版权声明:===========版权所有,可随意转载,欢迎互相交流=========== https://blog.csdn.net/weixin_42446330/article/details/85178956
以下是我的学习笔记,以及总结,如有错误之处请不吝赐教。
词向量:
NLP的发展主要有两个方向:
- 传统方向:基于规则
- 现代方向:基于统计机器学习:如HMM(隐马尔可夫)、CRF(条件随机场)、SVM、LDA(主题模型)、CNN..
词向量需要保证空间中分布的相似性:

离散表示进阶:
- One-hot表示:很容易理解,即在有词的地方填充1,其他地方填充0,作为一个长向量。

- Bag of Words(词袋模型)表示:是在one-hot基础上进行优化,用单词出现的次数来表示文档。文档的向量表示可以直接将各词的词向量表示加和:
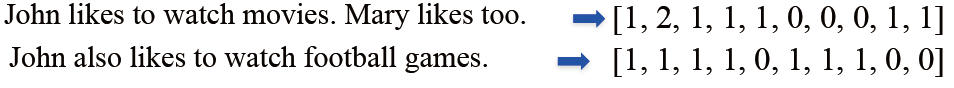
- TF-IDF是进一步优化了考虑单词在整体文档中的频次:

- Bi-gram和N-gram表示:前面的两种方法都只是表示了单个单词的关系,没有上下文顺序的关系,因此发展出了N-gram和Bi-gram(如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为 Bi-gram:参考一),一句话 (词组合) 出现的概率为:
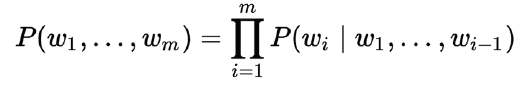

这样表示的优点是:考虑的了词顺序,但是缺点是词表膨胀,导致计算量增大。
- 离散表示的问题:
①无法衡量词向量之间的关系;
②词表维度随着语料库增长膨胀;
③n-gram词序列随语料库膨胀更快;
④数据稀疏问题。
分布式表示 (Distributed representation) :在离散表示的基础上发展而出,用一个词附近的其他词表示该词,被称为现代统计自然语言最有创见的想法之一,举例如下:

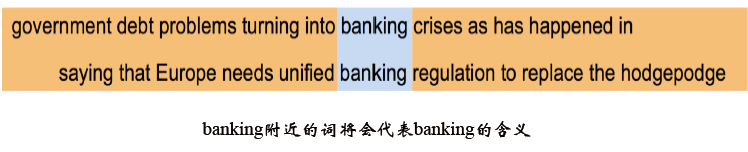
- 共现矩阵(Cocurrence matrix):Word - Document 的共现矩阵主要用于发现主题(topic),用于主题模型,如LSA (Latent Semantic Analysis), 局域窗中的Word - Word 共现矩阵可以挖掘语法和语义信息:


将共现矩阵行(列)作为词向量存在问题:
- 向量维数随着词典大小线性增长;
- 存储整个词典的空间消耗非常大;
- 一些模型如文本分类模型会面临稀疏性问题;
- 模型会欠稳定
SVD降维:受上面存在的问题,进行改进构造低维稠密向量 (25~1000维)作为词的分布式表示,想到用SVD对共现矩阵向量做降维 :

但是也同样存在问题:
- 计算量随语料库和词典增长膨胀太快,对X(n,n)维的矩阵,计算量O(n^3)。 而对大型的语料库,n~400k,语料库大小1~60B token ;
- 难以为词典中新加入的词分配词向量;
- 与其他深度学习模型框架差异大。
Word2vec:
上面叙述了很多词向量表示方法,现在终于进入正题。
NNLM (Neural Network Language model) :这个模型可以说是word2vec的前身,它直接从语言模型出发,将模型最优化过程转化为词向量表示的过程 ,目标函数为:
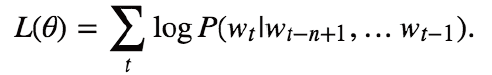
- 改进点:
①使用了非对称的前向窗函数,窗长度为n-1;
②滑动窗口遍历整个语料库求和,计算量正比于语料库大小 ;
③概率P满足归一化条件,这样不同位置t处的概率才能相加,即:
- 结构:

其中:
①(N-1)个前向词:one-hot表示;
②采用线性映射将one-hot表示投影到稠密D维表示 ;
③输出层:Softmax;
④各层权重最优化:BP+SGD ;
⑤词典维数V,稠密词向量表示维数D 。
计算复杂度:每个训练样本的计算复杂度为:N * D + N * D * H + H * V(ps:一个简单模型在大数据量上的表现比复杂模型在少数据量上的表现会好 ):

CBOW(连续词袋):是word2vec模型的一种,从单词袋上下文预测目标单词,结构如下:

- 特点:①无隐层;②使用双向上下文窗口;③输入层直接使用低维稠密表示;④投影层简化为求和(平均)。
- 目标函数:

- 概率分布计算方法:
(1)层次softmax:①使用Huffman Tree 来编码输出层的词典 ;②只需要计算路径上所有非叶子节点词向量的贡献即可 ;③计算量降为树的深度 V => log_2(V) :
那么:
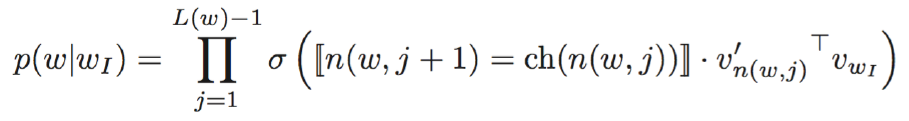 其中:
其中:
①Sigmoid函数:
②n(w,j):Huffman数内部第j层的节点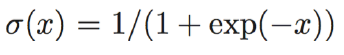
③ch(n(w,j)):n节点的child节点
④[[n(w,j+1)=ch(n(w,j)]] 是选择函数,表明只选择从根节点到目标叶节点路径上的内部节点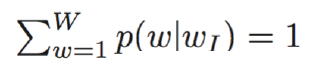
(2)负例采样:P(w|context(w)): 一个正样本,V-1个负样本,对负样本做采样:
其中:
是context(w)中词向量的和 ,
是词u对应的一个(辅助)向量 ,NEG(w)是w的负样本采样子集
损失函数:对语料库中所有词w求和 :
词典中的每一个词对应一条线段,所有词组成了[0,1]间的剖分: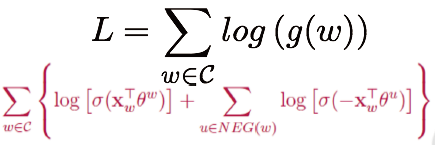
实际使用中取counter(w)^(3/4)效果最好,l1,l2,.....,ln组成了[0, 1]间的剖分: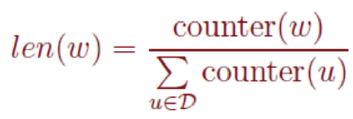
将[0, 1]划分为M=10^8等分,每次随机生成一个[1, M-1]间的整数,看落在那个词对应的剖分上。
Skip-grams (SG):这是word2vec模型的另一种,是预测给定目标的上下文单词:

- 结构如下:

- 特点与CBOW类似:
①无隐层 ;②投影层也可省略;③每个词向量作为log-linear模型的输入 ; - 目标函数:

- 概率密度由softmax计算:
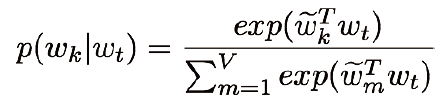
Word2Vec: 存在的问题:
- 对每个local context window单独训练,没有利用包含在global co-currence矩阵中的统计信息;
- 对多义词无法很好的表示和处理,因为使用了唯一的词向量;
总结:
离散表示:
- One-hot representation, Bag Of Words Unigram语言模型
- N-gram词向量表示和语言模型
- Co-currence矩阵的行(列)向量作为词向量
分布式连续表示:
- Co-currence矩阵的SVD降维的低维词向量表示
- Word2Vec: Continuous Bag of Words Model
- Word2Vec: Skip-Gram Model

更多案例代码:欢迎关注我的github
To be continue......