四、实战应用
1. 【基于HDFS云盘存储系统】架构设计及秒速上传功能分析

① 网盘的增删改查即文件大小和日期都可通过hdfs dfs实现
② 相同的文件只保存一份。给用户显示的只是图标、链接。
③ 极速秒传
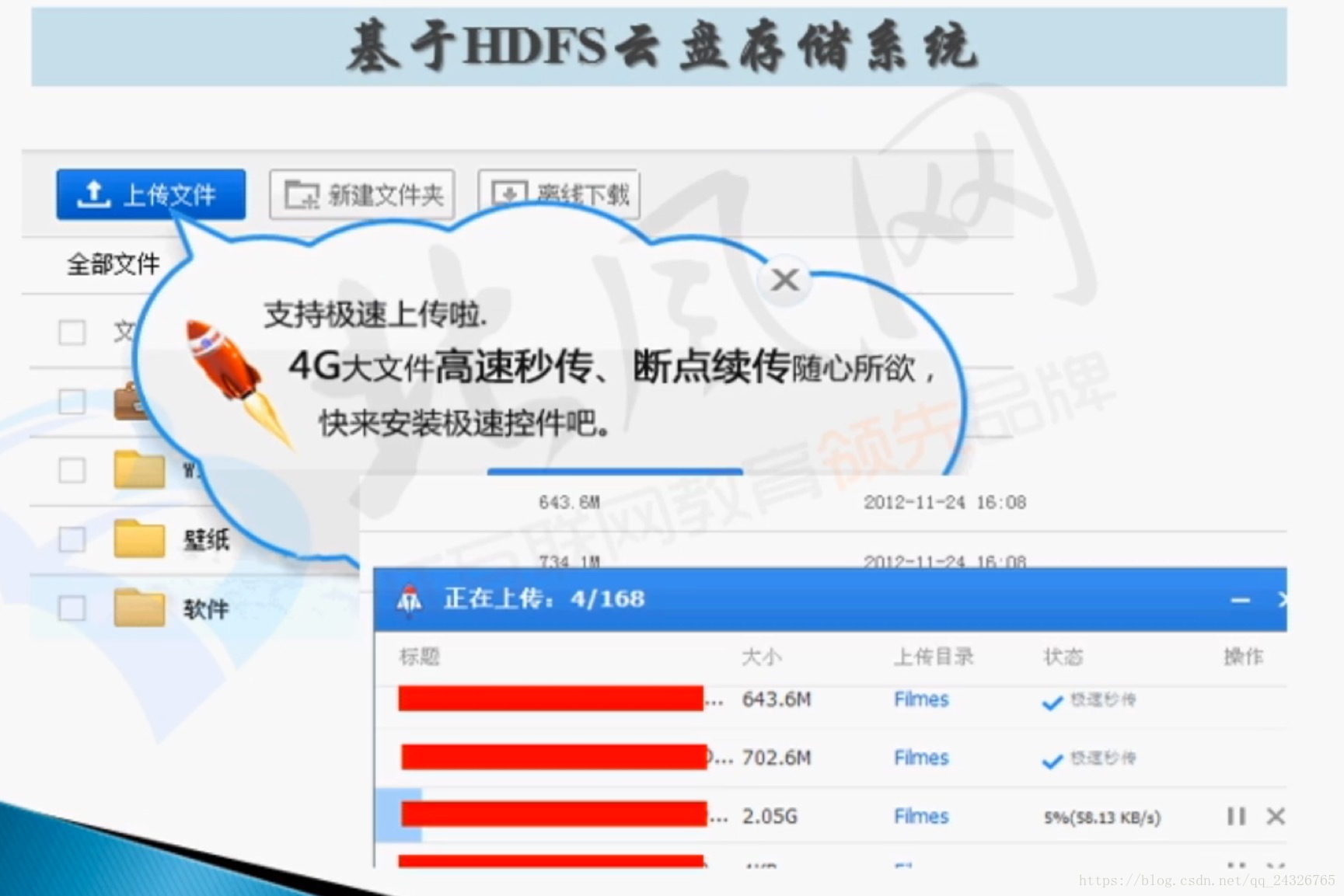
系统为每个文件生成一个hash码,把这个值上传到系统,系统在库里匹配有没有和这个值相对应的文件,有的话,就建立连接,实际上并没有上传。
④ 文件的相关信息存到HBase中
2. Hadoop 三大发行版本


CDH(Cloudera's Distribution, including Apache Hadoop)

HDP(Hortonworks Data Platform)

