0.快速排序简介
快速排序是20世纪世界上最伟大的算法之一,顾名思义,这个算法能很快的对数据进行排序。而且在很多库的底层代码中也经常使用快速排序来实现排序的功能,比如jdk,stl等。
1.快速排序的思想
以升序为例。首先会找一个元素v作为基准,然后将整个待排序序列parttion成3个区域A,B和C。其中A区域为全部比v小的元素,B区域为全部等于v的元素,C区域为全部大于v的元素。此时B区域就成为了元素v在序列中的最终位置,也就是说下一趟排序的时候不需要考虑元素v了,然后将元素v的位置p记录下来。然后根据分治法的思想将整个待排序序列一分为二,即p左边一个部分和p右边一个部分,一直这样递归地二分下去,直到二分出来的区域只有1个元素的时候终止递归。就这样每一次parttion之后,所选择的基准元素都被置换到了整个序列有序时的最终位置。
parttion所做的工作就是将整个序列以元素v为基准,逐渐将整个序列调整成两个区域,一个区域中的元素小于v,另一个区域中的元素大于v。而v所在的位置为分界点。parttion的工作流程我们用下面的图来表示:

其中橙色区域中的元素都小于v,紫色区域中的元素都大于v。l为基准元素v的索引,j为橙色区域的右闭区间的索引,i为当前待检查的元素的索引,同时i-1就是紫色区域的右闭区间的索引,e表示当前待检查的元素的值。
那么当e大于v的时候,要做的事情就很简单,只要++i就行了。那如果e小于v的话,为了保持序列只有橙色和紫色区域的性质,需要将e扔到橙色区域里面去。为了实现这个功能,可以先将arr[j+1]和a[i]进行交换,然后++j,然后++i继续检查下一个元素。
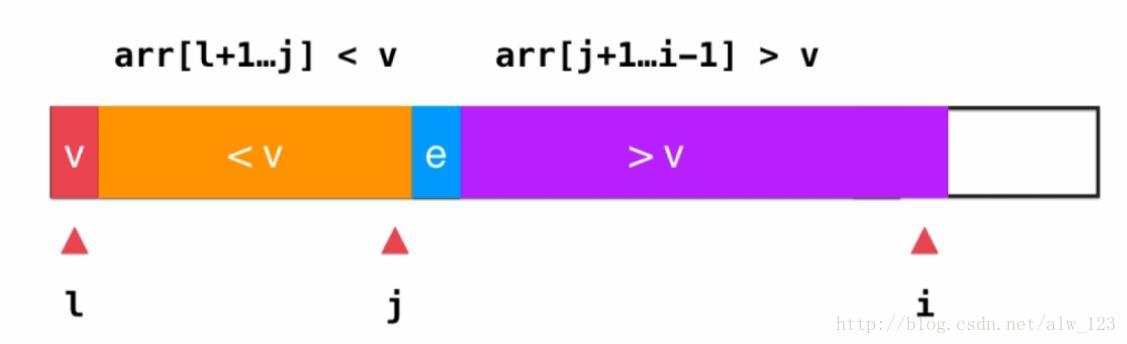
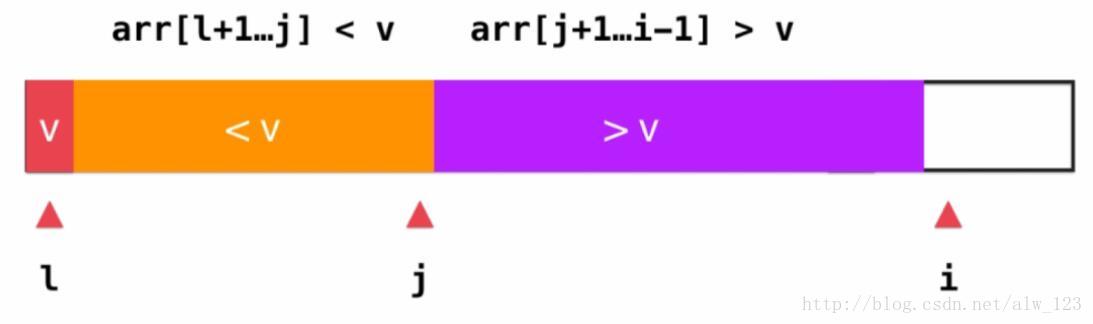
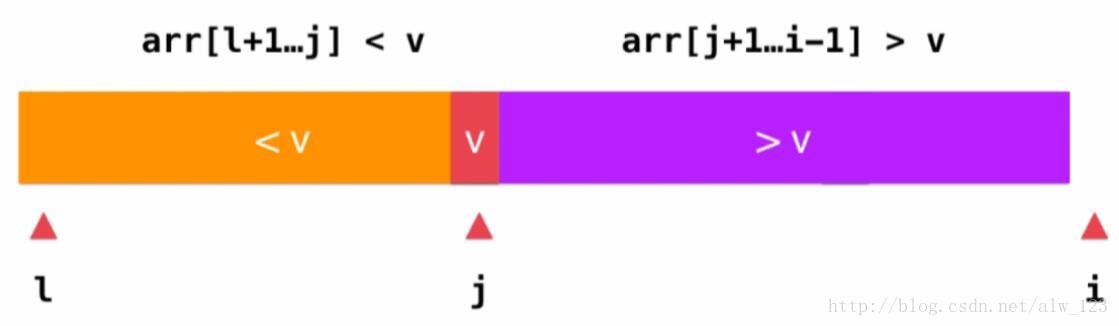
在序列中的所有元素都遍历完成之后,只要将arr[l]和arr[j]进行交换,就能得到parttion的最终结果了。

