前面的博文简述的都是但分类问题,也就是最终的结果要么是1要么是0
可参考博文:七、加载数据集和八、泰坦尼克号数据集加载训练
像MNIST手写数字数据集这种10分类问题神经网络如何设计?
softmaxhh函数可参考博文:九、逻辑回归多分类和softmax多分类
离散分布满足条件: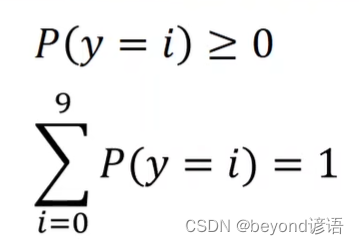
softmax函数表达式
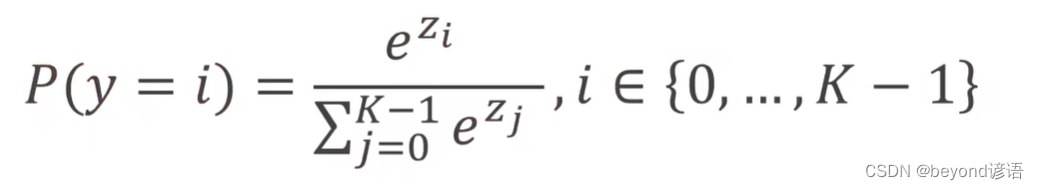
softmax层
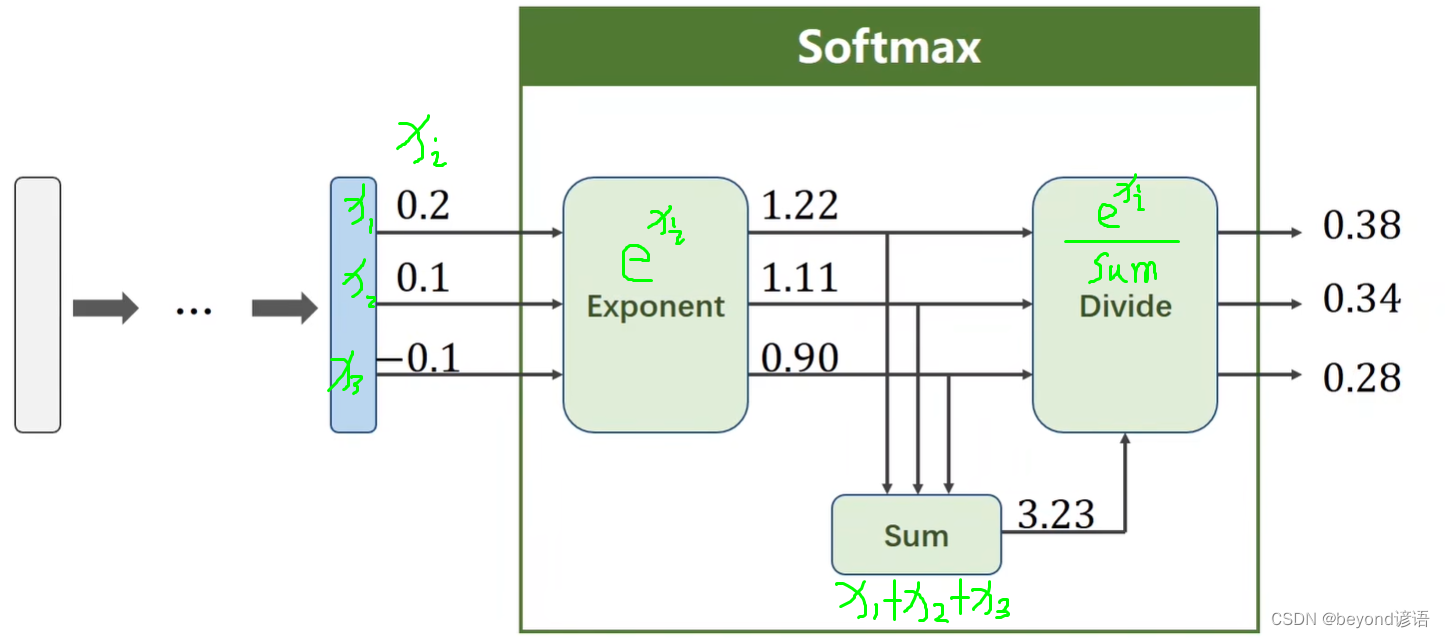
在多分类任务中,无论有多少类别,只有一项是非零的,剩下的都是零的结果类别都是没啥用的。此时引入了one_hot编码,可参考博文:十一、决策树和随机森林
NLL(Negative Log Likelihood) Loss
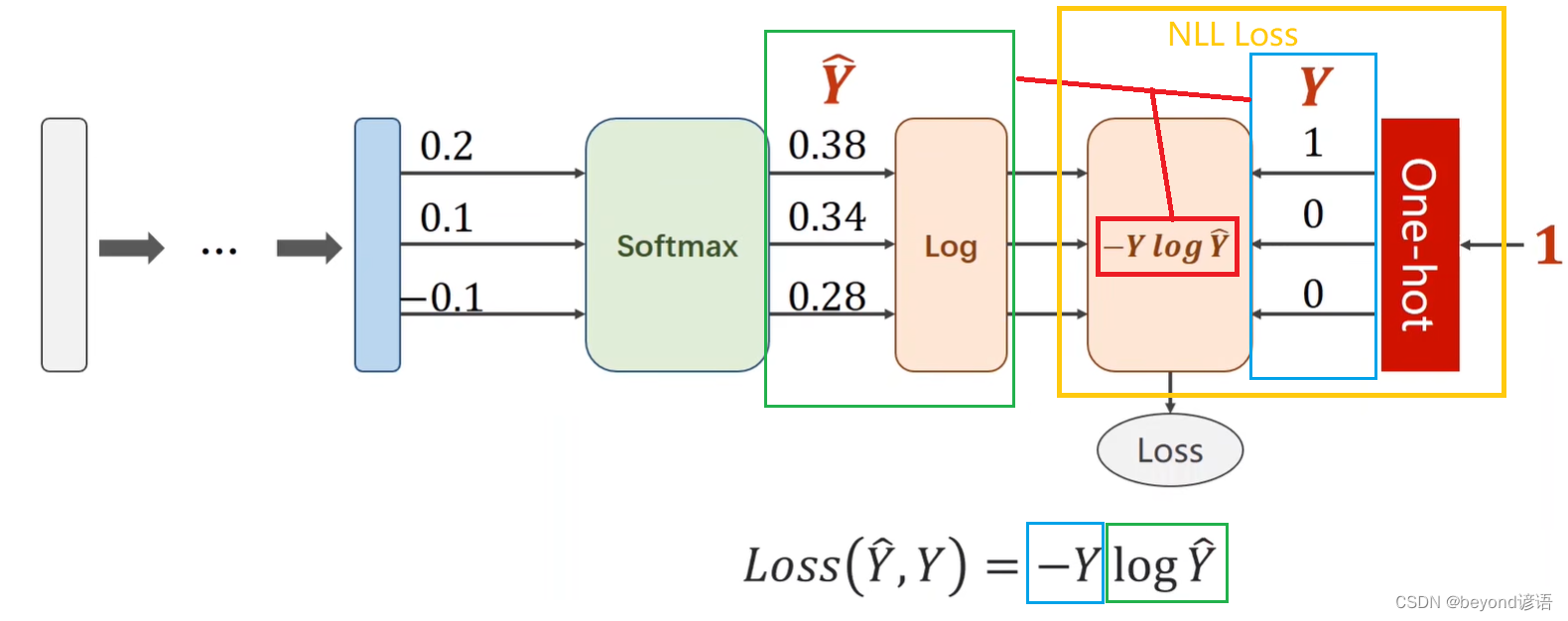
Cross Entropy交叉熵
交叉熵详情可参考博文:十三、Loss Functions
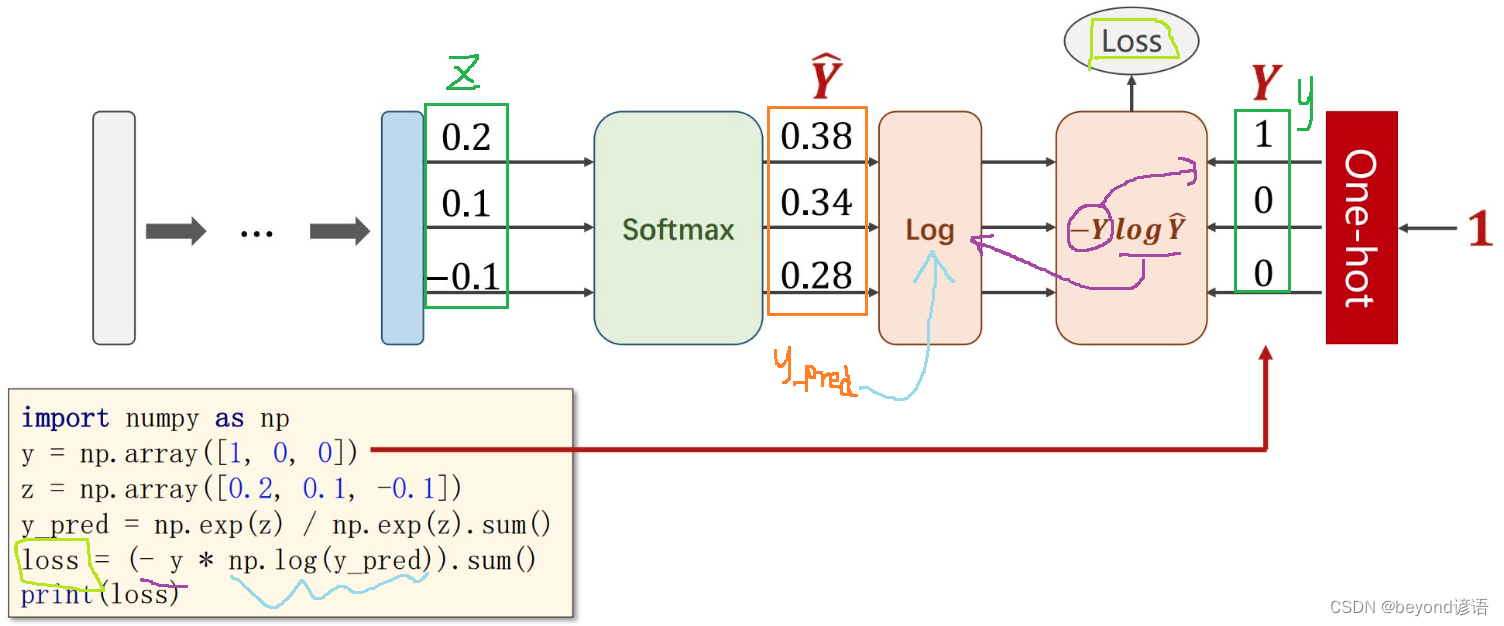
import numpy as np
y = np.array([1,0,0])
x = np.array([0.2,0.1,-0.1])
y_hat = np.exp(x) / np.exp(x).sum()
loss = (- y * np.log(y_hat)).sum()
print(loss.item())
"""
0.9729189131256584
"""
在pytroch中已经封装好了
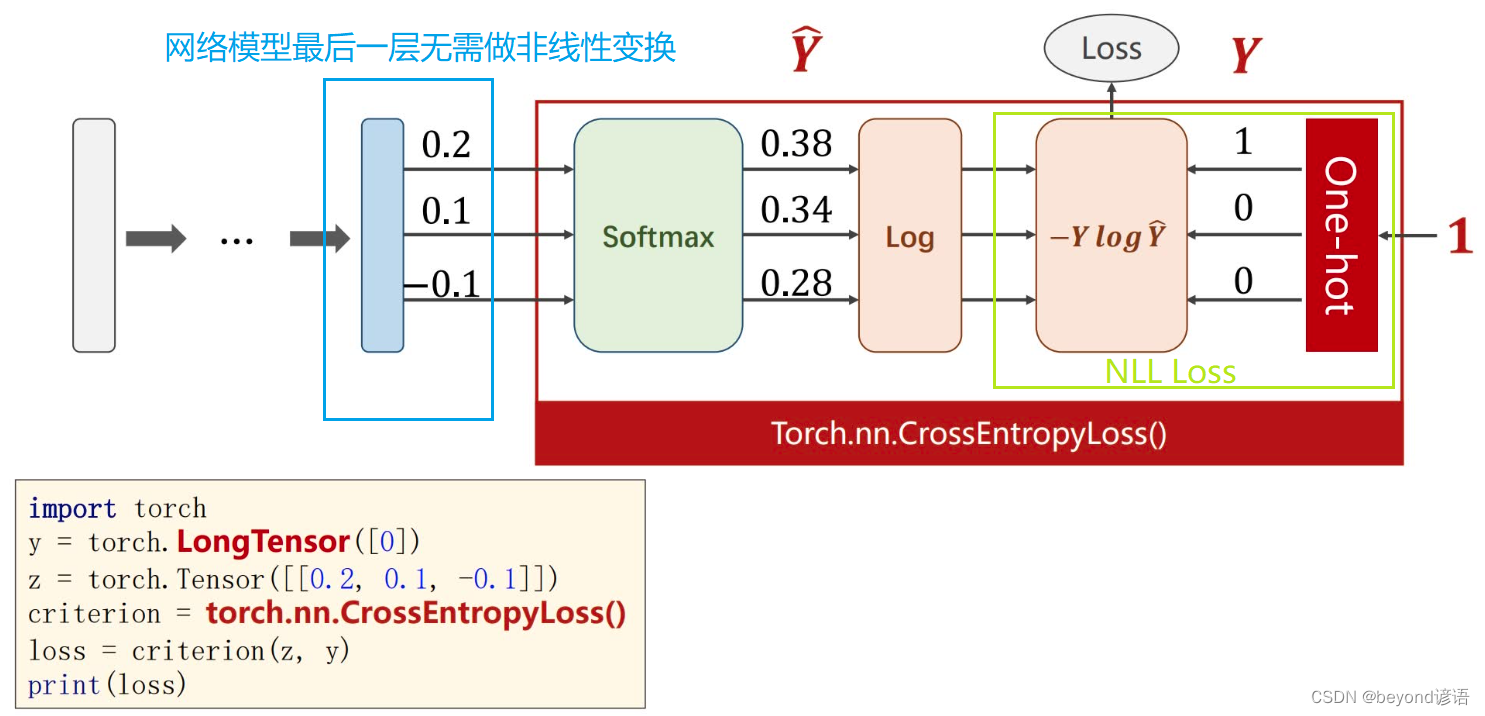
注意事项:
y必须是长整型的张量
损失函数构造的时候直接torch.nn.CrossEntropyLoss()
按上图所示,Y是[1,0,0]也就是这个x属于第0类,即y = torch.LongTensor([0])
x输入为x = torch.Tensor([[0.2,0.1,-0.1]])
交叉熵损失函数计算得传入x和y
import torch
y = torch.LongTensor([0])
x = torch.Tensor([[0.2,0.1,-0.1]])
CE = torch.nn.CrossEntropyLoss()
