三、高级Hadoop 2.X
1. 分布式部署Hadoop2.x概述讲解
Hadoop 2.x 部署
*Local Mode
*Distributed Mode
*伪分布式
一台机器,运行所有的守护进程,
从节点DataNode、NodeManager
*完全分布式
有多个从节点
DataNodes
NodeManagers
配置文件
$HADOOP_HOME/etc/hadoop/slaves
2. 克隆虚拟机需要修改的配置
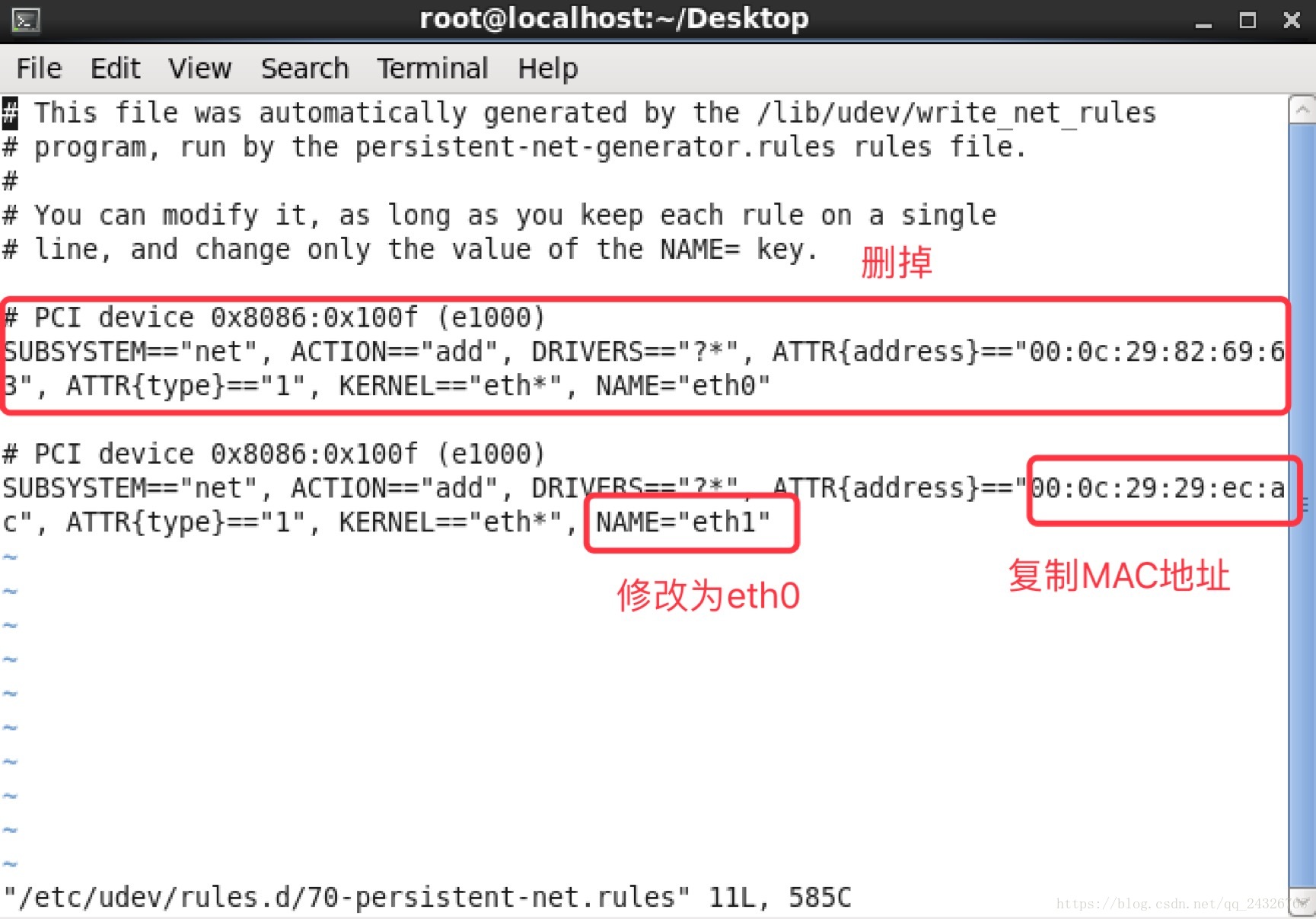
① 修改网卡名称(可改可不改)
[root@localhost Desktop]# vi /etc/udev/rules.d/70-persistent-net.rules
② 修改IP和MAC地址
[root@hadoop-senior ~]# vi/etc/sysconfig/network-scripts/ifcfg-eth0
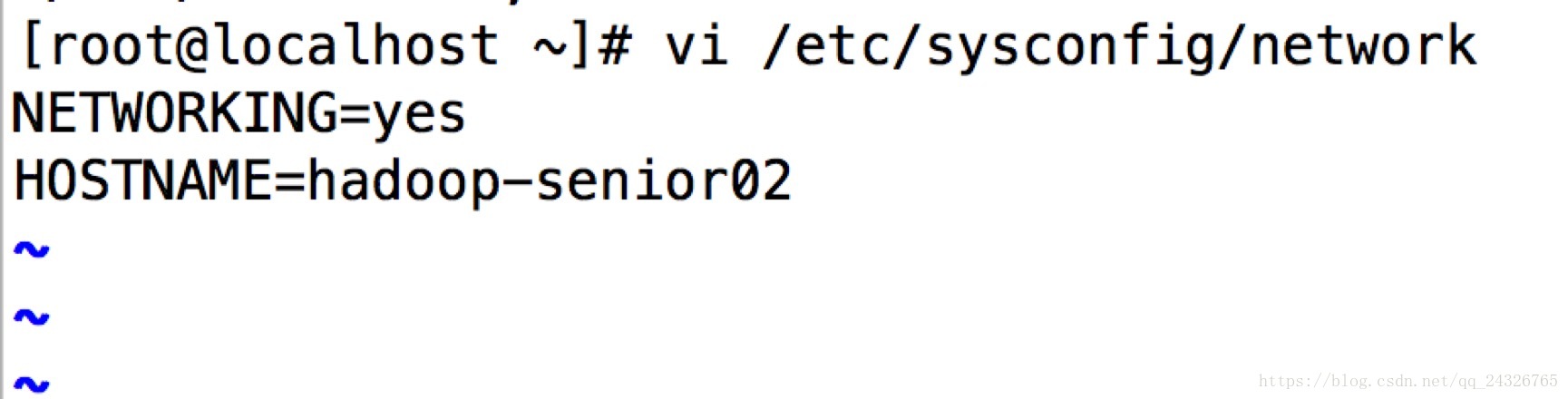
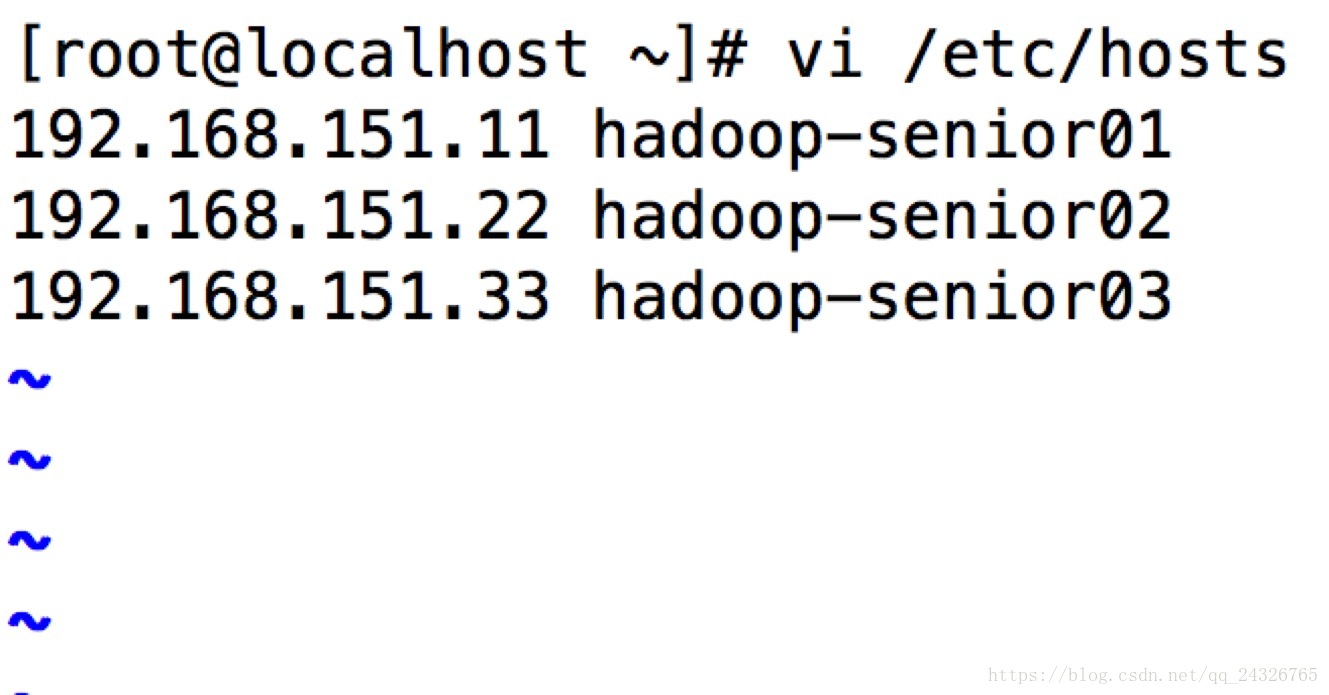
③ 修改主机名和映射
④ 可以把子节点上不需要的软件删除。
例如:hadoop只需要主节点安装,子节点就可以删除。
3. HDFS、YARN、MapReduce的部署位置
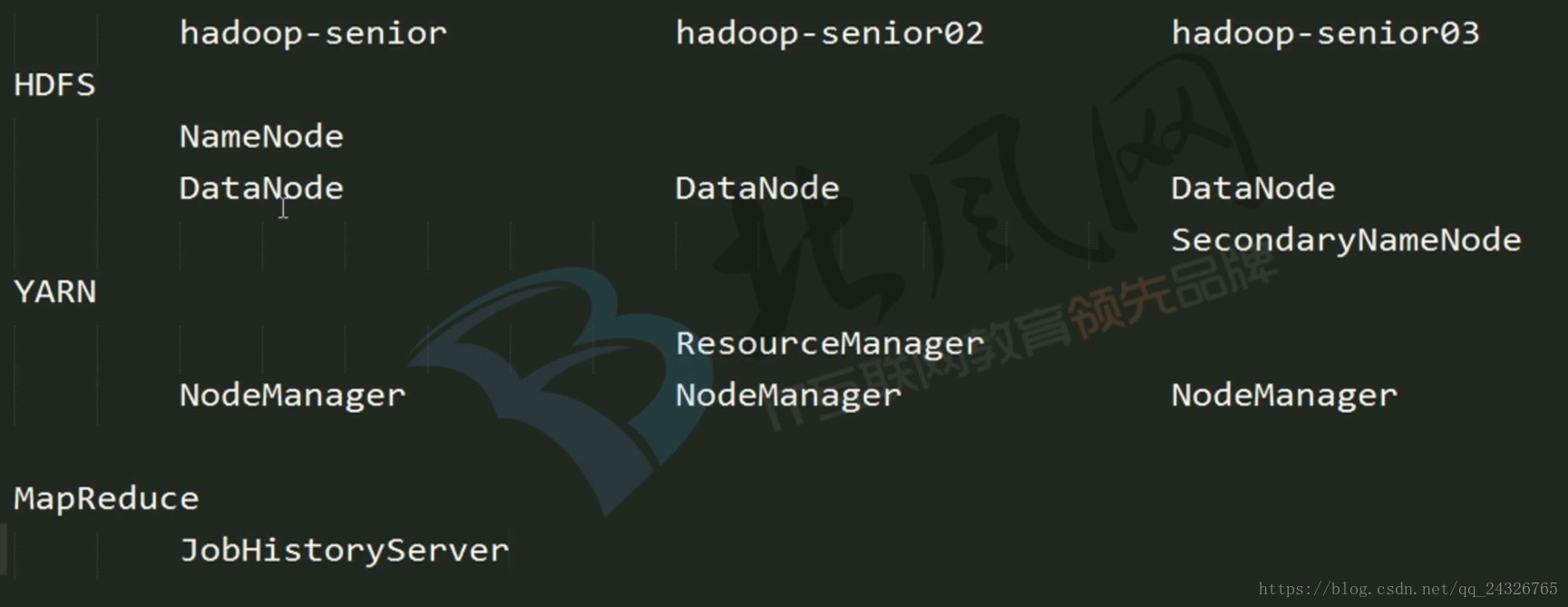
ResourceManager不要和NameNode、SecondaryNameNode放在同一个节点上,为了避免该节点出问题,整个集群挂掉。
4. 集群搭建
① 需要修改的配置文件:
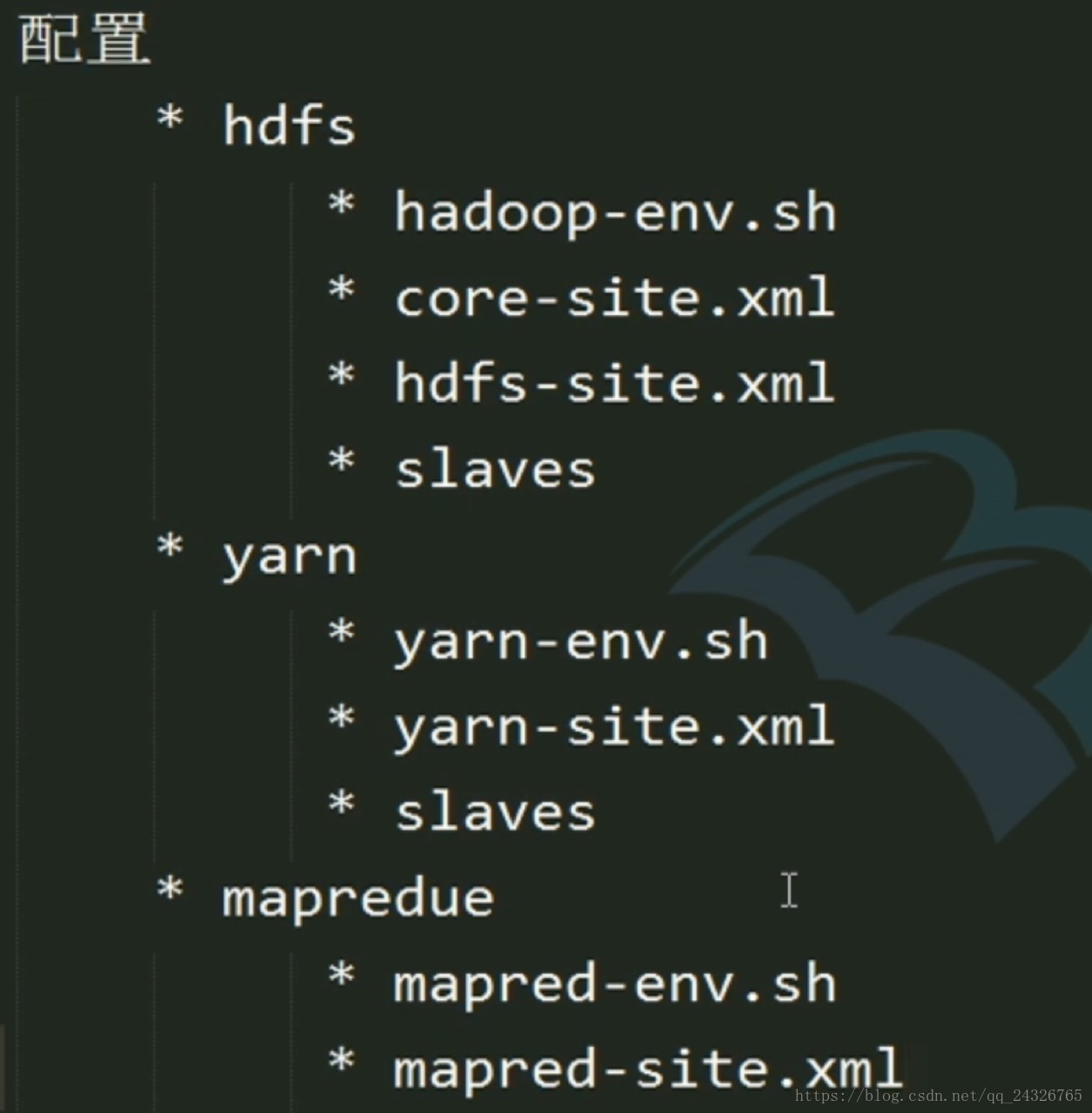
HDFS:
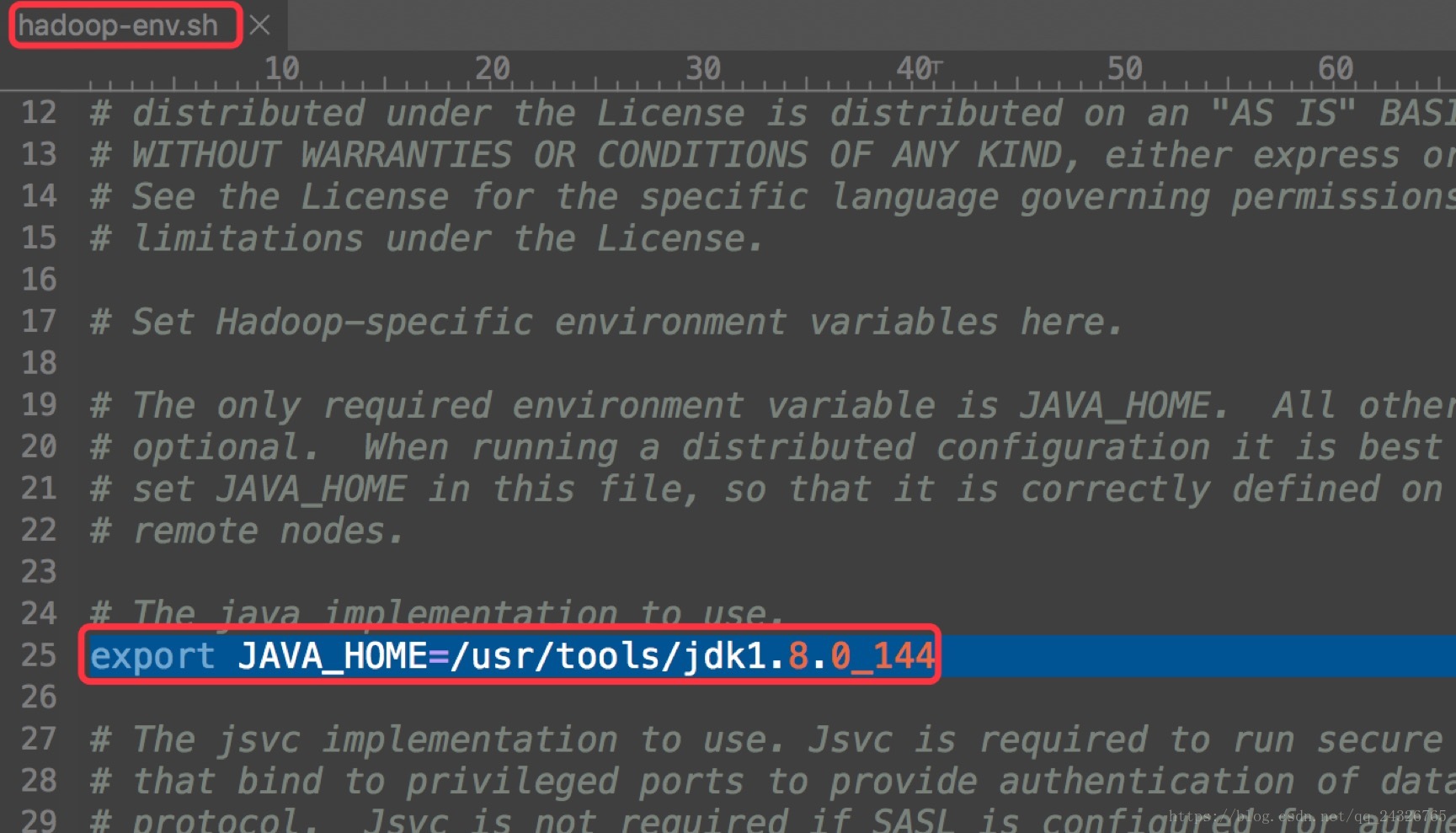
hadoop-env.sh
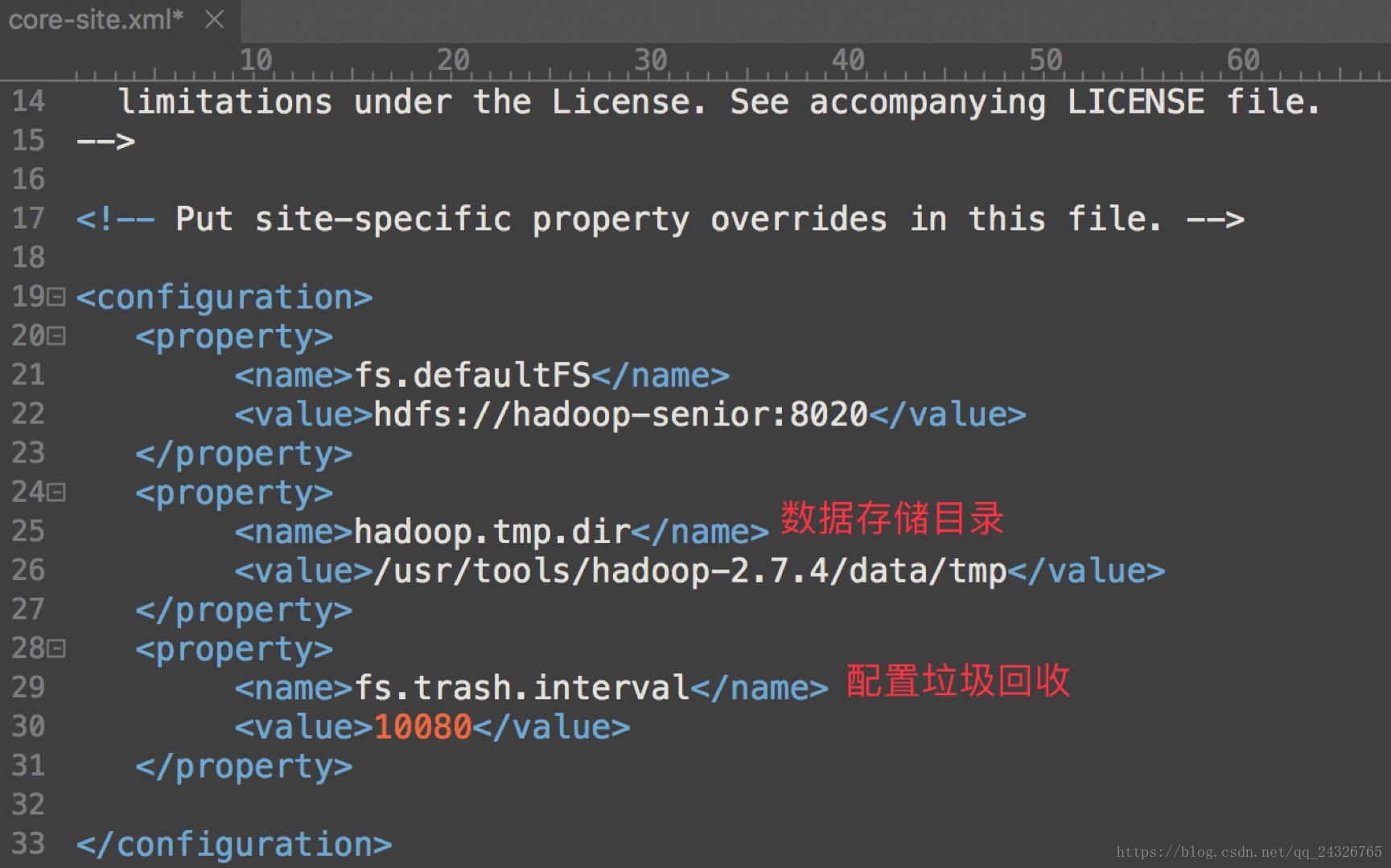
core-site.xml
hdfs-site.xml
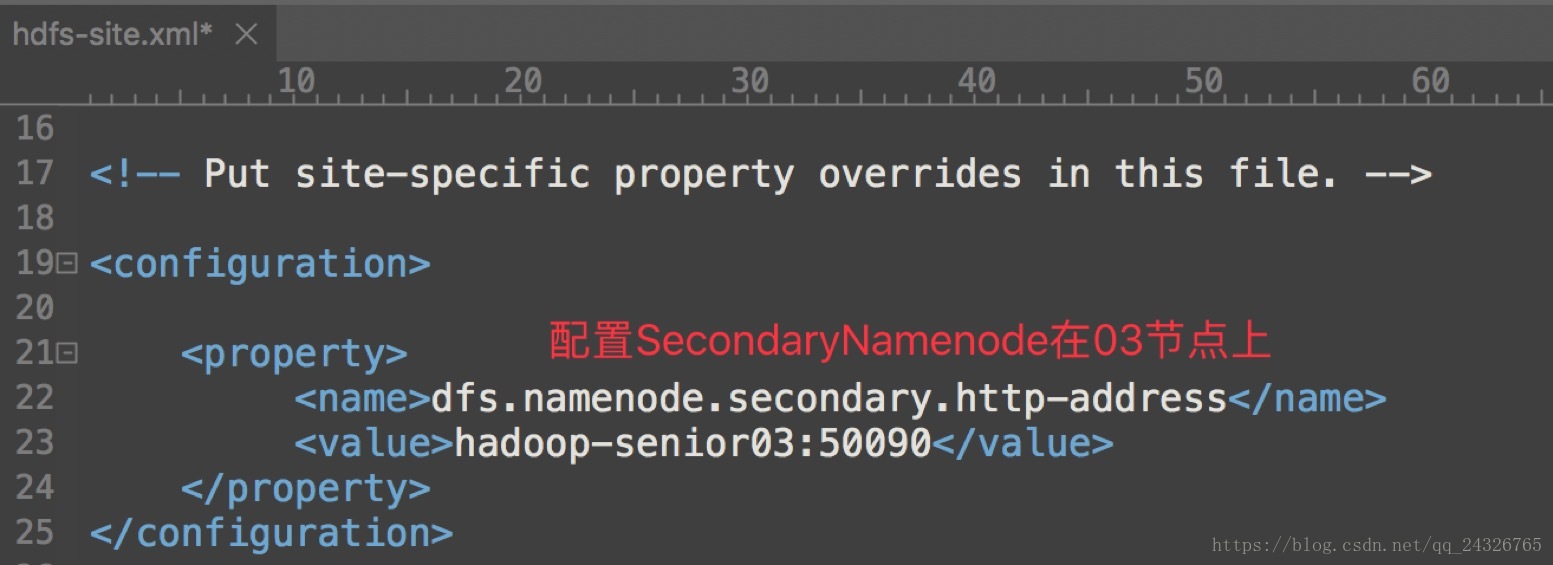
slavers
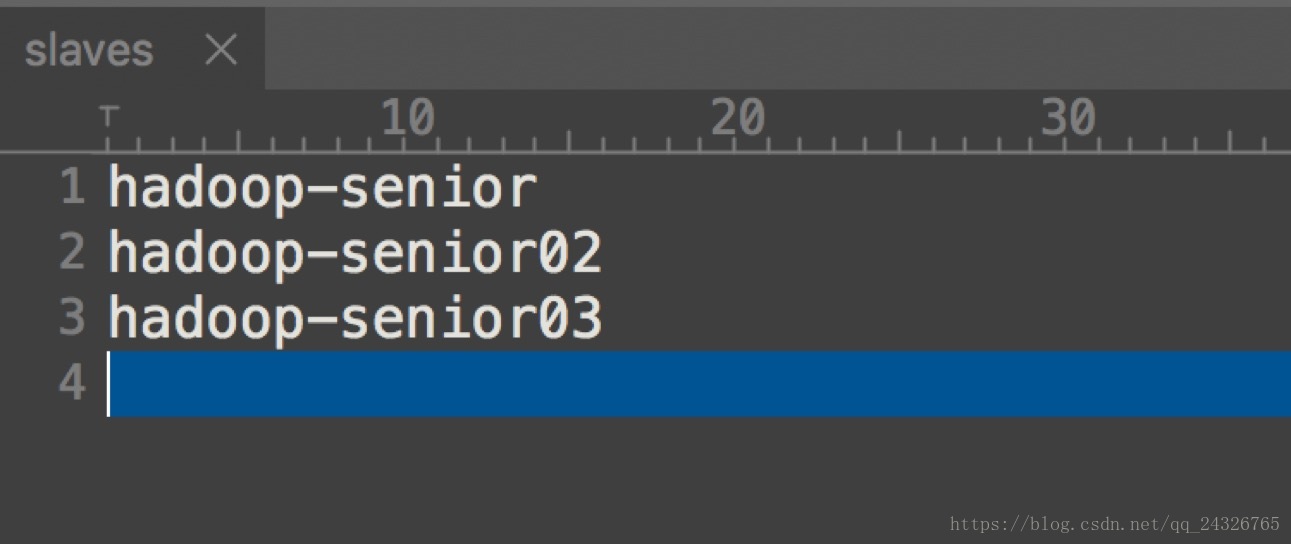
配置datanode和nodemanager
YARN:
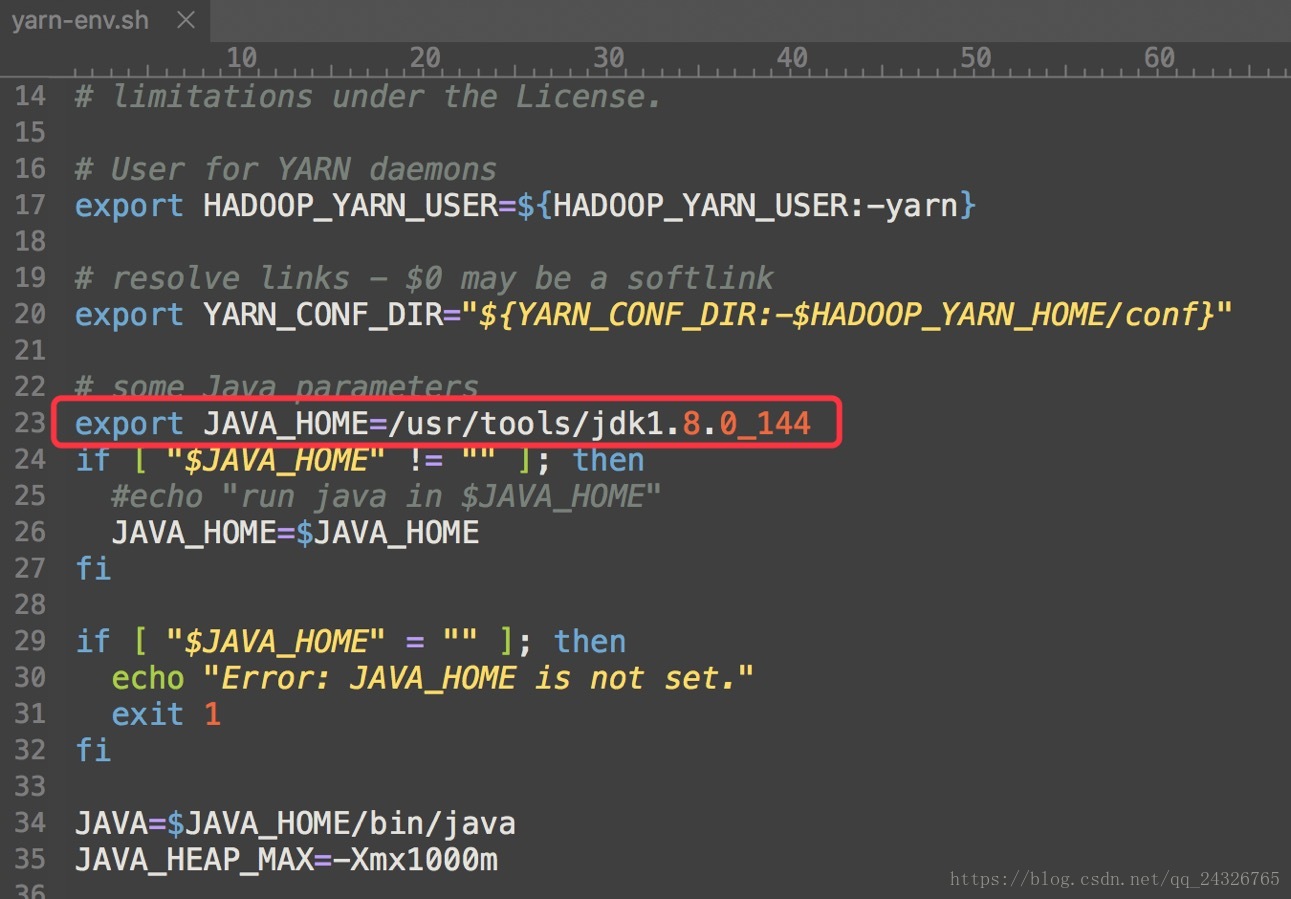
yarn-env.sh
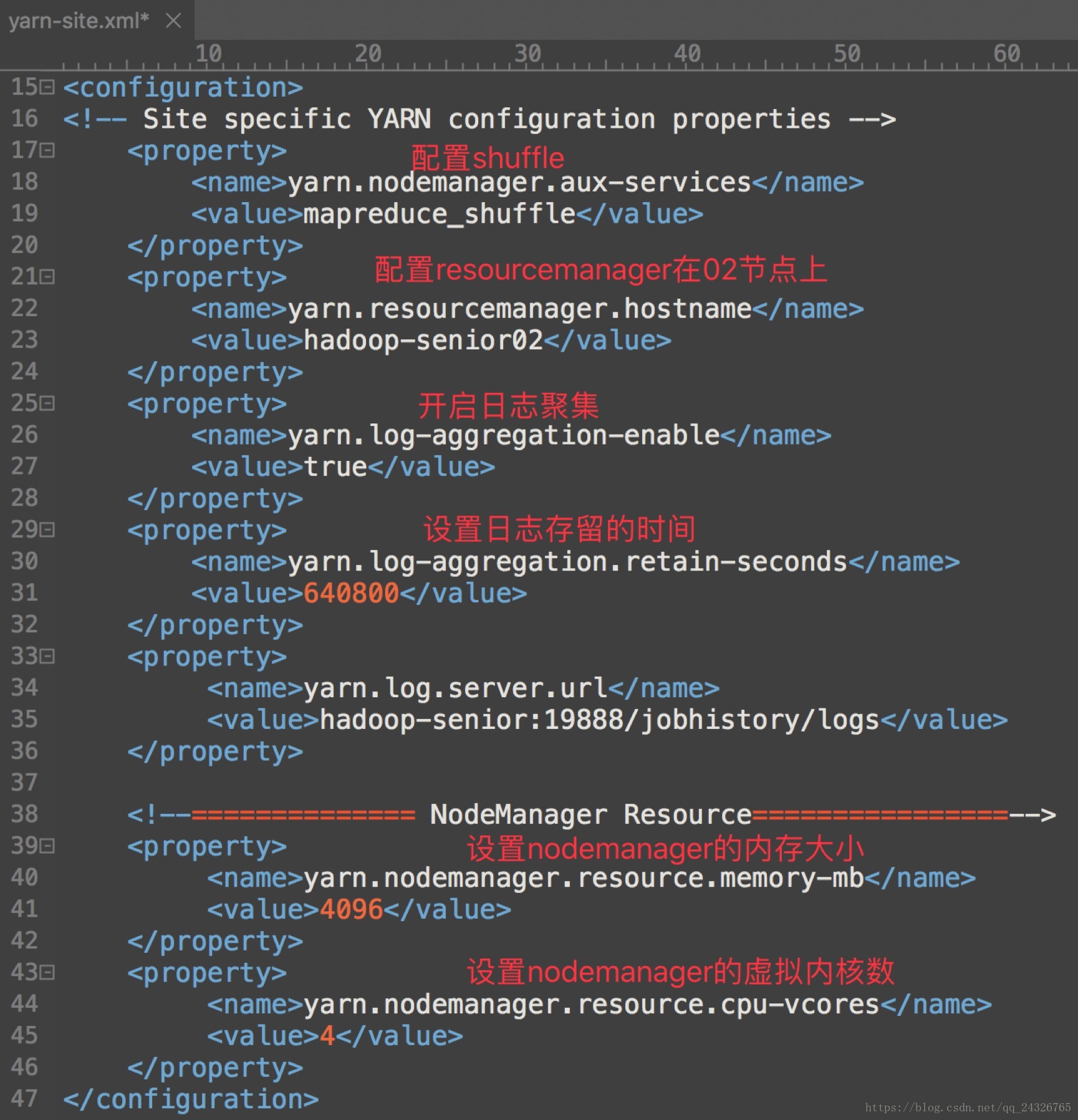
yarn-site.xml
MapReduce:
marped-env.sh
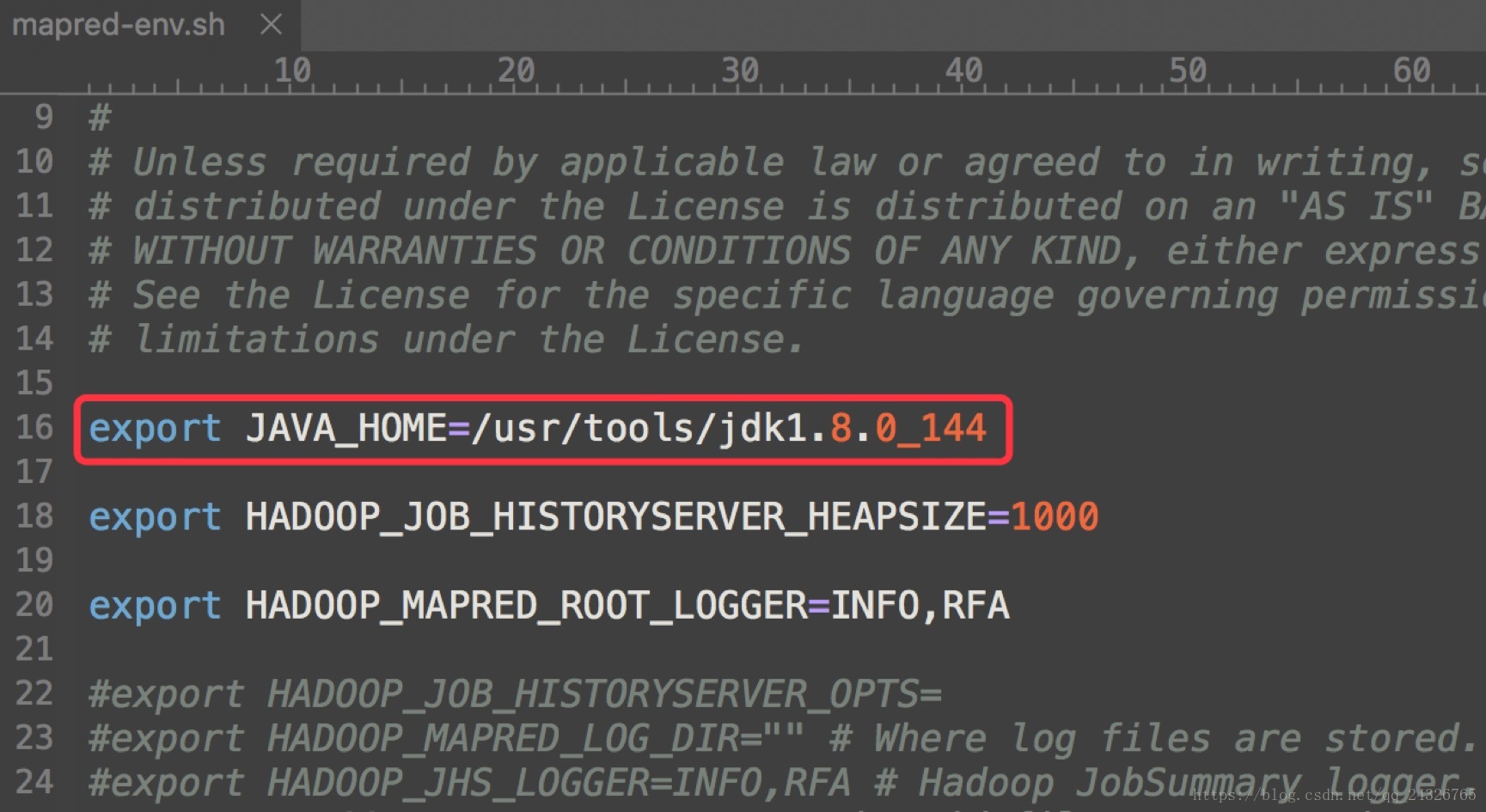
marped-site.xml
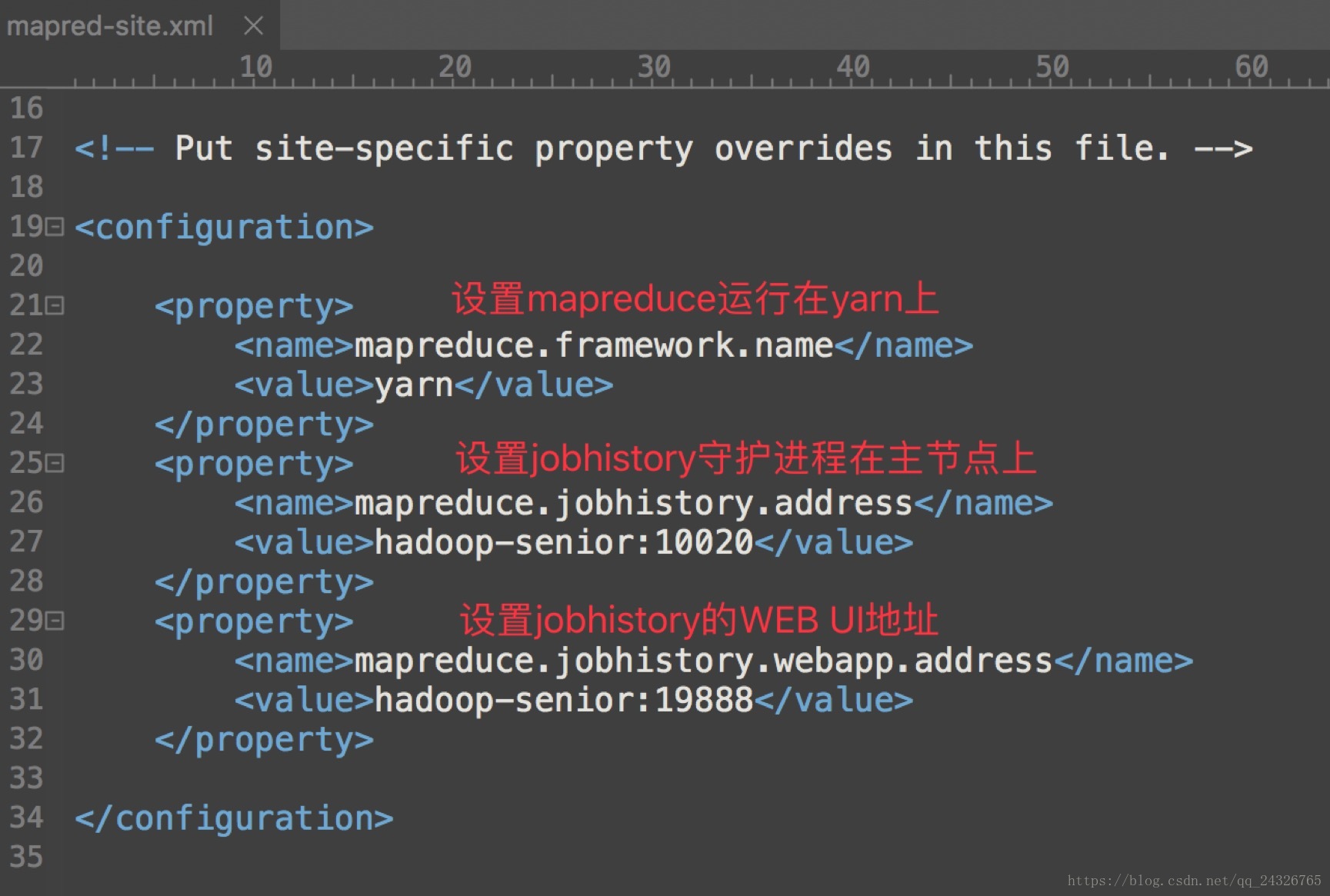
② 分发:
因为hadoop下的doc文件夹所占空间较,且不常用,可将其删除再往其他节点分发

