NLP之Word2Vec详解
什么是 Word2vec?
在NLP中,如果你需要对语料库进行预处理,比如,英文语料库你可能需要大小写转换检查拼写错误等操作,如果是中文日语语料库你需要增加分词处理。在得到你想要的语料之后,将他们的one-hot向量作为word2vec的输入,通过word2vec训练低维词向量(word embedding)就可以了。本文旨在阐述word2vec如何将语料库的one-hot向量(模型的输入)转换成低维词向量(模型的中间产物,更具体来说是输入权重矩阵)。
word2vec有两种训练模型:CBOW模型和Skip-gram模型。
如果是用一个词语作为输入,来预测它周围的背景词,那这个模型叫做Skip-gram 模型。
而如果是拿一个词语的背景词作为输入,来预测这个词语本身,则是 CBOW 模型。
什么是Skip-gram模型?
在Skip-gram中,我们用一个词来预测它在文本序列周围的词。
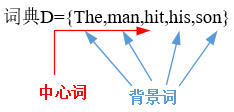
跳字模型所关心的是,给定中心词"hit" ,生成它背景词"the", " man", "his ,和"son"的概率。由于"hit"只生成与它距离不超过2的背景词,该时间窗口的大小为2。
Skip-gram模型
假设词典大小为|V|,我们将词典中的每个词与从0到|V|-1的整数一一对应︰词典索引集V={0,1…|V|-1}。给定一个长度为T的文本序列中,t时刻的词为w(t)。当时间窗口大小为m时,跳字模型需要最大化给定任一中心词生成背景词的概率:
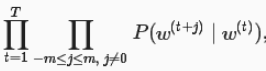
上式的最大似然估计与最小化以下损失函数等价
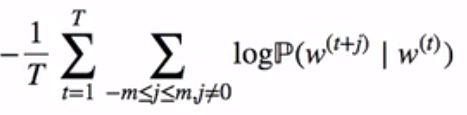
我们可以用v和u分别代表中心词和背景词的向量。换言之,对于词典中一个索引为i的词,它在作为中心词和背景词时的向量表示分别是vi和ui。而词典中所有词的这两种向量正是跳字模型所要学习的模型参数。
为了将模型参数植入损失函数,我们需要使用模型参数表达损失函数中的中心词生成背景词的概率。假设中心词生成各个背景词的概率是相互独立的。给定中心词wc在词典中索引为c,背景词wo在词典中索引为o,损失函数中的中心词生成背景词的概率可以使用softmax函数定义为
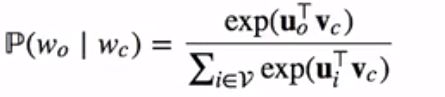
当序列长度T较大时,我们通常随机采样一个较小的子序列来计算损失函数并使用随机梯度下降优化该损失函数。通过微分,我们可以计算出上式生成概率的对数关于中心词向量vc的梯度为:
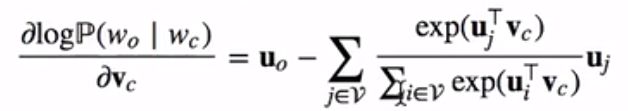
而上式与下式等价:
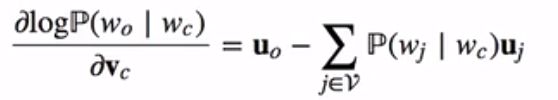
通过上面计算得到梯度后,我们可以使用随机梯度下降来不断迭代模型参数vc。其他模型参数uo的迭代方式同理可得。最终,对于词典中的任一索引为i的词,我们均得到该词作为中心词和背景词的两组词向量vi和ui。
什么是CBOW模型?
连续词袋模型中用一个中心词在文本序列周围的背景词来预测该中心词。
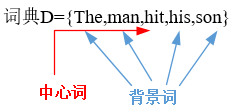
连续词袋模型所关心的是,背景词"“the" “man”’, " his ",和"son"一起生成中心词"hit"的概率。
CBOW模型
假设词典大小为|V|,我们将词典中的每个词与从0到|V|-1的整数一一对应。词典索引集V={0,1…|V|-1}。给定一个长度为T的文本序列中,t时刻的词为w(t)。当时间窗口大小为m时,连续词袋模型需要最大化由背景词生成任一中心词的概率:

上式的最大似然估计与最小化以下损失函数等价
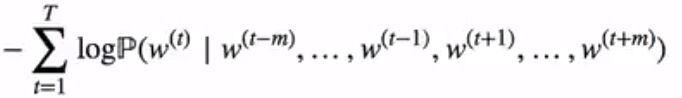
我们可以用v和u分别代表背景词和中心词的向量。换言之,对于词典中一个索引为i的词,它在作为背景词和中心词时的向量表示分别是vi和ui。为了将模型参数植入损失函数,我们需要使用模型参数表达损失函数中的中心词生成背景词的概率。给定中心词wc在词典中索引为c,背景词Wo1, … , w2m在词典中索引为o1, … , o2m,损失函数中的背景词生成中心词的概率可以使用softmax函数定义为
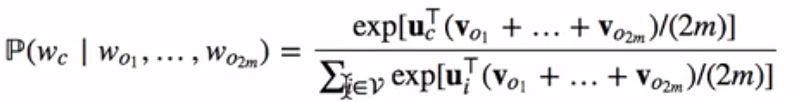
当序列长度T较大时,我们通常随机采样一个较小的子序列来计算损失函数并使用随机梯度下降法优化该损失函数。通过微分,我们可以计算出上式生成概率的对数关于任一背景词向量voi(i = 1,…, 2m)的梯度为:
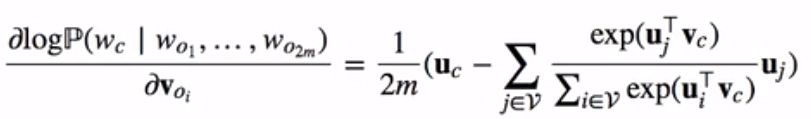
而上式与下式等价:
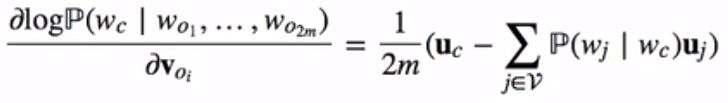
通过上面计算得到梯度后,我们可以使用随机梯度下降法来不断迭代各个模型参数voi(i= 1,…,2m)。其他模型参数uc的迭代方式同理可得。最终,对于词典中的任一索引为i的词,我们均得到该词作为背景词和中心词的两组词向量vi和ui。
注意:由于softmax的出现造成最后的梯度计算与词典的大小|V|相关,因此梯度计算开销会很大。为此出现了两种高效的训练方法:负采样和层序softmax。