事先声明,这篇博客的适用人群是想入门NLP知识的同学,希望能够帮到大家~
关键字: Word2Vec,NCE损失,层次SoftMax
如下是本篇博客的主要内容:
- 训练数据获取方式
- 模型构建
- 损失函数构建
- 总结
Word2Vec模型的核心目标是把词表vocabulary中每个词用固定维度的Embedding向量表示出来,且相似词的Embedding向量尽量相近。其核心手段是利用训练预料中词语的上下文之间的关系,对构建的模型进行训练,从而使得模型预测出的相似词语的Embedding向量距离比较相近。其具体手段分为训练数据准备,模型构建,损失函数构建三个部分,下面会从这三个部分进行讲述。
1. 训练数据获取方式
训练语料的raw数据一般是从vocabulary中提取的sentence集合,集合的每一个item是一个sentence,每个sentence由若干个词组成。从训练语料的raw数据用于训练的数据获取方式分为两种,CBOW和SkipGram。CBOW是通过sentence的中心词的上下文来预测中心词,SkipGram的基本思想是通过中心词来预测上下文,下图为诠释了两个获取训练数据的思想的区别。
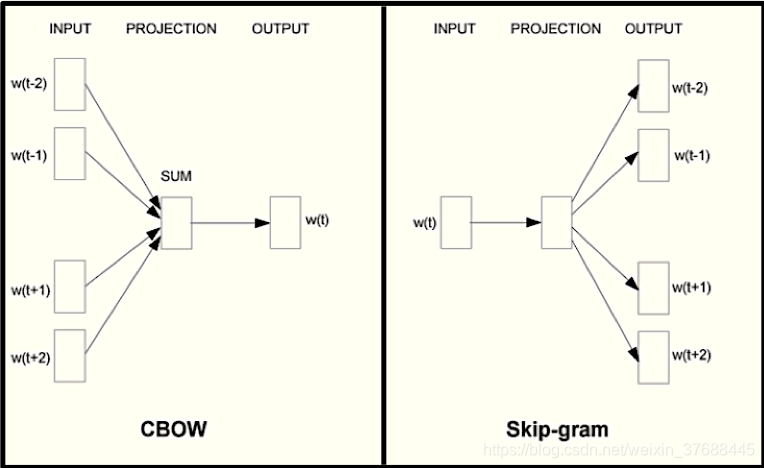
由于篇幅有限,这里只介绍SkipGram的实现方法。这里需要声明几个变量,sentence代表输入的raw数据,n代表的是最终获取到的每一条训练数据的维度,k代表的是中心词左右的滑动子窗口的大小,即整体滑动窗口的大小是2k+1,可能这样讲有点难懂,下面代码实现能比较清楚地展现计算过程。
from nltk.util import ngrams
from itertools import combination
def skipgrams(sentence, n, k):
SENTINEL = object()
ngrams_list = list(ngrams(sentence, n + k, \
pad_right=True, right_pad_symbol=SENTINEL))
for ngram in ngrams_list:
head = ngram[:1]
tail = ngram[1:]
for skip_tail in combinations(tail, n - 1):
if skip_tail[-1] is SENTINEL:
continue
yield head + skip_tail
为了能够更加清晰地了解这段代码背后的思想,以sentence="1 2 3 4 5 6 7 8 9 10 11 12 13 14, n = 3, k = 5"为例,来介绍算法的流程。首先,通过调用ngrams函数来构建sentence的n+k gram,这样操作的意义在于第一个中心词向左获取训练样本能够正常进行,下图是对这里描述的进一步解释。
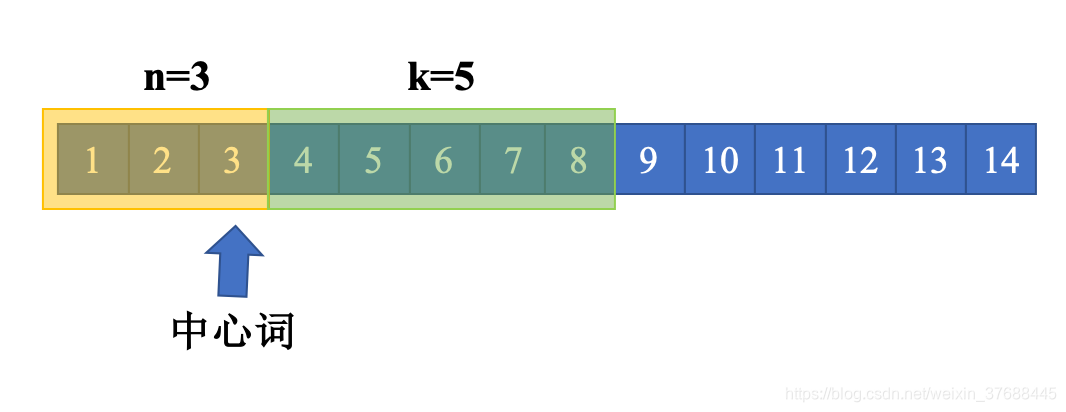
针对每一个gram,固定首元素
,针对剩下的n+k-1个元素,随机选择两个元素
(其中
代表的是grams中的第
个gram),将
与这两个元素拼接在一起作为一条训练数据
,这样对于每一个gram,都有
种组合,这样就能够不重不漏地将所有的训练数据构建完成。
2. 模型构建
模型的总体结构如下图所示,总共有三层:输入层,隐藏层和输出层。
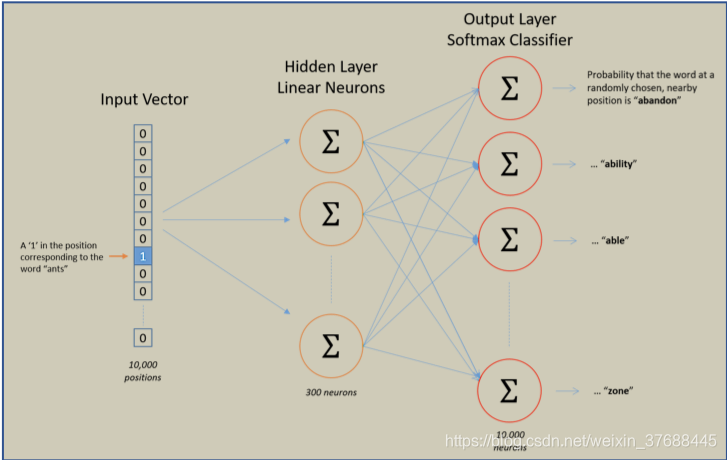
为了更加形象的描述模型构建过程,这里假设词表中有10000个词,三层具体情况如下所示:
-
输入层
输入为一个词的one-hot向量,one-hot向量的长度为vocabulary中词的个数。这个词在vocabulary中的哪个位置,哪个位置上的数值为1,其他位置为0,即one-hot向量为
[0,1,0,0,0,...,0]。 -
隐藏层
定义隐藏层的参数矩阵为
[10000, 300], 这个矩阵其实就是词向量矩阵,因为与之相乘的向量是一个one-hot向量。 -
输出层
输出层的纬度为
[300, 10000], 隐藏层输出的向量与输出层相乘,输出一个维度为10000的向量,这个向量再经过SoftMax归一化,生成一个概率向量,进而与标签进行损失函数计算,从而进行反向传播,经过若干次迭代之后得到训练好的模型。
3. 损失函数构建