进行分发:
scp -r /usr/opt/modules/hadoop-2.7.4/root@hadoop-senior02:/usr/opt/modules/
scp -r /usr/opt/modules/hadoop-2.7.4/root@hadoop-senior03:/usr/opt/modules/
(前提:设置SSH免密码登录)
③ 格式化
在namenode所在的节点上(hadoop-senior):
bin/hdfs namenode –format
如果报错:
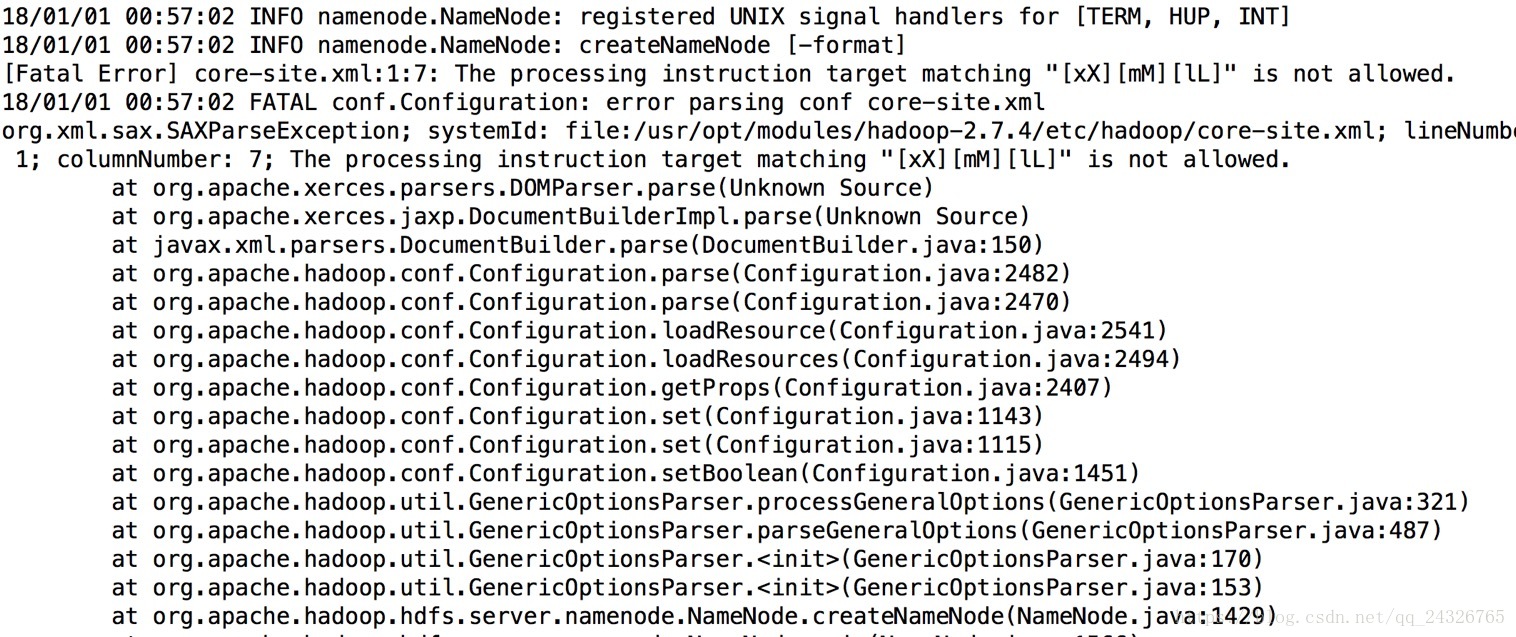
原因:没有创建下图文件夹

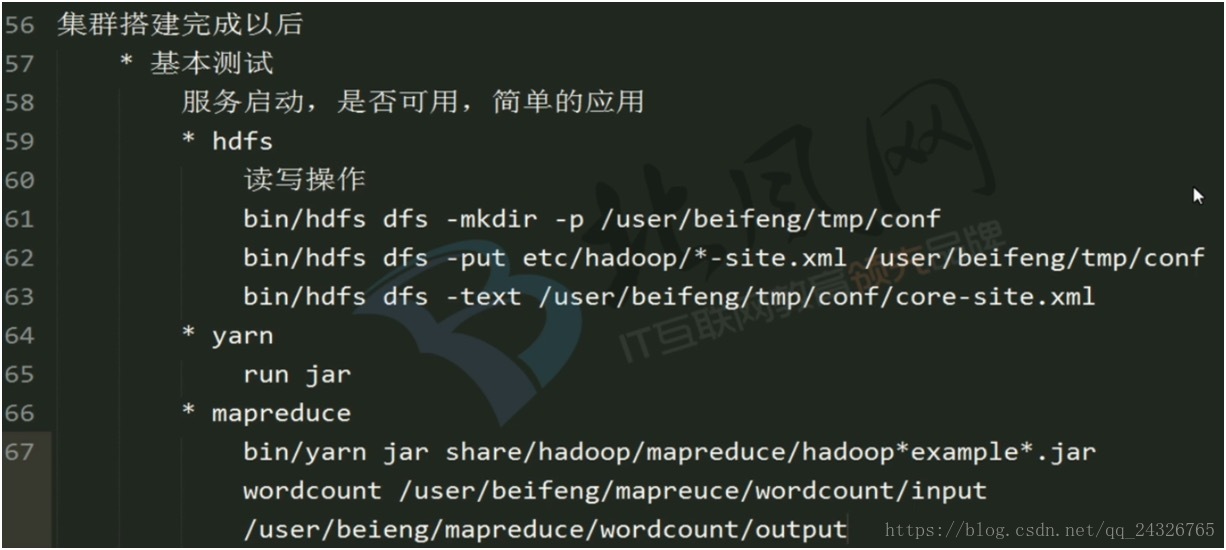
④ 基本测试及监控
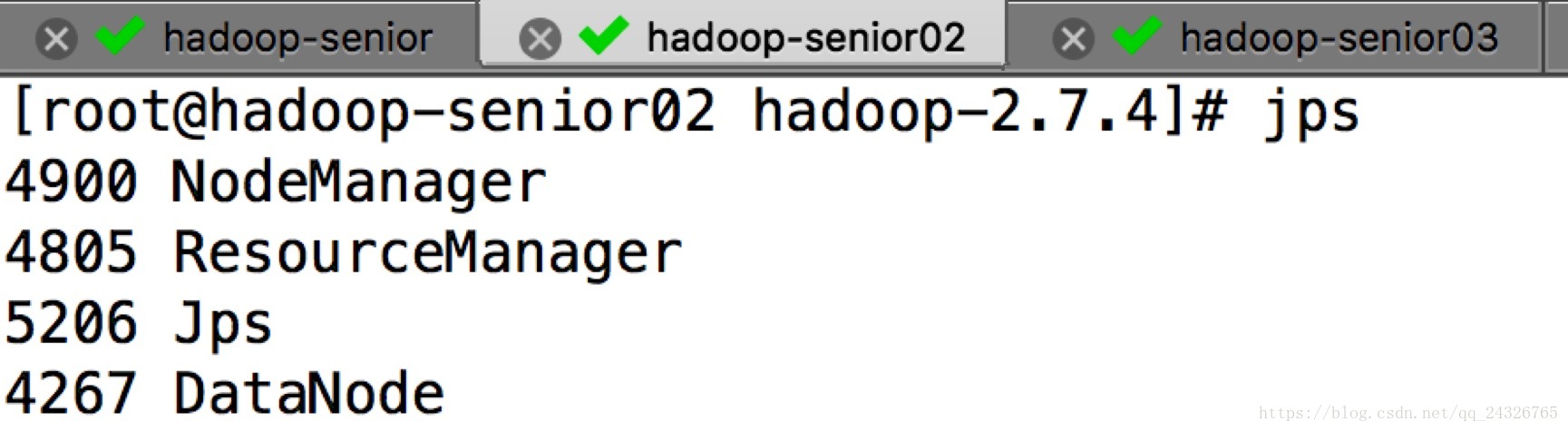
启动hdfs:
sbin/start-dfs.sh(在namenode所在节点)
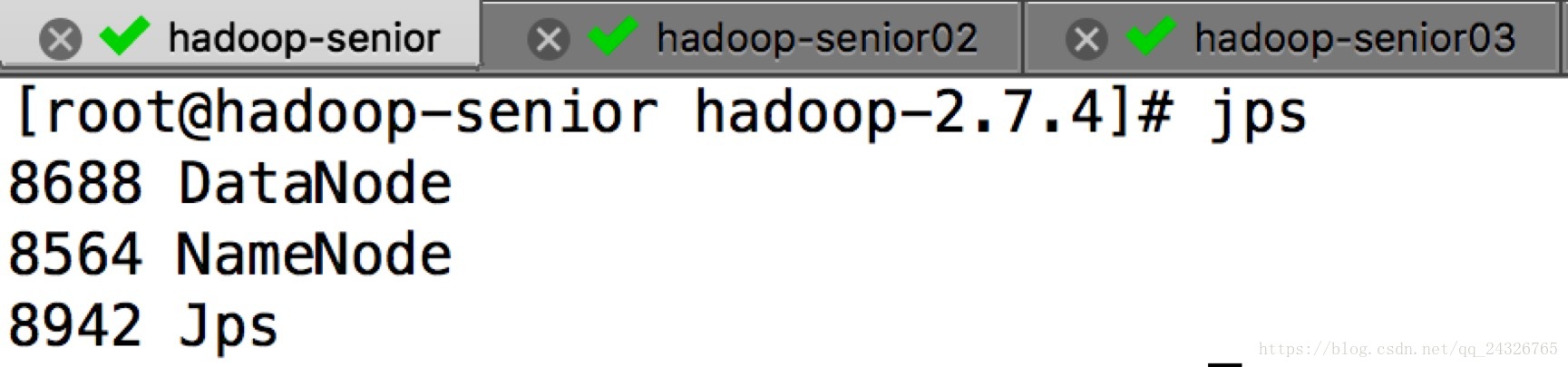

