前言
这是本人的第一篇博客,主要以记录自己的学习内容为主,由于水平有限,如果内容有误还请各位看官多多包涵,及时指正。本篇博客也多参考了各篇博客、书籍及视频,在此感谢各位前辈的指导。
这一篇博客将要介绍早期NLP发展阶段使用到的模型,随后引出至今为止依然在使用的词向量。
数学基础
贝叶斯公式
贝叶斯公式是英国数学家贝叶斯( Thomas Bayes)提出来的,用来描述两个条件概率之间的关系。若记P(A),P(B)分别表示事件A和事件B发生的概率,P(A|B)表示事件B发生的情况下事件A发生的概率,P(A,B)表示事件A,B同时发生的概率,则有
根据上面的公式进一步推出
以上便是贝叶斯公式。
统计语言模型
简单说来,统计语言模型简单来讲就是计算一个句子出现概率的概率模型。
模型原理
假设一个句子W 由T个词
按顺序组成,记作
则一个句子的概率就是词
的联合概率
根据贝叶斯公式,上式分解为
这里等式右边的式子中各项条件概率便是该语言模型(LM)的参数了。如果计算得到了这些参数,那么就可以通过上面的式子计算得到句子出现的概率。
接下来介绍计算这些参数的方法。计算参数的方法有很多,这里只介绍n-gram和神经网络两种。
参数计算
现在考虑计算上面式子中的一个参数
。根据贝叶斯公式,有
根据大数定理,当语料库足够大时,上式近似表示为
其中
和
分别表示词串
和
在语料中出现的次数,即对语料中出现次数进行统计,这也是为什么该模型被称为统计语言模型的原因。
如果
很大的时候,
和
的统计非常耗时。
n-gram模型
n-gram的基本思想是:一个词的出现概率只和其之前n-1个词有关,从而大大降低计算复杂度。即
根据贝叶斯公式和大数定理,上式转化成
n的取值是一个值得考究的问题,如果n过小,那么模型的效果肯定不行;但是如果n的取值过大,需要计算的参数会指数级增长,计算将非常耗时。实际应用中n=3是常用取值。
