一、前馈神经网络的缺点
- 每次网络的输出只依赖当前的输入,没有考虑不同时刻输入的相互影响
- 输入和输出的维度都是固定的,没有考虑到序列结构数据长度的不固定性
二、循环神经网络(RNN)
1、RNN 介绍
循环神经网络(Recurrent Neural Network,RNN)是一类专门用于处理时序数据样本的神经网络,它的每一层不仅输出给下一层,同时还输出一个
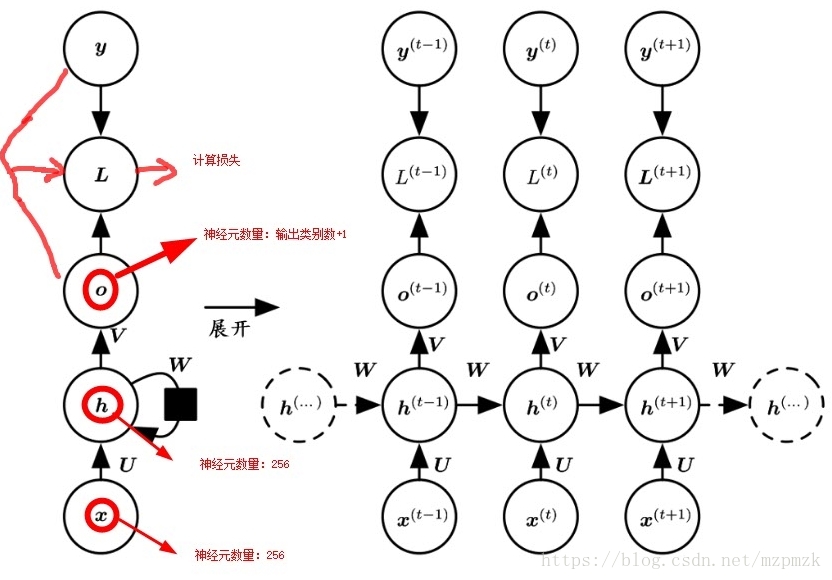
隐状态,给当前层在处理下一个样本时使用。就像卷积神经网络可以很容易地扩展到具有很大宽度和高度的图像,而且一些卷积神经网络还可以处理不同尺寸的图像,循环神经网络可以扩展到更长的序列数据,而且大多数的循环神经网络可以处理序列长度不同的数据(for 循环,变量长度可变)。它可以看作是带自循环反馈的全连接神经网络。其网络结构如下图所示。
其中 是输入序列(长度为 ), 是隐藏层序列, 是输出序列, 是总体损失, 是目标标签序列, 是
输入层到隐藏层的参数矩阵, 是隐藏层到隐藏层的自循环参数矩阵, 是隐藏层到输出层的参数矩阵。值得注意的是:图中输入节点数(不止一个)、隐藏节点数、输出节点数都是用一个小圆圈表示的,它们之前是全连接的,且在隐藏层之间加了一个自循环反馈(通过权重共享),这也是它能够处理不同序列长度数据的原因。其具体计算流程如下:- 前向传播:公式如下所示,其中,输入层到隐藏层使用双曲正切激活函数(tanh),隐藏层到输出层使用 softmax 将输出映射为 (0, 1) 的概率分布。按时间序列递减的方式反复把第一个公式带入到它本身中,我们将会看到当前时刻隐藏层的输出值不仅受当前时刻输入
的影响,还受到过去所有时刻输入
的影响,如此一来,
隐藏层的输出值(h)就可以看作是网络的记忆,这使得它非常适合处理前后有依赖关系数据样本。
- 损失函数:公式如下所示,一般可使用交叉熵来计算某个时刻