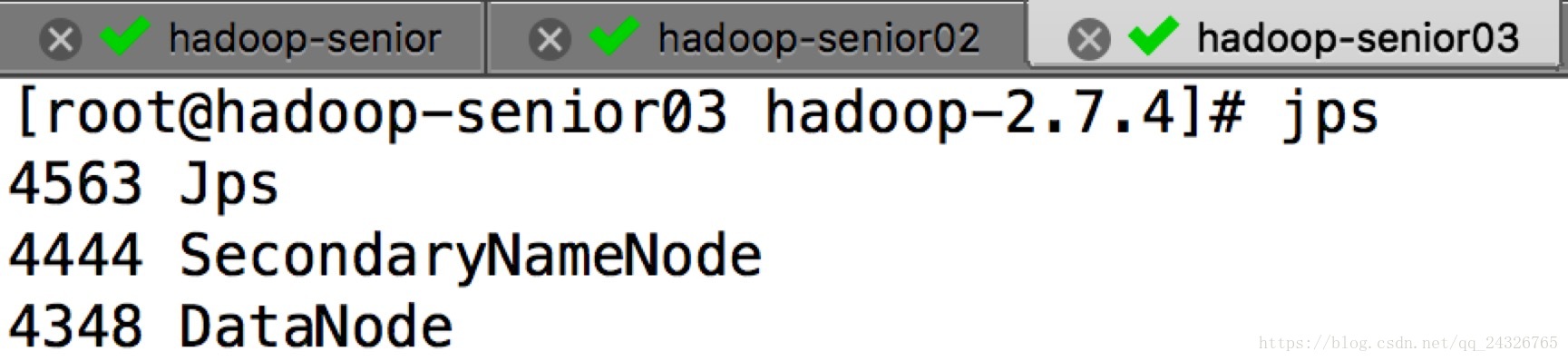
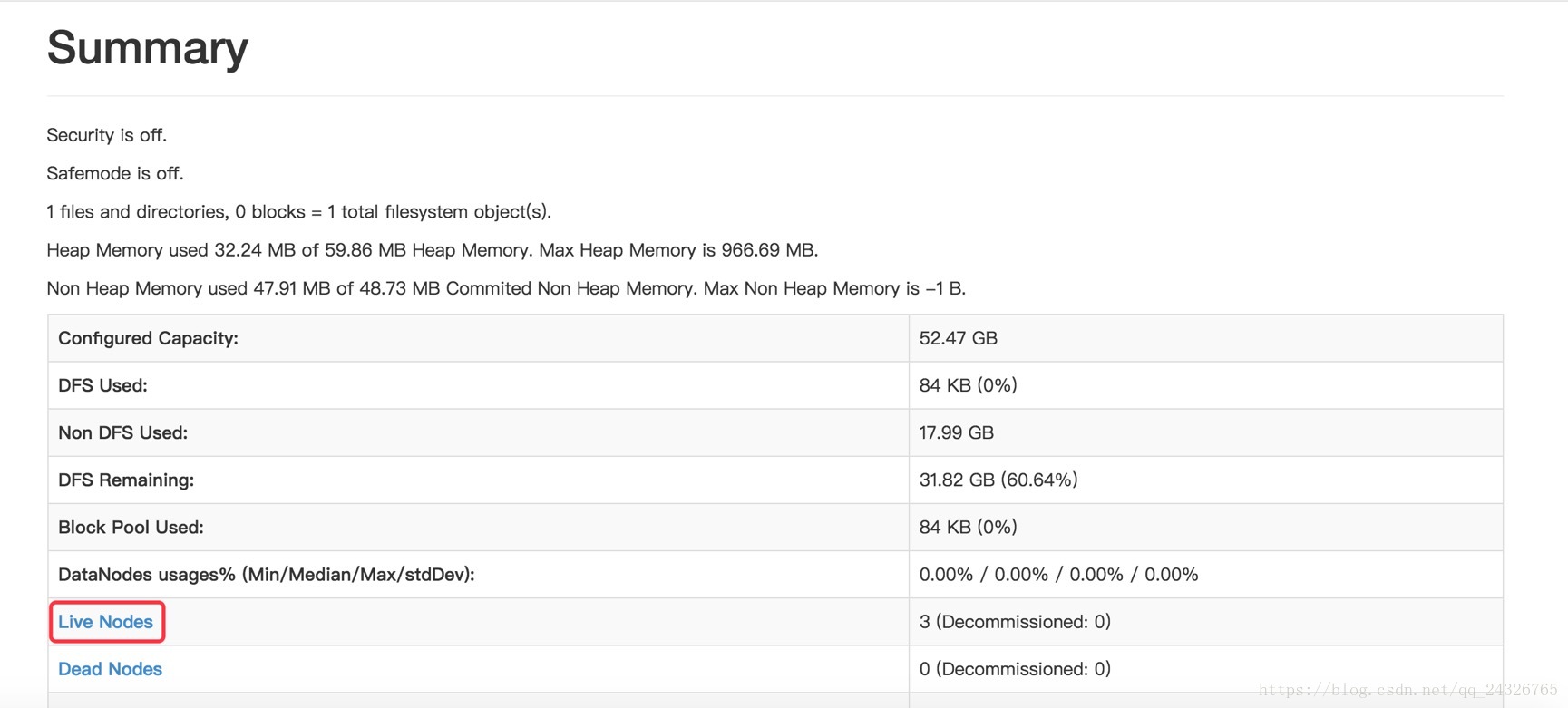
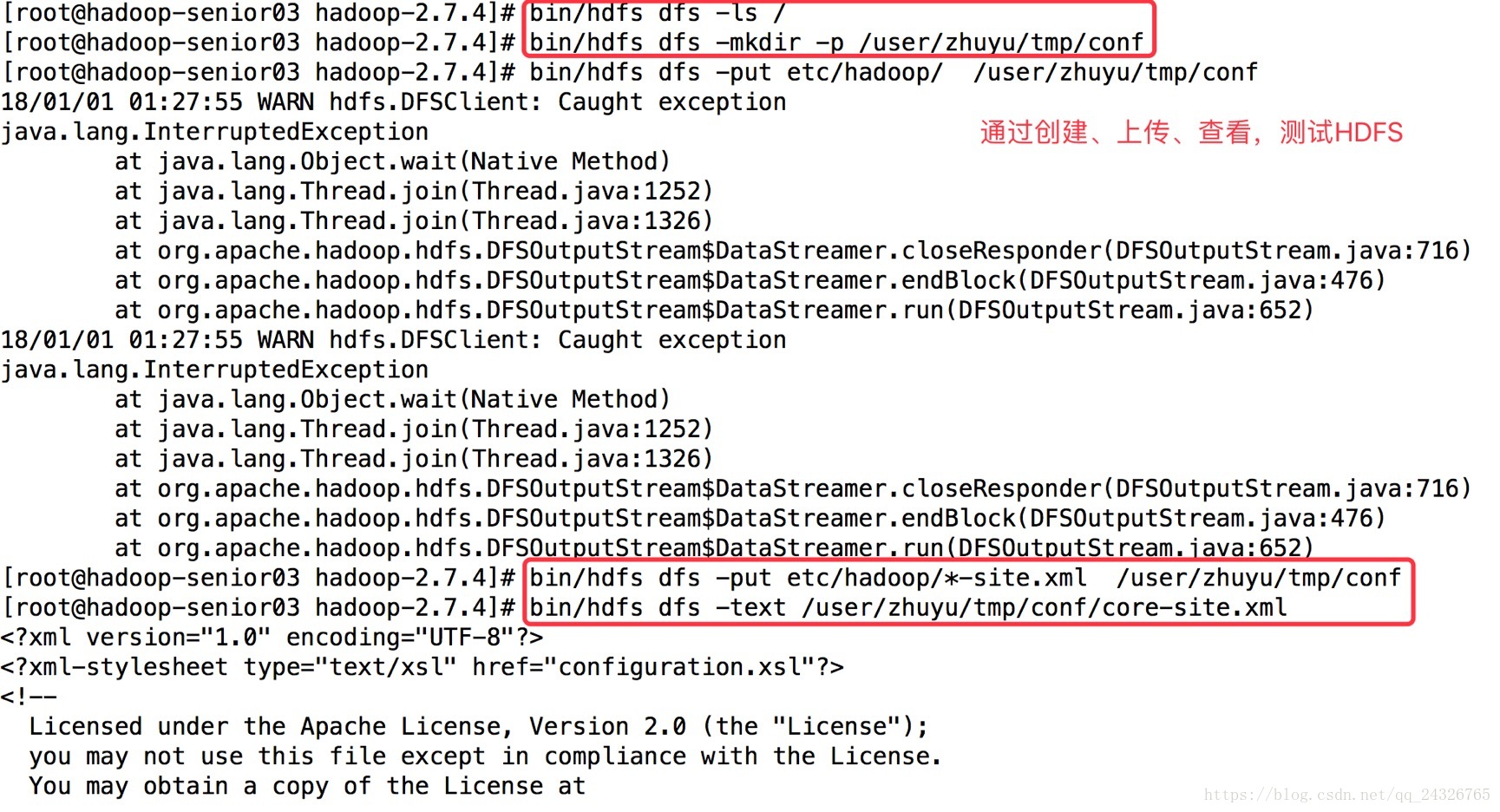
测试:
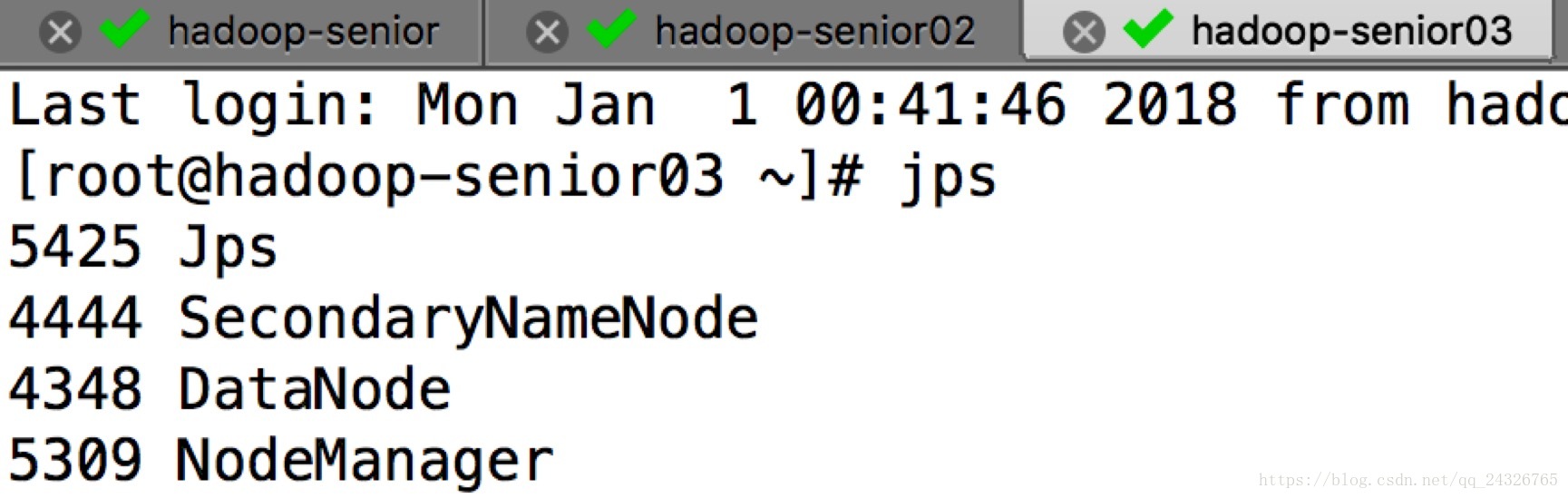
启动yarn:
sbin/start-yarn.sh(在resourcemanager所在节点)
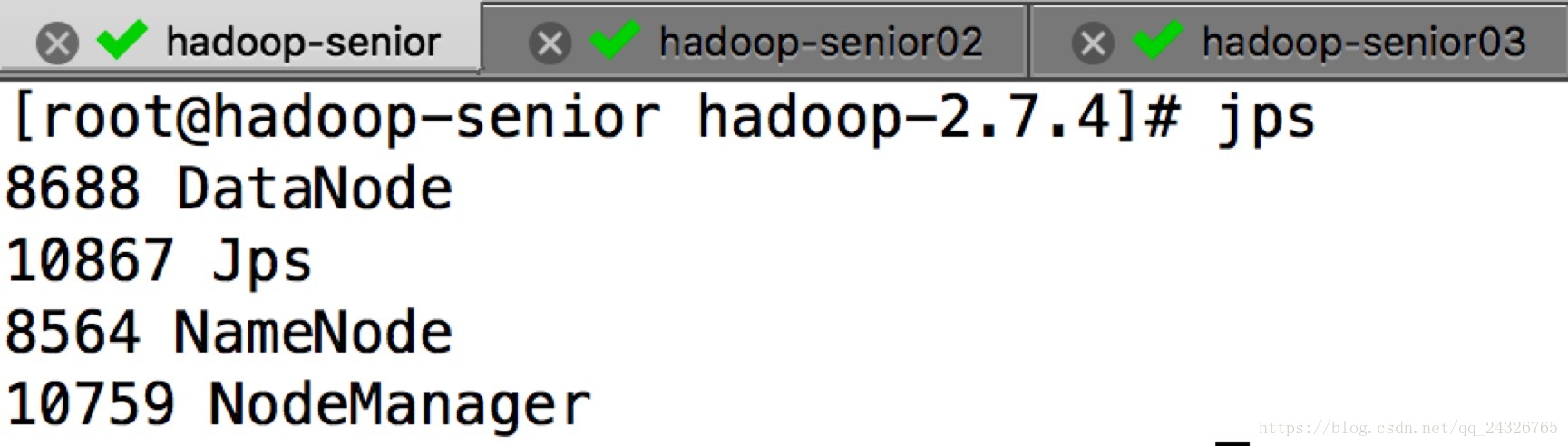
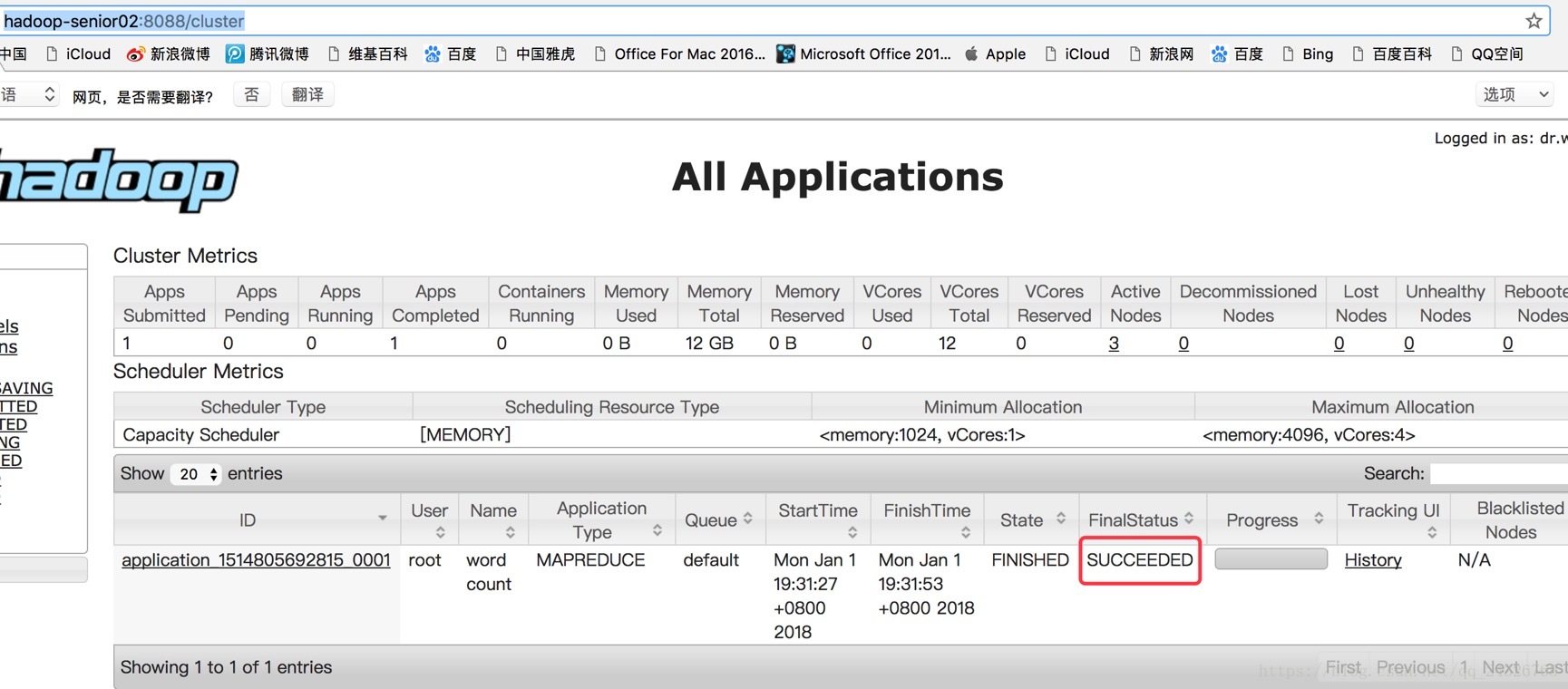
测试:
运行wordcount在yarn上

查看运行情况:
http://hadoop-senior02:8088/cluster
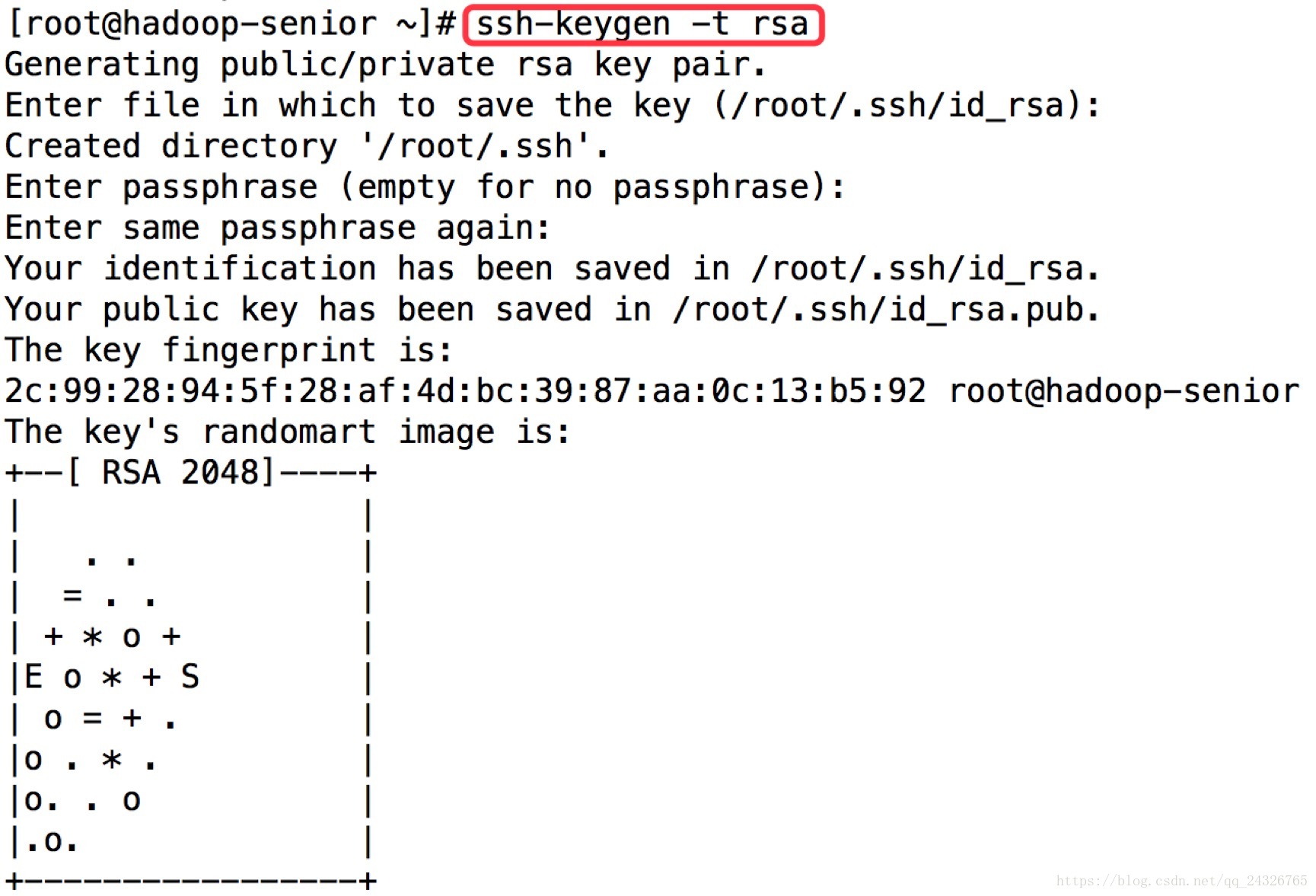
5.配置Hadoop 2.x中主节点(NN和RM)到从节点的SSH无密码登录
① 生成rsa密钥
② 设置主节点与子节点的SSH无密码登录
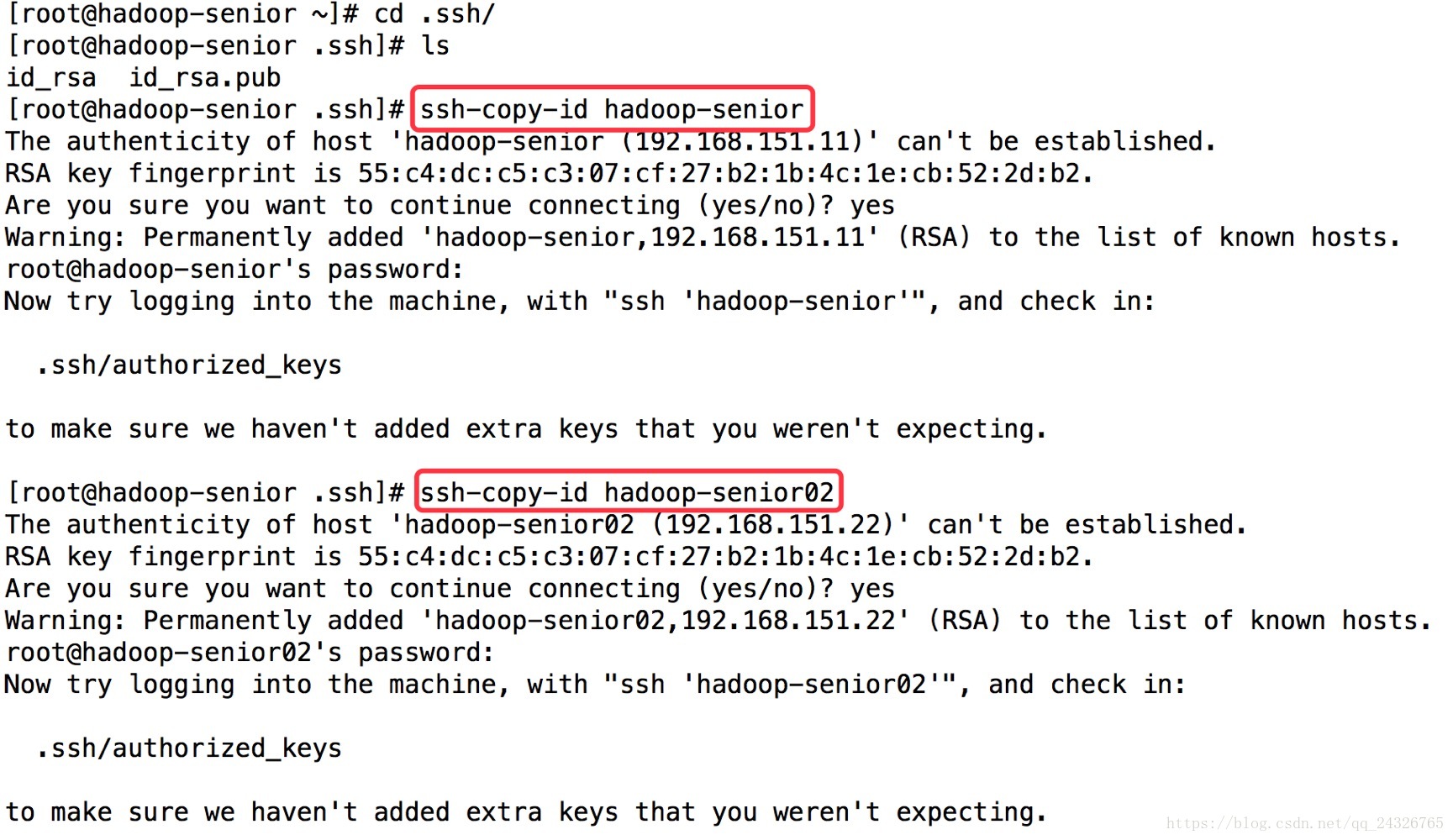
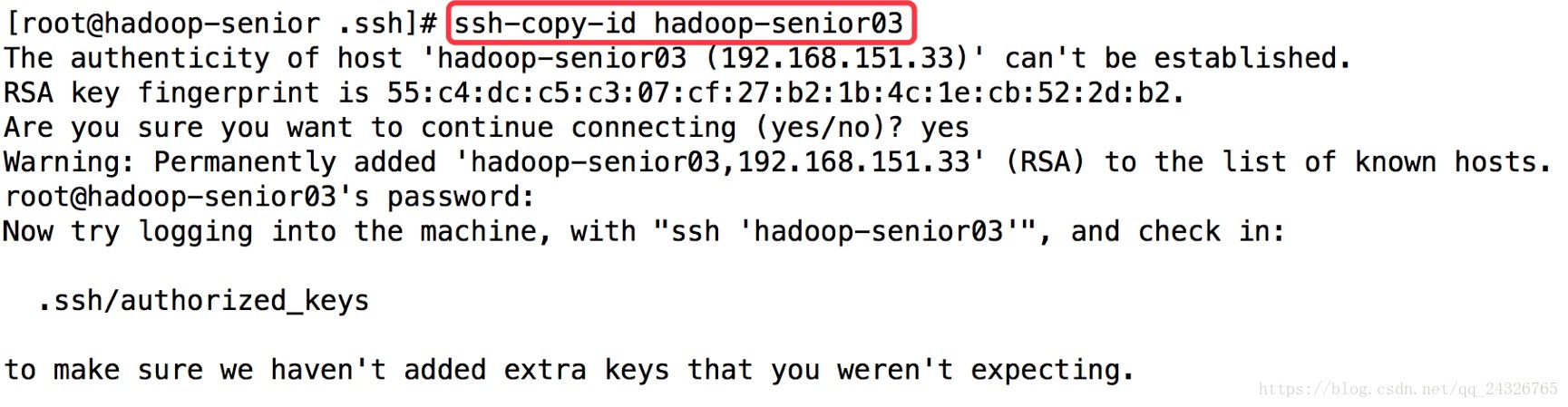
注意:本机的也要设置一下,即ssh-copy-id hadoop-senior
③ 每个节点的设置同①②
注意:重新生成rsa的话之前配置的ssh要重新设置;不是每个节点都要设置SSH,namenode和resourcemanager所在的节点设置就可以了。
6. 基础测试和基准测试


7. 使用ntp配置内网中集群机器时间同步(一般不连接外网,因为不安全,所以不使用网络时间同步)
集群的时间要同步
*找一台机器作为时间服务器
*所有的机器与这台机器时间进行定时的同步。比如,每日十分钟,同步一次时间。
① 查看是否安装ntp服务:
# rpm-qa|grep ntp
② 修改配置文件:
# vi /etc/ntp.conf



网上资料:http://acooly.iteye.com/blog/1993484
# For more information about this file, see the man pages # ntp.conf(5), ntp_acc(5), ntp_auth(5), ntp_clock(5), ntp_misc(5), ntp_mon(5).
driftfile /var/lib/ntp/drift
# Permit time synchronization with our time source, but do not # permit the source to query or modify the service on this system. restrict default kod nomodify notrap nopeer noquery restrict -6 default kod nomodify notrap nopeer noquery
# Permit all access over the loopback interface. This could # be tightened as well, but to do so would effect some of # the administrative functions. restrict 127.0.0.1 restrict -6 ::1
# Hosts on local network are less restricted. # 允许内网其他机器同步时间 restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
# Use public servers from the pool.ntp.org project. # Please consider joining the pool (http://www.pool.ntp.org/join.html). # 中国这边最活跃的时间服务器 : http://www.pool.ntp.org/zone/cn server 210.72.145.44 perfer # 中国国家受时中心 server 202.112.10.36 # 1.cn.pool.ntp.org server 59.124.196.83 # 0.asia.pool.ntp.org
#broadcast 192.168.1.255 autokey # broadcast server #broadcastclient # broadcast client #broadcast 224.0.1.1 autokey # multicast server #multicastclient 224.0.1.1 # multicast client #manycastserver 239.255.254.254 # manycast server #manycastclient 239.255.254.254 autokey # manycast client
# allow update time by the upper server # 允许上层时间服务器主动修改本机时间 restrict 210.72.145.44 nomodify notrap noquery restrict 202.112.10.36 nomodify notrap noquery restrict 59.124.196.83 nomodify notrap noquery
# Undisciplined Local Clock. This is a fake driver intended for backup # and when no outside source of synchronized time is available. # 外部时间服务器不可用时,以本地时间作为时间服务 server 127.127.1.0 # local clock fudge 127.127.1.0 stratum 10
# Enable public key cryptography. #crypto
includefile /etc/ntp/crypto/pw
# Key file containing the keys and key identifiers used when operating # with symmetric key cryptography. keys /etc/ntp/keys
# Specify the key identifiers which are trusted. #trustedkey 4 8 42
# Specify the key identifier to use with the ntpdc utility. #requestkey 8
# Specify the key identifier to use with the ntpq utility. #controlkey 8
# Enable writing of statistics records. #statistics clockstats cryptostats loopstats peerstats |
# vi /etc/sysconfig/ntpd
③ 启动ntp服务:service ntpd start
设置ntp服务开机自启:chkconfig ntpd on
④ 在02和03节点上写脚本:
每十分钟与时间服务器(节点)同步一次
crontab –e(必须要root用户)
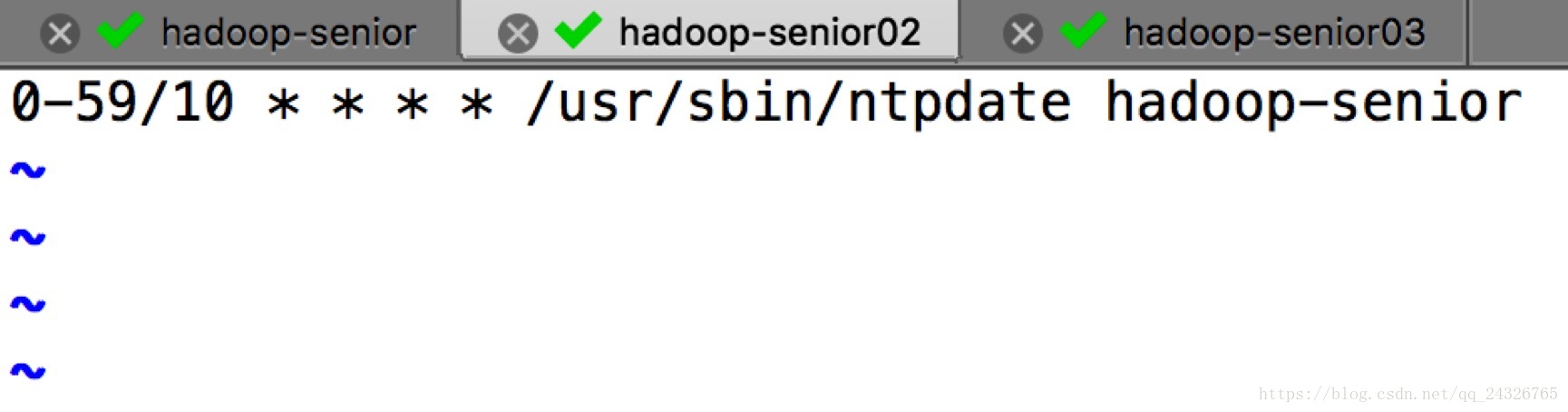

手动同步:
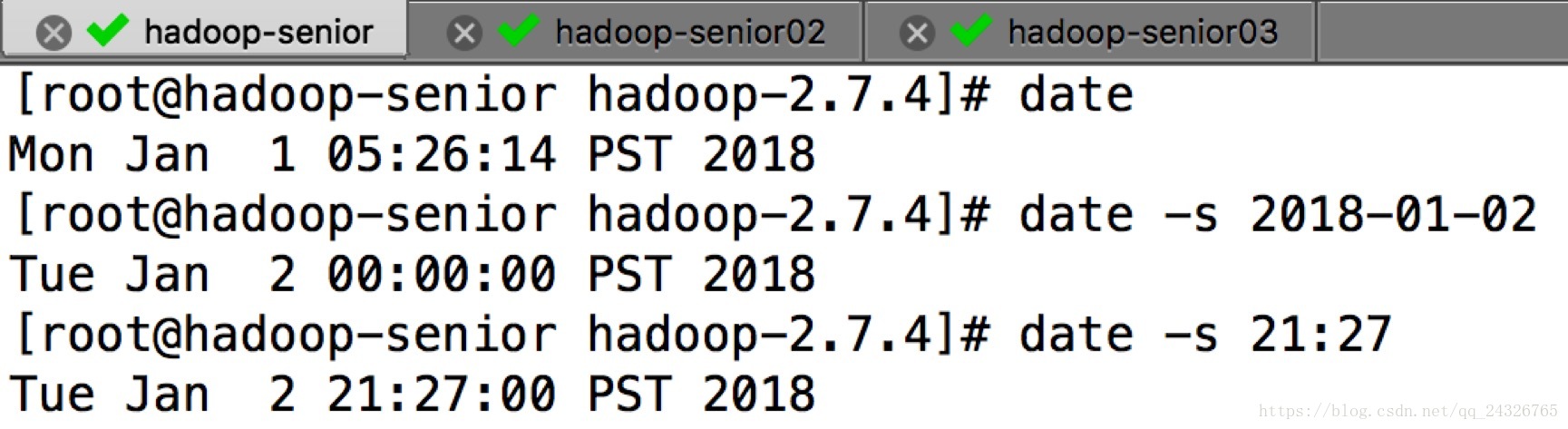
(给时间服务器设置个时间)
其他节点与时间服务器同步:


可能出现的问题:

时间服务器必须要启动10分钟才能同步,等待。
8. 分布式协作服务框架Zookeeper架构功能讲解

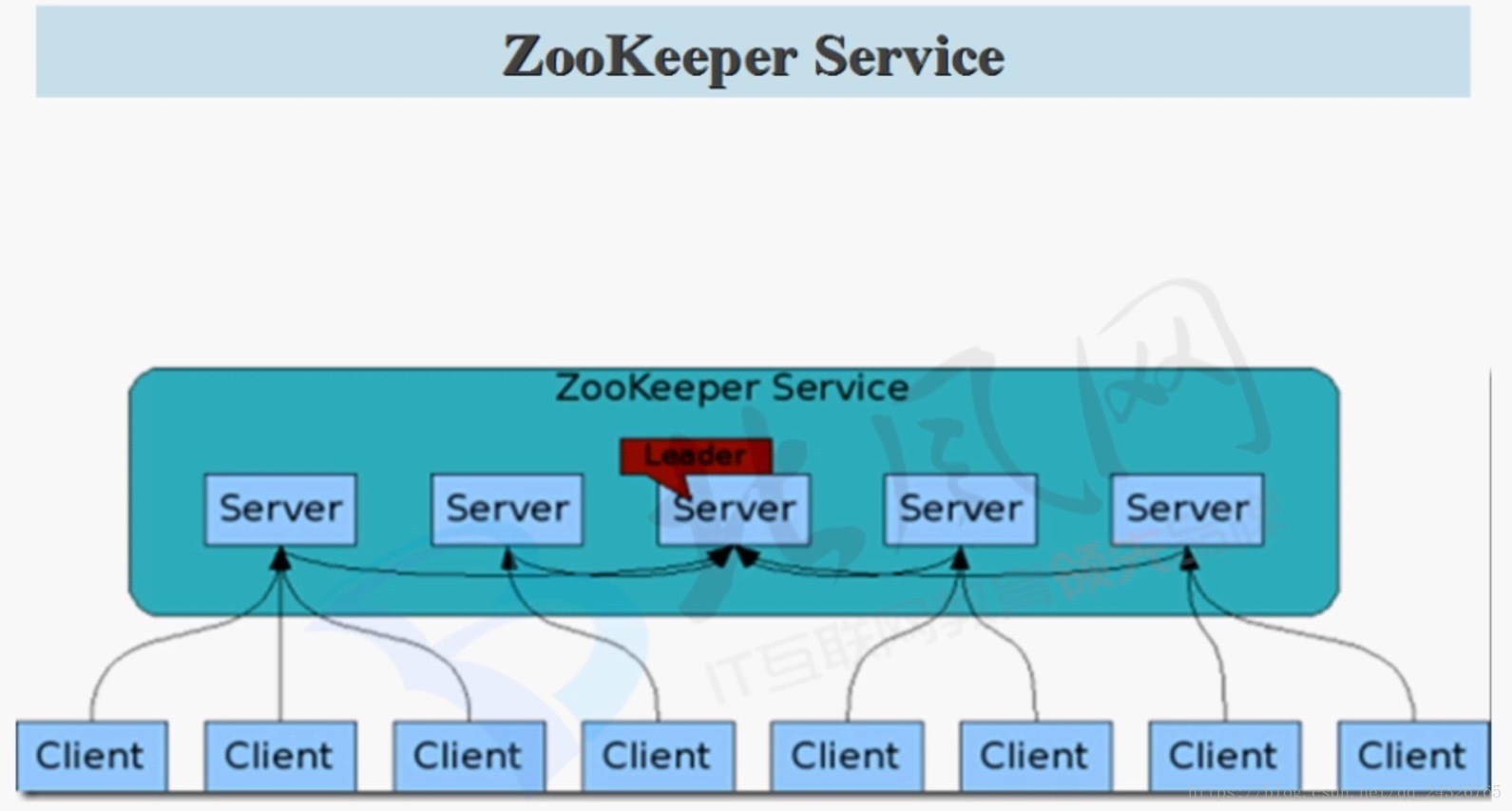
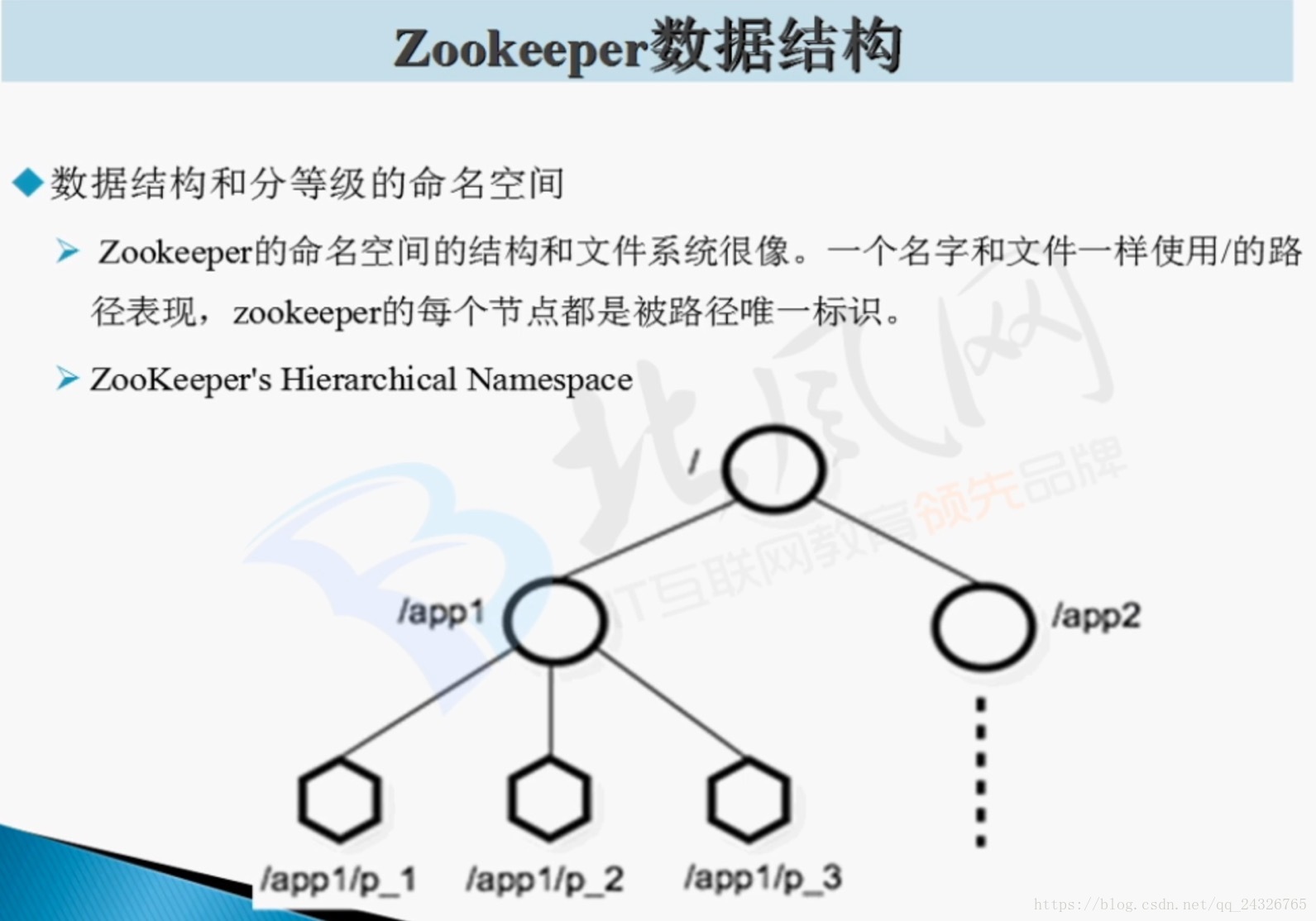
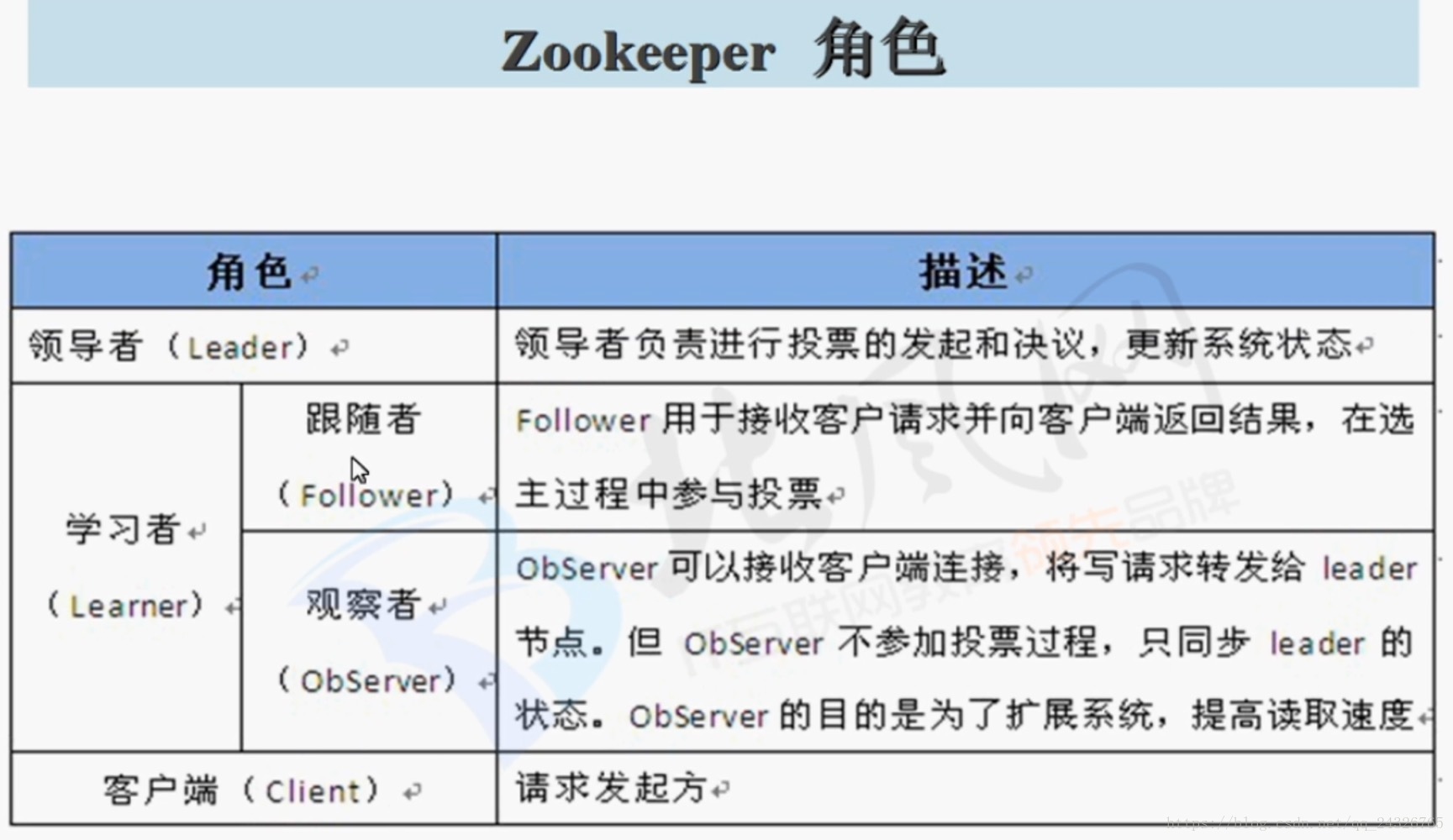

(由java编写;它的服务器节点的个数一般是奇数个;将配置信息配置到zookeeper上,这样就不用scp了)
9. 分布式协作服务框架Zookeeper的安装
安装本地模式:
① 解压:
tar -xzvf zookeeper-3.4.8.tar.gz -C /usr/opt/modules/
② 修改配置文件
zoo.cfg(将zoo_sample.cfg重命名)
修改数据存放目录
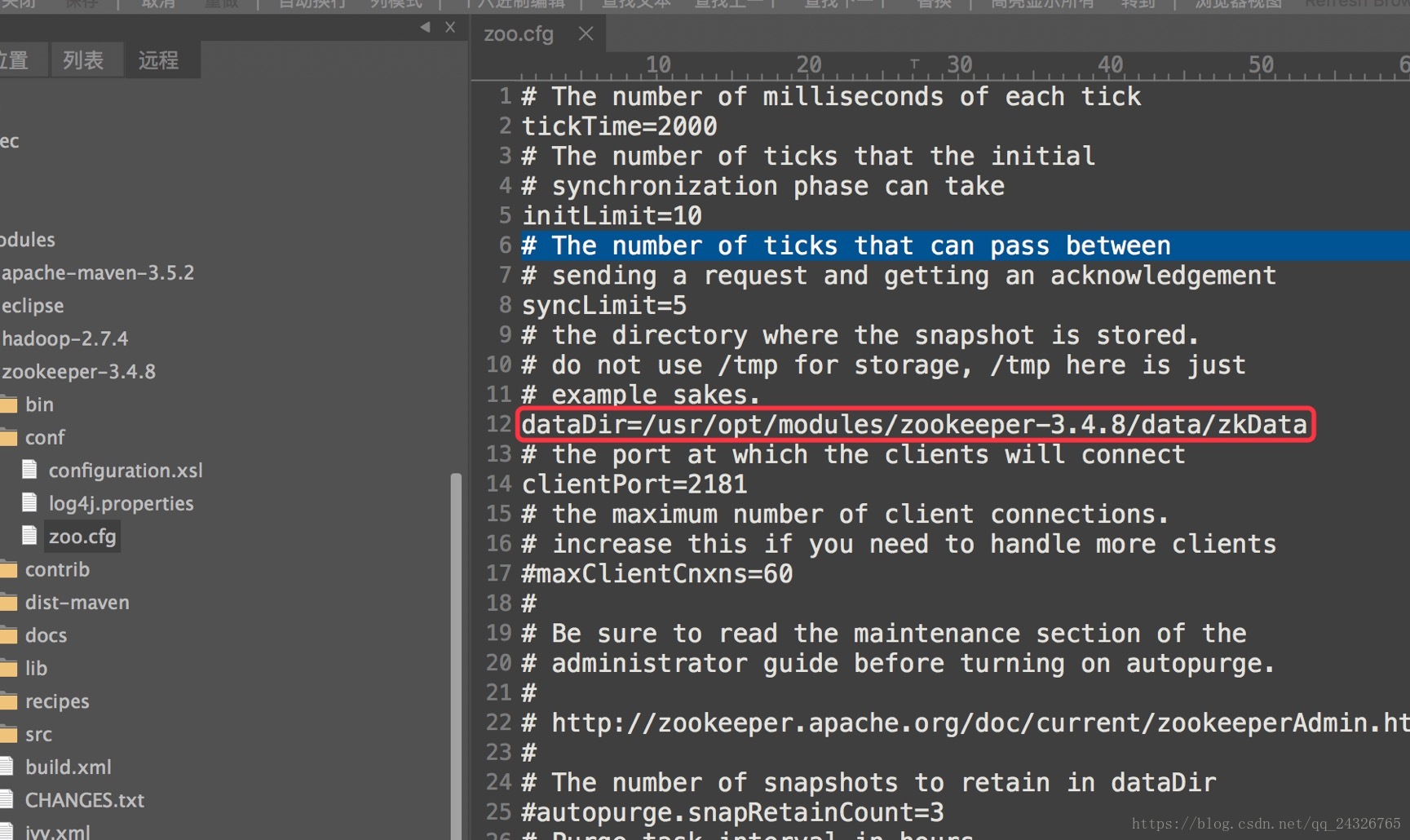
③ 启动zookeeper:bin/zkServer.shstart

安装分布式(对时间同步要求很高):
① 修改配置文件:
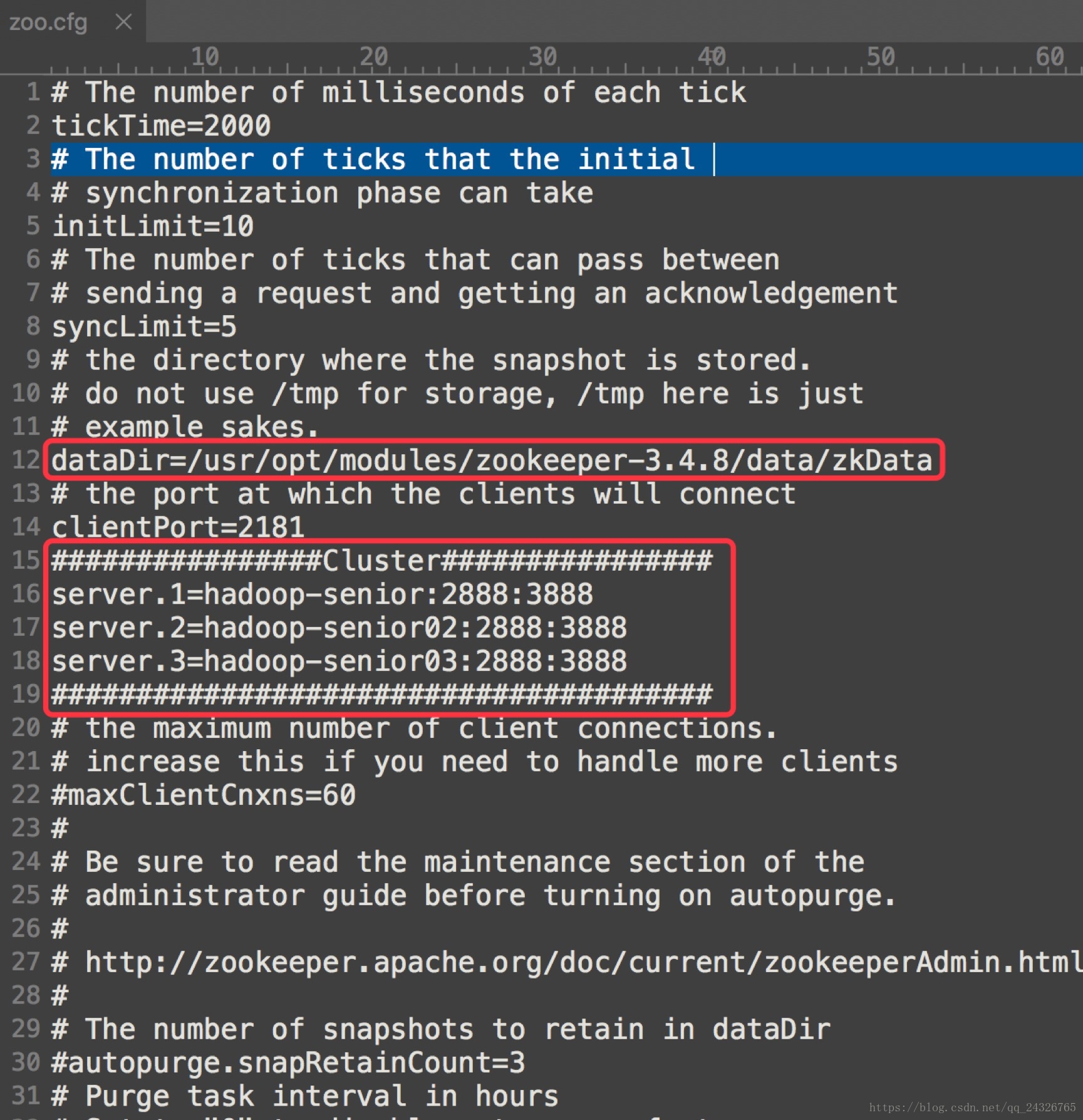
② 在数据存储目录下创建myid文件
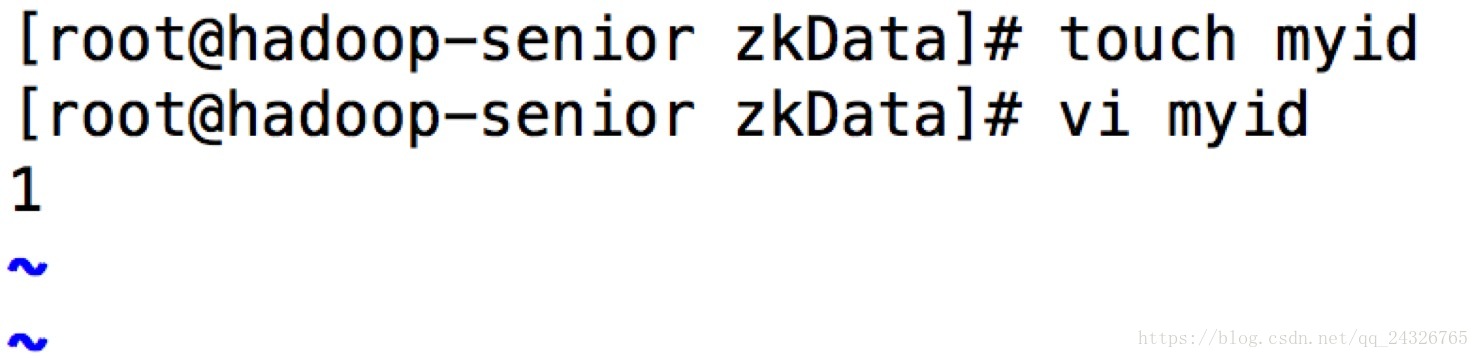
② 将zookeeper分发到各个节点上
[root@hadoop-senior modules]# scp -rzookeeper-3.4.8/ root@hadoop-senior02:/usr/opt/modules/
[root@hadoop-senior modules]# scp -rzookeeper-3.4.8/ root@hadoop-senior03:/usr/opt/modules/
③ 修改各个节点上的myid
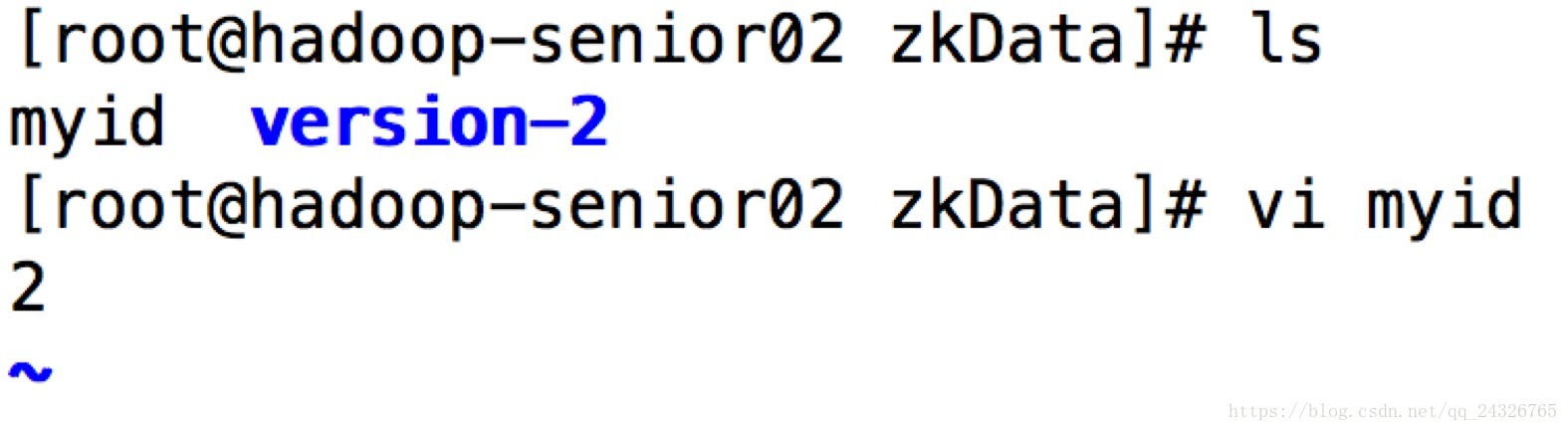
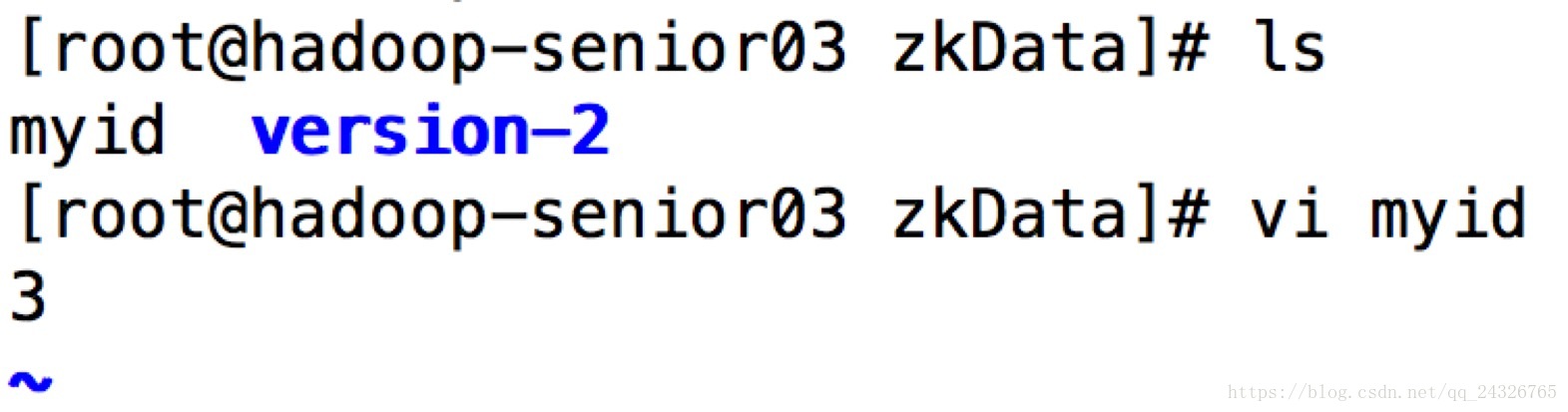
④ 启动并查看状态
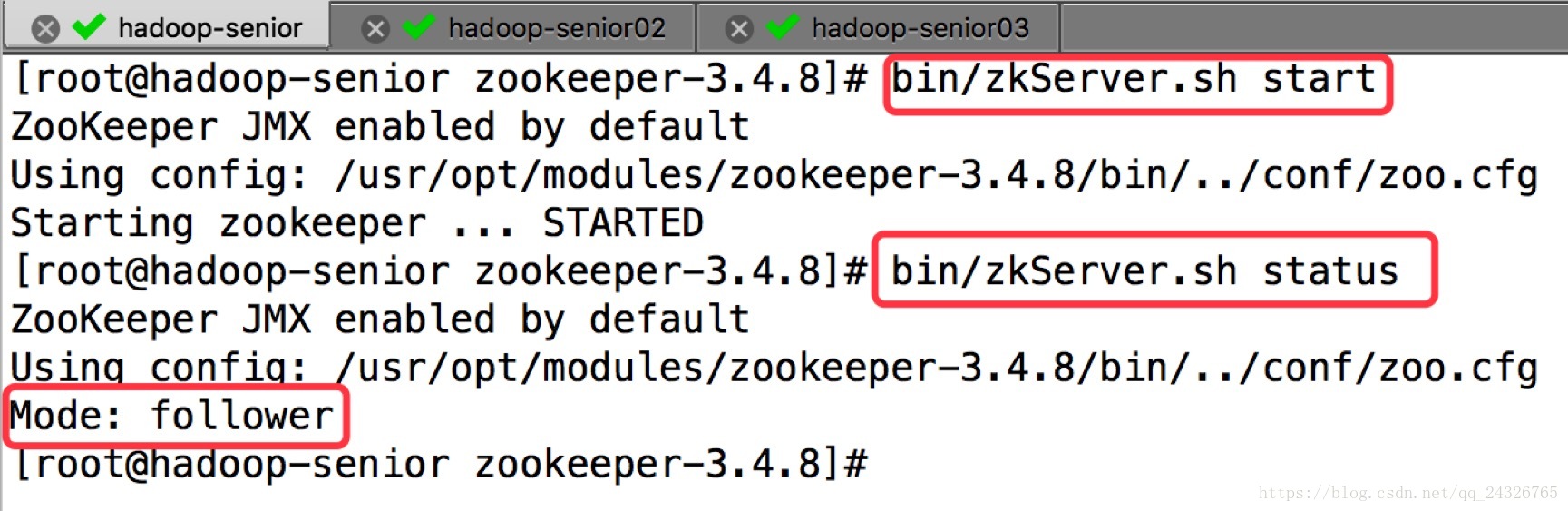
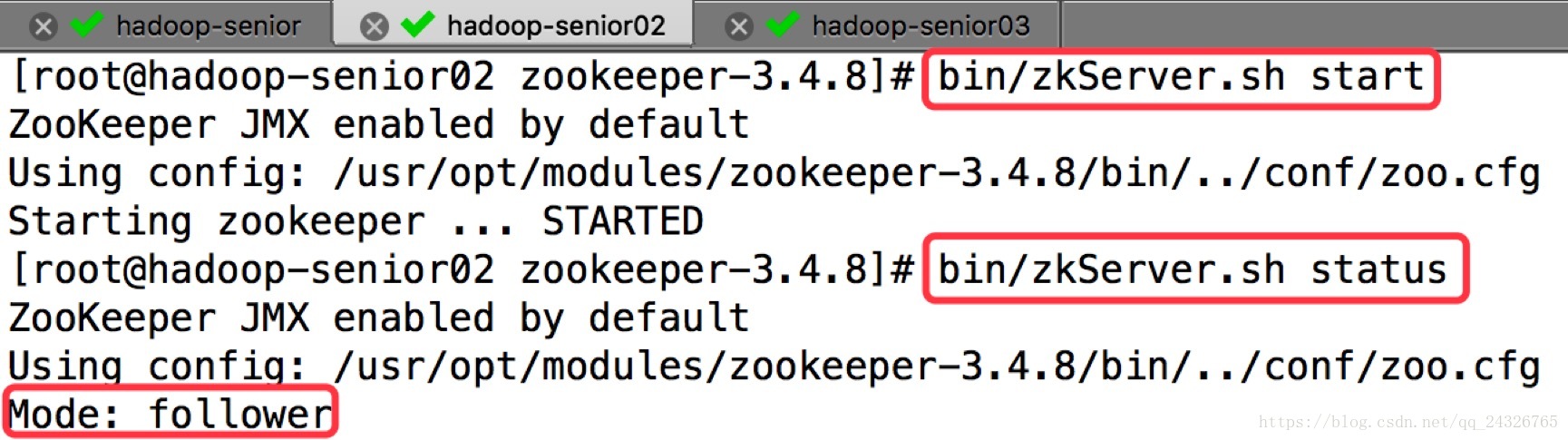
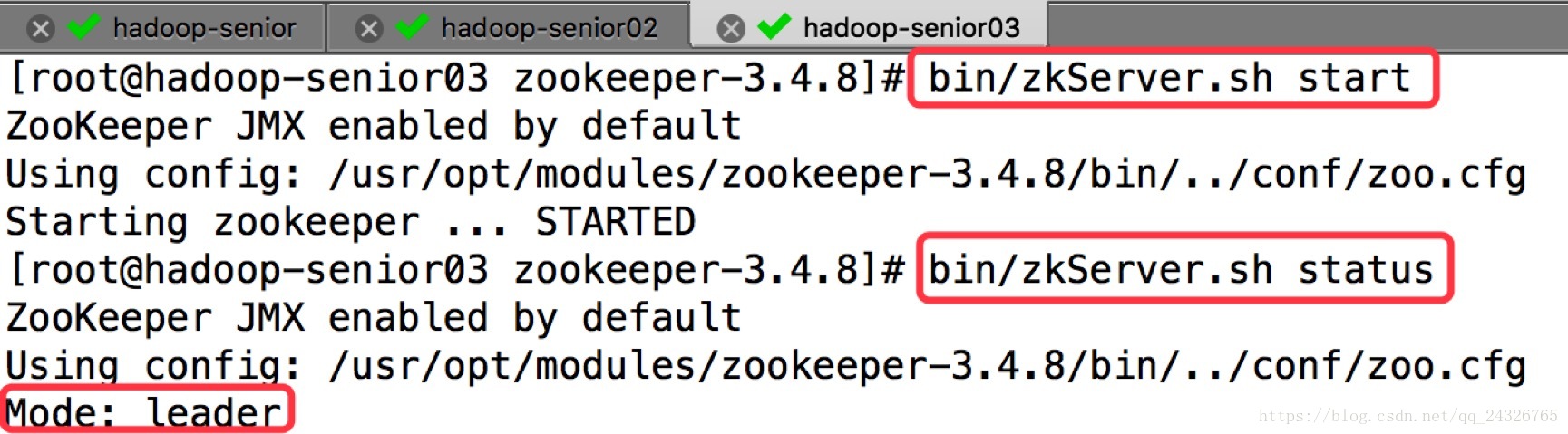
进入shell:bin/zkCli.sh

创建目录:

