0.堆排序简介
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。大根堆的要求是每个节点的值都不大于其父节点的值,即A[PARENT[i]] >= A[i]。在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的要求可知,最大的值一定在堆顶。在分析堆排序算法之前,首先要分析堆这种数据结构,在堆中二叉堆又是最为经典的一种堆的实现方式,所以下面分析二叉堆得定义。
1.二叉堆的定义
二叉堆其实可以看成一棵二叉树,但这个二叉树满足一些要求。以大顶堆为例,根节点的值要比孩子节点的值大,同样孩子节点作为根节点所构成的子树同样满足根节点的值大于孩子节点的值。并且这个二叉树是一颗完全二叉树。
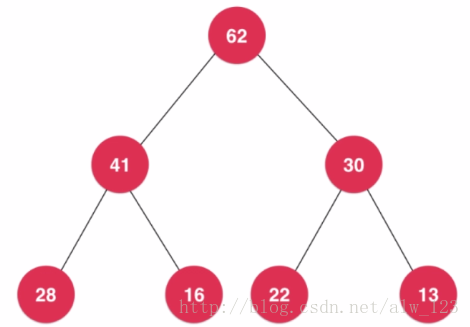
虽然从图中看到的二叉堆是树形结构,但是由于这个二叉堆是个完全二叉树,如果给每个节点编个号,就能够很容易的用数组来存储一个二叉堆。假设一个节点的编号是x,那么这个节点的左孩子的编号是2*x,右孩子的编号是2*x+1,父节点的编号是x/2。(这里起始编号是1)
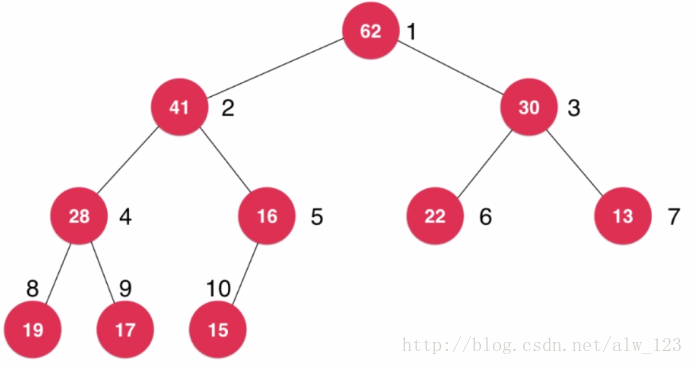
2.二叉堆的操作
2.1 插入
要往二叉堆里插入一个新的节点时,并不是简单的在末尾添加就行了,因为这么草率的话就不能使得插入新节点后还是满足二叉堆的性质。为了插入正确,需要进行shift up操作,即上浮操作。shift up操作的流程下面将举例说明。
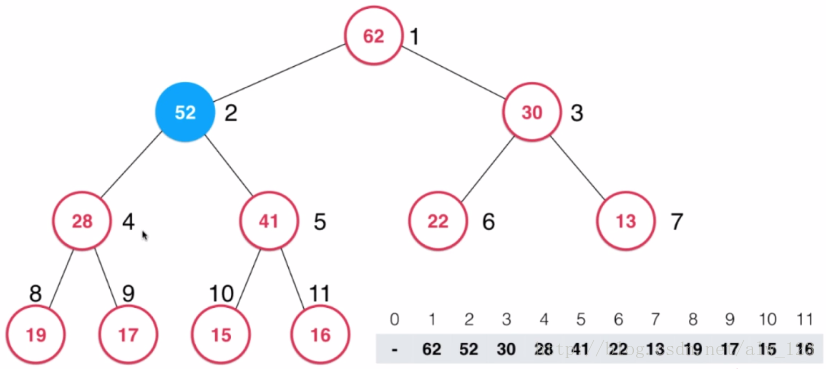
假设我们要往这个二叉大顶堆里插入一个值为52的新节点。初始状态如下图所示,其中数组的0号索引不存储任何节点信息。
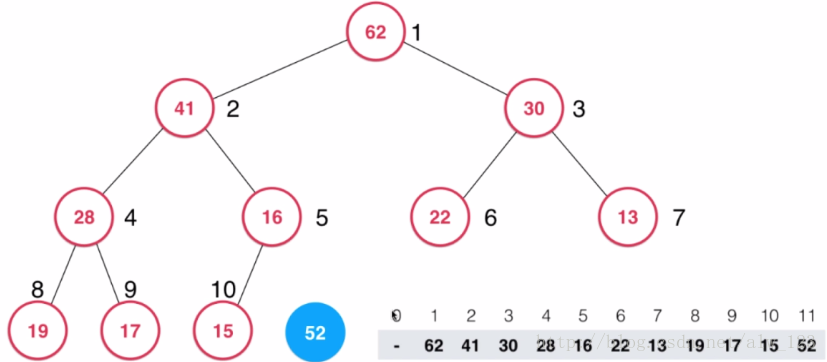
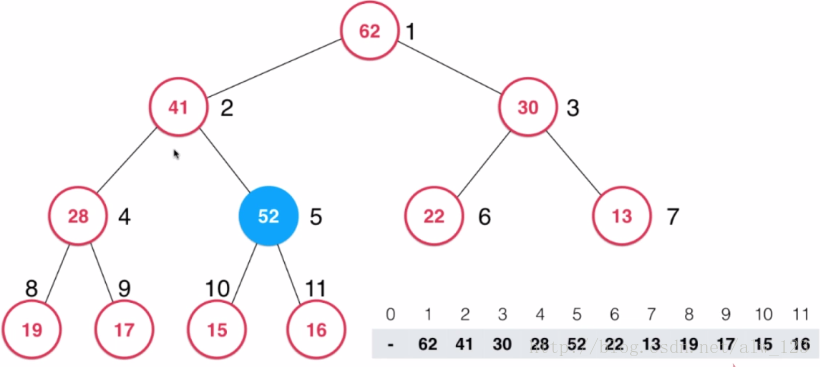
此时52这个节点比它的父节点还要大,违背了大顶堆的性质。怎么让52到达合适的位置呢?其实在插入52之前,整个堆是满足大顶堆性质的,当插入52的时候才出现了不满足大顶堆性质的问题。因此只需要将52这个节点不断地和它的父节点比大小,如果比父节点大,就和父节点交换就行了。并且维护一个变量来记录数组的大小。