在所有
个样本上的损失,整体的损失值则为所有时刻损失之和
- 前向传播:公式如下所示,其中,输入层到隐藏层使用双曲正切激活函数(tanh),隐藏层到输出层使用 softmax 将输出映射为 (0, 1) 的概率分布。按时间序列递减的方式反复把第一个公式带入到它本身中,我们将会看到当前时刻隐藏层的输出值不仅受当前时刻输入
的影响,还受到过去所有时刻输入
的影响,如此一来,
循环神经网络的一个重要特性是:
在不同时刻,模型的参数是共享的,这使得我们可以在时间上共享不同位置的统计强度。当序列数据中的某些部分会在多个位置出现时,这种参数共享机制就显得尤为重要了。例如,在两个车牌“皖F.WY656”和“沪A.F6661”中 “F”分别出现在第 位和第 位,我们希望模型通过参数共享机制可以学习到字母 “F” 的抽象特征,从而无论这个字母出现在什么位置,模型都能够识别它。其参数可以通过时序反向传播算法(Back-Propagation Through Time,BPTT)来学习,每一次参数更新用到的梯度都是所有时刻梯度之和。
2、RNN 的结构类型
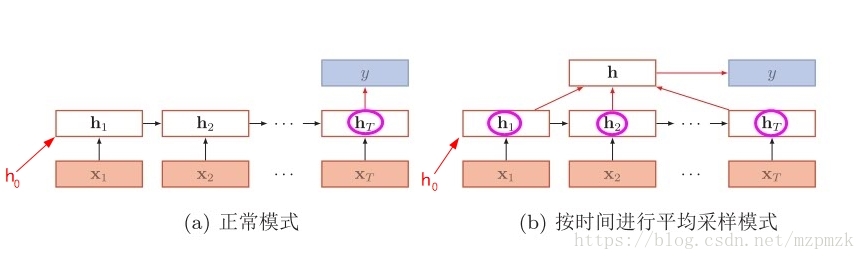
序列分类(N VS 1)
- 输入是一个序列,输出是一个单独的值而不是序列,这种结构通常用来处理序列分类问题。如输入一段文字判别它所属的类别,输入一个句子判断其情感倾向,输入一段视频并判断它的类别等等。
- 可以对最后一个 h 进行输出变换,或对所有的 h 进行平均后再进行输出变换
- 注意:
初始状态神经元的数量必定和隐层神经元的数量一致
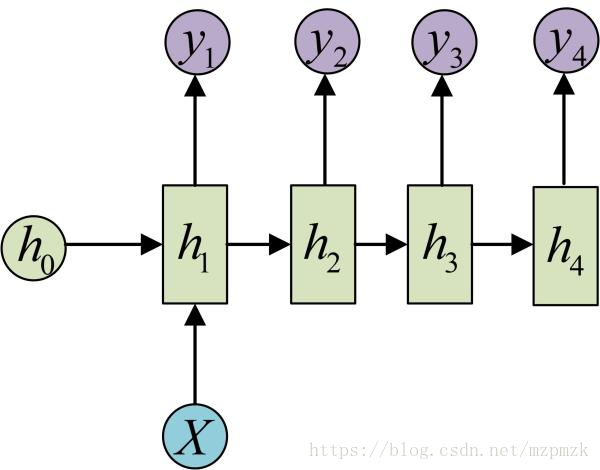
RNN (1 VS N)- 这种1 VS N 的结构可以处理的问题有:
- 从图像生成文字(image caption),此时输入的X就是图像的特征,而输出的y序列就是一段句子
