上一篇对普通的快速排序算法进行了分析并通过实验发现,普通的快速排序算法在碰到有大量重复数据的数据集时,很有可能会导致在parttion之后进行二分时,两个部分的划分失去平衡,然后退化成O(n^2)的算法。在这一篇中,将对前辈们针对这种问题而提出的双路快速排序算法和三路快速排序算法进行分析。
0. 双路快速排序算法
在上一篇的普通快速排序算法的实现中并没有考虑到当前考察的元素等于基准的情况,如图所示:

也就是说,当出现大量e==v的时候,紫色区域会很大,而橙色区域会很小。这就会把整个数组分成极不平衡的两个部分!
0.0 算法思路
将大于v(紫色区域)和小于v(橙色区域)的两个部分放在数组的两头。在这里假设两个变量i和j,i表示橙色区域的右开位置(arr[l+1..j-1] < v),j表示紫色区域的左开位置(arr[j+1,r]>v)。
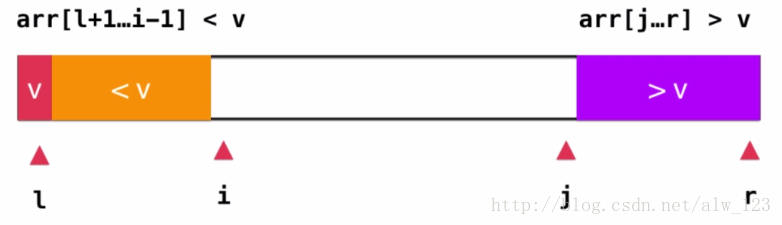
然后从i的位置开始扫描(往后),一直扫到arr[i]>=v时,从j的位置开始扫描(往前),一直扫到arr[j]<=v时停止,此时数据如图所示:
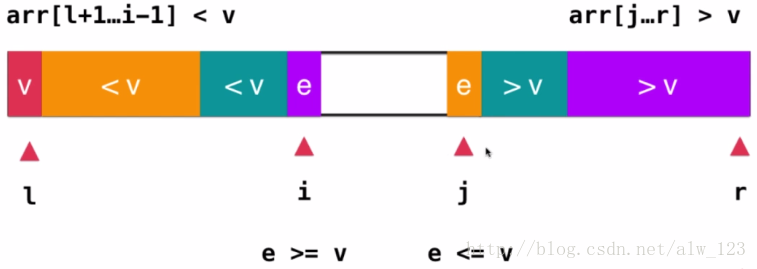
这个时候只要将arr[i]和arr[j]将行交换,然后i++,j–。
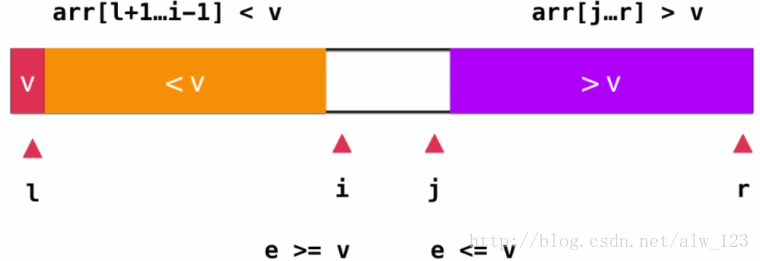
然后重复上述过程,直到i和j重合,表示parttion操作完毕。
通过这个parttion操作之后,整个数组其实还是被分成小于等于v和大于等于的两个部分,但是由于是两个索引都往中间靠过去,即使有大量的等于v的元素,也会将等于v的元素尽量的分散在左右两个部分。所以最后基准的位置会在一个较为平衡的位置。