loss = CE(x,y)
print(loss.item())
"""
0.9729189276695251
"""
直接计算结果:0.9729189131256584
调用API计算结果:0.9729189276695251
通过直接计算和调用API计算,结果并不完全一样,但大差不差。想要探索个究竟可以去pytorch官方文档扒拉细节。
现学现卖
有两组模型预测数据,每组有三个样本结果,真正的类别分别属于2、0、1类
也就是说,真实样本结果y=[2,0,1]
第一组预测
第一个样本[0.1,0.2,0.9] 本因属于2类,模型预测结果也是2类
第二个样本[1.1,0.1,0.2] 本因属于0类,模型预测结果也是0类
第三个样本[0.2,2.1,0.1] 本因属于1类,模型预测结果也是1类
第二组预测
第一个样本[0.8,0.2,0.3] 本因属于2类,但模型预测结果显然是0类
第二个样本[0.2,0.3,0.5] 本因属于0类,但模型预测结果显然是2类
第三个样本[0.2,0.2,0.5] 本因属于1类,但模型预测结果显然是2类
很显然,第一组样本猜的效果更好一些,最终的结果对应的loss应该较小
import torch
lossf = torch.nn.CrossEntropyLoss() #定义交叉熵函数对象
Y = torch.LongTensor([2,0,1])
y1_hat = torch.torch.Tensor([[0.1,0.2,0.9],
[1.2,0.1,0.3],
[0.1,3.1,0.2]])
y2_hat = torch.torch.Tensor([[0.8,0.2,0.3],
[0.2,0.3,0.5],
[0.2,0.2,0.6]])
loss1 = lossf(y1_hat,Y)
loss2 = lossf(y2_hat,Y)
print(loss1.item())
"""
0.4396563470363617
"""
print(loss2.item())
"""
1.2527350187301636
"""
Cross Entropy交叉熵和NLL(Negative Log Likelihood)之间的的关系
Cross Entropy Loss = Log(Softmax) + NLL Loss
对MINIST手写数字数据集进行训练十分类任务
①准备数据集
导包