- 从类别生成语音或音乐等
只在序列开始进行输入计算,其它 time step 输入为 0
把输入信息X作为每个阶段的输入
- 这种1 VS N 的结构可以处理的问题有:
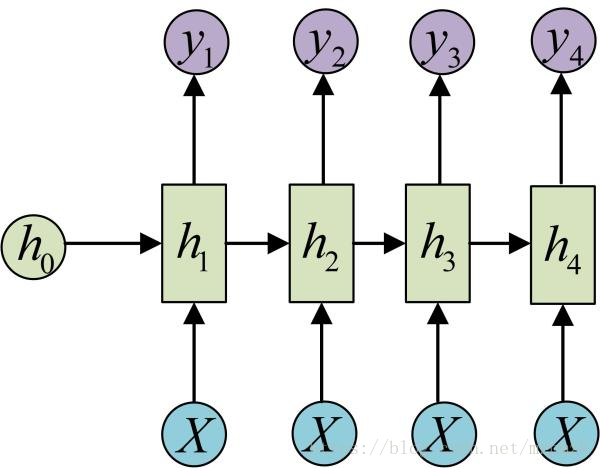
同步的序列到序列的模式(N VS N)- 最经典RNN结构要求
输入和输出序列必须要是等长的。 - 由于这个限制的存在,经典RNN的适用范围比较小,但也有一些问题适合用经典的RNN结构建模,如:计算视频中每一帧的分类标签。因为要对每一帧进行计算,因此输入和输出序列等长。
- 最经典RNN结构要求
异步的序列到序列的模式(N VS M)- 这种 N vs M 的结构又叫
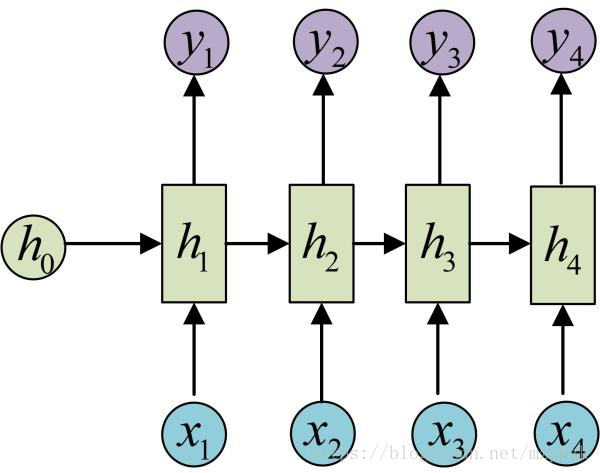
Encoder-Decoder模型,也可称之为Seq2Seq模型。原始的 N vs N RNN 要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。Encoder-Decoder 模型可以有效的建模输入序列和输出序列不等长的问题,具体步骤如下:
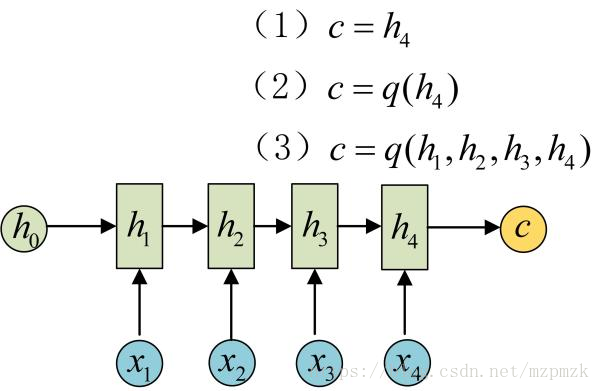
- 首先,用一个 Encoder(RNN) 将输入的序列
编码为一个上下文向量c。得到 c 有多种方式,最简单的方法就是把 Encode r的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到 c,也可以对所有的隐状态做变换 到 c。
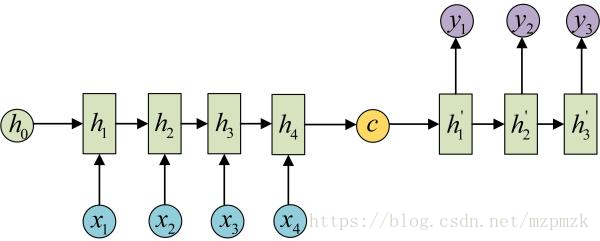
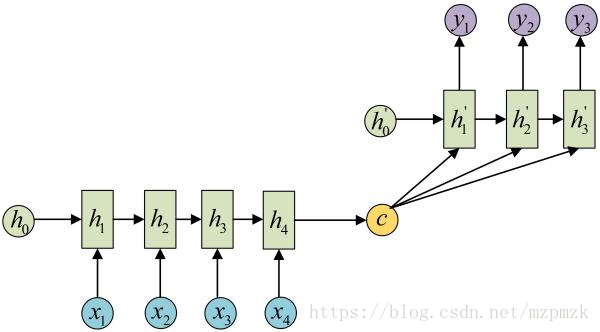
- 然后,用一个 Decoder(另一个RNN) 对