2.快速排序的实现
template<typename T>
int parttion(vector<T>& data, int left, int right)
{
//将整个数组划分成小于key key 大于key三个部分,j表示小于key部分的最后一个索引
T key = data[left]; //基准值
int l = left; //基准值的索引
int j = left;
for (int i = left + 1; i <= right; ++i)
{
if (data[i] < key)
{
swap(data[i], data[++j]);
}
}
swap(data[j], data[l]);
return j;
}
template<typename T>
void quickSortKernel(vector<T>& data, int left, int right)
{
if (left >= right)
return;
int p = parttion(data, left, right);
quickSortKernel(data, left, p-1);
quickSortKernel(data, p + 1, right);
}
template<typename T>
void quickSort(vector<T>& data)
{
quickSortKernel(data, 0, data.size() - 1);
}3.分析
3.1 随机数据实验
本实验使用随机生成的1000000数据作为输入,使用上一篇中优化后的归并排序和第2节中实现的快速排序进行对比,实验结果如下:
从图可以看出在数据的有序程度不高的情况下,同是O(nlogn)的归并排序算法的速度没有快速排序高。
3.2 近似有序数据实验
本实验使用随机生成的1000000近似有序数据作为输入,使用上一篇中优化后的归并排序和第2节中实现的快速排序进行对比,实验结果如下:
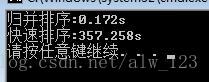
卧槽。。快速排序用了300多秒。。这还是快速排序么。。下面来分析原因。
归并排序之所以是O(nlogn)的排序算法,是因为会将待排序列一分为二,然后再一分为二,以此类推。那么整个层数就是logn的,合并的时候是n的,所以是O(nlogn)的算法。
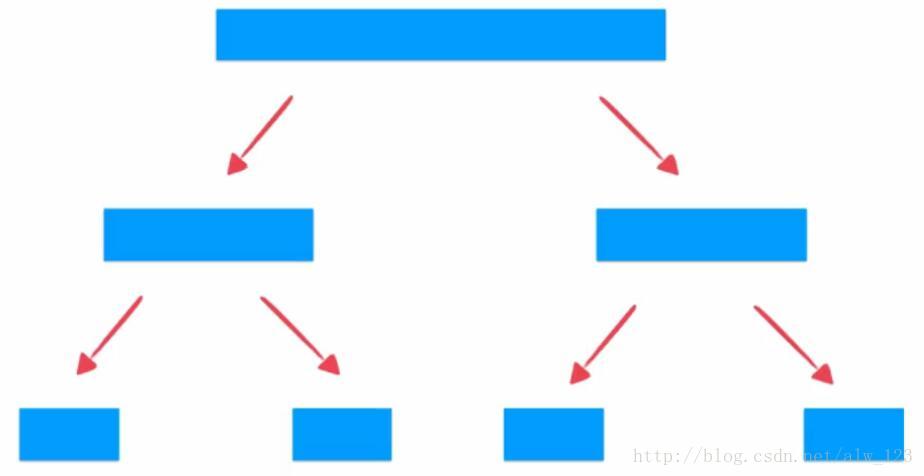
而快速排序算法也是一分为二,逐步划分的过程,但快速排序二分出来的子序列可能是一大一小,而不是正好的一半一半。
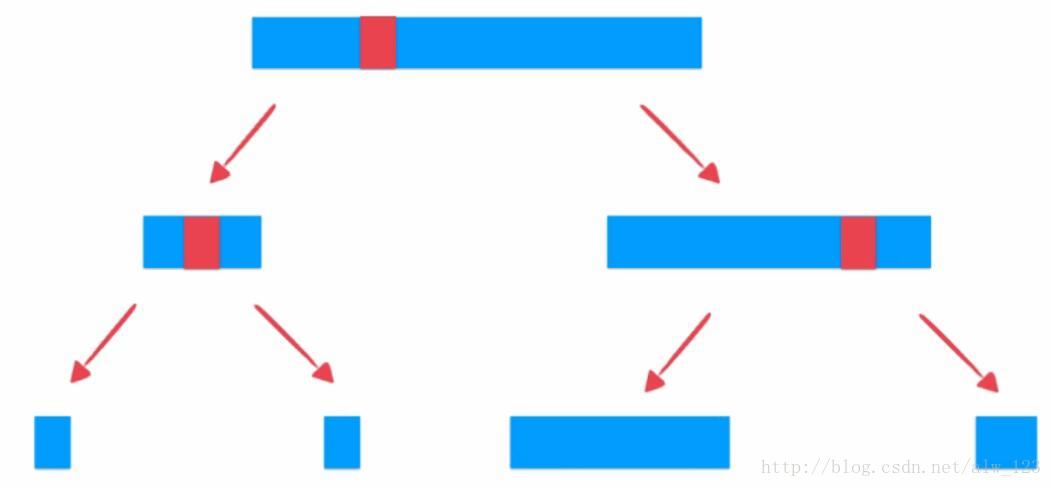
如果在最坏的情况下(完全有序的情况),快速排序二分时的二叉树也就退化成了链表,也就是说退化成了O(n^2)的算法。