获取数据:
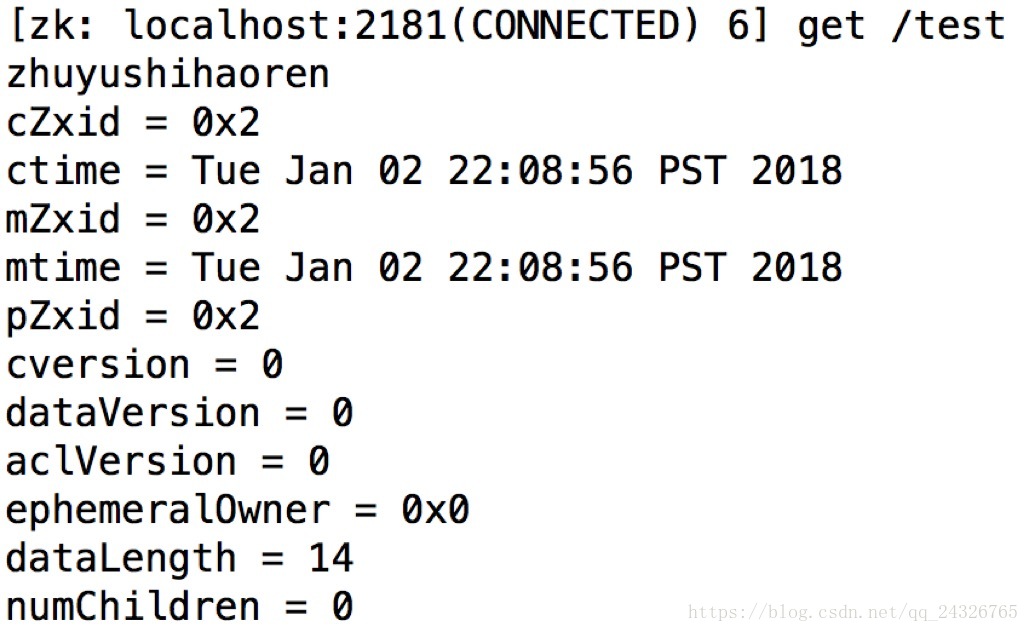
删除数据:

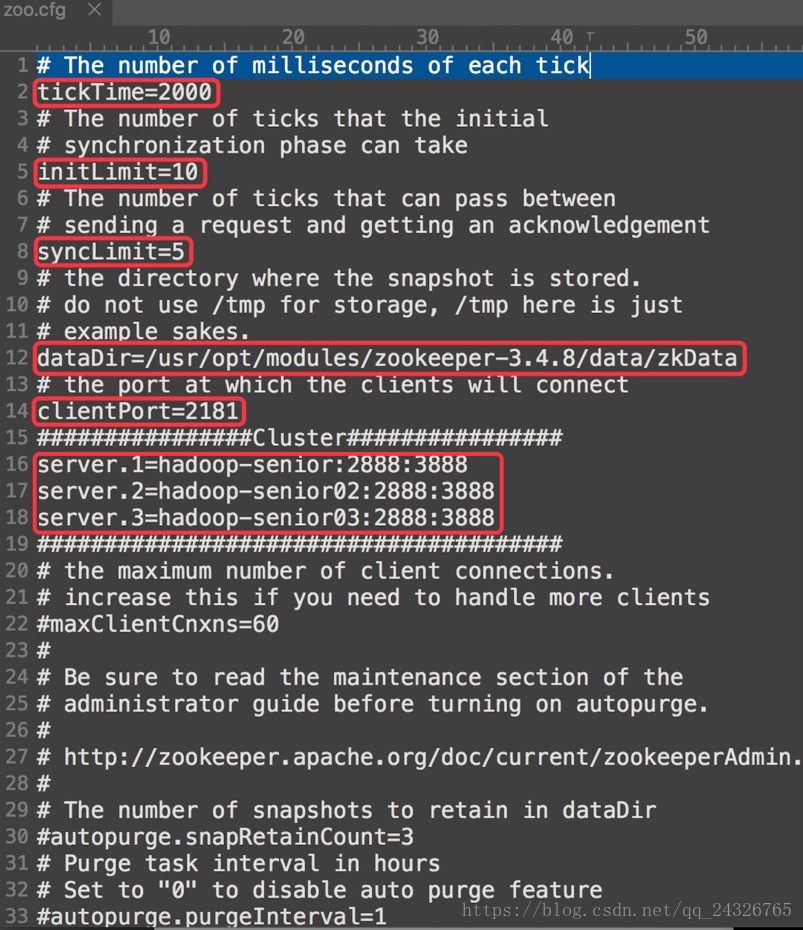
10. Zookeeper配置参数详解
zoo.cfg



11.回顾HDFS架构存在单节点故障及引出HDFS HA
HDFS
分布式存储
*NameNode
元数据
/user/beifeng/tmp/core-site.xml
文件名称 路劲 拥有者(所属者) 所属组 权限 副本数 .....
*DataNode
128 MB
Block方式进行存储
本地磁盘(位置的配置信息如下)
hdfs-default.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
*Client
客户端访问集群时,先找NameNode,然后再根据NameNode找到DataNode
这就意味着NameNode 节点出现问题,整个集群就不能用了。
* HDFS HA(hadoop 2.2.0开始出现)
* NameNode Active
* NameNode Standby
12.HDFS HA架构设计及四大要点讲解

机器升级时需要关机。
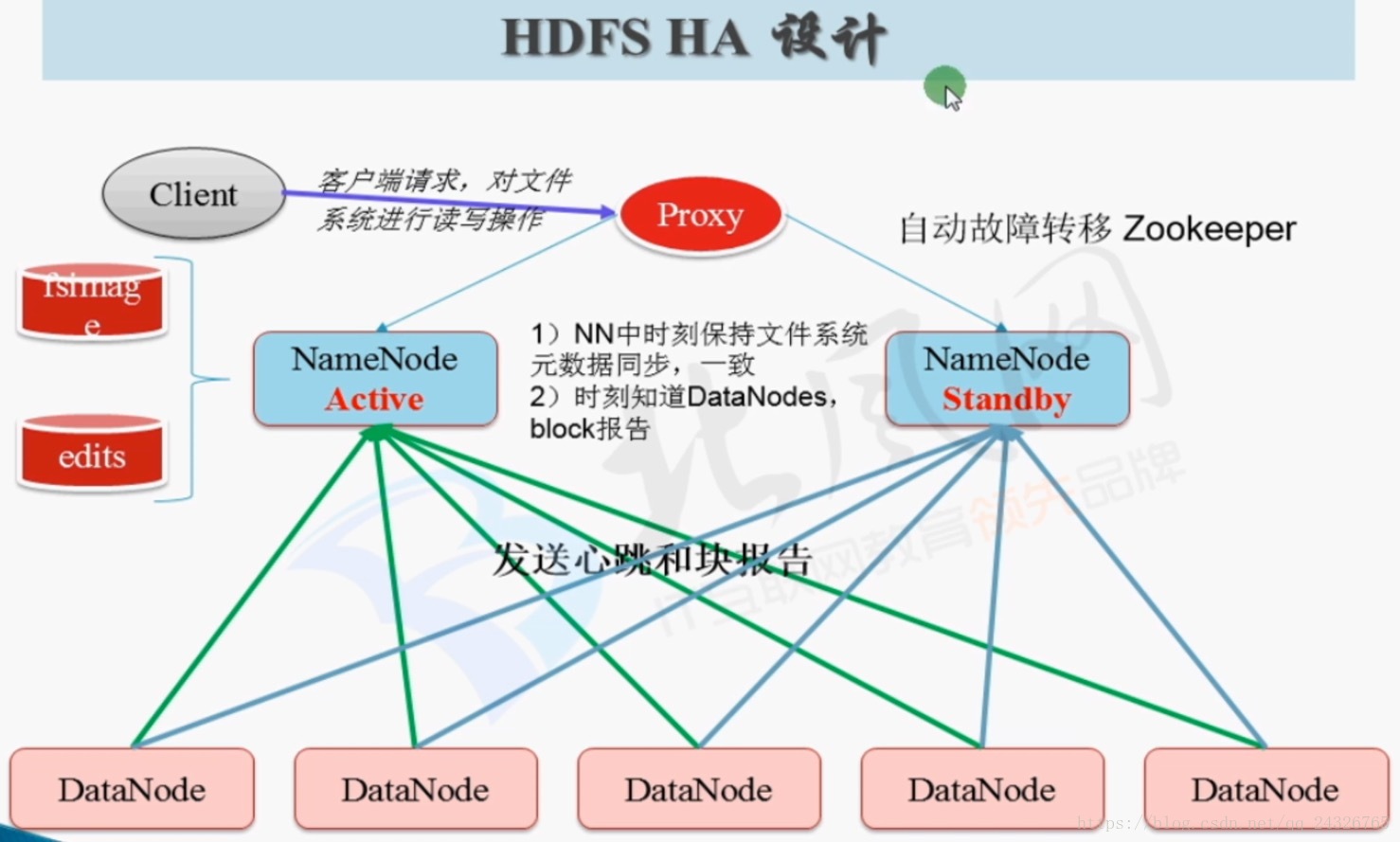
HA的核心就是怎样保证两个namenode内存里面元数据内容的一致,这个一致的核心就是编辑日志(edits)。那么如何保证edit文件的安全性和可靠性?方案如下:

把编辑日志存在奇数(2n+1)台机器上,有个进程叫JournalNode。当有n+1个节点写成功了,就表示日志是安全的。例如:3个节点有2个写成功。DataNode不仅要向Active发送心跳和块报告,也要向Standby发送。
配置要点:
* share edits
JournalNode
* NameNode
Active,Standby
* Client
Proxy
* fence(隔离)
同一时刻仅仅有一个NameNode对外提供服务
使用的方式sshfence
两个NameNode之间能够ssh无密码登录
131(NameNode) ssh -> 132
132(NameNode) ssh -> 131
13. 根据官方文档配置HDFS HA
集群规划:

HA不需要secondarynamenode了,因为Active关机,Standby就直接替Active干活了,同时Standby具备合并fsimage和edits的功能。
官方文档:
修改配置文件:
hdfs-site.xml
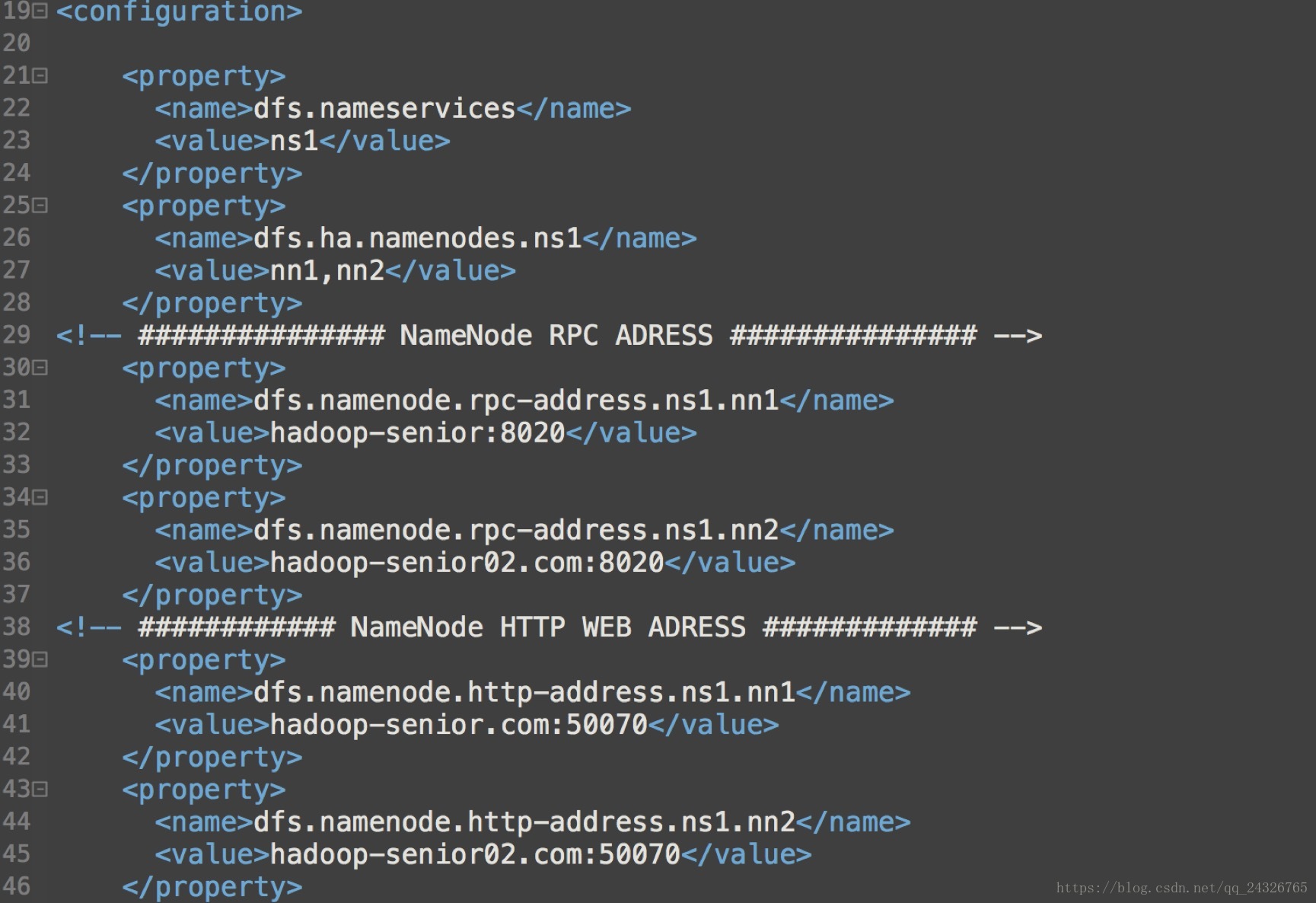
配置集群服务的名称:
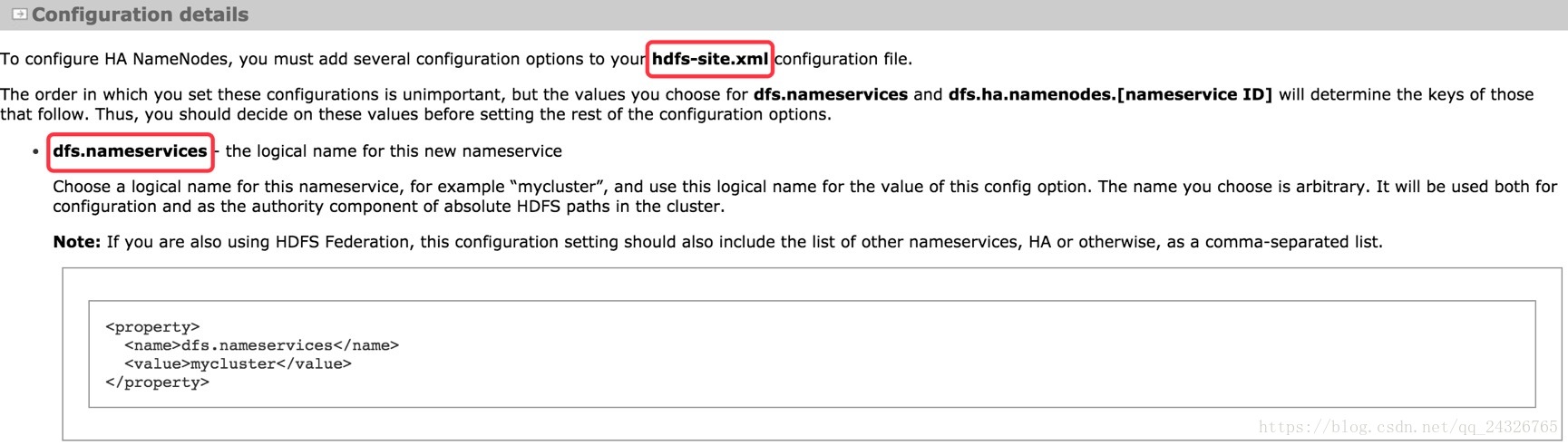
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>配置高可用的NameNode:

<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>配置高可用的NameNode的RPC地址:

<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>machine1.example.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>machine2.example.com:8020</value>
</property>配置高可用的NameNode的WEB地址:

<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>machine1.example.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>machine2.example.com:50070</value>
</property>配置共享编辑日志的目录在哪个节点上(JournalNode节点):

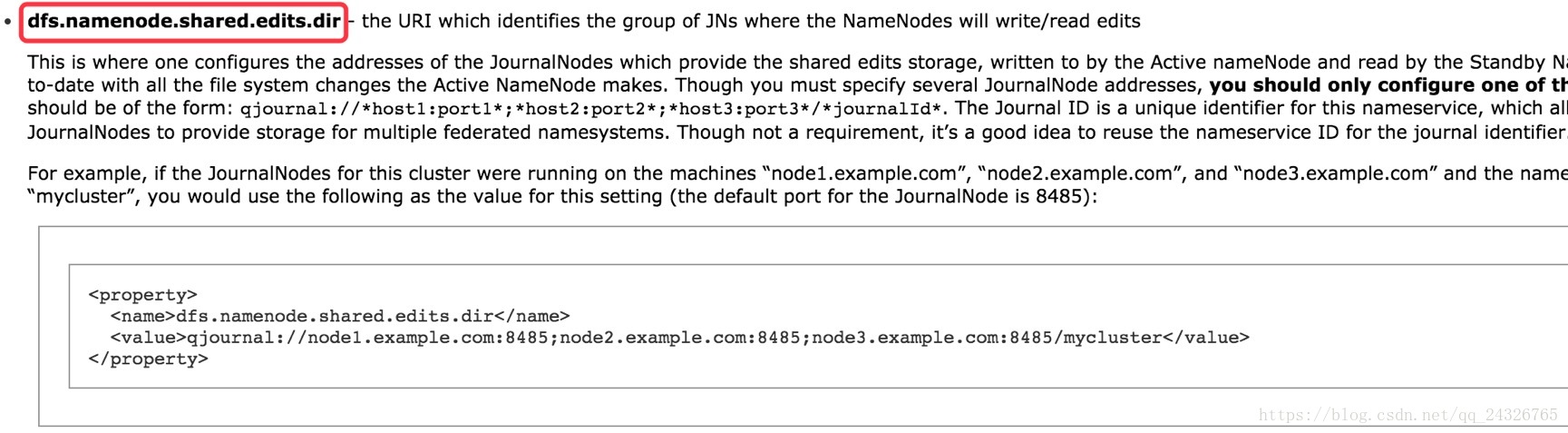
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/mycluster</value>
</property>配置JournalNode节点日志的存放目录:

<property>
<name>dfs.journalnode.edits.dir</name>
<value>/path/to/journal/node/local/data</value>
</property>配置代理客户端:

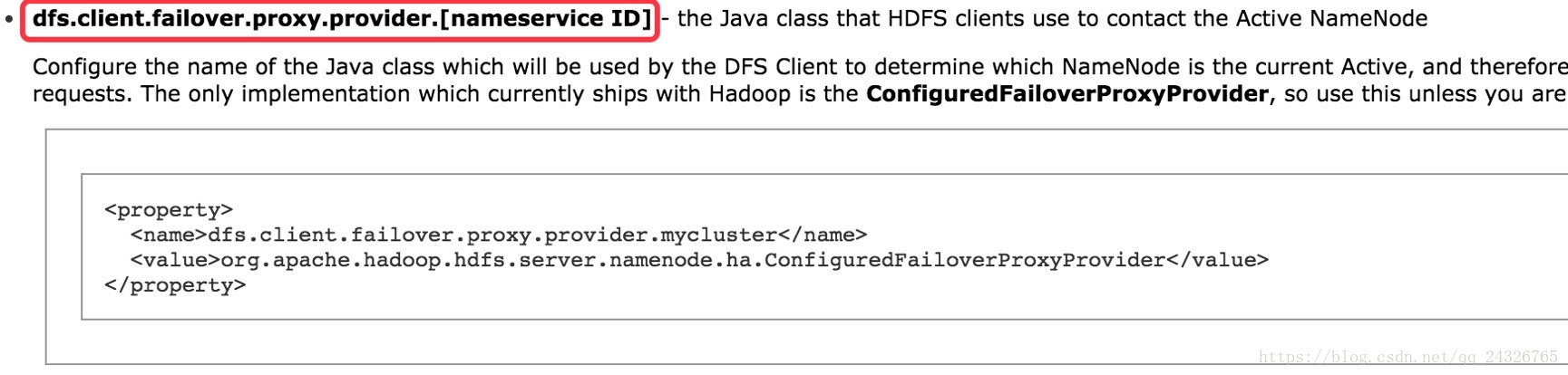
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>使用SSH隔离:

前提:两个namenode要实现ssh免密码登录
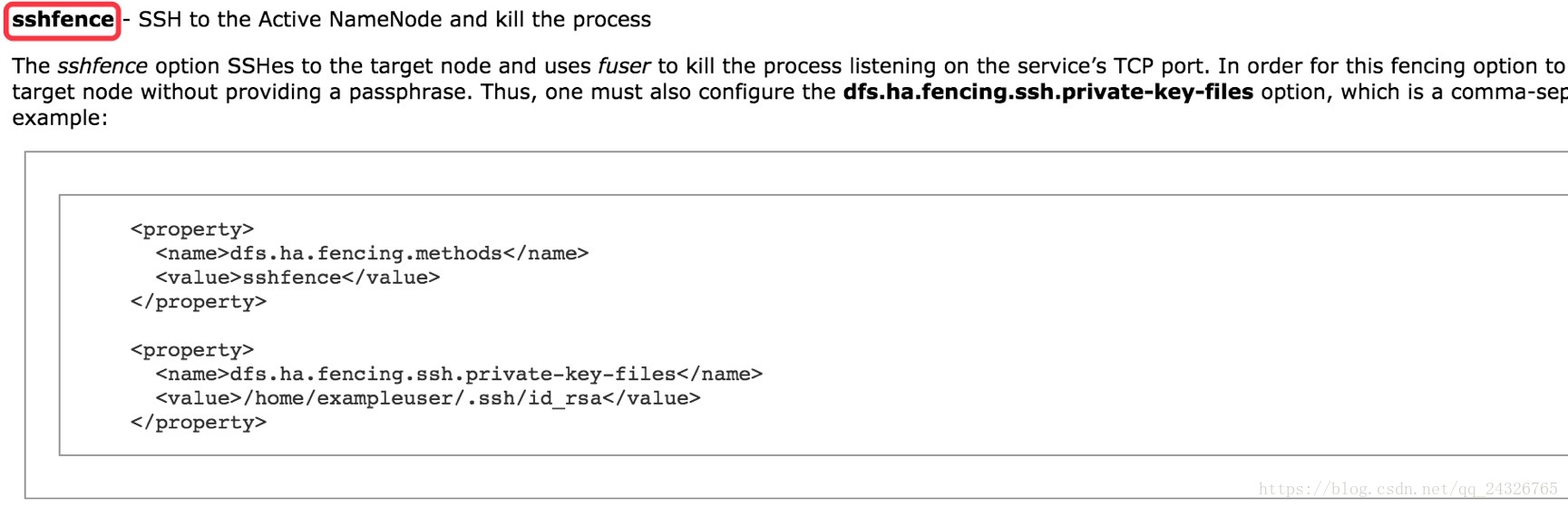
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/exampleuser/.ssh/id_rsa</value>
</property>core-site.xml
配置namedode节点:
之前是一个namenode,现在有两个,所以需要改
之前:

现在:
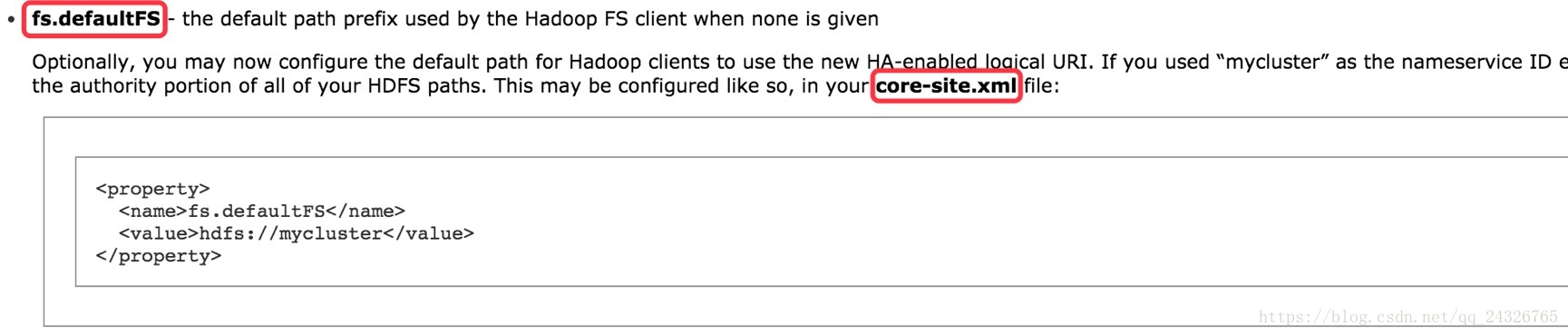
配置高可用完整版:
hdfs-site.xml
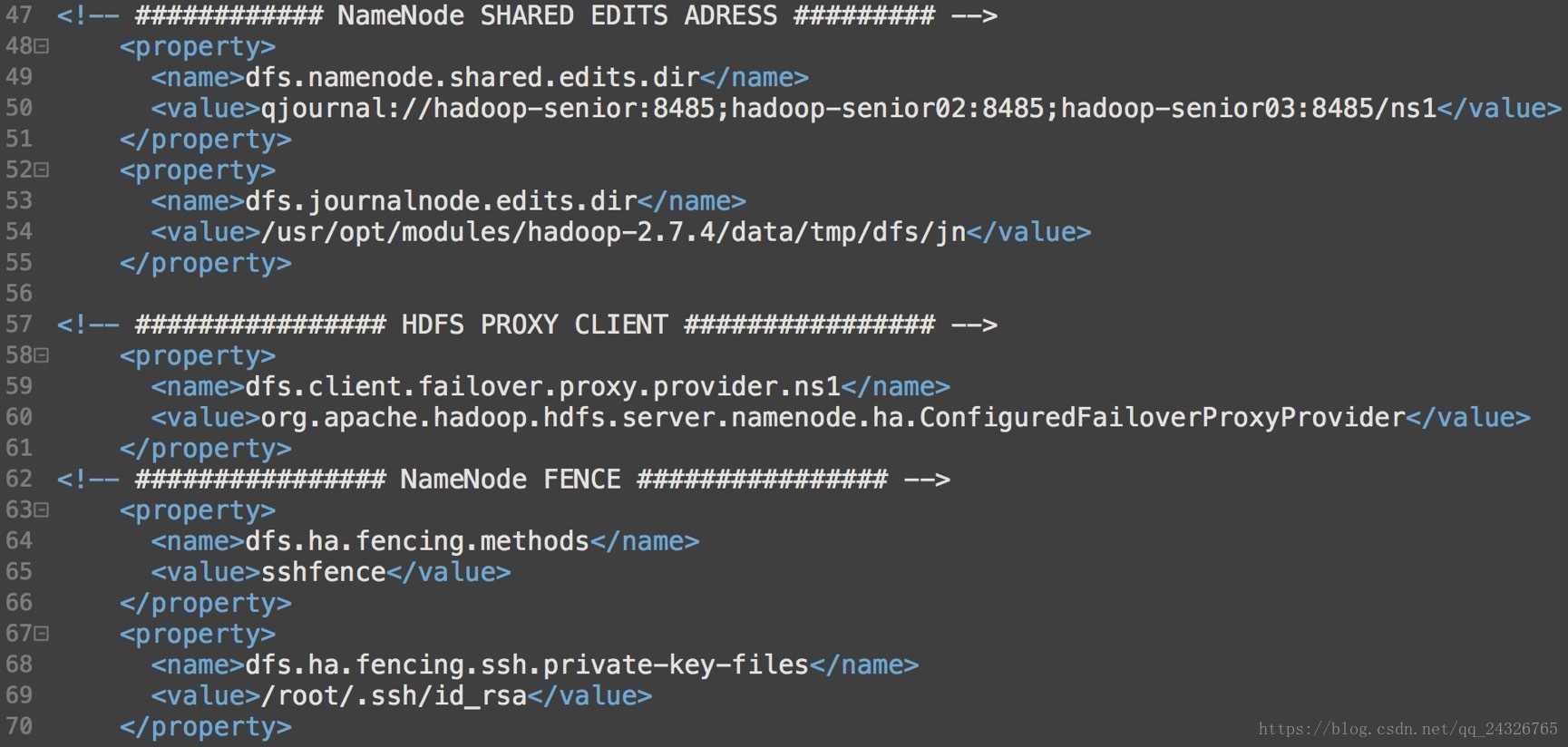
core-site.xml
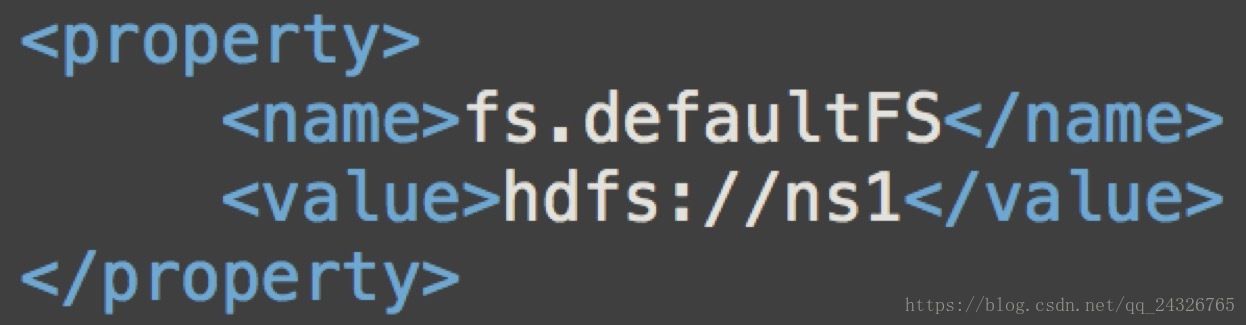
分发:

14. 按步骤逐一启动HDFS HA中各个守护进程

① 启动JournalNode(对日志进行收集,必须要先开启,否则无法格式化)
[root@hadoop-senior hadoop-2.7.4]#sbin/hadoop-daemon.sh start journalnode
② 在NameNode1上进行格式化并启动NameNode1
(因为是新的集群所以要格式化)
[root@hadoop-senior hadoop-2.7.4]#bin/hdfs namenode –format
[root@hadoop-senior hadoop-2.7.4]#sbin/hadoop-daemon.sh start namenode
③ NameNode2同步NameNode1的元数据信息
[root@hadoop-senior02 hadoop-2.7.4]#bin/hdfs namenode –bootstrapStandby
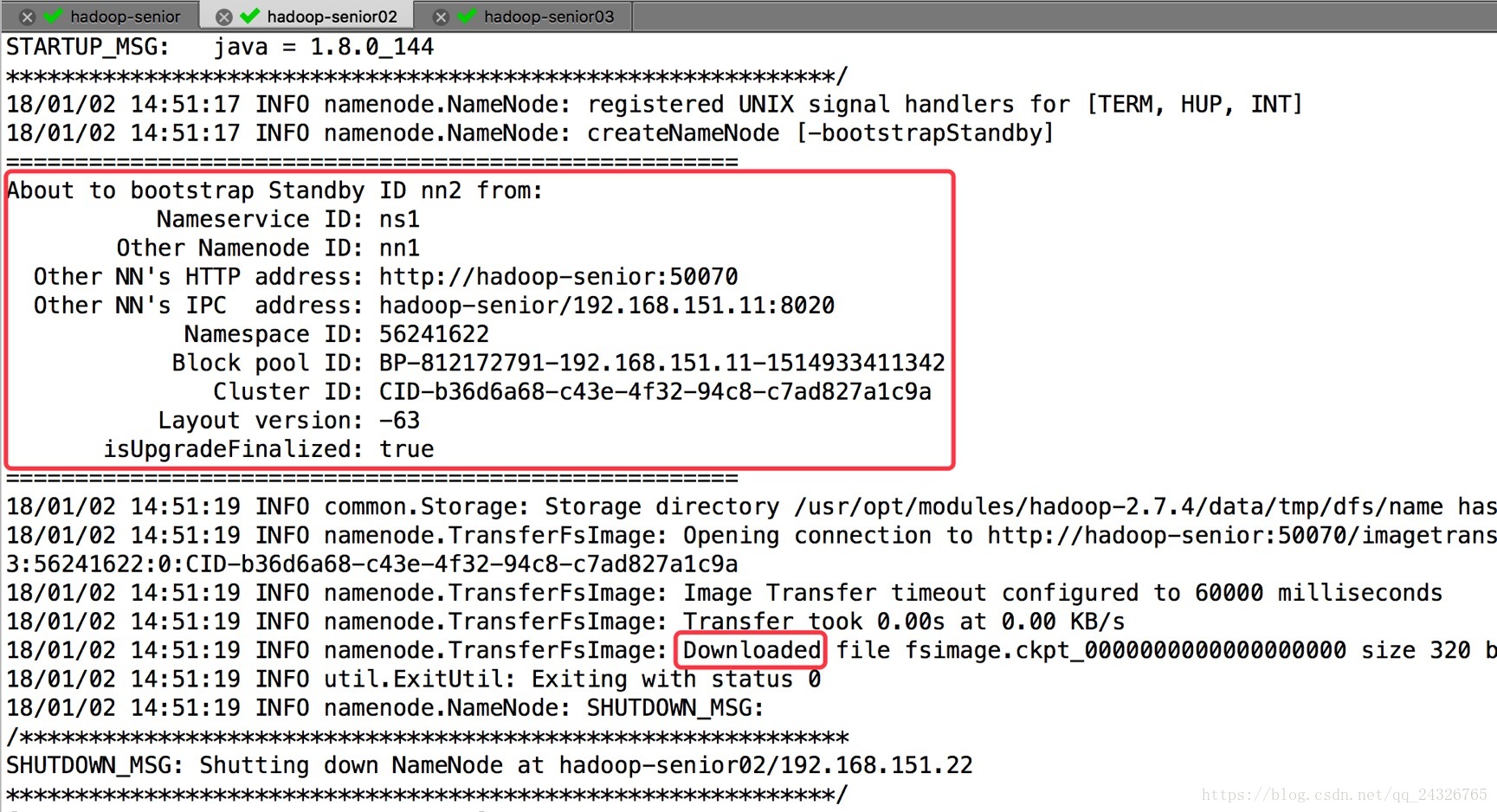
④ 启动NameNode2
[root@hadoop-senior02 hadoop-2.7.4]#sbin/hadoop-daemon.sh start namenode
查看50070页面:
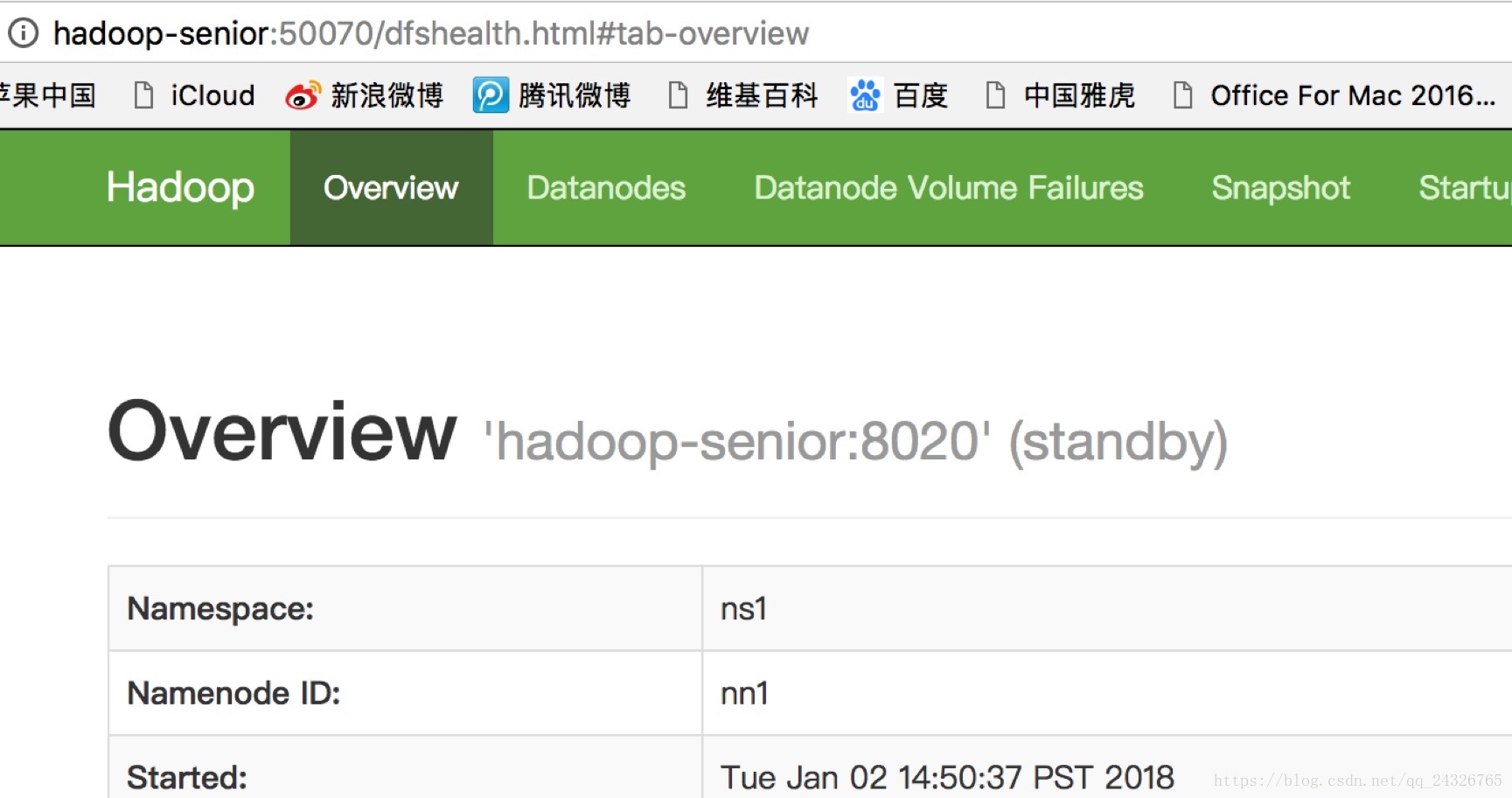
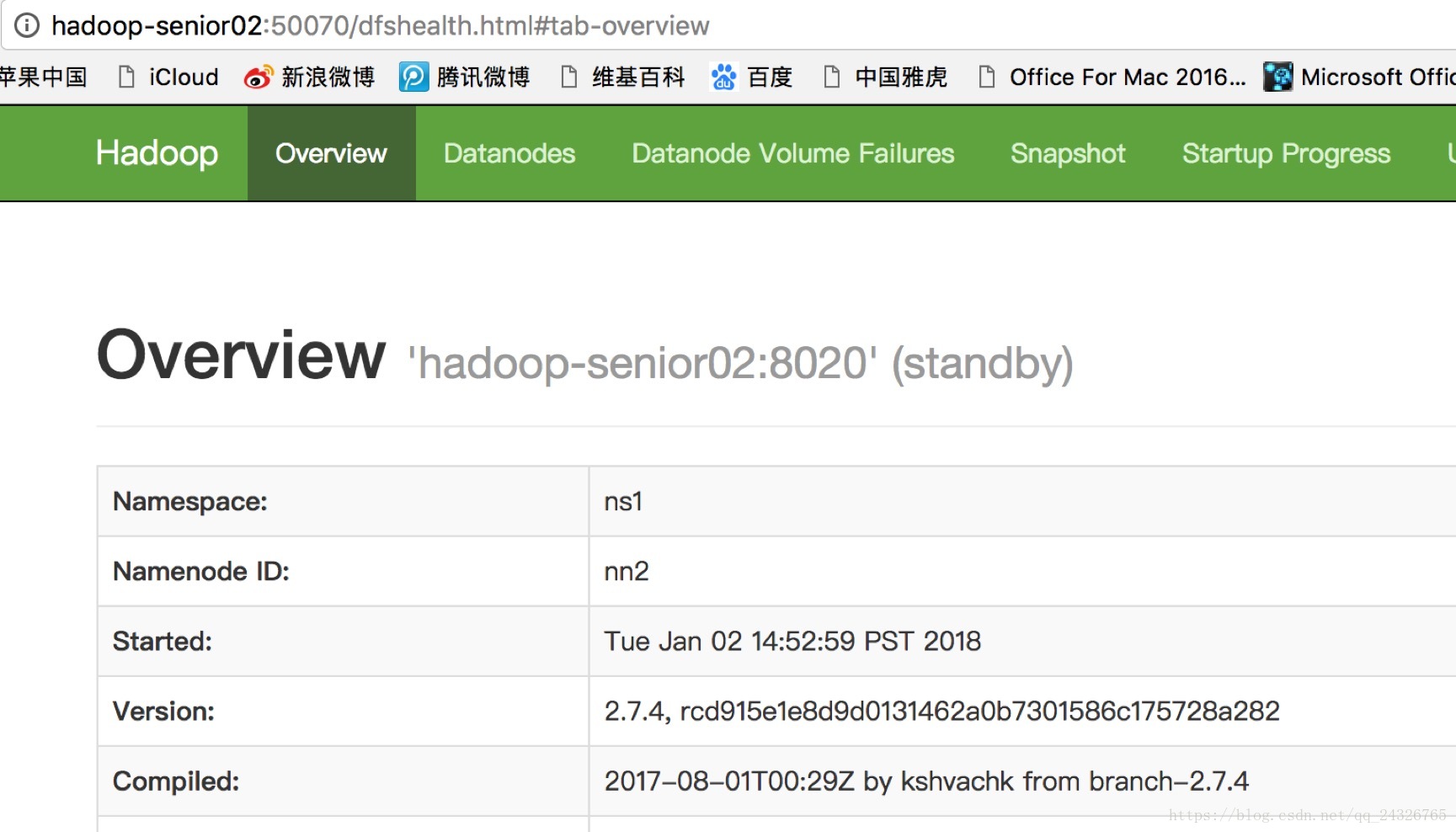
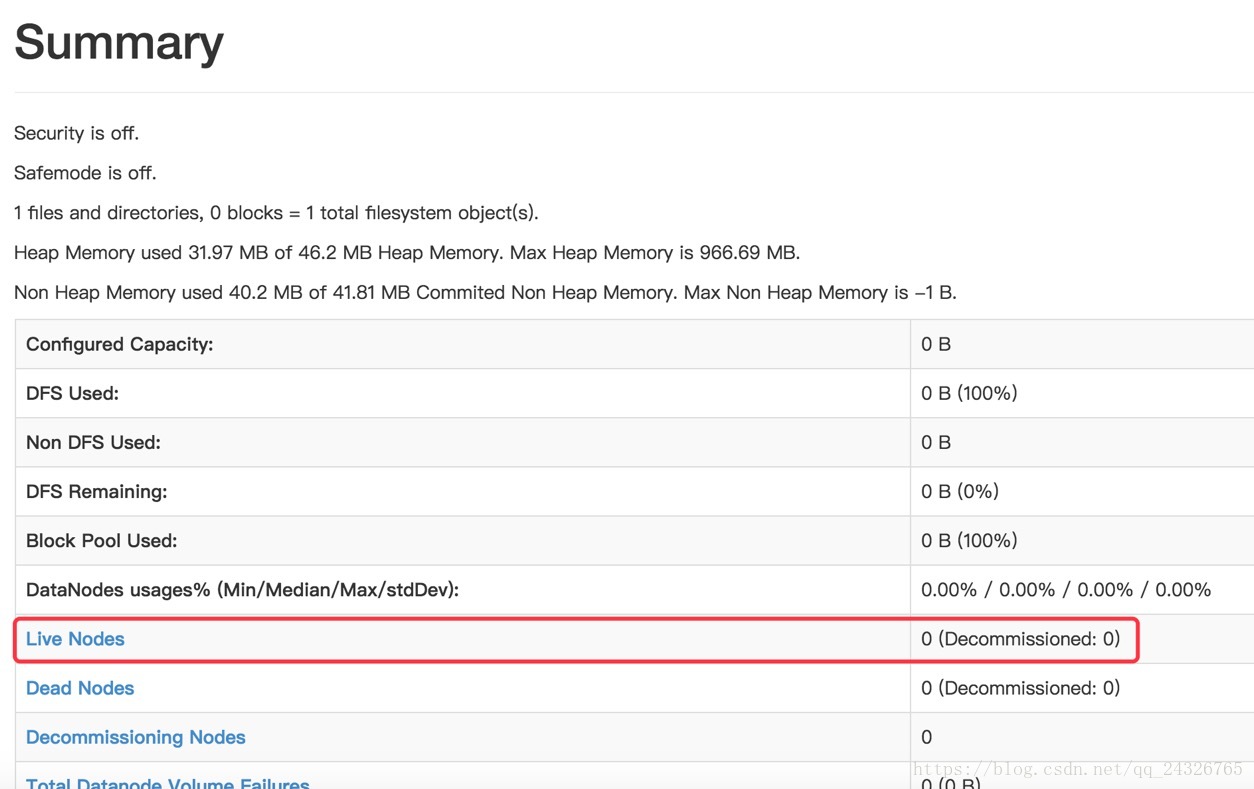
⑤ 启动所有DataNode
[root@hadoop-senior hadoop-2.7.4]#sbin/hadoop-daemon.sh start datanode
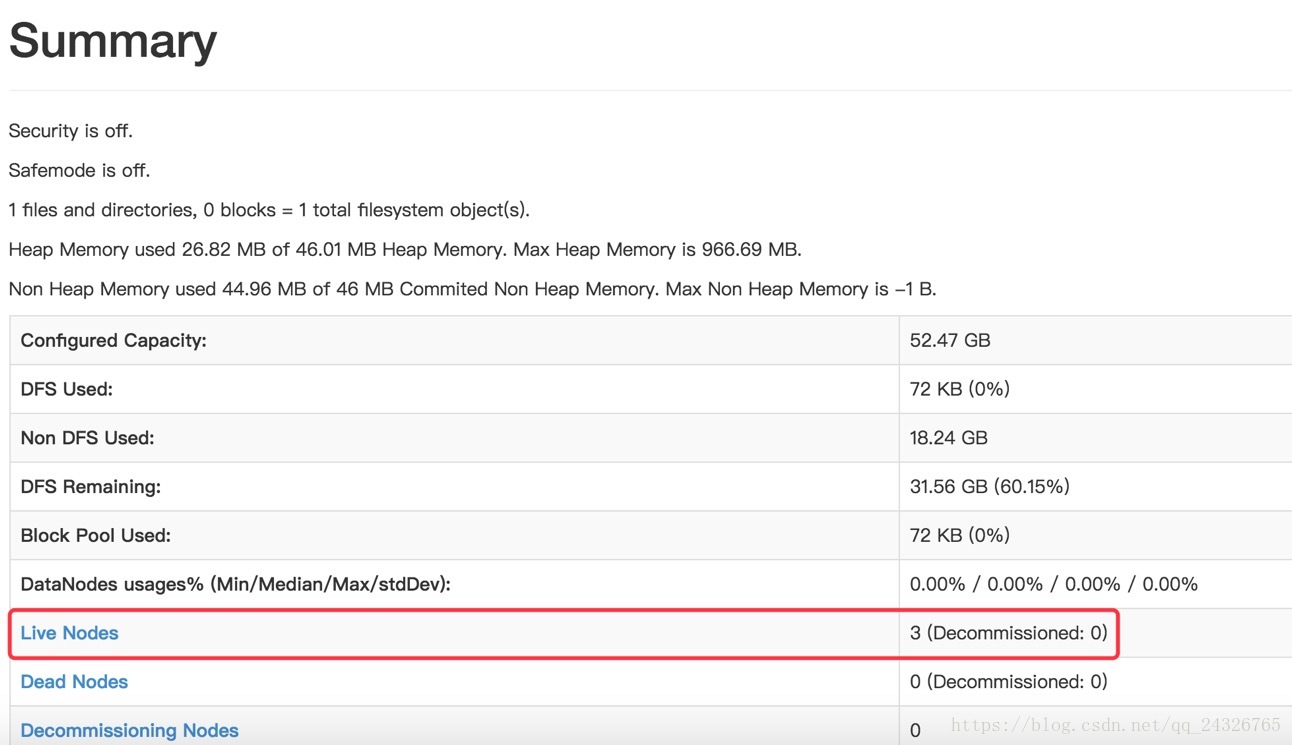
⑥ 将NameNode1切换为Active
[root@hadoop-senior hadoop-2.7.4]#bin/hdfs haadmin -transitionToActive nn1

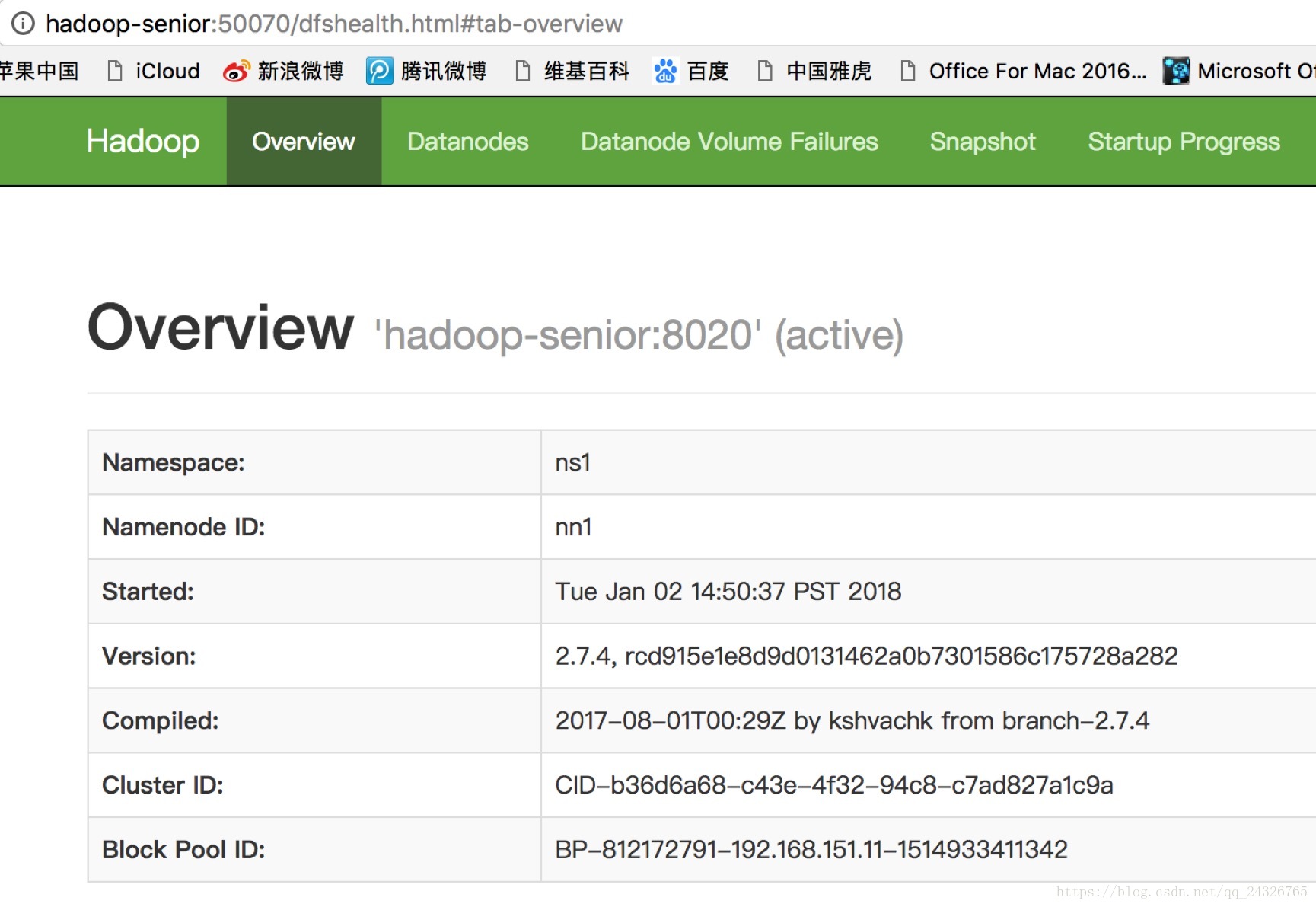
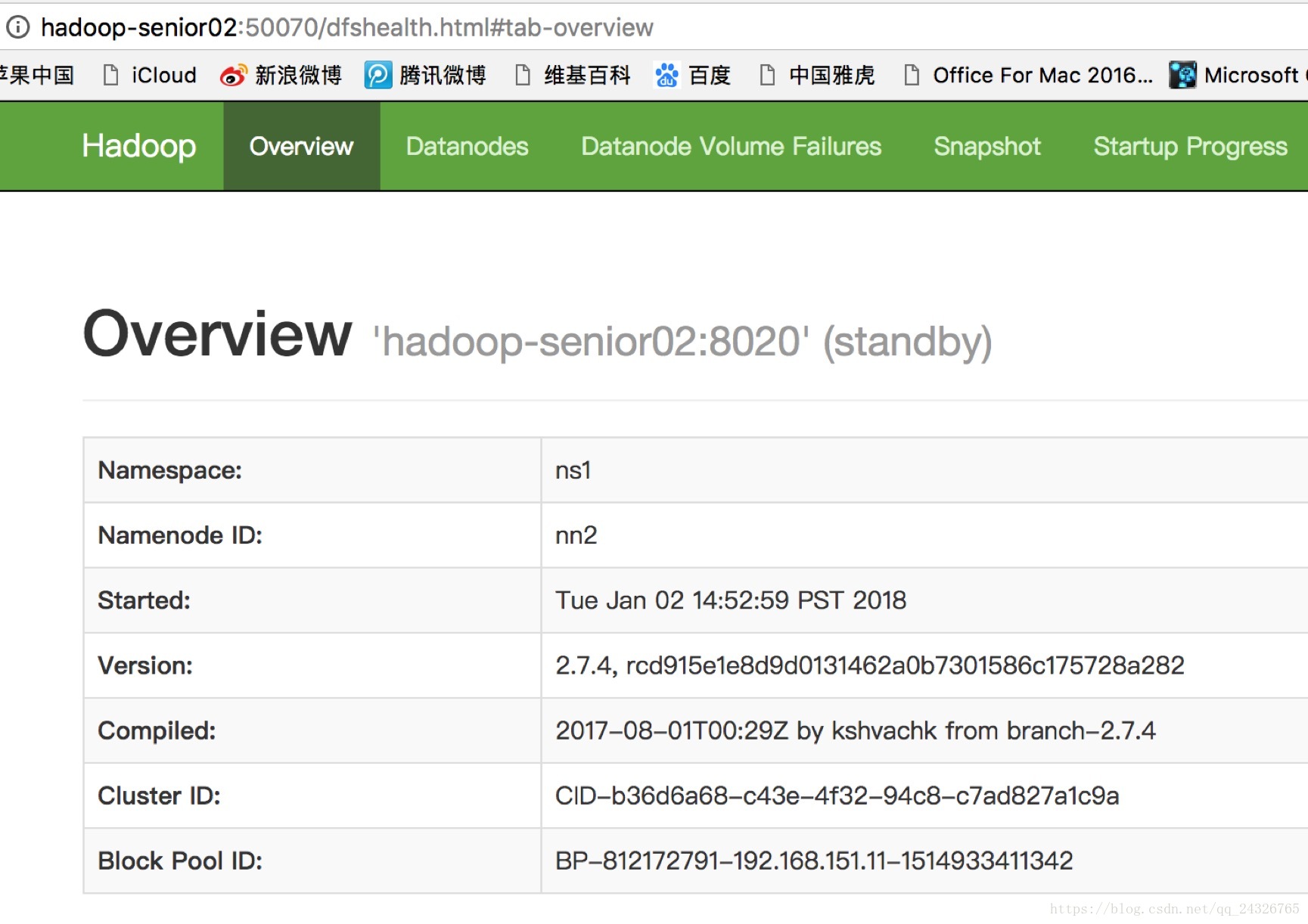
测试:
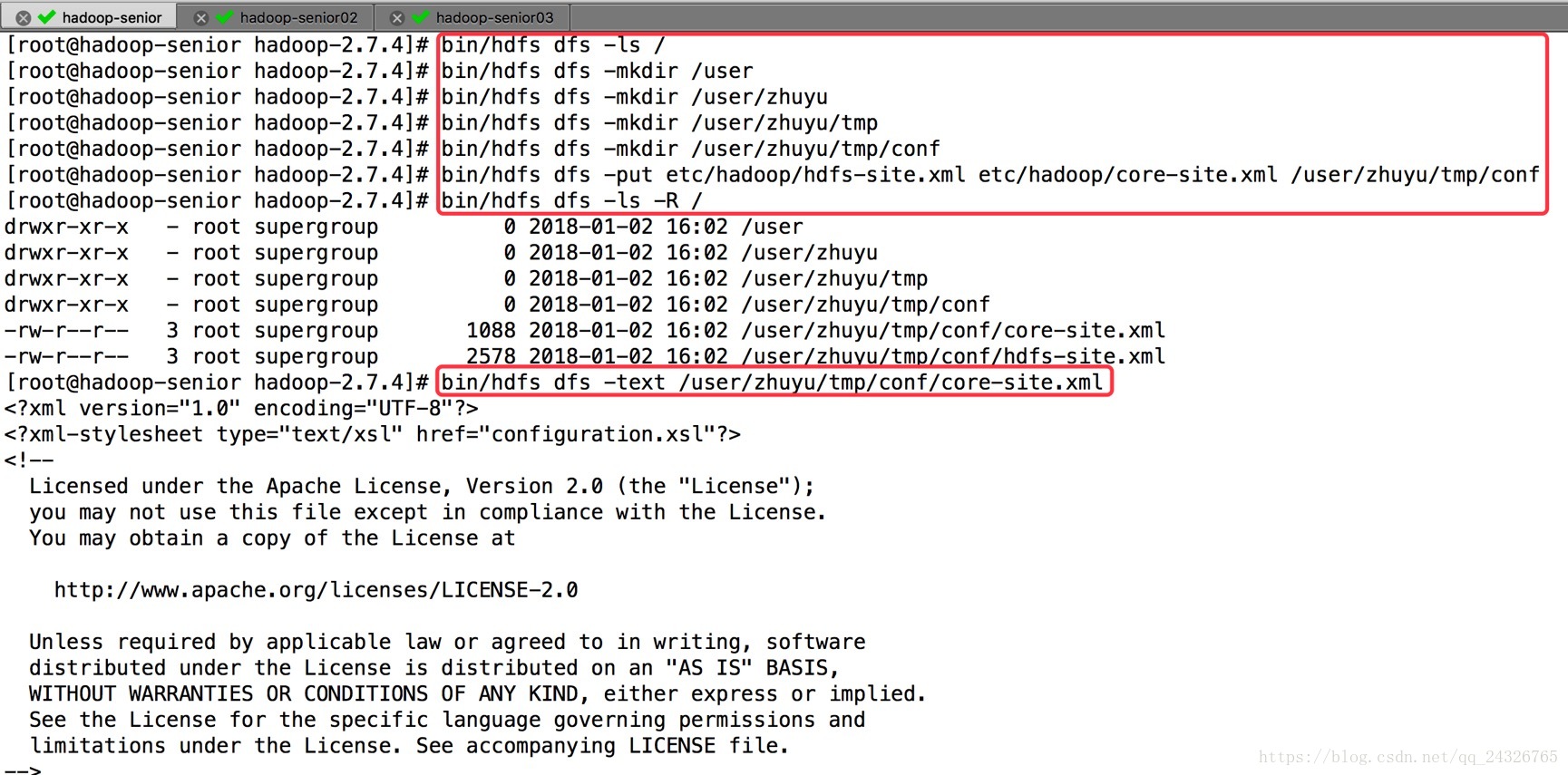
15.HDFS HA自动故障转移
手动切换状态(出故障了需要到场手动切换,太麻烦):
[root@hadoop-senior hadoop-2.7.4]#bin/hdfs haadmin –transitionToActive nn1/nn2
[root@hadoop-senior hadoop-2.7.4]#bin/hdfs haadmin –transitionToStandby nn1/nn2
自动切换状态:
Zookeeper起到的作用
* 两个namenode启动以后都是Standby
选举一个为Active
* 监控
ZKFC
FailoverController
两个namenode节点上增加了两个守护进程ZKFC:
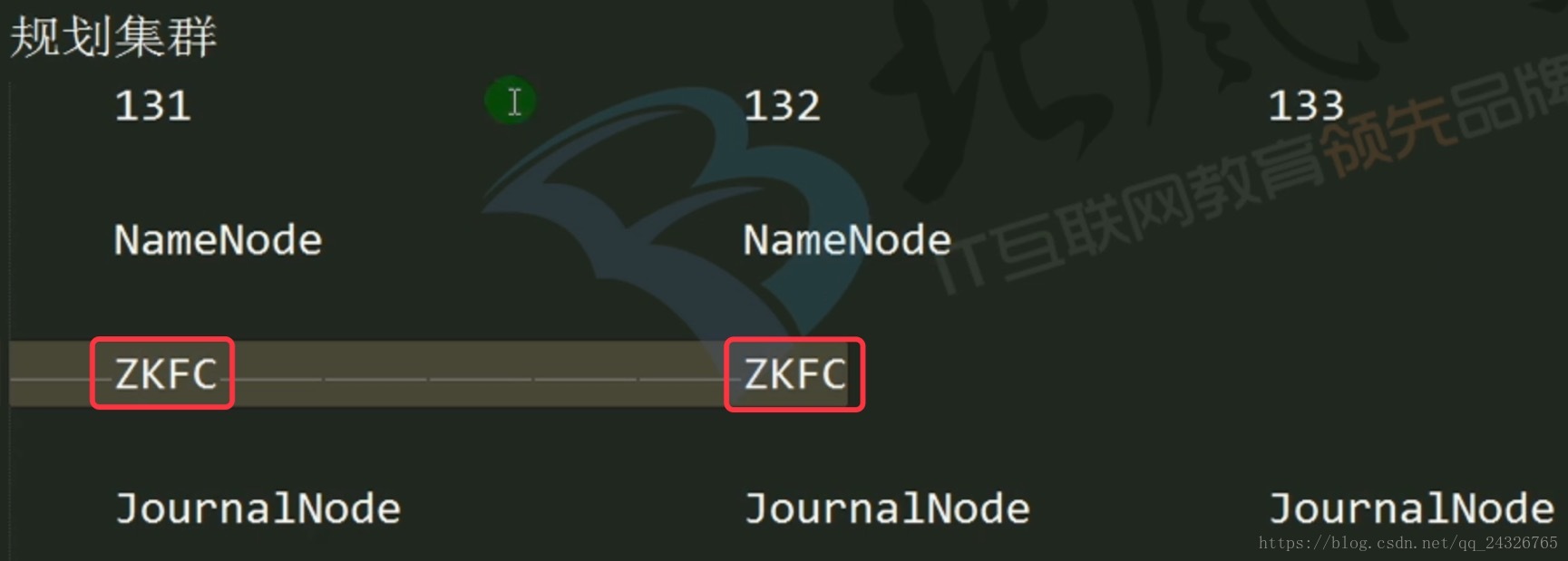
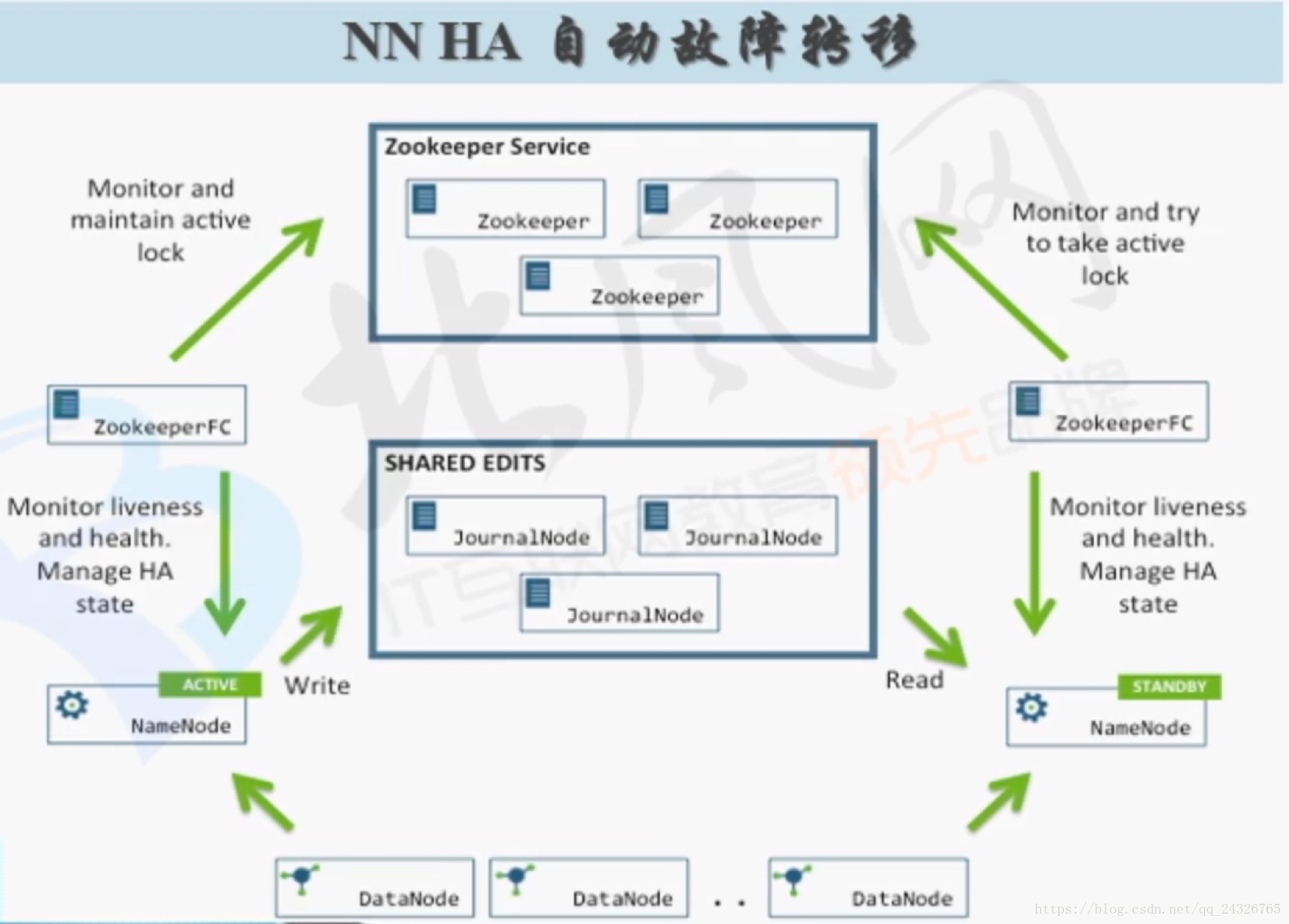
实际上zkfc就是Zookeeper的一个客户端。
① 修改配置文件
开启自动故障转移:
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property> 
设置HA的ZooKeeper服务:
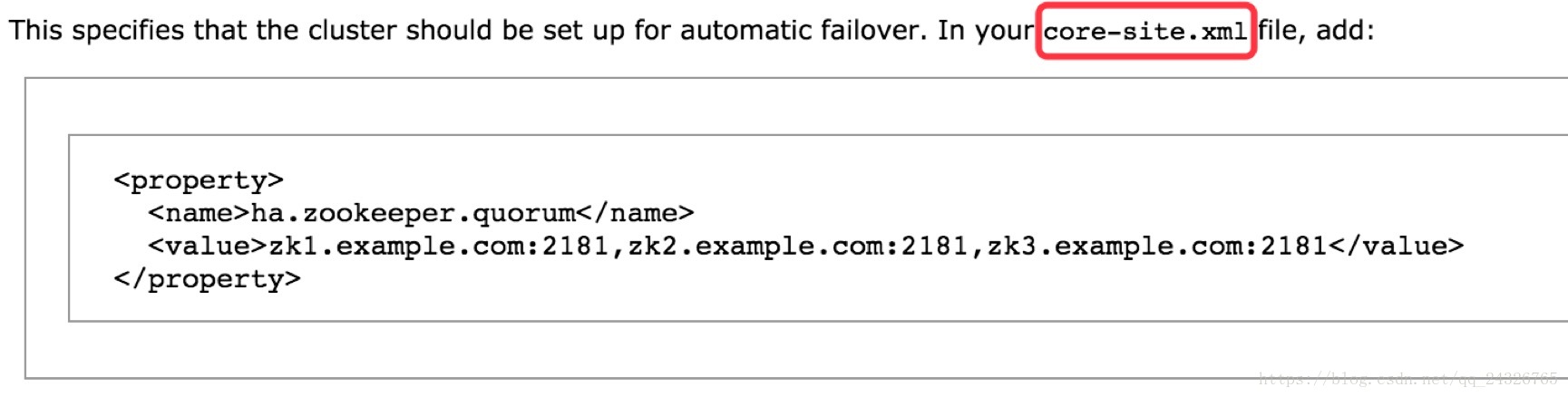
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1.example.com:2181,zk2.example.com:2181,zk3.example.com:2181</value>
</property>
② 分发
[root@hadoop-senior hadoop-2.7.4]# scp-r etc/hadoop/hdfs-site.xml etc/hadoop/core-site.xml root@hadoop-senior02:/usr/opt/modules/hadoop-2.7.4/etc/hadoop/
[root@hadoop-senior hadoop-2.7.4]# scp-r etc/hadoop/hdfs-site.xml etc/hadoop/core-site.xmlroot@hadoop-senior03:/usr/opt/modules/hadoop-2.7.4/etc/hadoop/
③ 开启一系列服务并测试

