HDFS(HadoopDistributedFileSystem):Hadoop分布式文件存储系统。
分布式文件存储系统
分布式文件存储系统是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。常见的分布式文件系统有,GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS等,各用于不同的领域。
HDFS是一个主从结构,一个HDFS集群是由一个名字节点,它是一个管理文件命名空间和调节客户端访问文件的主服务器,当然还有一些数据节点,通常是一个节点一个机器,它来管理对应节点的存储。HDFS对外开放文件命名空间并允许用户数据以文件形式存储。
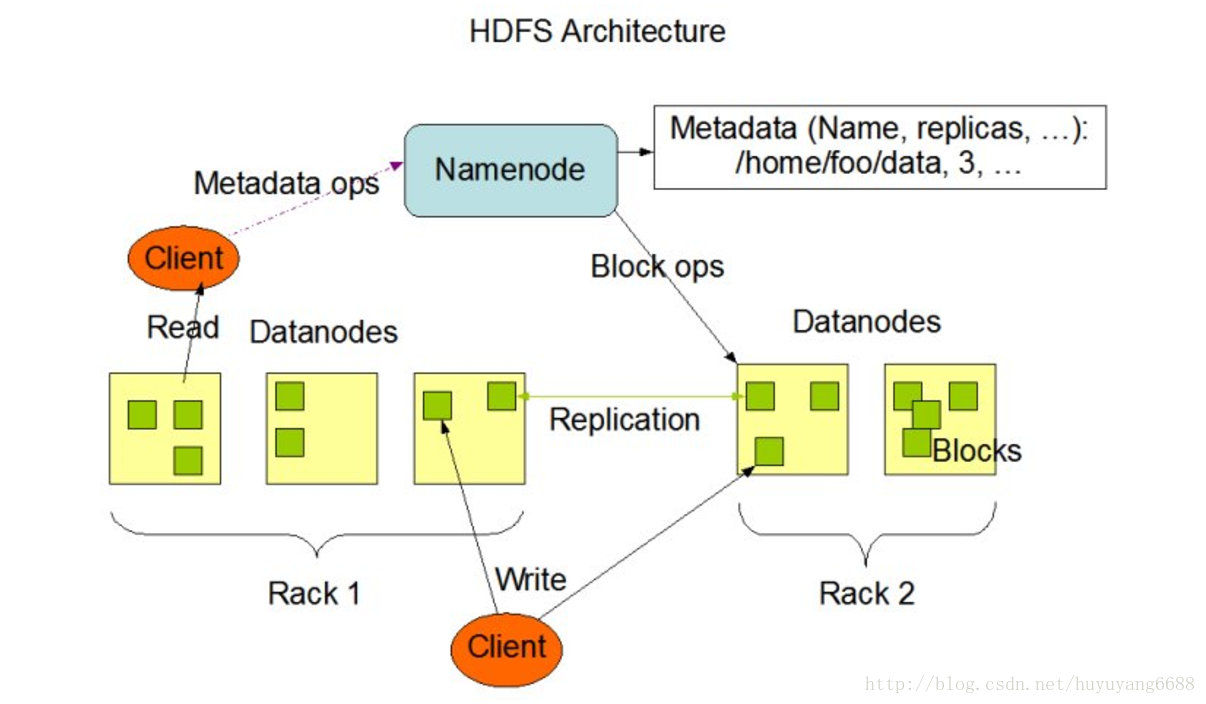
内部机制是将一个文件分割成一个或多个块,这些块被存储在一组数据节点中。名字节点用来操作文件命名空间的文件或目录操作,如打开,关闭,重命名等等。它同时确定块与数据节点的映射。数据节点负责来自文件系统客户的读写请求。数据节点同时还要执行块的创建,删除,和来自名字节点的块复制指令。
名字节点和数据节点都是运行在普通的机器之上的软件,机器典型的都是GNU/Linux,HDFS是用java编写的,任何支持java的机器都可以运行名字节点或数据节点,利用java语言的超轻便型,很容易将HDFS部署到大范围的机器上。典型的部署是由一个专门的机器来运行名字节点软件,集群中的其他每台机器运行一个数据节点实例。体系结构不排斥在一个机器上运行多个数据节点的实例,但是实际的部署不会有这种情况。
集群中只有一个名字节点极大地简单化了系统的体系结构。名字节点是仲裁者和所有HDFS元数据的仓库,用户的实际数据不经过名字节点。