神经网络
在机器学习领域通常的做法是:对所考虑的问题建模后先为其构造一个目标函数,然后对这个目标函数进行优化,从而求得一组最优的参数,最后利用这组最优参数对应的模型来进行预测。
对于统计语言模型,构造目标函数为极大似然,即
其中
表示语料(Corpus),
表示词的上下文,即
周边的词的集合。
实际应用中,目标函数也会常采用极大对数似然
接下来将进一步介绍使用神经网络的模型。
神经网络语言模型(NNLM)
概述
- 应用场景:已知前文数个词语,通过概率计算预测下一个词。
- 输入:语料中词 以及它的上下文{ };
- 输出:预测语料中基于前文的前提下每个词的概率 (即类条件概率);
- 目标:最大化似然函数。
网络结构
NNLM具有三层网络结构,分别为输入(投影)层、隐含层和输出层,如下图所示。
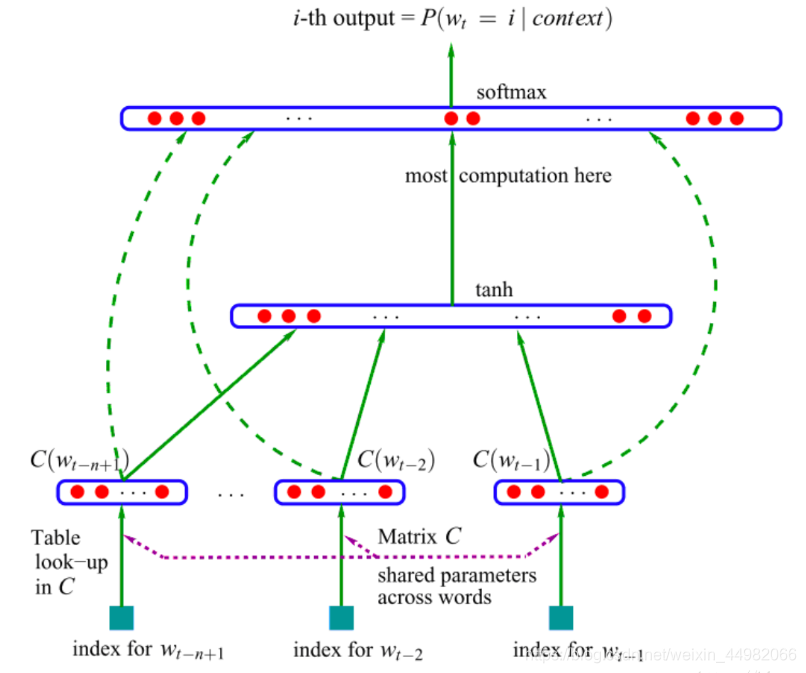
这里首次出现了词向量的输入处理,关于词向量的介绍放在下一节,在此我们专注于介绍网络结构。
- 输入(投影)层
- 将语料中所有不重复的词语提取出来作为词典。这里的输入是传统one-hot编码。one-hot是早期对词语进行编码的形式,在以词典所构成的维度大小的向量中,每一个词对应位标记为1,其余位全为0(关于one-hot更详细的解释建议看官查阅其它博客)。因此也可以将每个词的one-hot看作是每一个词的索引,根据这个索引可以在从语料提取的词典中找到对应的词语。所以图中的输入表示为index。
- 从one-hot到词向量的转换本质上便是乘以一个转换矩阵C ,这里是共享参数的,所有输入进行相同的矩阵变换。但是为了提取一个词,我们要进行一次矩阵运算,比较低效,所以比较成熟的框架都提供了查表的方法,效率更高。这也就是图中的look-up table。
