NLP Word2Vec
1、NLP原理及基础
NLTK:
- 自带语料库
- 词性分类库
- 自带分类,分词功能
1.1 文本处理流程:
- 1、文本预处理
- 2、分词
- 3、make features
- 4、machine learning
把人能够理解的文本变成机器可以学习的表达式
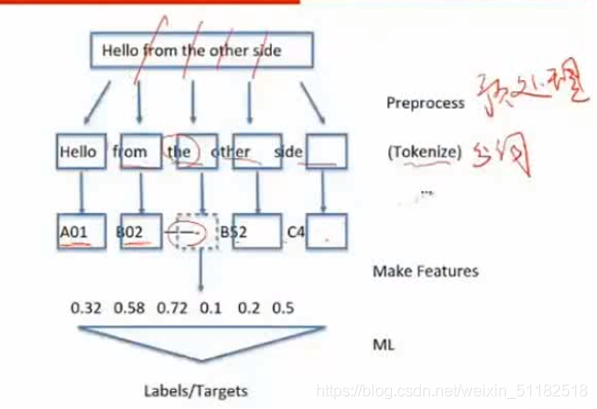
1.2 Tokensize:分词
对于英文:
tokens=nltk.word_tokensize(sentence)
对于中文:
自定义语料库,使用HMM/CRF等方法
import jieba
#jieba返回的是列表
seg_list=jieba.cut("我来到北京清华大学",cut_all=False)
#返回所有的可能的分词结果,适用于搜索引擎
seg_list1=jieba.cur_for_search("sentence")
1.3 特殊词处理
使用正则表达式对于非字母字符进行过滤

1.4 词性还原
walking ======= walk ========= walked
-
- stemming:词干提取
walking…>walk
- stemming:词干提取
ps = PorterStemmer()
word = ps.stem(word.lower())
-
- emmatization:词归归一
went…> go
- emmatization:词归归一
from nltk.stem import WordNet.Lemmatizer
leminatizer=WordNetLemminater()
word=leminatizer.lemmatize("word")
加入词的词性,可以更准确的还原
如果不指定pos,默认为NN
word=leminatizer.lemmatize("word",pos="v")
1.5 词性标注
返回的是(word,pos_tag)的形式
import nltk
nltk.pos_tag(text)
1.6 停用词处理
from nltk.corpus import stopwords
filter_words=[word for word in word_list if word not in stopwords.words("english")]
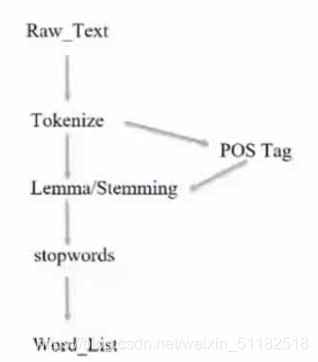
1.7 文本预处理流程
- 分词
- 词性标注
- 词性/词形还原
- 停用词过滤
- 生成数据清洗后的word_list
1.2 特征工程
- tf-idf: 表征了词在该篇文档中的重要性
- one-hot encoding :表达了文章中出现的词
- count_based:表达了词频
- word2vec:表达了词之间的相关性。泛化能力强。
如何计算相似度——余弦相似度
- 情感分析
- 文本分类
tf-idf例子:

可能的模型
- svm
- lr
- lstm
- rnn
2、Word2vec 理论基础
NLP处理方法
- 传统:基于规则
- 现代:基于统计机器学习
词编码需要保证词的相似性
2.1 分布式表示:
用一个词附近的词来表示该词:增加词语相关性,相似性大的词前后词应该也有一定的重合或相关。
共现矩阵
局域窗中的word-word共现矩阵可以挖掘语法和语义信息
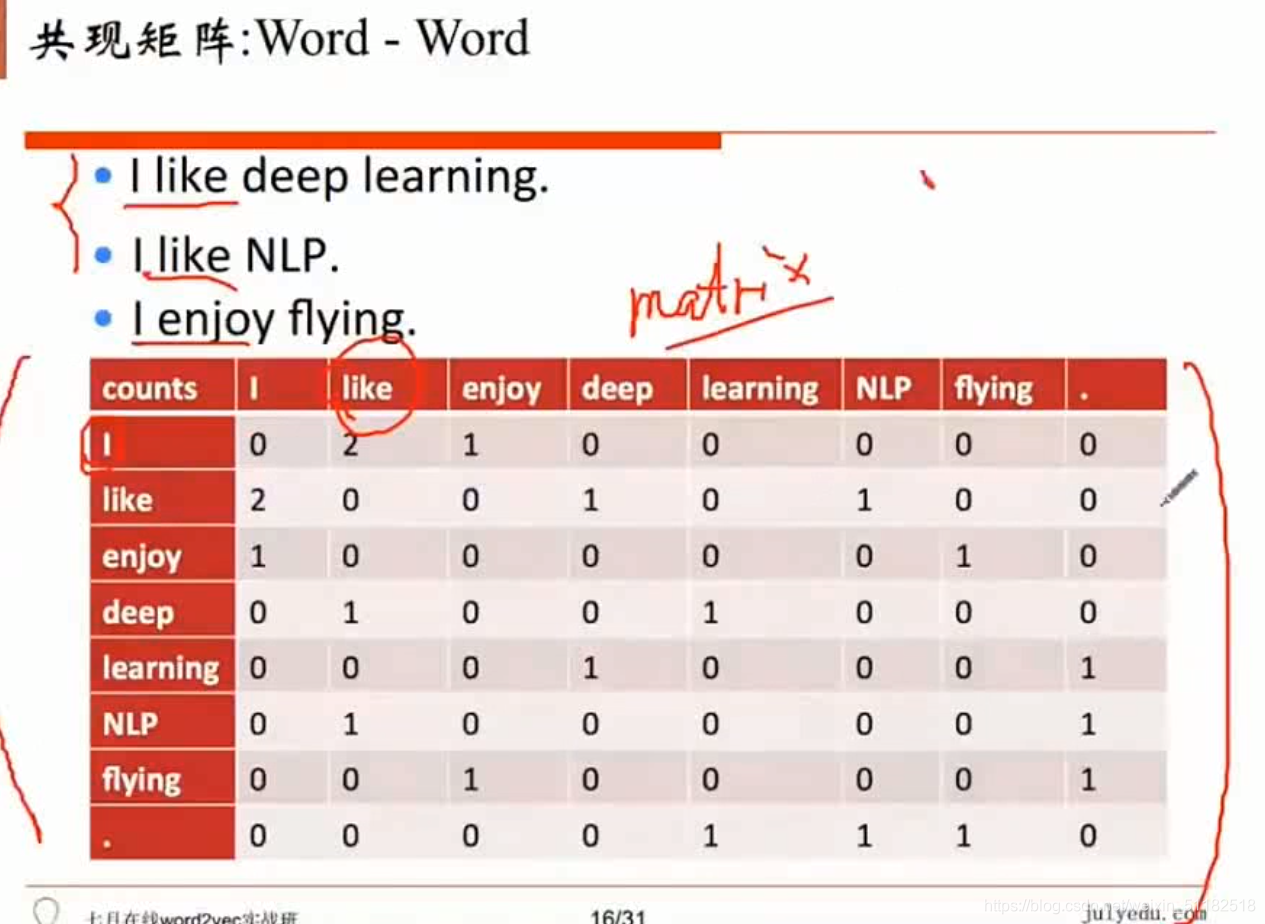
每一行都可以作为一个词向量。
问题:
-
向量维数随着字典大小线性增长
-
存储词典的空间消耗非常大
-
稀疏性,不稳定性
解决: :降维
用svd对共现矩阵降维。(计算量很大) -
cbow:根据周边词预测中心词

- skip-gram:根据中心词预测周边词