transforms的详细使用可参考博文:四、Transforms
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F #为了使用relu激活函数
import torch.optim as optim
像素归一化

batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),#把图片变成张量形式
transforms.Normalize((0.1307,),(0.3081,)) #均值和标准差进行数据标准化,这俩值都是经过整个样本集计算过的
])
数据集采用MNIST手写数字数据集
②加载数据集
pytorch提供函数接口可以直接调用下载数据集
train_dataset = datasets.MNIST(root='./',train=True,download=True,transform = transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
test_dataset = datasets.MNIST(root="./",train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)
③模型构建
模型构建框架
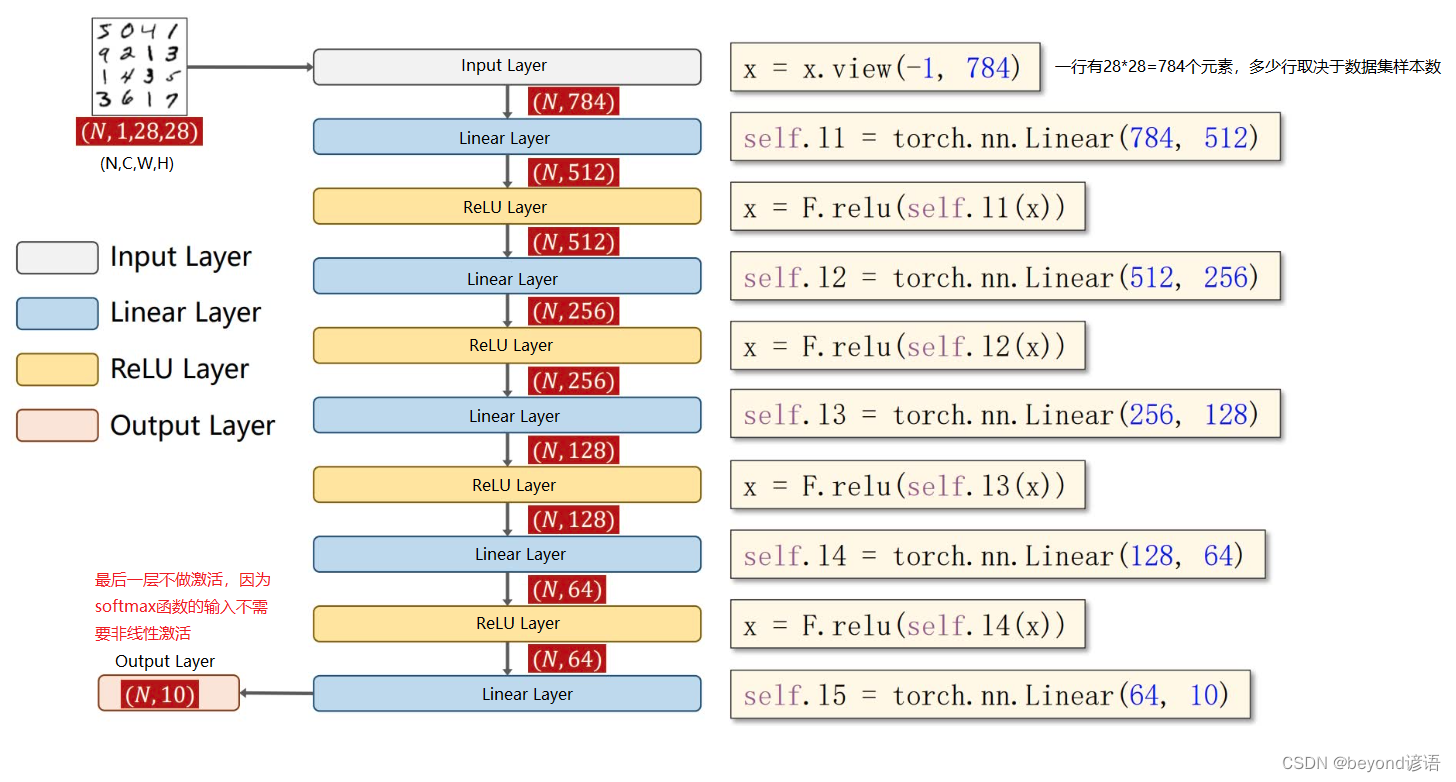
class y_net(torch.nn.Module):
def __init__(self):
super(y_net,self).__init__()
self.l1 = torch.nn.Linear(784,512)
self.l2 = torch.nn.Linear(512,256)
self.l3 = torch.nn.Linear(256,128)
self.l4 = torch.nn.Linear(128,64)
self.l5 = torch.nn.Linear(64,10)
def forward(self,x):
x = x.view(-1,28*28)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = y_net()
④损失函数和优化器
损失函数采用交叉熵损失
优化器采用梯度下降法,因为网络模型有点大,故采用更好的优化算法,使用momentum冲量参数
