问题陈述和分析
原始数据可以从链接中下载,是一关于某项疾病的分类问题,表格中最后一列为标签,前面的278列是各项特征指标。其中标签为1 的为为患病样本,标签为2——15的为确定的患病的样本,标签为16的为不确定的患病样本。标签中缺少11、12、13的样本。对于这类问题首先想到的就是传统的机器学习方法SVM,再比较新颖的是lasso还有xgboost等方法。对于SVM分类器直接将特征送入模型中,用不超过70% 的数据训练,用剩余的数据进行测试。对于xgboost可以直接进行处理。对于lasso,可以用于特征降维与特征选择,将选择后的特征送入xgboost进行学习。整个工程代码和数据在这里。
SVM 三分类
因为从患病和不患病的角度看,这其实就是一个二分类问题,但是考虑到还有一种不确定的心脏病类型,问题可以看成一个三分类问题。首先将数据集分成训练集和测试集,其中训练集的样本数量为310个,测试集的样本数量为142个。

在数据处理的时候将空值置为0,将label放在数据的第一列,并保存为csv格式文件。训练集文件名为data_two_test.csv,测试集文件为data_two_test.csv。
训练过程与测试结果
整个框架是在tensorflow下进行的,训练和测试被我写在一个工程里,命名为svm_3_c权值文件保存在model1_1里。Batch设为100,迭代次数也是100。Optimizer是梯度下降法。
在迭代100次后学习到的结果如下:
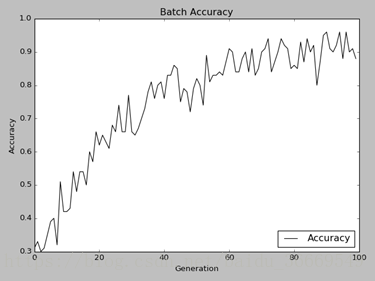
测试仍然是每次取100组数据进行测试,取10次最后取平均值。考虑其稳定性继续做了四次测试,测试精度在0.9附近。可以认为三分类有较高的精度。
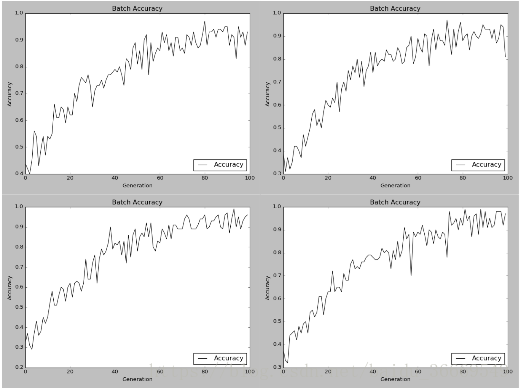
虽然三分类具有较高的精度,但是这并不是我们想得到的结果。想象病人得知自己得了某种确定的疾病,但是还不知道是哪一种确定的疾病,无论是心情还是对于整个治疗都没有什么帮助。但是三分类对于医生做进一步的诊断提供了有效且高精度的参考,如果患者得了某种确定的疾病,仍需人工的介入才能得到准确的诊断。
Xgboost + Lasso六分类
虑到xgboost的良好表现试着采用xgboost进行多分类。xgboost的数据需要进行预处理。还有一点就是标签不平衡问题,为了解决这个问题,又进行了六分类。六分类主要是考虑到不确定的心脏病类型仅有22个样本,所以我对确定的心脏病类型的185个样本重新分组得到六分类的结果。

训练过程与测试结果
xgboost的相关实验做了四组。第一组实验是源数据在无特征降维与选择下的实验,第二组是在lasso二分类标签下特征选择后再进行分类,第三组是在lasso三分类标签下特征选择后再进行分类,第四组是lasso六分类标签下特征选择后再进行实验。这几个实验分别在test_exp1、test_exp2、test_exp3、test_exp4文件夹中。

在第二组实验中,使用特征从279维降到25维准确率比没有使用特征选择时降低了。第三组实验中特征从279维降到30维,准确率有所提高。第四组实验将特征维度降低到36维,准确率已经比没有降低特征维度要高。所以使用特征选择可以有效的提升分类的准确度。
SVM 十三分类
由特征降维和特征选择能有效改善分类结果的启示,我又将这279个特征进行了特征排序,排序用的是ensemble里的随机森林回归。在此基础上对svm分类器进行优化。

由于每个score是一个三维向量,我的操作是求得平均值后在进行指数操作,底数是100000,这个数没有任何含义,只是为了将每个特征得分很好的区分开。这样操作的结果使这279个特征的得分变换范围变成0.27-4.13之间。得分最高的特征是‘V2 R wave amplitude’特征,得分最低的是‘Height’特征。

这个小节的实验将分成两个部分,一个是没有进行特征选择的svm分类器,一个是进行特征选择的svm分类器。
训练过程与测试结果
实验一
不进行特征选的svm13分类器的训练类似三分类,仍然在tensorflow框架下迭代100次,这里选择100次是因为实验室电脑比较老的原因。在编程实现要注意几个维度的变化即可。
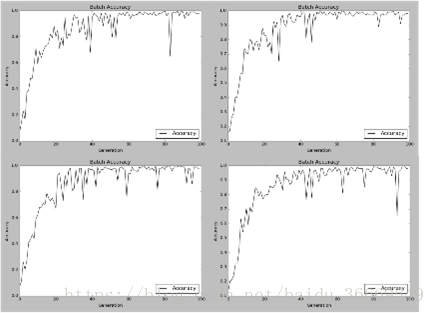
测试结果准确率分别是0.86100006、0.796、0.88500005、0.80200005。
实验二
只提取得分前名的20个特征进行分类,同样迭代100次,做四次得到训练结果如下图所示。只提取得分前名的20个特征进行分类,同样迭代100次,做四次得到训练结果如下图所示。

测试结果分别为0.8549999、0.8809999、0.82、0.857。个人感觉对比不明显,我将迭代次数从100升至1000。没有进行特征选择,做了两组实验结果分别为0.897、0.866。进行了特征选择的结果分别是0.916、0.896我将迭代次数上升至10000次,没有进行特征选择的测试精度分别为0.872、0.77,进行了特征选择的0.878、0.866。
总结
整个实验的实现以及完成是在不断学习和改进的过程中进行的。从前期模型论证,到特征工程是不断的实验论证,改代码的过程。尤其是最近实验室换电脑来回折腾耽搁了很多工作,思路也从svm转移到了xgboost,还有laasso。
之所以从xgboost又回到svm是因为做了一些实验发现精度很难提高,尤其是在svm还保持比较高的精度的前提下,xgboost的精度仍然在0.6左右徘徊时,毅然放弃了使用xgboost方法。
后来想了想,有一个原因非常重要,就是数据集不够大。传统的svm方法在针对小数据集类问题表现非常好,而xgboost相关方法从2014年开始在各大数据挖掘类比赛中表现抢眼,一个关键问题就是,比赛中的数据集基本上都是百万级别的,所以精度不高是情有可原的。