0. 上篇回顾
在上一篇中对二叉堆的定义进行了阐述,并且对二叉堆存储方式,插入和删除操作的算法思想(shift up和shift down)进行了较为详细的分析。那么下面将对依靠堆这种数据结构的堆排序算法进行分析。
1. 简单的堆排序
假设需要对一个数组中的数据进行排序,我们可以将数组中的数据依次地插入到一个二叉堆中,然后再将堆中的所有元素都删除(提取最大值)并赋值给数组的相应位置即可使整个数组有序。(因为删除掉的元素是当前堆中最大的元素)代码如下:
template<typename T>
void heapSort(vector<T>& data)
{
//这货是个大顶堆
MaxHeap<T> maxheap(data.size());
//将所有数据都插入到大顶堆中
for (int i = 0; i < data.size(); ++i)
{
maxheap.insert(data[i]);
}
//升序排序
for (int i = data.size() - 1; i >= 0; --i)
{
//提取最大值
data[i] = maxheap.extractMax();
}
}从代码和上一篇中shift up和shift down的实现可以看出将数组中所有数据都插入到堆的时间复杂度为O(nlogn),从堆中提取最大值并删除的时间复杂度也为O(nlogn)。因此整个堆排序的时间复杂度为O(nlogn)。
2. heapify后的堆排序
在上一节中的堆排序虽然能实现O(nlogn)的排序,但是在构建大顶堆时,会不断的调用insert函数。也就是说有n个数据那么就要调用n次insert函数。那么能不能减少insert函数(实质上是shift up)的次数,从而提高构建大顶堆的效率呢?答案是有的,也就是下面要介绍的heapify。heapify的意思就是说将一个给定数组中的数据构建成一个堆。
2.1 heapify
heapify的主要思路是先将数组中的数据构建成一个完全二叉树,然后整个完全二叉树中最后一个不是叶子结点的结点(最后一个不是叶子结点的索引即最后一个节点的索引除以2)开始从后往前执行shift down操作。(从最后一个不是叶子结点的结点开始是因为叶子结点可以看成是一个只有一个节点的堆,然后从他们的根节点来shift down的话能够使其满足堆的性质。)
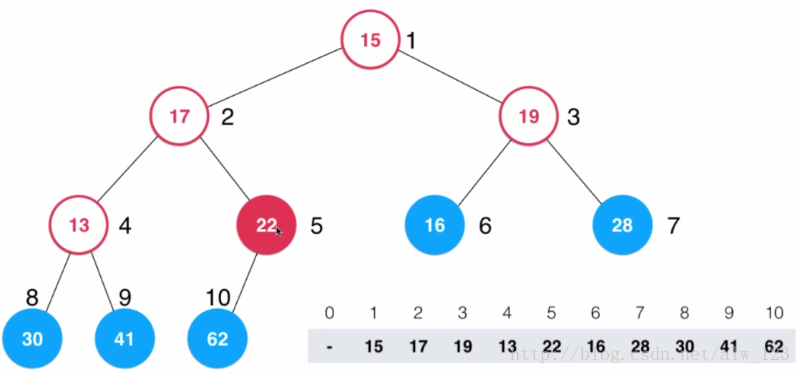
图中蓝色结点为叶子结点(也意味着能满足堆性质的结点),红色结点为当前要进行shift down的结点。这个时候22比62小,所以会shift down,也就成了下面这个样子。
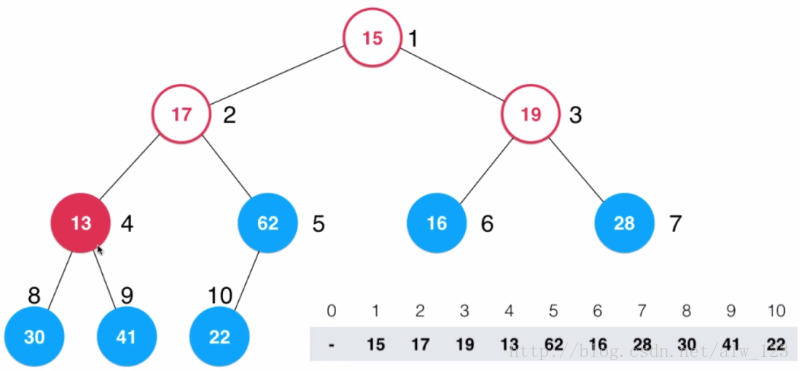
然后考察13这个结点,这货比30和41都小,那么进行shift down(13和41进行交换)。