2.2 删除
要从二叉堆里面删除一个节点时,同样不能简单的将第一个节点删掉,因为那样会导致二叉堆不满足堆的性质。为了删除正确,需要进行shift down操作,即下沉操作。shift down操作的流程下面将举例说明。
假设我们要删除儿叉大顶堆中最大的节点,也就是根节点。初始状态如下图所示,其中数组的0号索引不存储任何节点信息。
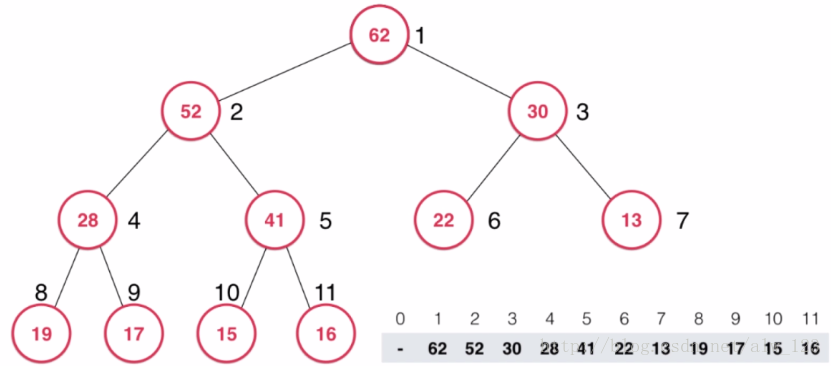
当然这个时候需要把根节点删掉。删除的话其实就是把根结点和最后一个孩子节点进行交换,然后用一个变量count来维护数组的大小,没删除一个节点count就-1,也就相当于将节点给删掉了。
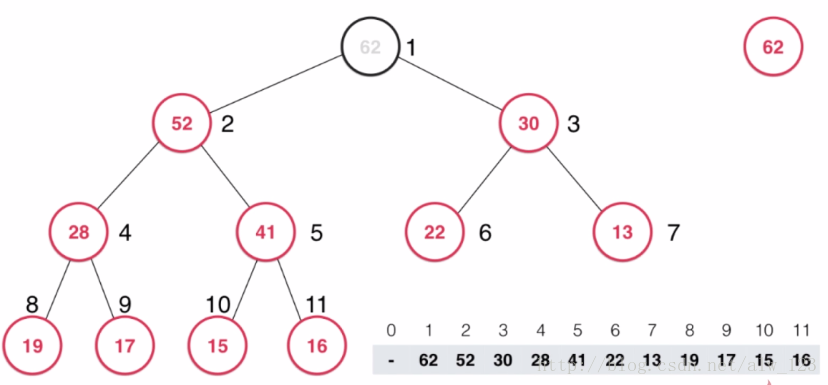
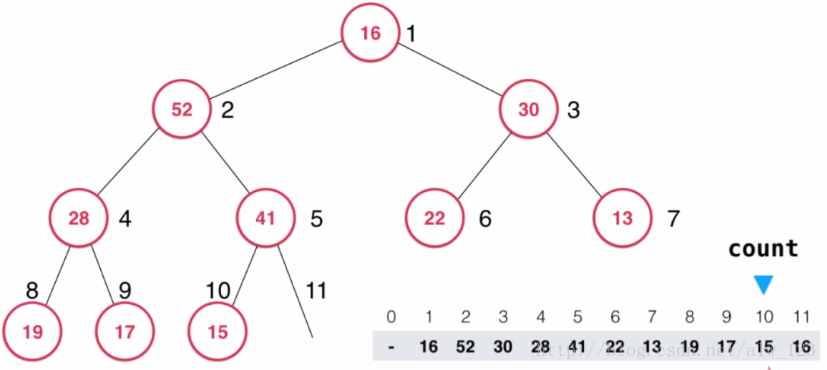
但是这样做还不够,从上图可以看出此时的根节点并不比孩子节点大,因此接下来就要对根节点进行shift down操作。shift down操作主要思路是将当前节点和它的孩子节点们进行比较,如果当前节点的值比孩子节点的最大值大,那么结束shift down操作,否则就和最大的孩子节点进行交换,以此类推。在这里16比max(52,30)小,所以16和52进行交换。
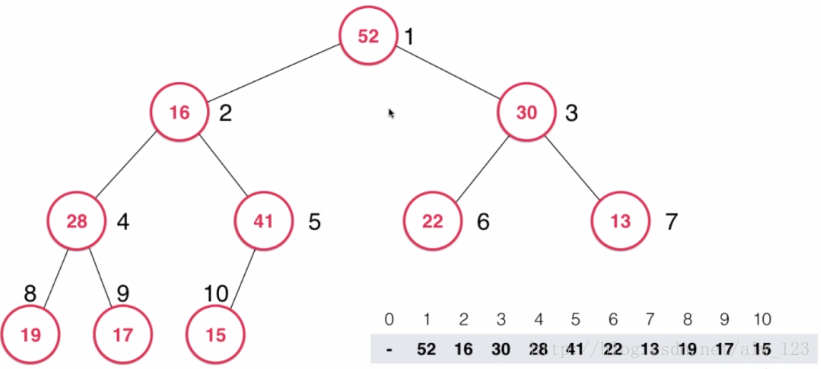
然后16比max(28,41)小,所以16和41进行交换
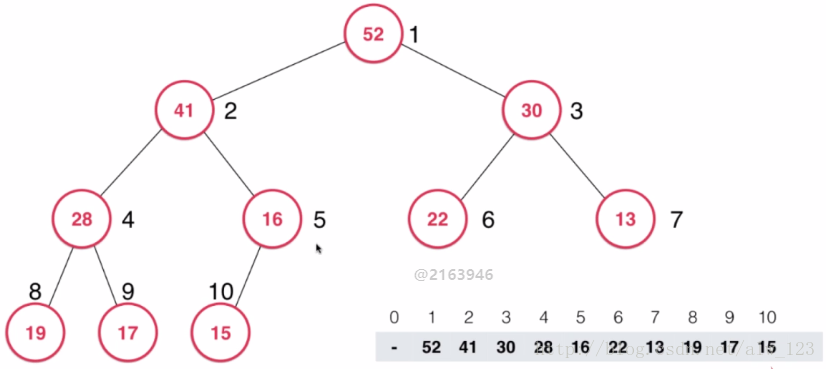
此时16比15大,结束shift down操作。可以看到此时的二叉堆依然是一个二叉大顶堆。
3.二叉堆的实现
template<typename Item>
class MaxHeap
{
public:
MaxHeap(int capacity)
{
//为了好计算下标,默认0号索引不存任何数据
m_size = 0;
m_capacity = capacity+1;
m_pData = new Item[m_capacity];
}
~MaxHeap()
{
delete[] m_pData;
}
int size()
{
return m_size;
}
bool isEmpty()
{
return m_size == 0;
}
//插入
void insert(Item item)