初始化HA在Zookeeper中的状态:
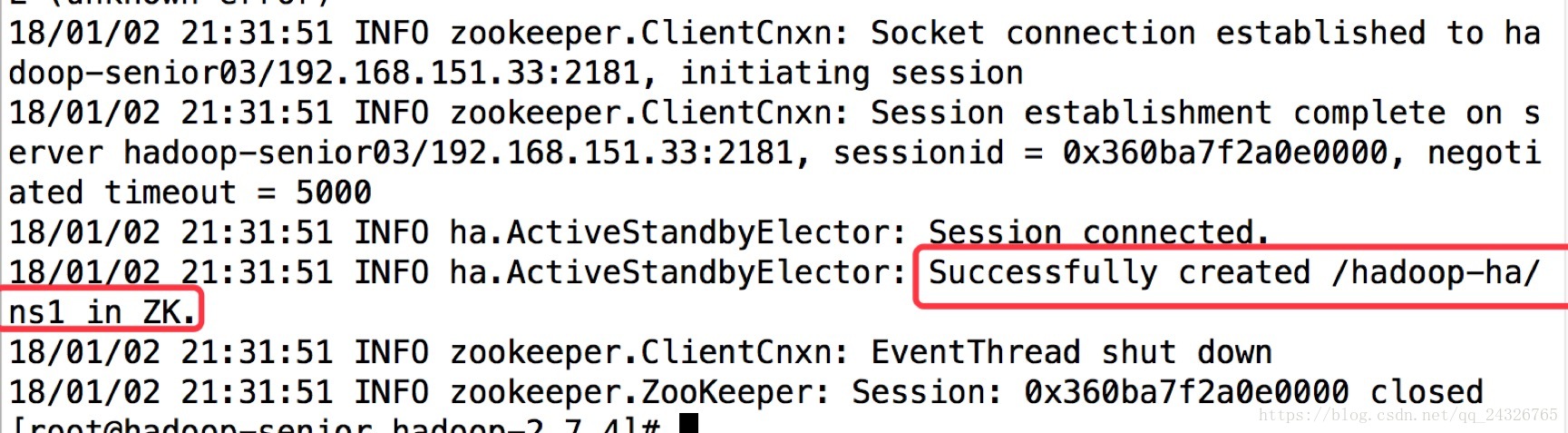
查看zookeeper的目录可发现多了hadoop-ha这个文件夹:

启动结果:
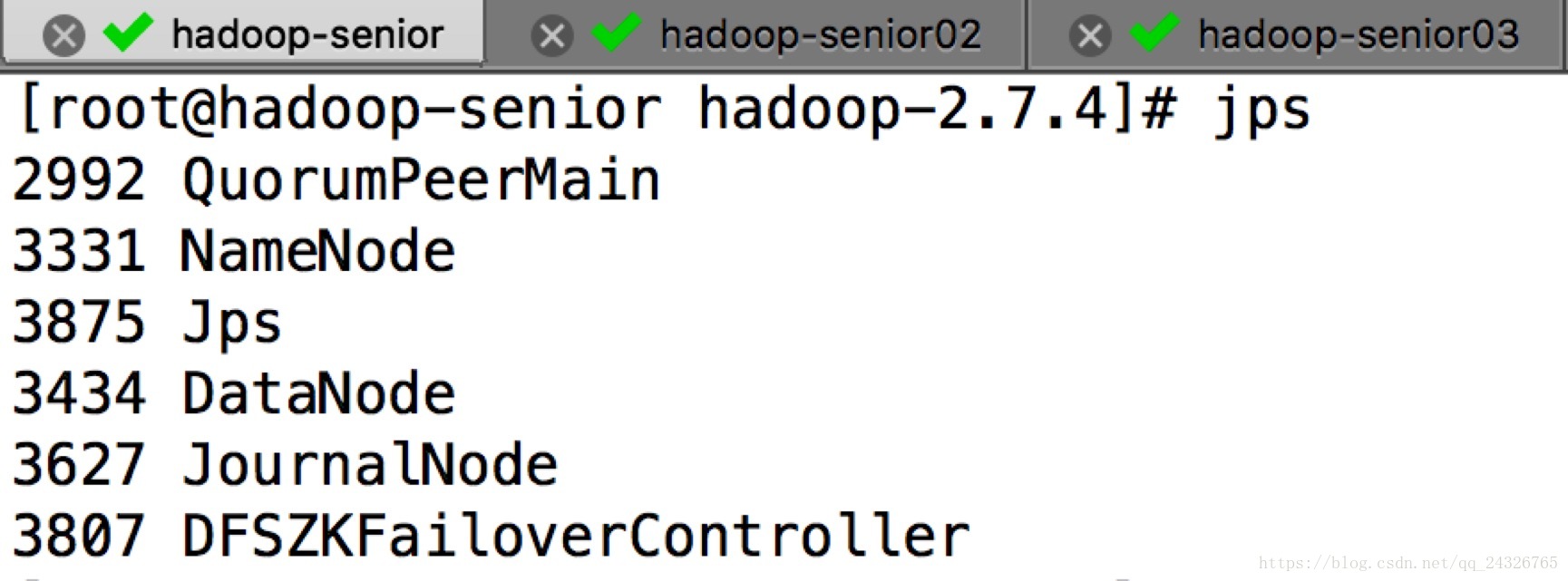
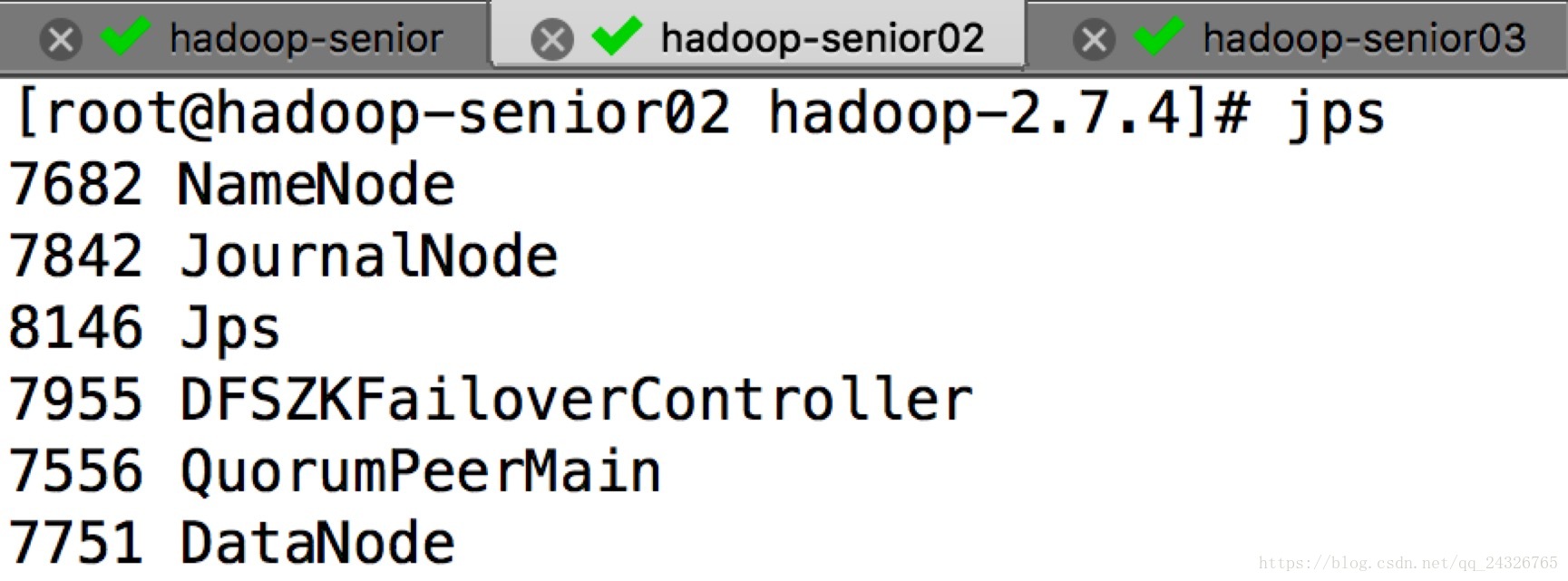
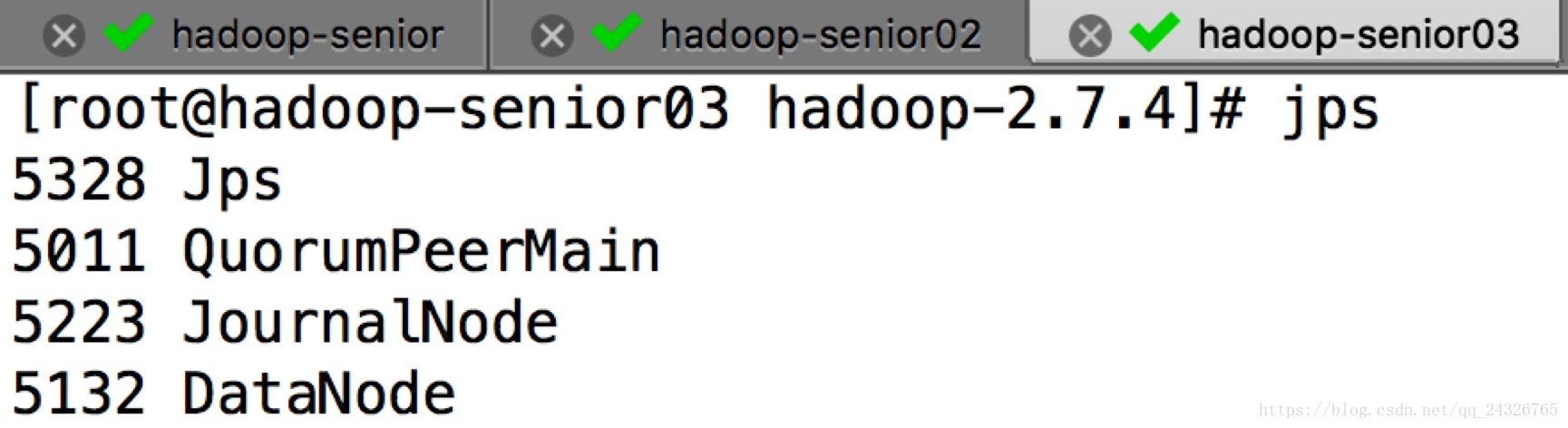
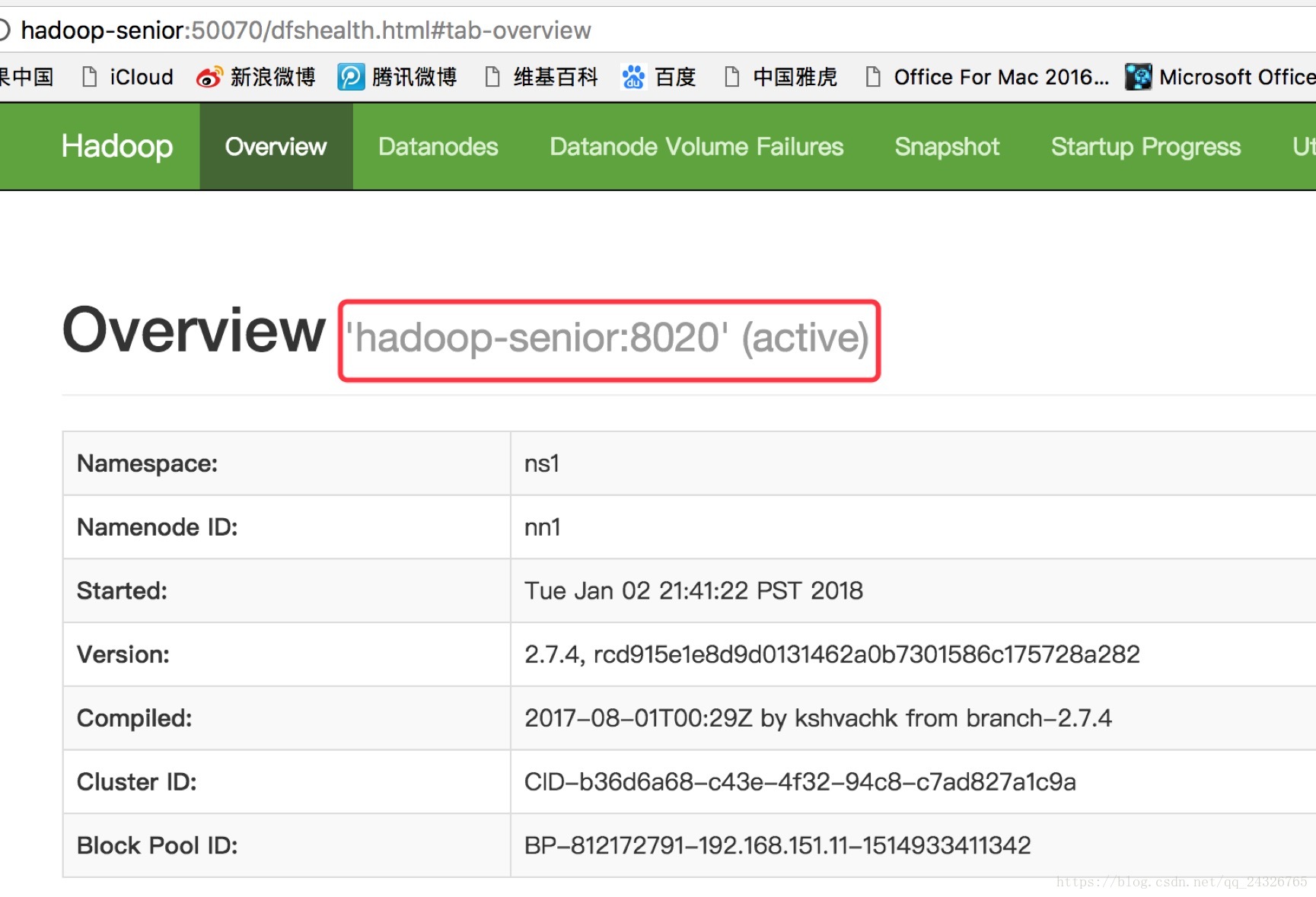
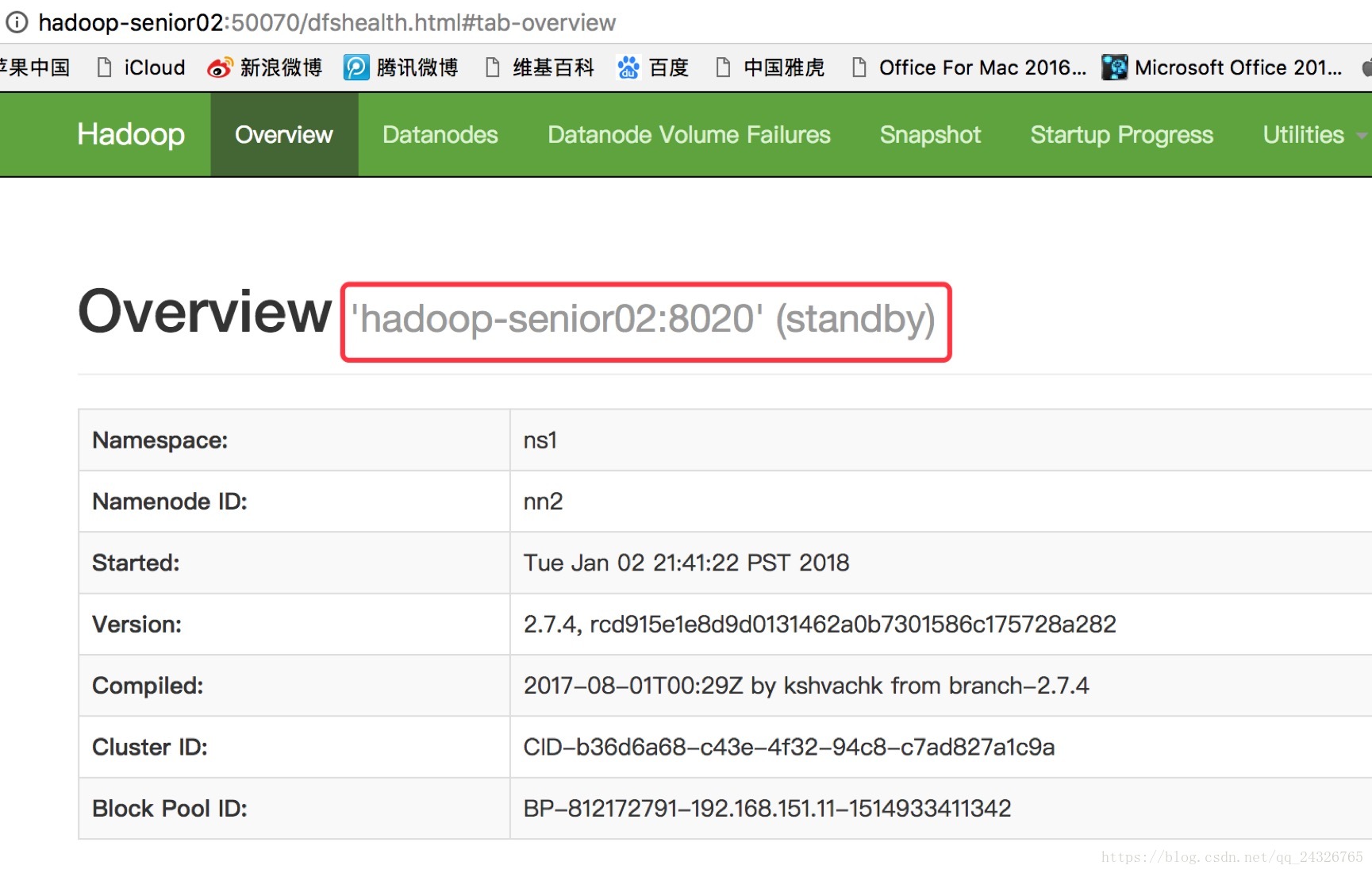
测试:
kill掉active
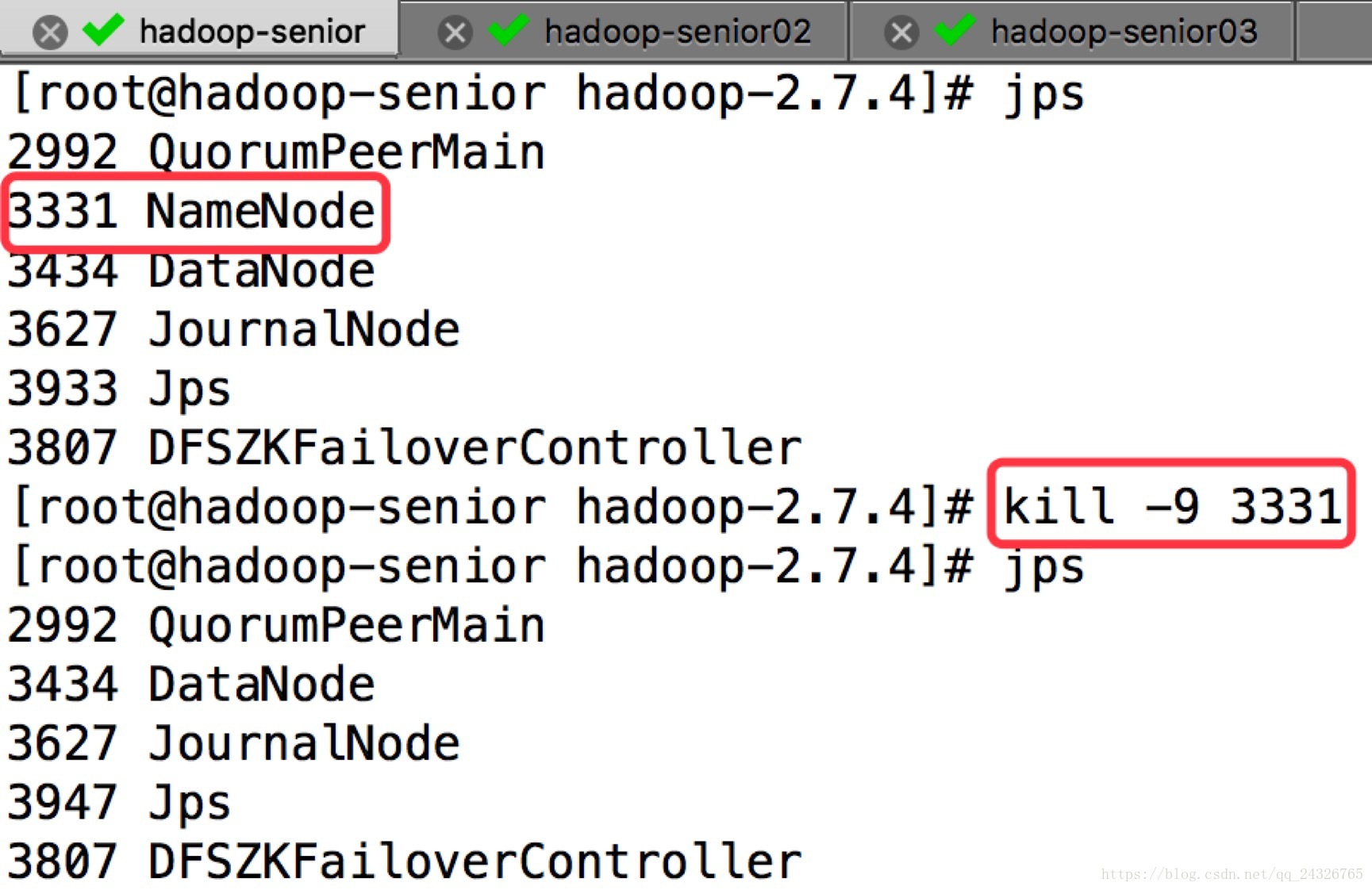
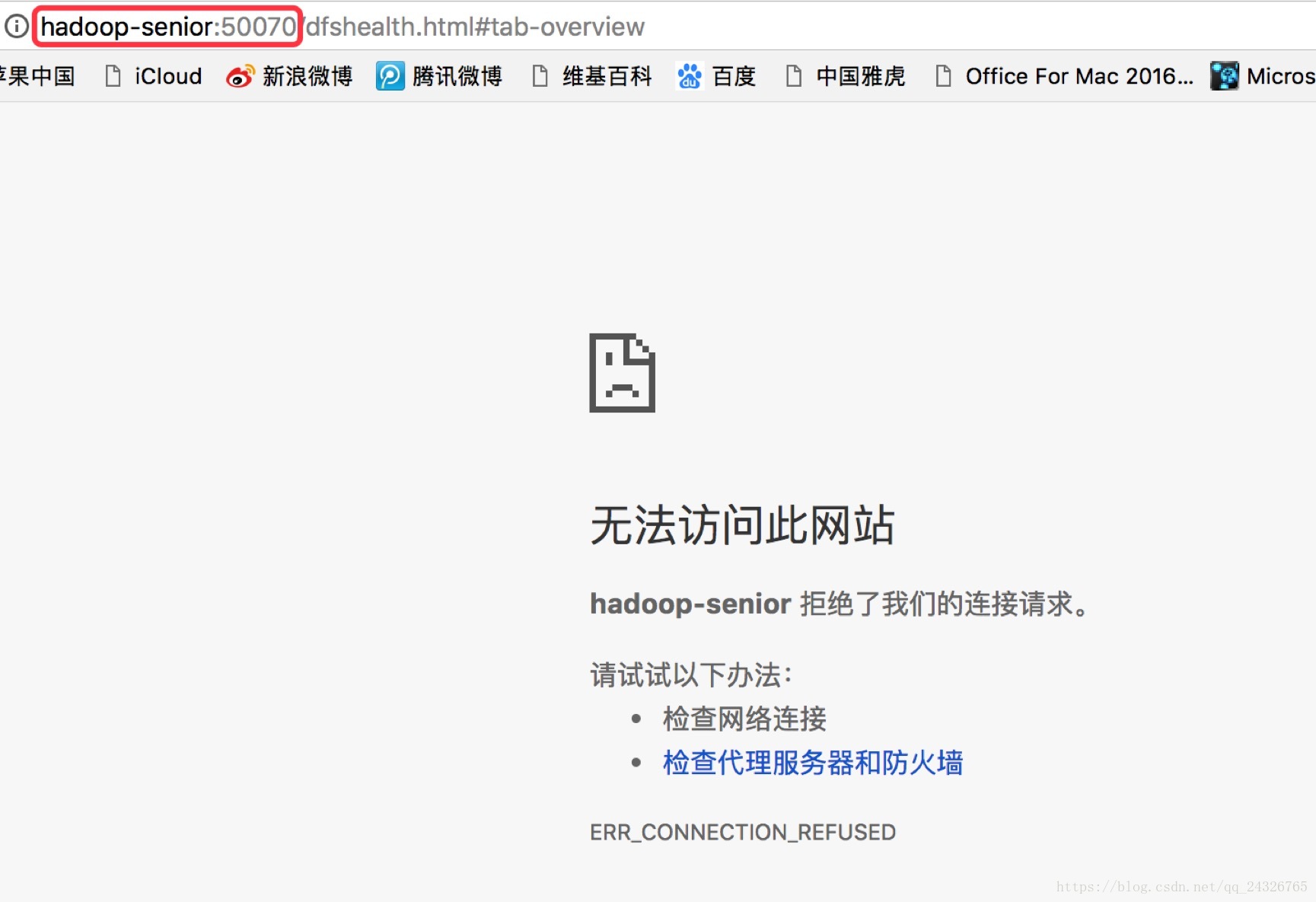
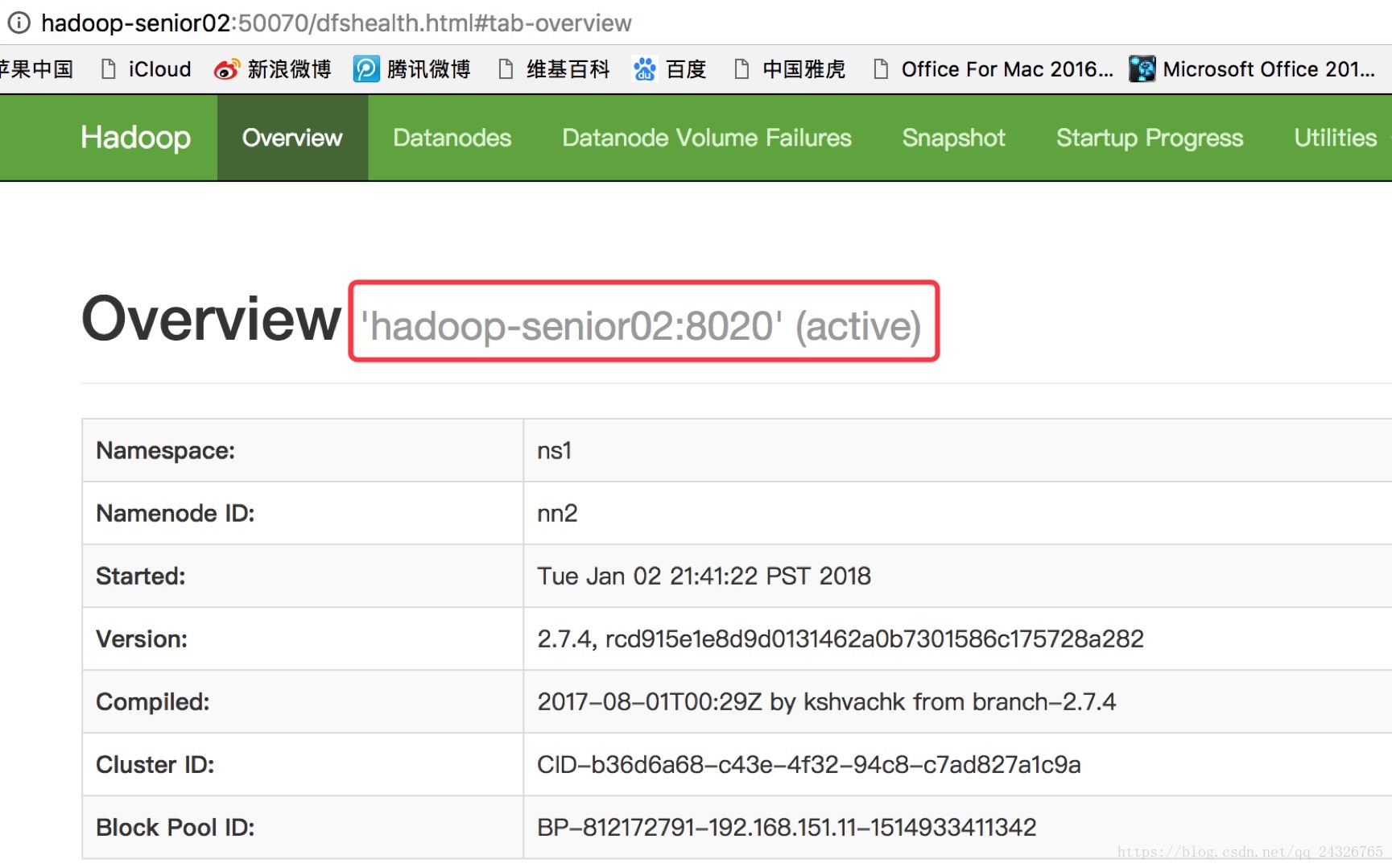
注:Zookeeper挂掉,不影响HDFS集群,只是不能故障自动转移了。
16. HDFS 2.x中高级特性
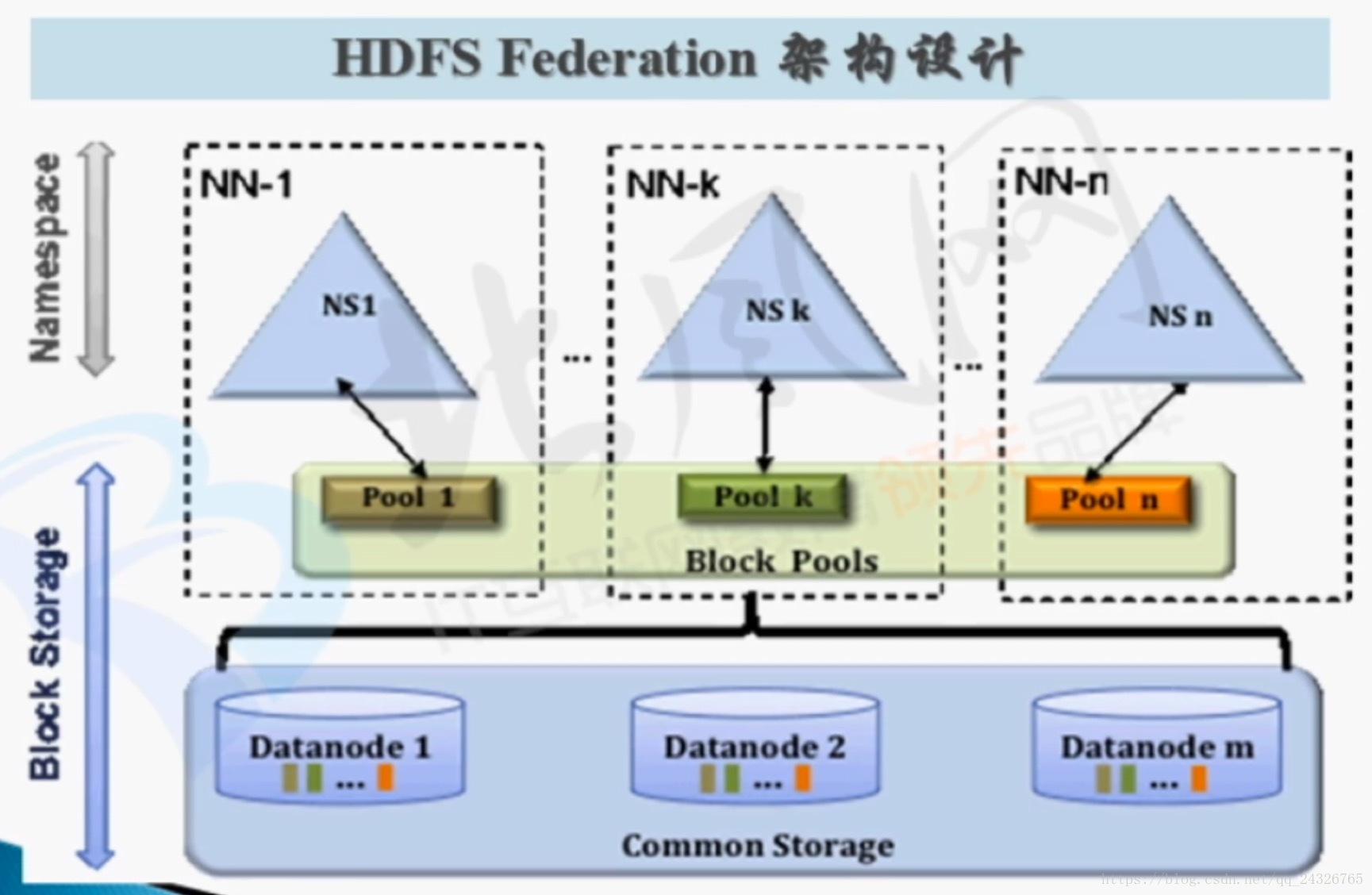
① 联邦机制(概念非常好,但用的不多,在大公司中会用)
为什么要使用联邦?