3. 项目实战之一【北风用户行为日志】项目数据文件的分析
北风网一天的日志量:10G
一般电商的日志量:30G – 50G

Nginx服务器:
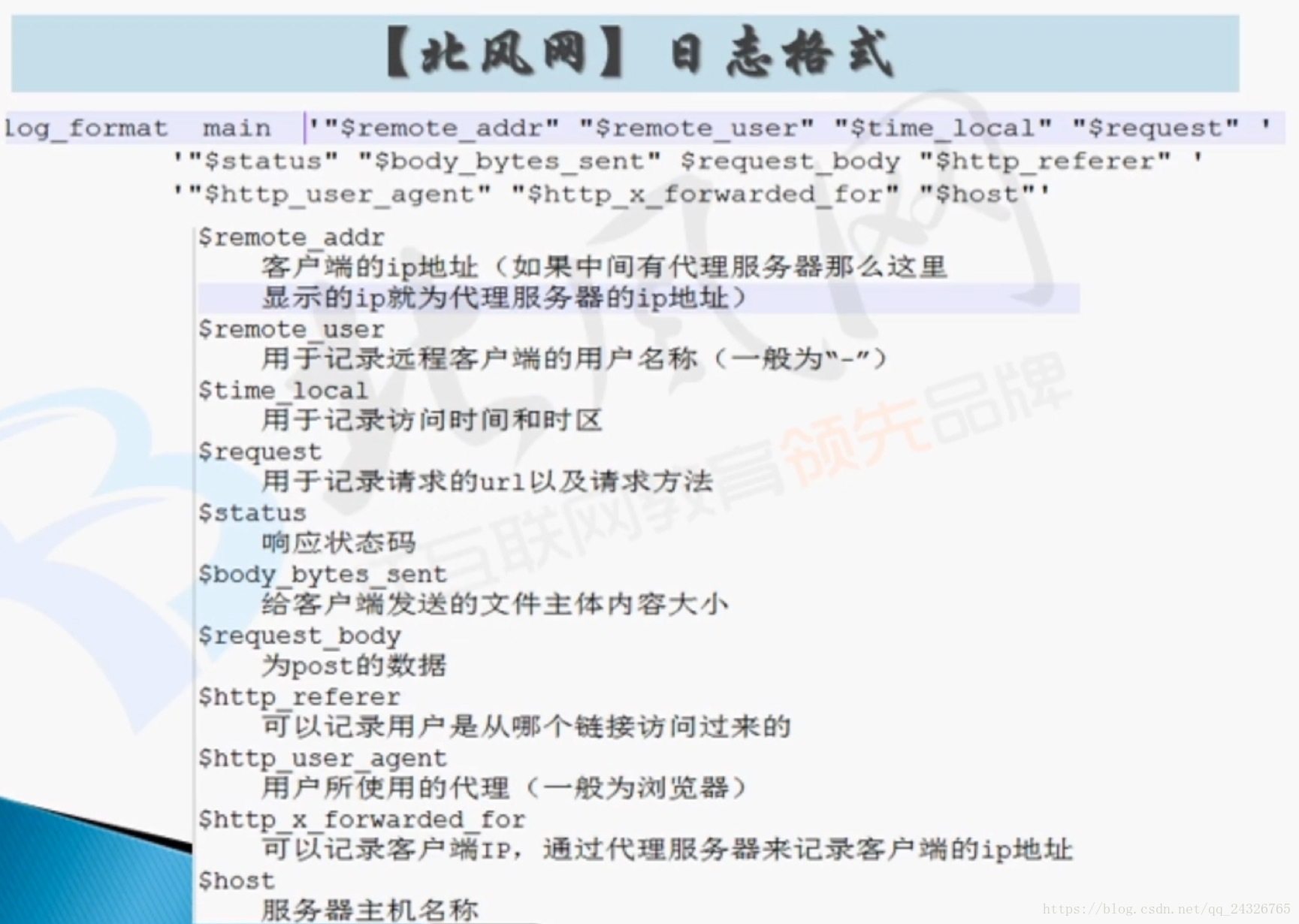
举例:
"27.38.5.159" "-""31/Aug/2015:00:04:37 +0800" "GET /course/view.php?id=27HTTP/1.1" "303" "440" -"http://www.ibeifeng.com/user.php?act=mycourse" "Mozilla/5.0(Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63Safari/537.36" "-" "learn.ibeifeng.com"
数据清洗:
日志数据往往会出现不合格的情况,如果不清洗,应用程序最常见的会出现空指针异常。所以需要数据清洗(最常用的方式--------MapReduce)。
4.项目实战之二业务需求之IP地址分析、访问时间、请求地址等分析及搜索推荐功能分析
① IP地址分析

(一般根据前两段就可以确定)
案例:
北风给百度钱做推广,比如说当北京或上海的ip搜索hadoop时,让百度显示第一个链接是北风网。
② 访问时间分析

(每天的访问的时间是最重要;其次是日期,看是否是节假日)
北风销售人数:40-50人
③ 请求地址分析

案例:

实时统计访问量最多的关键字。

④ 转入链接分析

北风网是8台机器在做以上的所有分析,24G内存,5T磁盘,8核的CPU。
5. 项目实战之四日志文件数据存储、收集、预处理和分析
① 数据存储


② 数据收集

* 定时收集:写程序,每天定时将文件上传到HDFS上(put)
* 实时收集:flume
* shell脚本
③ 数据预处理和分析

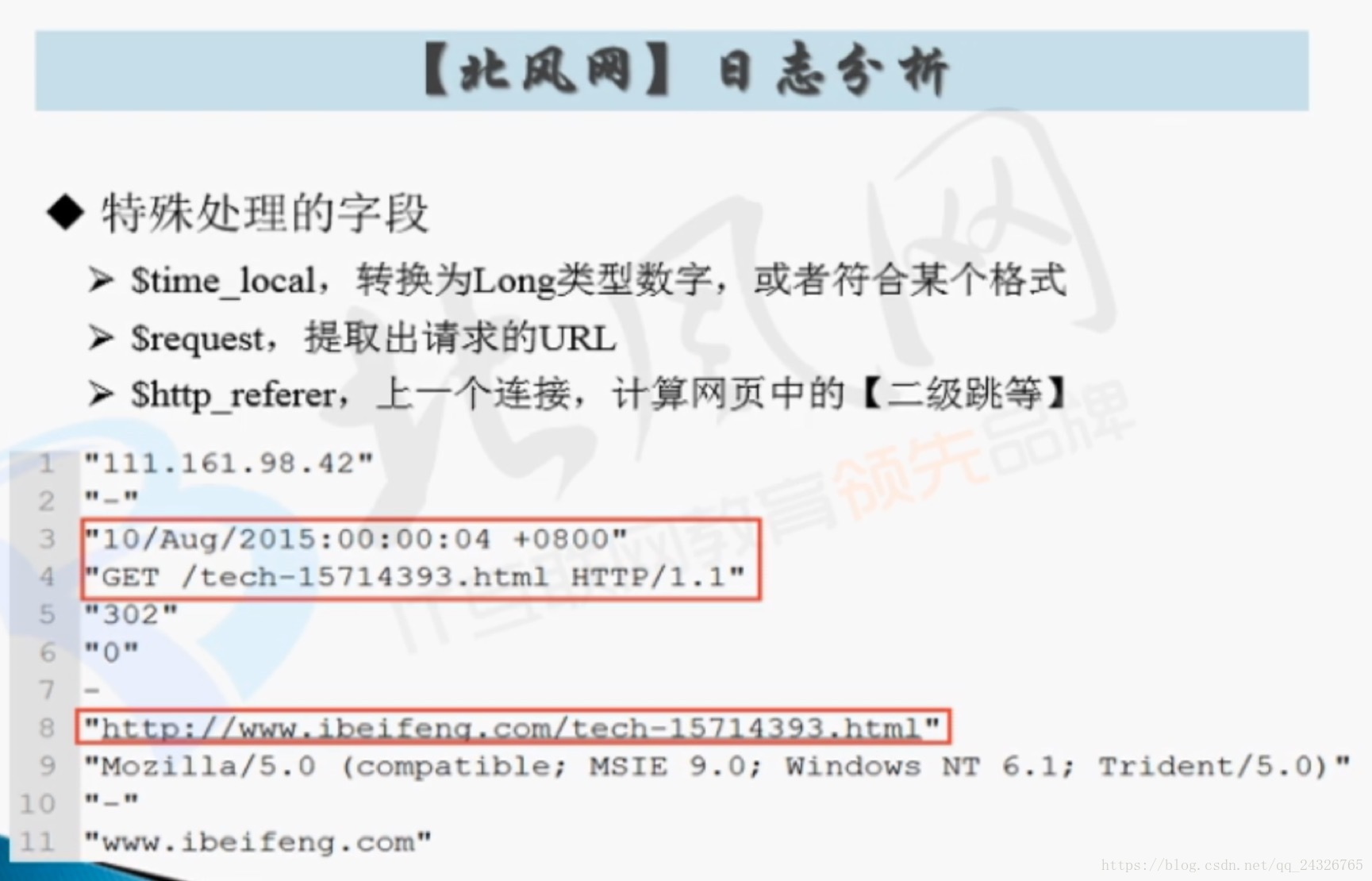
* 预处理
* MapReduce
* Hive
* 处理
*MapReduce
④ 对结果集进行处理
* 处理成数据格式
* json
* 导入到关系型数据库中(RDBMS)
⑤ 展示数据
* 报表工具,进行展示
DAAS:数据即服务(数据做为一种服务是通过传递有用的信息以帮助他人的活动来实现的)
五、附录:
文件位置规范:
/opt
modules 安装位置
software 软件下载位置
datas 数据文件位置