c进行解码,将其变成输出序列。可以将 c 当做之前的初始状态 h0 输入到Decoder,也可以将 c 当做每一步的输入
- 首先,用一个 Encoder(RNN) 将输入的序列
- 由于这种 Encoder-Decoder 结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:
- 机器翻译:Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出的
- 文本摘要:输入是一段文本序列,输出是这段文本序列的摘要序列。
- 阅读理解:将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
- 语音识别:输入是语音信号序列,输出是文字序列。
- 这种 N vs M 的结构又叫
3、RNN 分类
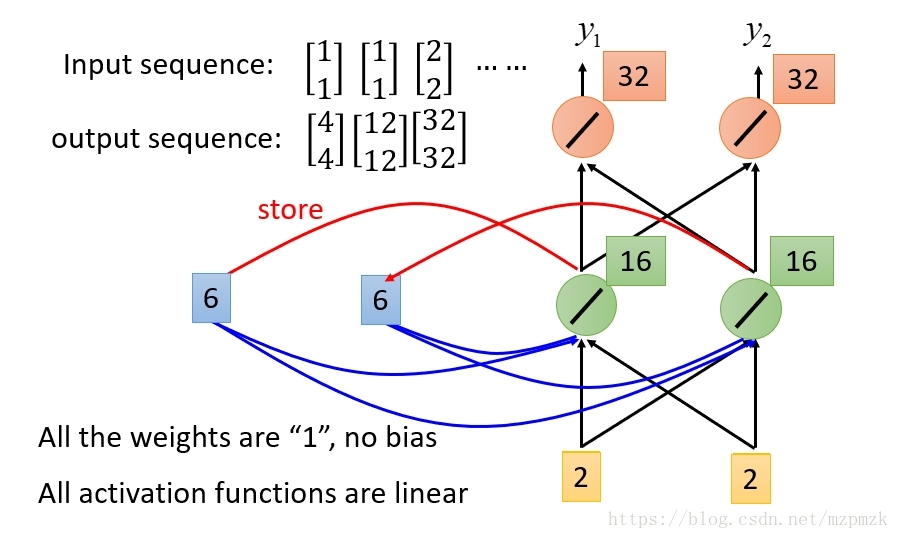
单隐层 RNN
- 输入、隐藏层以及输出层的神经元数量均为 2
- 储存的隐状态:代表了当前及历史的信息
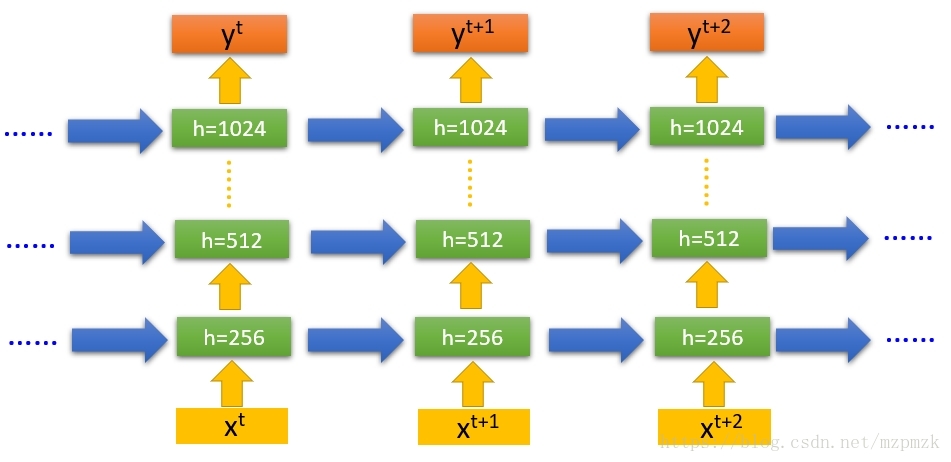
多隐层 RNN
单隐层 RNN可以看作是既“深”又“浅”的网络。一方面来说,如果我们把循环网络按时间展开,长时间间隔的状态之间的路径很长,循环网络可以看作是一个非常深的网络了。从另一方面来说,如果只看同一时刻网络输入到输出(只包含一个隐层),那么,这个网络是非常浅的。- 增加循环神经网络的深度:主要是增加
隐藏状态到输出以及输入到隐藏状态之 间的路径的深度。 - 我们可以在隐藏层堆叠多个RNN,加上输入层和输出层就构成了一个完整的 model, 只不过
隐藏层的 RNN 均可以在 Time 维度(单个序列的长度)上传递,输入层中单个序列中的每一个按照时间的顺序输入,输出层预测按照时间的顺序依次输出。