为了解决这个退化问题,可以在选定基准的时候进行随机选择,从概率上来讲,对近乎有序的数据使用快速排序时随机选择基准,而不是固定选择最左边的元素为基准的话,退化成O(n^2)的概率几乎为0。(退化的概率=1/n*1/(n-1)*1/(n-2)…*1)
那么优化的代码如下:

template<typename T>
int parttion(vector<T>& data, int left, int right)
{
//随机选取基准
int randIndex = rand() % (right - left + 1) + left;
T key = data[randIndex];
swap(data[left], data[randIndex]);
int l = left; //基准值的索引
int j = left;
for (int i = left + 1; i <= right; ++i)
{
if (data[i] < key)
{
swap(data[i], data[++j]);
}
}
swap(data[j], data[l]);
return j;
}经过优化之后,实验结果如下:
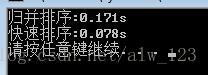
可以看到经过这么一个简单的优化之后,得到了质的飞跃,从O(n^2)又回到了O(nlogn),简直美滋滋。
3.3 拥有较多重复数据实验
本实验使用随机生成的1000000有大量重复数据的数据作为输入,使用上一篇中优化后的归并排序和第2节中实现的快速排序进行对比,实验结果如下:
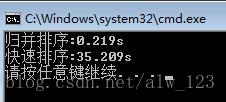
吃惊!又是这么慢!!这是因为如果待排序序列中有大量的重复数据的话,那么很有可能造成一种结果,就是橙色区域和紫色区域不是那么平衡!这样也就是说,很有可能同样的退化成一个O(n^2)的算法。

为了解决这种问题,算法大佬们提出了双路快速排序算法和三路快速排序算法,使得快速排序算法在各种特点的数据集中的表现都是接近O(nlogn)的。至于具体的算法思路和实现,将在下一篇博客中进行分析。