- 通过上一步操作得到每个词对应的词向量表示,最后将每个词向量拼接成句子矩阵输入到下一层。
- 隐含层
隐含层的操作比较简单,经过一层tanh激活函数运算输出到下一层。 - 输出层
最后的输出层的目的便是要得到每个词的类条件概率。于是将经过隐含层的计算输出进行归一化处理,使用softmax激活函数得到最终的概率。
需要注意的是,输出层这里使用了赫夫曼树的结构进行高效运算,感兴趣的看官可以查阅其它资料。
最后,训练过程便是使得正确词的类条件概率能够最大化的参数调整过程。
总结
在这个模型里面,词向量更像是一个副产物,不过这个副产物却带来了巨大的影响,下一节我们将深入理解。
最后我们讨论一下n-gram与NNLM的关系:n-gram是计算前n-1个词语条件下出现某个词语的概率,NNLM的话以这个概率公式为原型构造的目标函数,是n-gram演化而来的。
词向量及Word2Vec
One-hot Representation
在上一节中我们提到了one-hot representation,他属于词袋模型。one-hot representation用一个很长的向量来表示一个词,向量的长度为词典
的大小N,向量的分量只有一个1,其它全为0,1的位置对应该词在词典中的索引。
这种表示有一些缺点:
- 容易受维数灾难的困扰:one-hot representation都是非常稀疏的向量,将这样的向量直接输入将增加很多不必要的运算,耗时较长。
- 无法刻画相似词语之间的关系:one-hot representation只包含词典索引位置的信息,而词典中的词都是随意排列的;这样的数据直接进行学习好比死记硬背,泛化能力差。
Word Embedding
将one-hot representation转换成词向量的操作称作Word Embedding,词向量针对上面提到的缺点进行了改进。