lossf = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.0001,momentum=0.5)
⑤训练
为了提高效率,把单轮,一个epoch封装成一个函数
def ytrain(epoch):
loss_total = 0.0
for batch_index ,data in enumerate(train_loader,0):
x,y = data
optimizer.zero_grad()
y_hat = model(x)
loss = lossf(y_hat,y)
loss.backward()
optimizer.step()
loss_total += loss.item()
if batch_index % 300 == 299:# 每300epoch输出一次
print("epoch:%d, batch_index:%5d \t loss:%.3f"%(epoch+1, batch_index+1, loss_total/300))
loss_total = 0.0#每次epoch都将损失清除
⑥测试
def ytest():
correct = 0#模型预测正确的数量
total = 0#样本总数
with torch.no_grad():#测试不需要梯度,减小计算量
for data in test_loader:#读取测试样本数据
images, labels = data
pred = model(images)#预测,每一个样本占一行,每行有十个值,后续需要求每一行中最大值所对应的下标
pred_maxvalue, pred_maxindex = torch.max(pred.data,dim=1)#沿着第一个维度,一行一行来,去找每行中的最大值,返回每行的最大值和所对应下标
total += labels.size(0)#labels是一个(N,1)的向量,对应每个样本的正确答案
correct += (pred_maxindex == labels).sum().item()#使用预测得到的最大值的索引和正确答案labels进行比较,一致就是1,不一致就是0
print("Accuracy on testset :%d %%"%(100*correct / total))#correct预测正确的样本个数 / 样本总数 * 100 = 模型预测正确率