{
if (m_size+1 > m_capacity)
{
return;
}
m_pData[++m_size] = item;
shiftUp(m_size);
}
//删除
Item extractMax()
{
Item result = m_pData[0];
swap(m_pData[m_size--], m_pData[0]);
shiftDown(1);
return result;
}
private:
void shiftUp(int index)
{
while (index > 1 && m_pData[index/2] < m_pData[index])
{
swap(m_pData[index / 2], m_pData[index]);
index /= 2;
}
}
void shiftDown(int index)
{
while (1)
{
//有两个孩子
if (index*2+1 <= m_size)
{
int needSwap = index * 2;
if (m_pData[index * 2] > m_pData[index * 2 + 1])
needSwap = index * 2;
else
needSwap = index * 2 + 1;
if (m_pData[index] < m_pData[needSwap])
{
swap(m_pData[index], m_pData[needSwap]);
index = needSwap;
}
else
break;
}
else if (index * 2 <= m_size)
{
if (m_pData[index] < m_pData[index * 2])
{
swap(m_pData[index], m_pData[index * 2]);
index *= 2;
}
else
break;
}
else
break;
}
}
private:
Item* m_pData; //数组
int m_size; //当前二叉堆的size
int m_capacity; //容量,size<=capacity
};这样就实现了一个能够插入,删除的二叉大顶堆。但这个二叉大顶堆没有实现根据一个给定的数组来生成一个二叉大顶堆,也没有实现堆排序。下一篇将分析heapify操作和堆排序。