1 NLTK
特点
- Python上著名的自然语言处理库
- 自带语料库,词性分类库
- 自带分类,分词,等等功能
- 强大的社区支持
- 还有N多的简单wrapper
安装
pip安装完,安装语料库,
2 文本处理流程
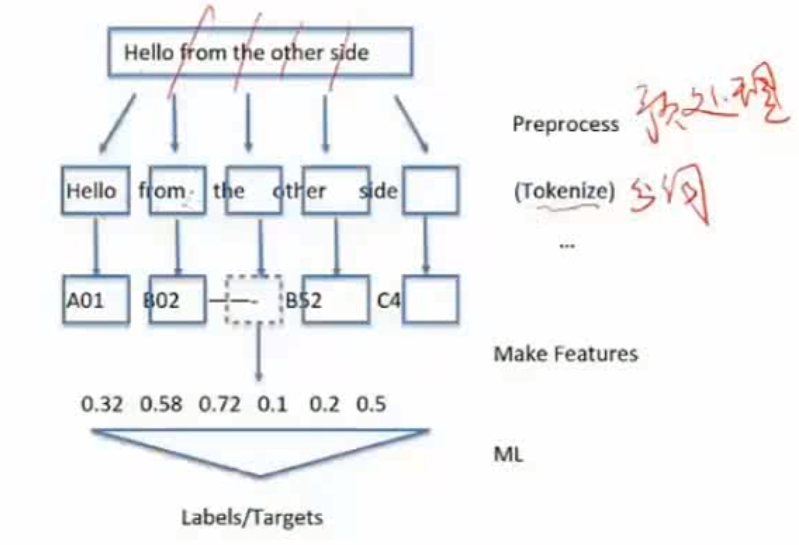
预处理(比如分词……) -> 特征生成 -> 训练
分词(tokenize):把长句子拆成“有意义”的小句子。 中英文是不同的
英文可以直接:
nltk.word_tokenize(sentence)中文单词中间是没有空格的:
一般使用启发式(Heuristic) 和 机器学习/统计方法(HMM、CRF)
中文就是用结巴
正则表达式
比如去除颜文字,通过正则表达式去匹配出来去除
词性归一化:
词干提取:去掉ing ed之类的修饰
词性归一:把各种类型的词的变形,都归为一个形式,比如went->go
NLTK实现Lemma
from nltk.stem import WordNetLemmatizer //查词典 包括Went->go
// 如果went是人名, 我们需要再加词性去限定
nltk.pos_tag(text) //词性标注Stopwords停止词
from nltk.corpus import stopwords比较通用的预处理流程:

什么是自然语言处理呢?
就是 自然语言 —-> 计算机数据

3 NTLK在NLP上的经典应用
- 情感分析
- 文本相似度
- 文本分类
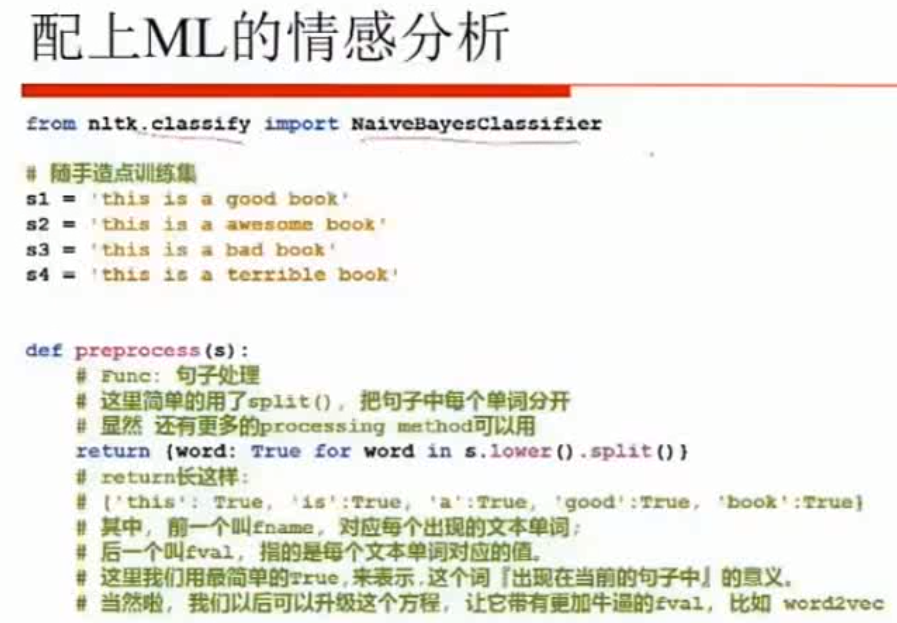
(1) 情感分类
最简单的sentiment dictionary
like 1
good 2
bad -2
terrible -3关键词打分机制
比如:AFINN-11

