Depthwise Separable Convolution
1.简介
Depthwise Separable Convolution 是谷歌公司于2017年的CVPR中在论文”Xception: deep learning with depthwise separable convolutions”中提出。
2.结构简介
对输入图片进行分通道卷积后做1*1卷积。结构如下图: 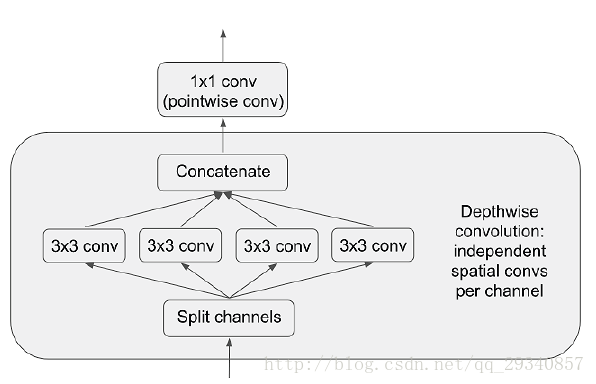
举例来说,假设输入通道数64,输出通道数64.
传统的Conv2D方法的参数数量为3*3*64*64;而SeparableConv2D的参数数量为3*3*64+1*1*64*64。
3*3*64:对输入的64个通道分别进行卷积
1*1*64*64:对concat后的64个通道进行1*1卷积(pointwise Convolution)
结论:参数数量减少了32192个。
3.适用范围
假设输入图片的空间位置是相较于通道之间关系是高度相关的。
depthwise_conv2d来源于深度可分离卷积
tf.nn.depthwise_conv2d(input,filter,strides,padding,rate=None,name=None,data_format=None)除去name参数用以指定该操作的name,data_format指定数据格式,与方法有关的一共五个参数:
-
input:
指需要做卷积的输入图像,要求是一个4维Tensor,具有[batch, height, width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数] -
filter:
相当于CNN中的卷积核,要求是一个4维Tensor,具有[filter_height, filter_width, in_channels, channel_multiplier]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,输入通道数,输出卷积乘子],同理这里第三维in_channels,就是参数value的第四维 -
strides:
卷积的滑动步长。 -
padding:
string类型的量,只能是”SAME”,”VALID”其中之一,这个值决定了不同边缘填充方式。 -
rate:
这个参数的详细解释见【Tensorflow】tf.nn.atrous_conv2d如何实现空洞卷积?
结果返回一个Tensor,shape为[batch, out_height, out_width, in_channels * channel_multiplier],注意这里输出通道变成了in_channels * channel_multiplier
tf.nn.separable_conv2d
可以看做,深度卷积tf.nn.depthwise_conv2d的扩展
- tf.nn.separable_conv2d(input,depthwise_filter,pointwise_filter,strides,padding,rate=None,name=None,data_format=None)
除去name参数用以指定该操作的name,data_format指定数据格式,与方法有关的一共六个参数:
-
input:
指需要做卷积的输入图像,要求是一个4维Tensor,具有[batch, height, width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数] -
depthwise_filter:
用来做depthwise_conv2d的卷积核,也就是说这个函数对输入首先做了一个深度卷积。它的shape规定是[filter_height, filter_width, in_channels, channel_multiplier] -
pointwise_filter:
用来做pointwise卷积的卷积核,什么是pointwise卷积呢?我们可以把它和GoogLeNet最原始版本Inception结构中后面的1*1卷积核做channel降维来做对比,这里也是用1*1的卷积核,输入通道是depthwise_conv2d的输出通道也就是in_channels * channel_multiplier,输出通道数可以自己定义。因为前面( 【Tensorflow】tf.nn.depthwise_conv2d如何实现深度卷积? )已经讲到过了,depthwise_conv2d是对输入图像的每一个channel分别做卷积输出的,那么这个操作我们可以看做是将深度卷积得到的分离的各个channel的信息做一个融合。它的shape规定是[1, 1, channel_multiplier * in_channels, out_channels] -
strides:
卷积的滑动步长。 -
padding:
string类型的量,只能是”SAME”,”VALID”其中之一,这个值决定了不同边缘填充方式。 - rate:
这个参数的详细解释见【Tensorflow】tf.nn.atrous_conv2d如何实现空洞卷积?
输出shape为[batch, out_height, out_width, out_channels]的Tensor