② 文件系统的快照


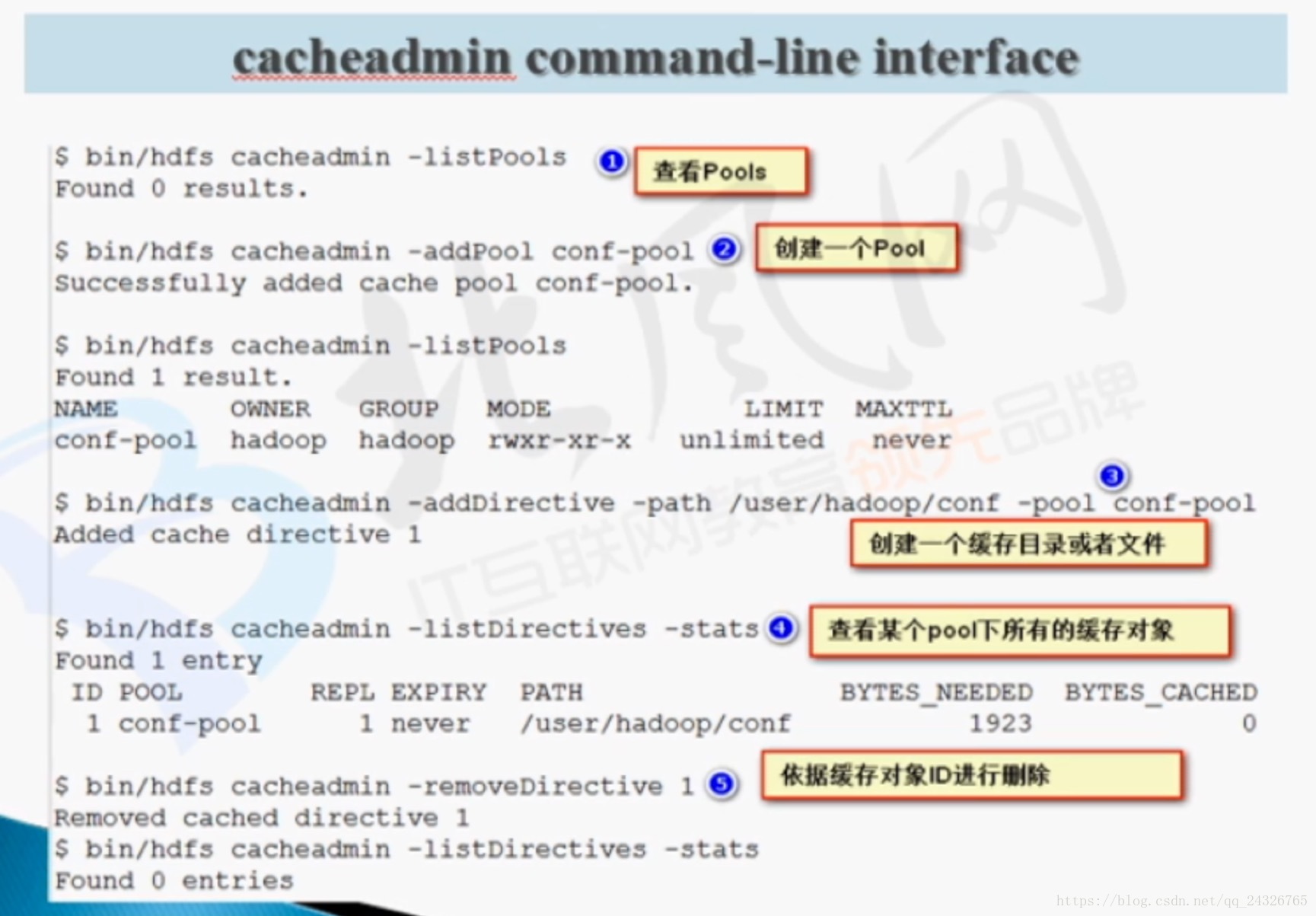
③ 集中式缓存管理


④ 集群的迁移(分布式的拷贝)
测试机群、生产集群、多个版本的Hadoop 大数据集群之间数据的迁移。

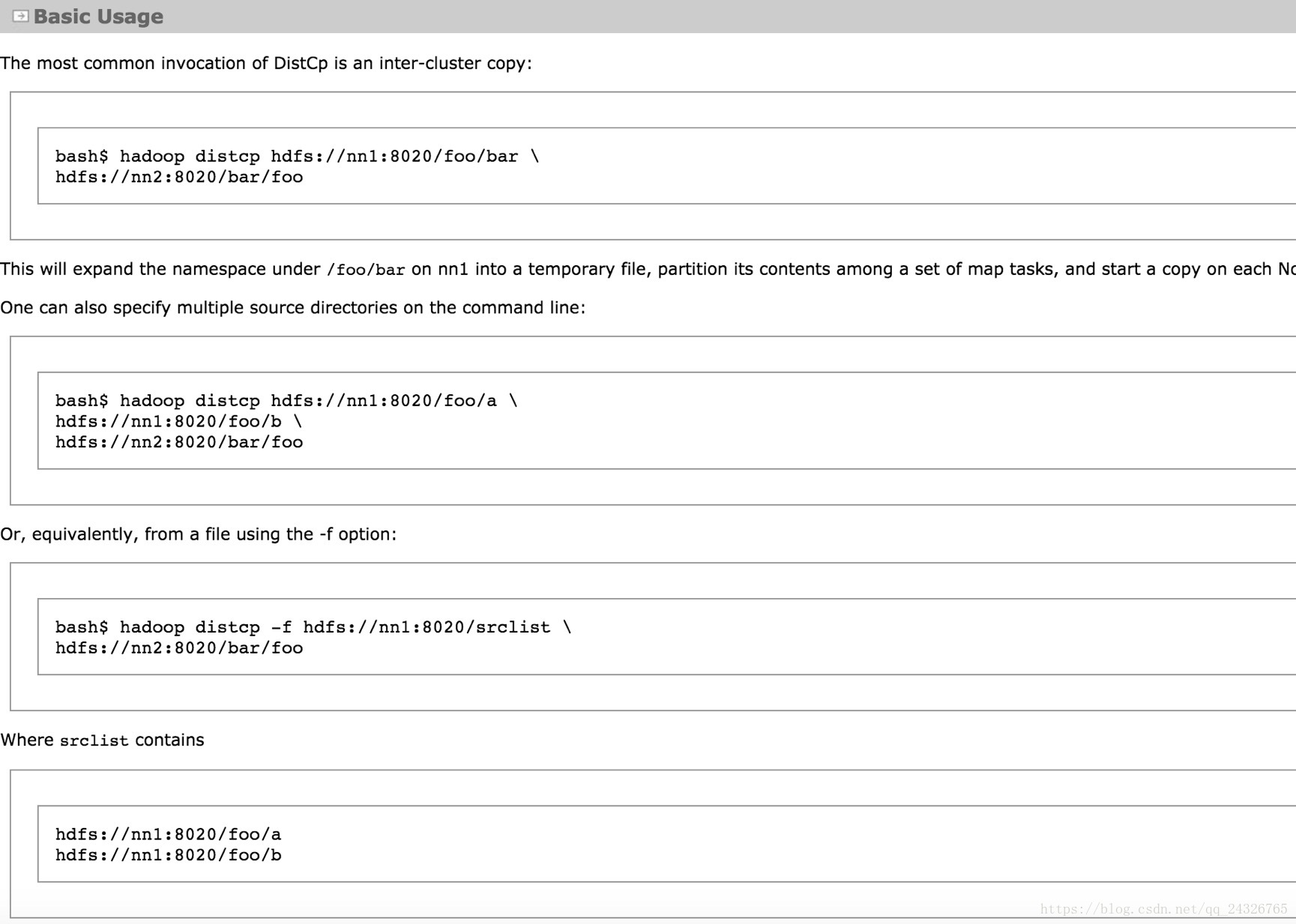
集群版本不一致的解决方案:
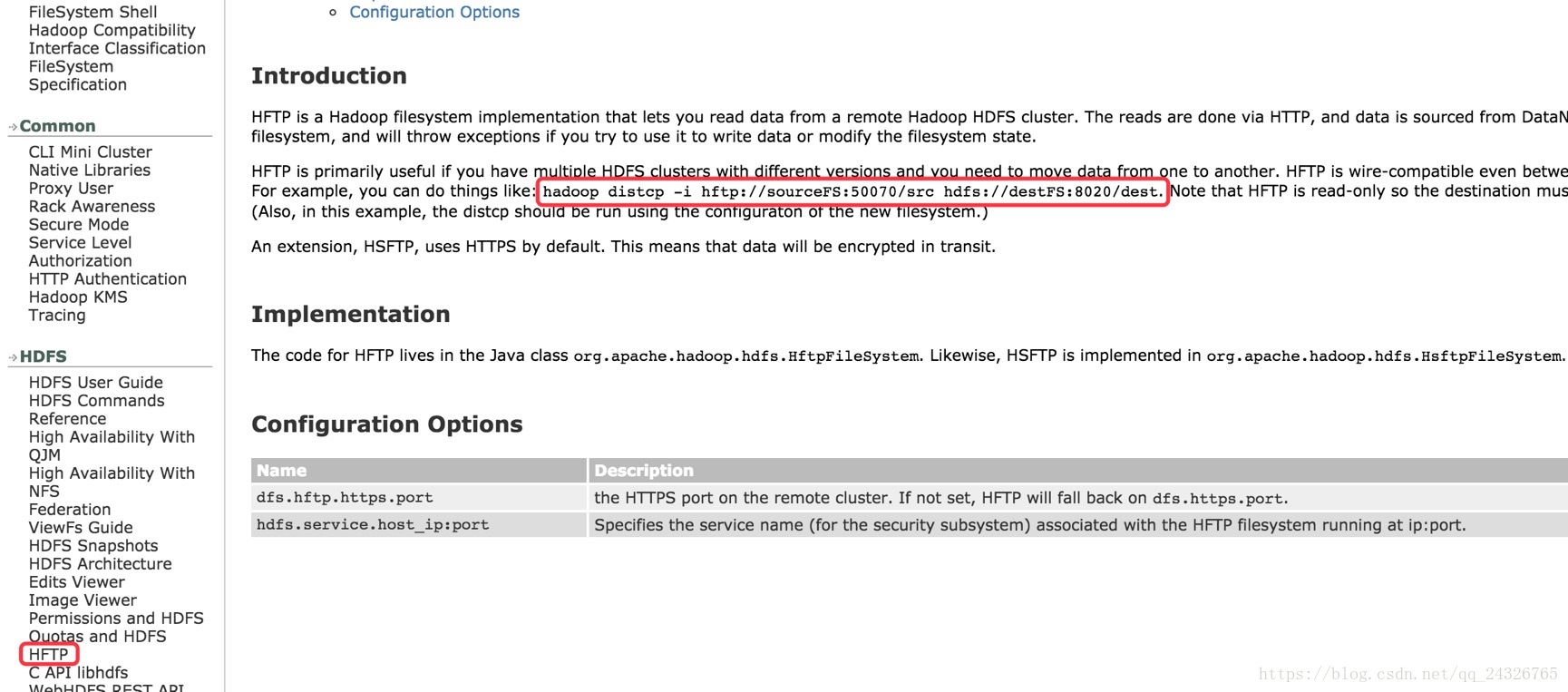
hadoop distcp -i hftp://sourceFS:50070/src hdfs://destFS:8020/dest
(底层是MapReduce)
17. YARN HA架构及RM与NMRestart讲解
目前生产集群HDFS和YARN是都做HA的。测试集群只做HDFS的HA,因为数据是最重要的,YARN坏了可以重启就行了,但是数据坏了还得修复,比较麻烦。
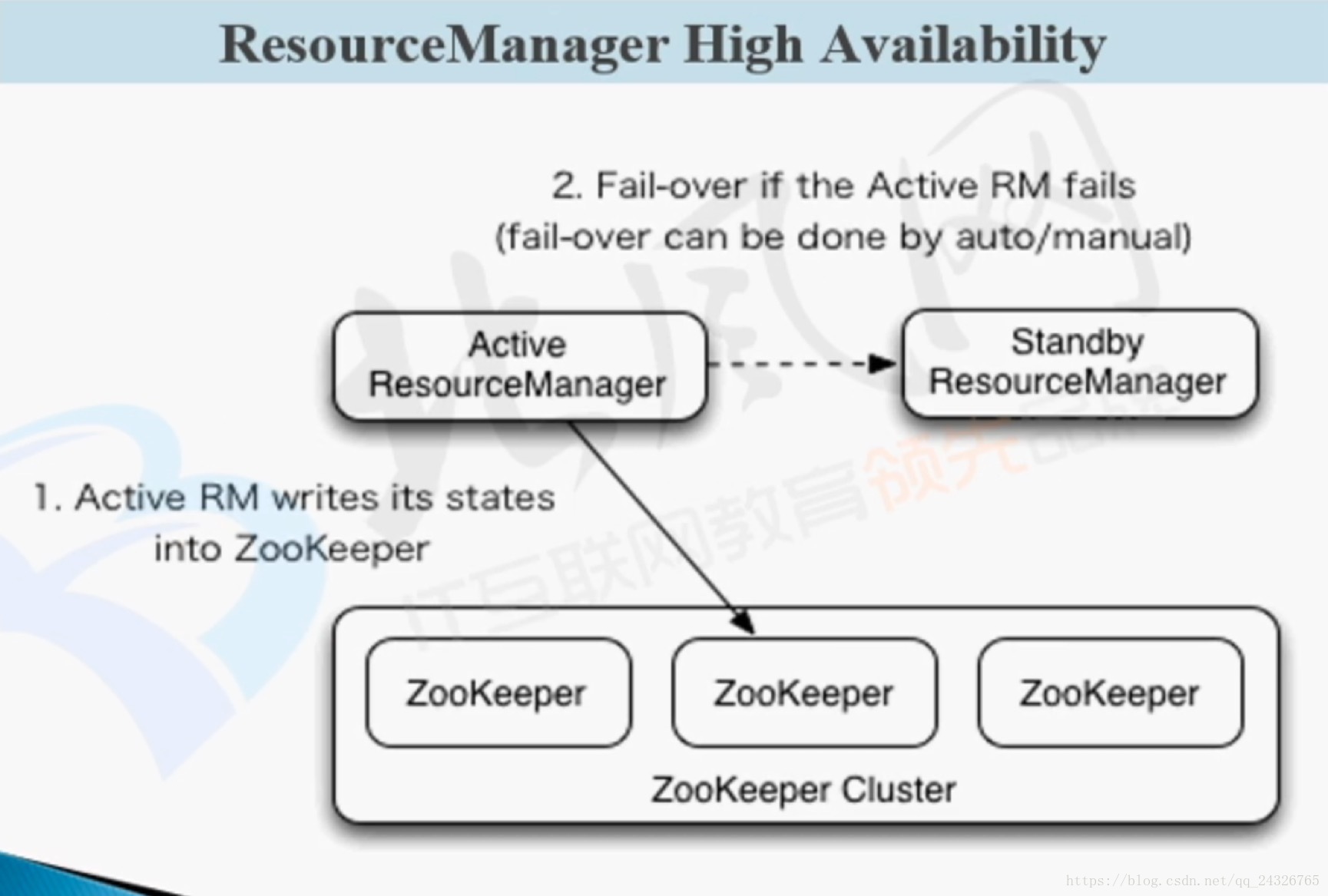
详细配置:http://hadoop.apache.org/docs/r2.7.5/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
添加配置信息:
yarn-site.xml

启动yarn后查看状态:
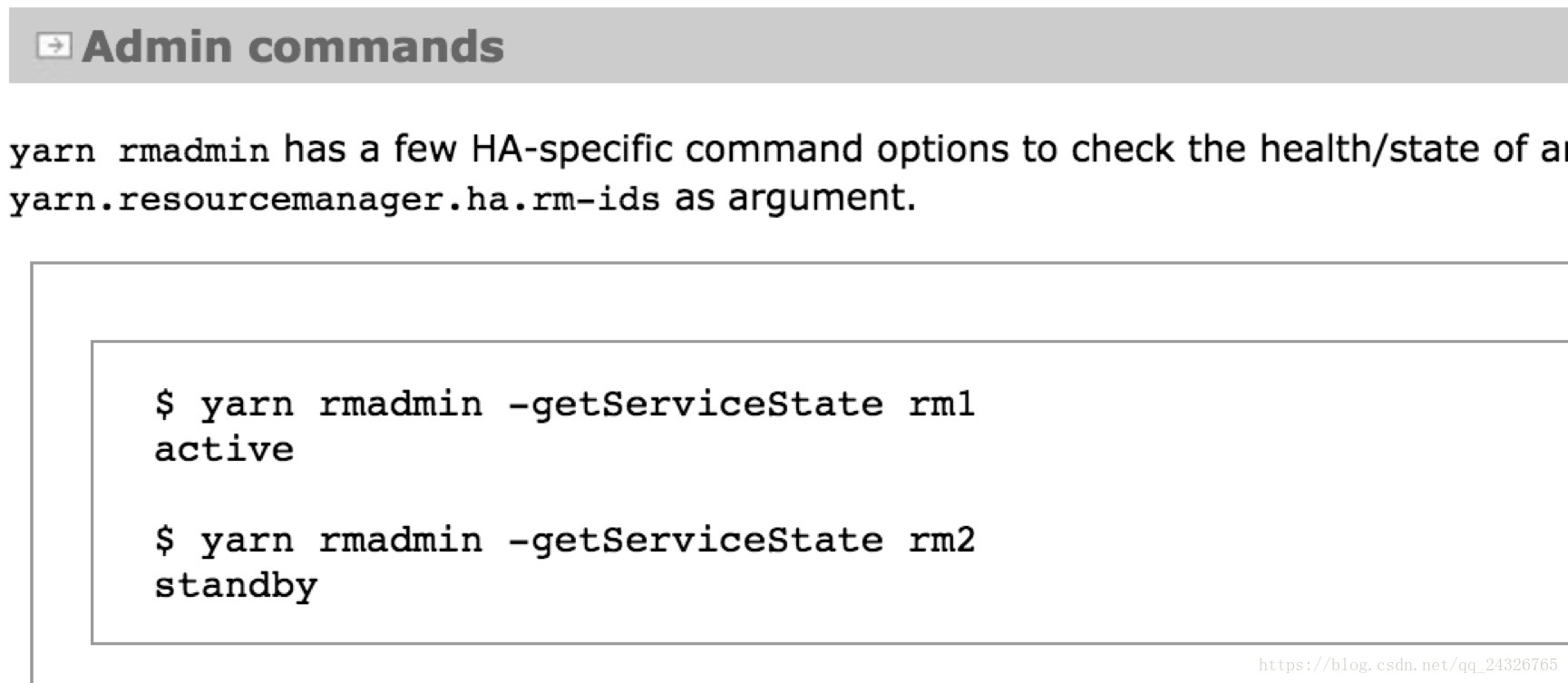
如果没有给RM HA配置zookeeper服务需要手动设置rm avtive:

18. ResourceManagerRestart和NodeManager Restart(特别有用,一般和HA结合使用)
可将任务和资源保存在一个地方,下次启动的时候,恢复上次的状态。例如,一个企业,每天100台机器,每天运行的作业量至少是上万个的,当守护进程出现故障的时候,恢复时,继续上次的作业。