- 类似语义的词语位置会比较接近,同时向量的每个维度都会代表特殊的含义。
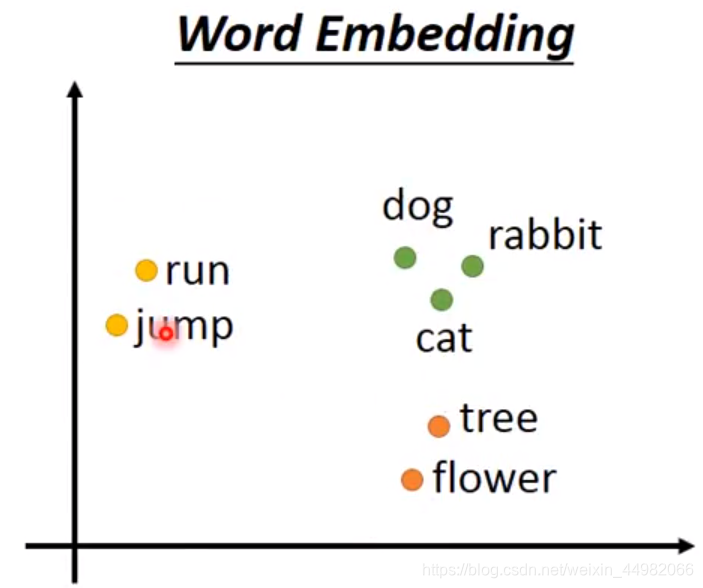
从上面这张图可以很好的解释这种优势,假定这个词向量的维度为2,则词向量空间即为一个平面。其中,动词和名词之间距离较远,植物之间、动物之间的距离很近。同时注意到,动词与动物几乎在同一高度,可以推测纵坐标可能代表着词语的动静含义;横坐标可能代表着词性的关系。 - 进一步地,相类似的词向量间存在着固定的关系,相同关系的词向量距离也是近乎相同的。
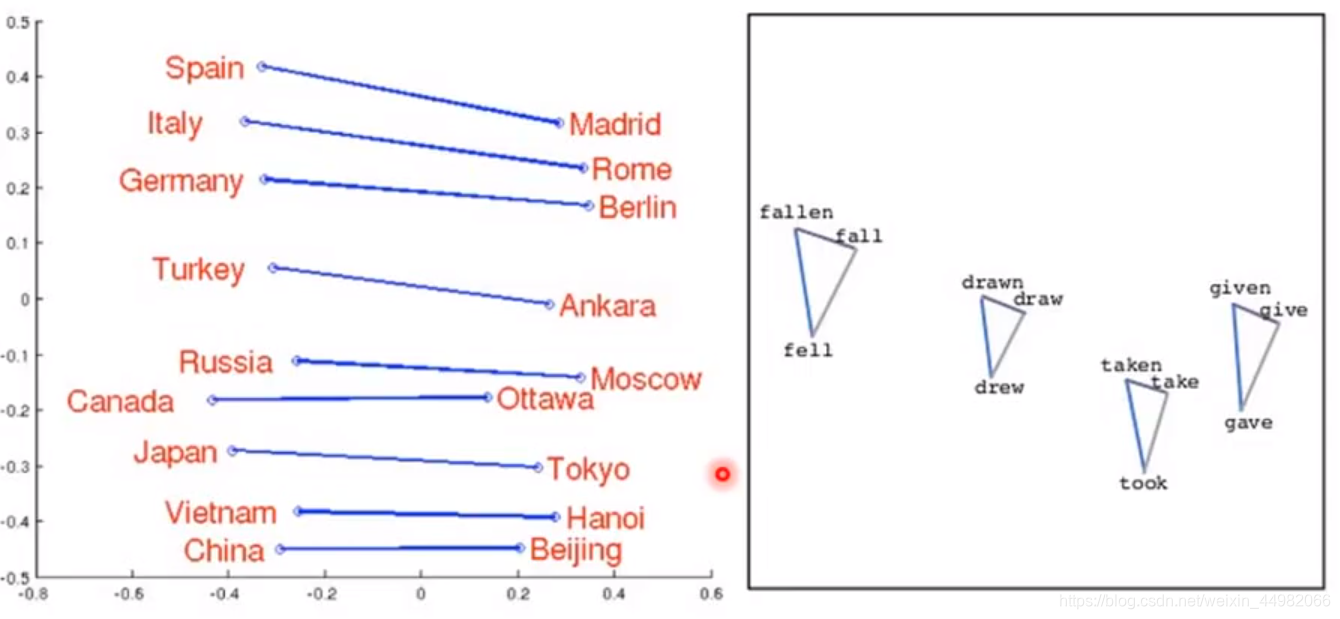

上面两张图非常清晰地展示了这种关系。将国家和首都的词向量,词语的不同时态词向量相连接,发现形成的形状是相似的,说明相似词向量存在固定的关系;接着定量分析,两种相同关系的词向量距离是近似的,因此已知另外一组相同关系词向量的距离可以间接推测其他对应的词向量。
Word Embedding是由机器阅读大量文章之后得到的,是一个无监督的过程。要使无监督过程起效果,实现的思路是词汇的含义可以由上下文来判断得到,或者更明白地说类似含义的词替换之后句子意思不会有问题。

获取词向量
介绍完词向量的优势之后,接下来就要考虑如何能够得到词向量的问题。这里有两种方法实现上述的思路:Count based和Prediction based。
简单介绍一下Count based:统计在相同文档中两个词出现的次数,与两个词的点积(相似度)成正相关,即使用出现频次来代表词向量间的距离。
我们将着重介绍Prediction based:训练一个网络,在给定上一个词的情况下得到输出下一个词的概率分布,在词语概率分布正确的情况下,其隐含层的输入即为所需要的词向量。