0.1 算法实现
//2ways parttion
template<typename T>
int parttion2Ways(vector<T>& data, int left, int right)
{
//随机选取基准
int randIndex = rand() % (right - left + 1) + left;
T key = data[randIndex];
swap(data[left], data[randIndex]);
int i = left+1; //data[left,i)<=key
int j = right; //data(j,right]<=key
while (true)
{
while (i<=right && data[i]<key)
{
++i;
}
while (j >= left+1 && data[j] > key)
{
--j;
}
if (i > j)
break;
swap(data[i++], data[j--]);
}
swap(data[left], data[j]);
//swap之后,j的位置表示最后一个小于等于key的位置
return j;
}
template<typename T>
void quickSortKernel2Ways(vector<T>& data, int left, int right)
{
if (left >= right)
return;
int p = parttion2Ways(data, left, right);
quickSortKernel2Ways(data, left, p - 1);
quickSortKernel2Ways(data, p + 1, right);
}
template<typename T>
void quickSort2Ways(vector<T>& data)
{
srand(time(NULL));
quickSortKernel2Ways(data, 0, data.size() - 1);
}1. 三路快速排序算法
三路快速排序算法的思想也比较简单。所谓三路,就是将整个数组分成3个部分(小于,等于,大于)。等于部分的作用是能够减小二分的区域的大小,因为等于部分不需要被parttion了。
1.0 算法思路
假设lt为小于v部分的最后一个索引(arr[ l+1,lt ] < v),gt为大于v部分的第一个索引(arr[gt,r] > v),i为当前处理的元素(arr[lt+1,i-1]==v)。
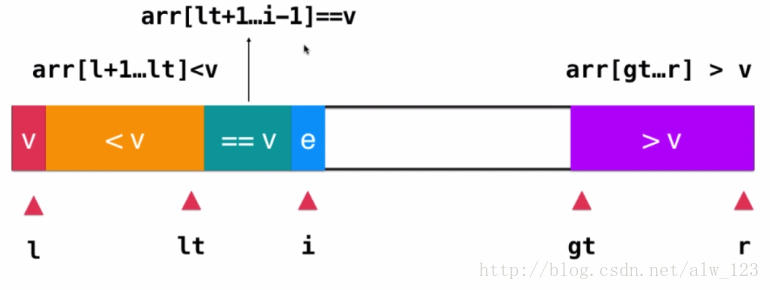
当arr[i] == e时,也就是i属于等于v的部分中,所以只要++i就好。
当arr[i] < e时,i所指向的元素应该被划分在橙色区域,为了维护arr[l+1,lt] < v的性质,此时只要将arr[lt+1]和arr[i]交换(交换后arr[lt+1] < v而arr[i] == v)然后再++lt,++i就好了。
同样,当arr[i] > e时,只要和arr[gt-1]交换下位置,然后gt–就好了。PS:这个时候i不+1,这是因为刚刚和arr[gt-1]进行过交换,交换后arr[i]是一个新的元素。
按照上面的过程以此类推,当i和gt重合时整个parttion操作完毕。

1.1 算法实现
//3 ways
template<typename T>
void quickSortKernel3Ways(vector<T>& data, int left, int right)
{
if (left >= right)
return;
//parttion
int randIndex = rand() % (right - left + 1) + left;
T key = data[randIndex];
swap(data[left], data[randIndex]);
//三个部分
int lt = left; //data[left+1,lt]<key
int rt = right + 1; //data[rt,right]>key
int i = left + 1; //data[lt+1,rt-1]==key
while (i < rt)
{
if (data[i] < key)
{
swap(data[i++], data[++lt]);
}
else if (data[i] > key)
{
swap(data[i], data[--rt]);
}
else
++i;
}
//此时lt为最后一个小于key的位置
swap(data[left], data[lt]);
quickSortKernel3Ways(data, left, lt);
quickSortKernel3Ways(data, rt, right);
}
template<typename T>
void quickSort3Ways(vector<T>& data)
{
srand(time(NULL));
quickSortKernel3Ways(data, 0, data.size() - 1);
}
2.实验
在这里以1000000随机生成的含有大量重复数据的数据为测试用例,分别对普通快速排序,双路快速排序和三路快速排序进行对比实验,结果如下:
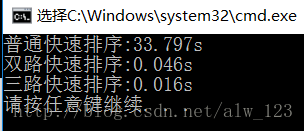
可以看出,双路快排和三路快排相较于普通快排在处理重复数据时效率高很多。而三路快排比双路快排又高出了几倍的效率。
当然,上面的三路快排也不是最优化的,比如在parttion之前可以判断待parttion的数组的大小,如果足够小的话,可以使用插入排序来代替parttion;在对unsigned int类型的数据排序时的swap可以使用一些bit trick来略微进行优化等等等。