⑦主程序运行训练和测试
if __name__ == '__main__':
for epoch in range(10):#训练10次
ytrain(epoch)#训练一次
if epoch%10 == 9:
ytest()#训练10次,测试1次
⑧完整代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F #为了使用relu激活函数
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),#把图片变成张量形式
transforms.Normalize((0.1307,),(0.3081,)) #均值和标准差进行数据标准化,这俩值都是经过整个样本集计算过的
])
train_dataset = datasets.MNIST(root='./',train=True,download=True,transform = transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
test_dataset = datasets.MNIST(root="./",train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)
class y_net(torch.nn.Module):
def __init__(self):
super(y_net,self).__init__()
self.l1 = torch.nn.Linear(784,512)
self.l2 = torch.nn.Linear(512,256)
self.l3 = torch.nn.Linear(256,128)
self.l4 = torch.nn.Linear(128,64)
self.l5 = torch.nn.Linear(64,10)
def forward(self,x):
x = x.view(-1,28*28)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = y_net()
lossf = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.0001,momentum=0.5)
def ytrain(epoch):
loss_total = 0.0
for batch_index ,data in enumerate(train_loader,0):
x,y = data
optimizer.zero_grad()
y_hat = model(x)
loss = lossf(y_hat,y)
loss.backward()
optimizer.step()
loss_total += loss.item()
if batch_index % 300 == 299:# 每300epoch输出一次
print("epoch:%d, batch_index:%5d \t loss:%.3f"%(epoch+1, batch_index+1, loss_total/300))
loss_total = 0.0 #每个epoch都将损失清除
def ytest():
correct = 0#模型预测正确的数量
total = 0#样本总数
with torch.no_grad():#测试不需要梯度,减小计算量
for data in test_loader:#读取测试样本数据
images, labels = data
pred = model(images)#预测,每一个样本占一行,每行有十个值,后续需要求每一行中最大值所对应的下标
pred_maxvalue, pred_maxindex = torch.max(pred.data,dim=1)#沿着第一个维度,一行一行来,去找每行中的最大值,返回每行的最大值和所对应下标
total += labels.size(0)#labels是一个(N,1)的向量,对应每个样本的正确答案
correct += (pred_maxindex == labels).sum().item()#使用预测得到的最大值的索引和正确答案labels进行比较,一致就是1,不一致就是0
print("Accuracy on testset :%d %%"%(100*correct / total))#correct预测正确的样本个数 / 样本总数 * 100 = 模型预测正确率
if __name__ == '__main__':
for epoch in range(10):#训练10次
ytrain(epoch)#训练一次
if epoch%10 == 9:
ytest()#训练10次,测试1次