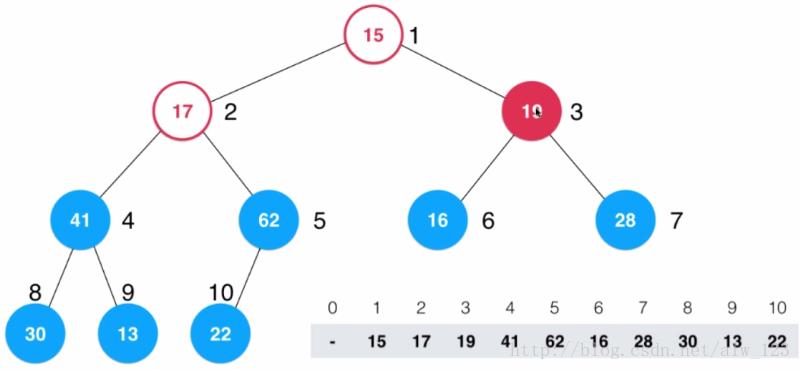
这个时候19要比28小,所以和28交换(shift down)。
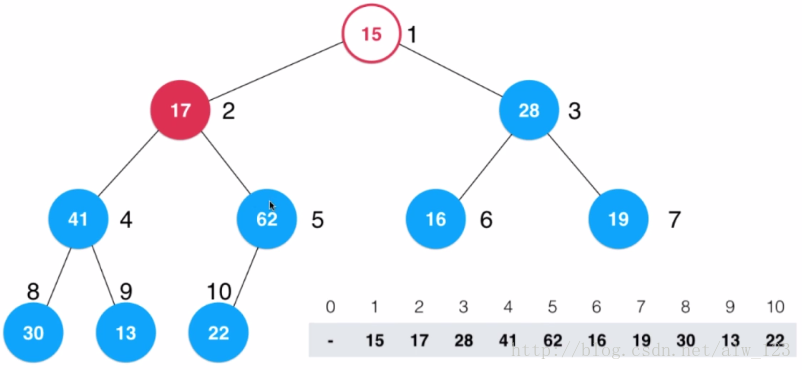
此时同样从17的位置开始shift down,17比max(41,62)小,17和62交换,然后17比22小,然后17和22交换。
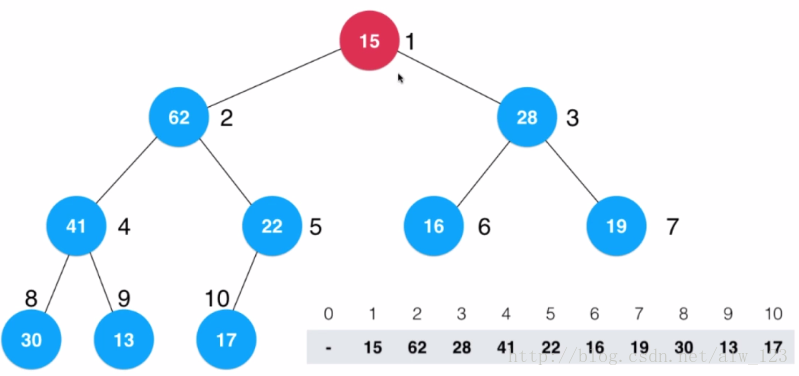
同样的套路,从15的位置shift down。15比max(62,28)小,15和62交换,然后15比max(41,22)小,15和41交换,最后15比max(30,13)小,那么15和30交换。
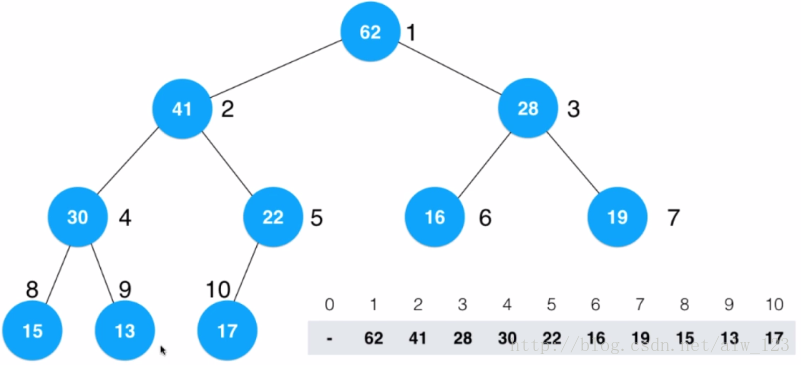
这样一来,一颗完全二叉树变成了一个大顶二叉堆。从这个过程也可以看出,相比于不断的调用insert的构建堆的方法,heapify的构建堆的方法更加的高效。据查阅资料得知,将n个元素插入到一个空堆中的时间复杂度为O(nlogn),而heapify的过程的时间复杂度为O(n),至于为什么是这样,因为牵扯到了很多数学证明,我对数学证明也不是很感冒,所以就不再复述。下面为heapify的实现:
//heapify
MaxHeap(vector<Item> data)
{
m_size = data.size();
m_capacity = data.size()+1;
m_pData = new Item[m_capacity];
//构建完全二叉树
for (int i = 1; i <= m_size; ++i)
{
m_pData[i] = data[i - 1];
}
//从最后一个有叶子节点的结点开始
for (int i = m_size / 2; i >= 1; --i)
{
shiftDown(i);
}
}2.2 heapify后的堆排序
heapify后的堆排序和简单的堆排序套路一样,只不过将循环调用insert替换成了heapify。
template<typename T>
void heapSort2(vector<T>& data)
{
//heapify
MaxHeap<T> maxheap(data);
//升序
for (int i = data.size() - 1; i >= 0; --i)
{
data[i] = maxheap.extractMax();
}
}2.3 简单堆排序 vs heapify后的堆排序
既然对简单的堆排序进行了优化,那么肯定要拿出点实验结果来证明这个优化是有必要的。下面的实验使用随机生成的10000000的数据来对两种堆排序算法进行实验,以下为实验结果:
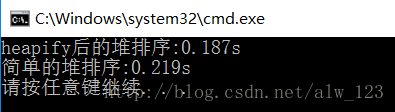
可以看出heapify后的堆排序比简单的堆排序的性能要略胜一筹。