此,必须有随时间变化的输入,以允许注意力随着时间的推移而变化。
另一个需要注意的重要事项是注意力网络需要二次训练时间。这使得很难对长输入进行训练。因此,它通常在滑动窗口的样式中使用,它先读单词[ 0, 20 ],然后[ 1, 21 ],[ 2, 22 ],等等。目前的研究旨在改善训练时间。
现在你知道了内部工作原理,是时候看一些代码了。这里提供了一个演示网络和数据集:链接