新词怎么办?特殊词怎么办?更特殊层次怎么办?

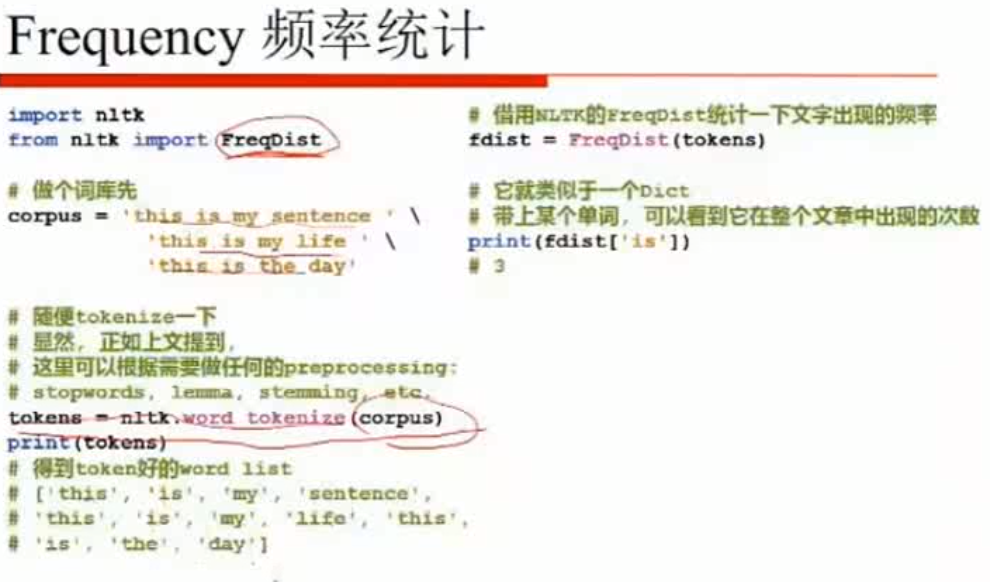
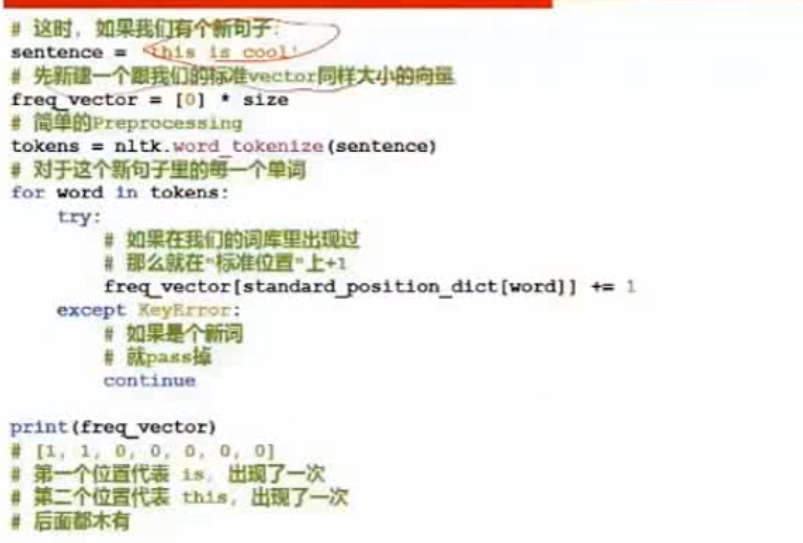
(2) Frequency 频率统计


(3) 文本分类
TF-IDF :
