
大数据时代
当前时代是数据爆炸的时代,全球各个网站、电子设备等都在源源不断地产生着大量数据.2006年数字世界项目统计得出全球数据总量为0.18ZB,2011年全球数据量1.8ZB,2013全球数据量4.4ZB,2014年全球数据总量在6.2ZB左右,2015年全球数据总量在8.6ZB左右,2016年12ZB左右,2020年的时候,全球的数据总量将达到40ZB。(小编的印象里,高中时用的手机内存卡是512M,当时就感觉已经很牛逼了,现在16G、32G都感觉不够用~)
1KB=1024B
1MB=1024KB
1GB=1024MB
1TB=1024GB
1PB=1024TB
1EB=1024PB
1ZB=1024EB
1YB=1024ZB
1BB=1024YB
1NB=1024BB
1DB=1024NB
1CB=1024DB
1XB=1024CB
Hadoop初识
随着数据量的急剧增加,遇到的两个最直接的问题就是数据存储和计算(分析/利用)。
Hadoop是一个用Java实现的分布式基础框架,也可以看做是一个支持开发、运行由通用计算设备组成的大型集群上的分布式应用的平台。Hadoop中的两个最重要的组件—HDFS和MapReduce就是用来解决海量数据(分布式)存储、海量数据(分布式)计算的。
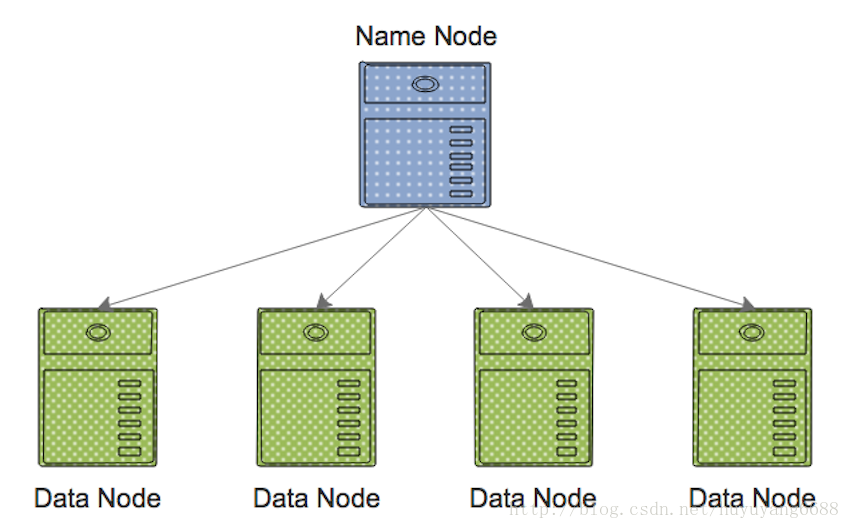
HDFS(HadoopDistributedFileSystem):Hadoop分布式文件存储系统,可以利用多台价格低廉的机器,分布式存储海量的数据。HDFS有两种节点,NameNode和DataNode。DataNode主要用来存储数据,NameNode管理着整个文件系统的交互。相对于普通的文件系统,HDFS显著的特点是分布式海量存储、备份机制。
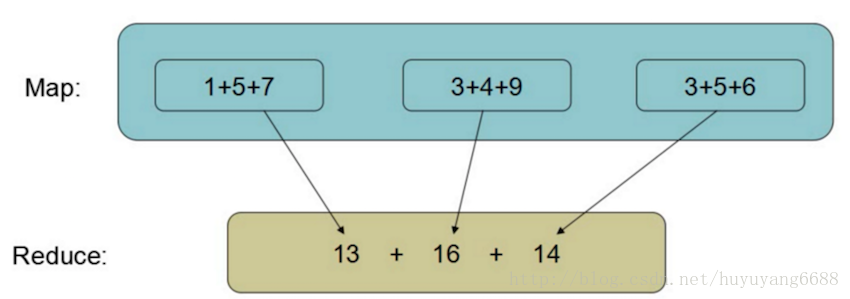
MapReduce:并行计算框架,MapReduce其实是一种分布式计算模型,多个计算机并行计算,共同做一件事情。
用一个简单的例子来说明MapReduce,比如要做如下公式的求和结果,当涉及到的计算量比较大时,可以把任务拆分成几个部分,每个部分分别有一台计算机处理,然后每台计算机处理的结果再进行汇总。
Hadoop应用场景
简单认识了什么是Hadoop,再来了解一下Hadoop一般都适用于哪些场景。
Hadoop主要应用于大数据量的离线场景,特点是大数据量、离线。
1、数据量大:一般真正线上用Hadoop的,集群规模都在上百台到几千台的机器。这种情况下,T级别的数据也是很小的。
2、离线:Mapreduce框架下,很难处理实时计算,作业都以日志分析这样的线下作业为主。另外,集群中一般都会有大量作业等待被调度,保证资源充分利用。
(参考:https://www.zhihu.com/question/20565951/answer/35172719)
另外,由于HDFS设计的特点,Hadoop适合处理文件块大的文件。大量的小文件使用Hadoop来处理效率会很低。
Hadoop常用的场景有:
●大数据量存储:分布式存储(各种云盘,百度,360~还有云平台均有hadoop应用)
●日志处理
●海量计算,并行计算
●数据挖掘(比如广告推荐等)
●行为分析,用户建模等
……