从第二节的输出层的损失函数的构建过程来看,上述损失函数的构建过程有一个很大的问题,对于语言模型来说,这样做将会非常耗时且耗费内存,因为语言模型的vocabulary都很长,vocabulary的每个位置都算是一类,这个多分类任务是非常庞大的,因为进行一次损失函数的计算将会非常吃力,这里介绍两种加速算法,分别是NCE损失和层次SoftMax,这两种方法的核心思想都是通过降低每次迭代过程中计算
3.1. NCE 损失
其实计算SoftMax损失函数的核心思想在于利用一个正样本和其他所有的负样本来对模型做训练,NCE损失计算的基本思想为提取一个正样本,且按照某种分布Q提取k个负样本(而不是全部的负样本),针对这k+1个样本进行梯度的学习,这k+1个样本的类别数即为这一次采样过后SoftMax计算的类别数,这样就能大大节省计算量了。
例如词
的上下文是
,
代表的是k个从Q中提取出来的负样本,其中提取一个正样本取决于经验分布
和上下文
, 提取一个负样本取决于
,因而
如下所示:
更近一步,有
又
其中
代表的是输出的embedding,这里可以直接将
简化为1,因而有
, 因而
根据蒙特卡洛法(平均积分)可得损失函数为:
tensorflow的应用示例如下所示:
VOCABULARY_SIZE = 5000
EMBEDDING_SIZE = 128
NUM_SAMPLED = 64
graph = tf.Graph()
with graph.as_default():
inputs = tf.placeholder(tf.int32, shape=[None])
targets = tf.placeholder(tf.int32, shape=[None, 1])
with tf.device('/gpu:0'):
embeddings = tf.Variable(
tf.random_uniform([VOCABULARY_SIZE, EMBEDDING_SIZE], -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, inputs)
nce_weights = tf.Variable(
tf.truncated_normal([VOCABULARY_SIZE, EMBEDDING_SIZE],
stddev=1.0 / math.sqrt(EMBEDDING_SIZE)))
nce_biases = tf.Variable(tf.zeros([VOCABULARY_SIZE]), dtype=tf.float32)
loss = tf.reduce_mean(
tf.nn.nce_loss(weights=nce_weights, biases=nce_biases, inputs=embed, labels=targets,
num_sampled=NUM_SAMPLED, num_classes=VOCABULARY_SIZE))
tf.summary.scalar("loss", loss)
train_op = tf.train.AdamOptimizer(LEARNING_RATE).minimize(loss)
init = tf.global_variables_initializer()
3.2. 层次SoftMax
既然每训练一个样本,就要遍历整个词典,那么就缩短计算计算路径,且词典中出现频次越高的单词,其概率应该越大,这是我理解的层次SoftMax的中心思想。
首先根据单词出现的词频构建哈夫曼树,树的每个根节点代表的是词典中的一个单词。算法的伪代码如下所示:
while (单词列表长度>1) {
从单词列表中挑选出出现频率最小的两个单词 ;
创建一个新的中间节点,其左右节点分别是之前的两个单词节点 ;
从单词列表中删除那两个单词节点并插入新的中间节点 ;
}
这里为了方便地解释后面的一系列公式,这里首先介绍一些符号,如下所示,
: 从根节点出发到达叶子节点w的路径
: 路径中包含的节点的个数
: 路径中的各个节点
: 词的编码
: 非叶子结点对应的参数向量。
这里给出基于w的上下文推导出的条件概率为:
从根节点到叶子节点经过了
个节点,每一个节点都是一个逻辑斯谛回归,即
目标函数如下所示:
这样进行传统的反向传播就能够学习到一个不错的模型。但现实情况下,层次SoftMax方法并不常用,因为该方法相较于NCE来说比较复杂。
4. 总结
本篇博客介绍了Word2Vec模型训练数据的获取方式,模型的网络结构的构建以及模型损失函数加速计算的方法,且中间有代码实现来辅助理解。