解释一下为什么隐含层输入就满足词向量的需求:Prediction based只有在隐含层学习到了较好的词向量特征才能够输出正确的概率分布,因此隐含层的输入确实是我们所需要的。
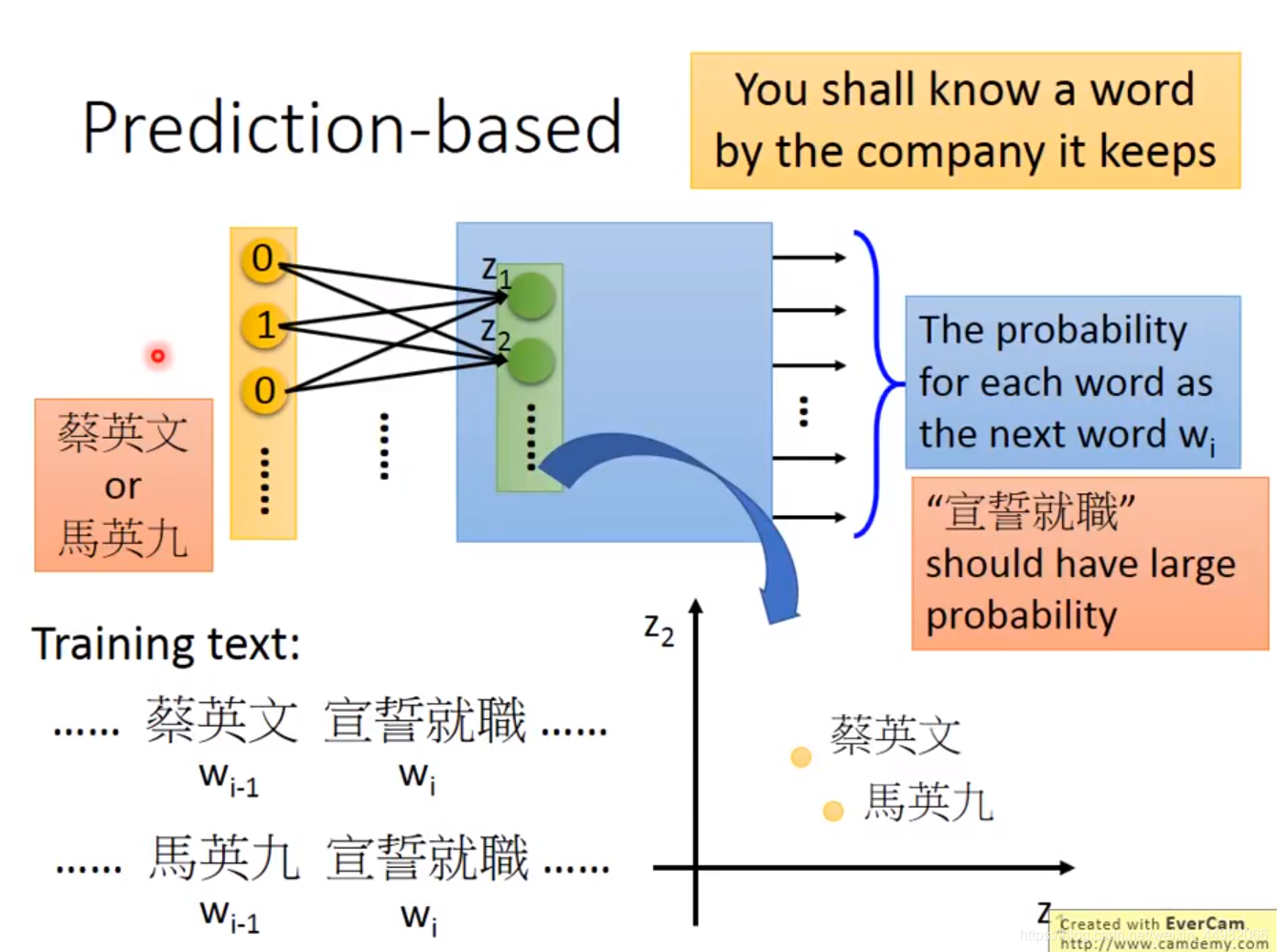
在网络训练过程中,我们只需要收集大量文本,将上下文输入到文本,最小化与正确词语概率分布之间的交叉熵即可。这里最小化交叉熵是等价于最大化极大似然的,具体的证明 可以参考知乎的文章。
单输入一个词汇的效果可能并不好,因此我们输入多个上文词汇,并且共享权重。共享权重目的是:可以减少参数数量,同时,避免上下文词语输入位置不一样而得到不同的结果。
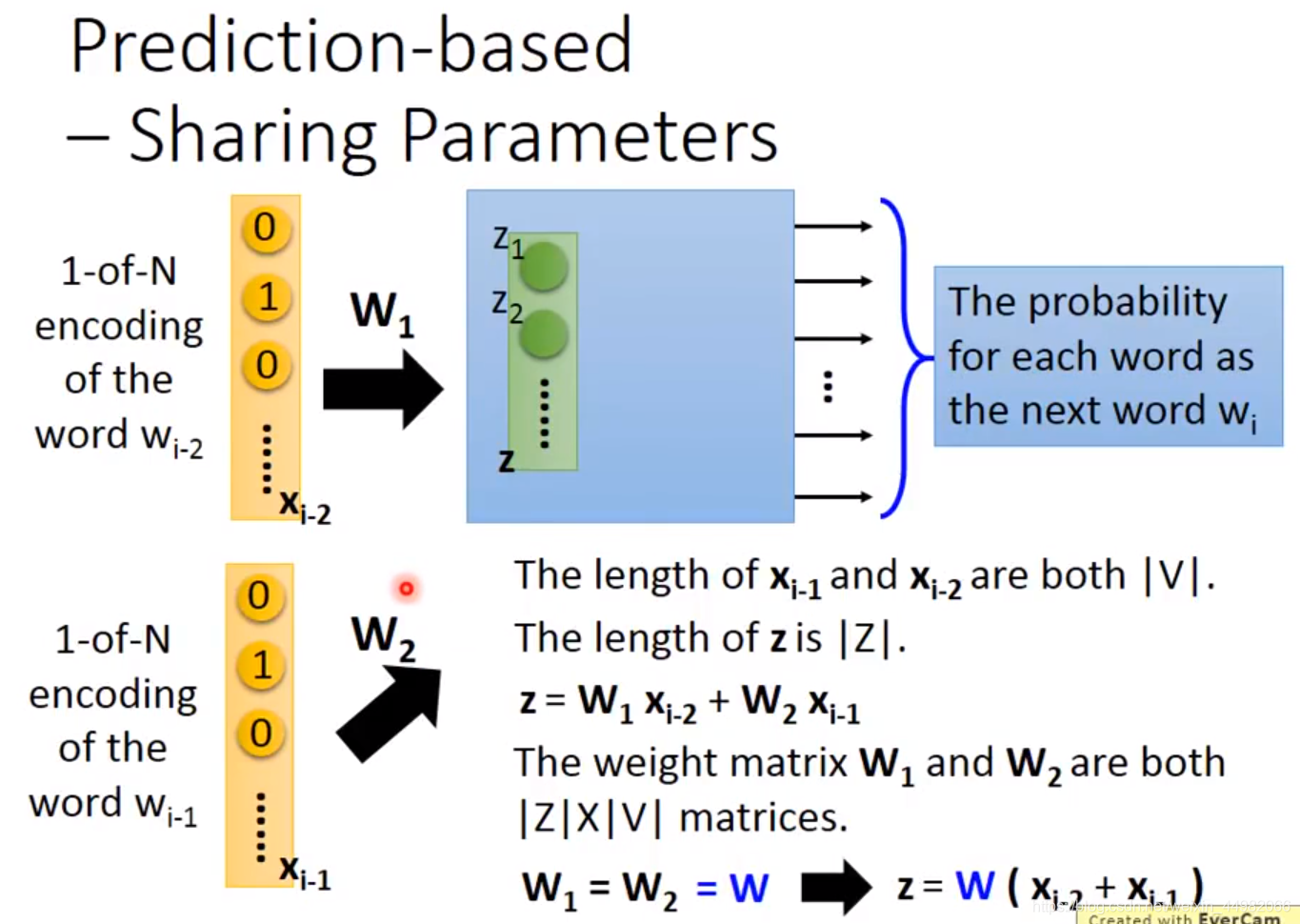
Word2Vec
接下来介绍广为人知的Word2Vec模型,也是基于上一小节提到的Prediction based方法。主要分为CBOW和Skip-gram两种模型。

它们都只有一层隐含层,同样,训练后取出隐含层的输入即为需要的词向量。
CBOW和feedforward NNLM非常相似。CBOW是输入前后文来预测中间词,而NNLM是只是输入前文,没有后文。Skip-gram则与之相反,输入中间词预测上下文。
参考资料
- word2vec 中的数学原理详解https://www.cnblogs.com/peghoty/p/3857839.html
- 李宏毅 深度学习19(完整版)国语https://www.bilibili.com/video/av48285039?p=67
- 神经网路语言模型(NNLM)的理解https://blog.csdn.net/lilong117194/article/details/82018008
最后欢迎各位看官指正错误,如果有不清楚的也欢迎留言,本人才疏学浅,会尽力回答。