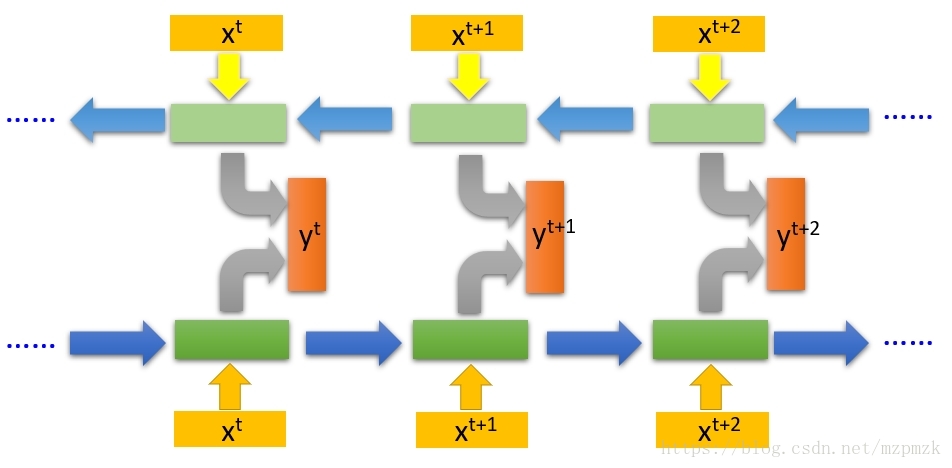
双向 RNN
- 在有些任务中,一个时刻的输出不但和
序列前面的信息有关,也和序列后面的信息有关。比如给定一个句子,其中一个词的词性由它的上下文决定,即:包含左右两边的信息。因此,在这些任务中,我们可以增加一个按照时间的逆序来传递信息的网络层,来增强网络的能力。 - 双向循环神经网络(bidirectional recurrent neural network,Bi-RNN)由两层循环神经网络组成,它们的
输入相同,只是信息传递的方向不同。
- 在有些任务中,一个时刻的输出不但和
三、长短时记忆网络(LSTM)
1、LSTM 简介及主要思想
简介
- 时序反向传播算法按照时间的逆序将错误信息一步步地往前传递。当每个时序训练数据的长度
较大或者时刻
较小时,损失函数关于
时刻隐藏层变量的梯度比较容易出现消失或爆炸的问题(也称
长期依赖问题)。具体原理如下:可参考复旦大学邱锡鹏的讲义
- 时序反向传播算法按照时间的逆序将错误信息一步步地往前传递。当每个时序训练数据的长度
较大或者时刻
较小时,损失函数关于
时刻隐藏层变量的梯度比较容易出现消失或爆炸的问题(也称
主要思想
- 梯度爆炸的问题一般可以通过梯度裁剪来解决,而梯度消失问题则要复杂的多,人们进行了很多尝试,其中一个比较有效的版本是长短期记忆神经网络(Long Short-Term Memory,LSTM)。LSTM 的主要思想是:
门控单元以及线性连接的引入
- 门控单元:有选择性的保存和输出历史信息
- 线性连接:如下图中的水平线可以看作是 LSTM 的“主干道”,通过
加法, 可以无障碍的在这条主干道上传递,因此 LSTM 可以更好地捕捉时序数据中间隔较大的依赖关系。
- 梯度爆炸的问题一般可以通过梯度裁剪来解决,而梯度消失问题则要复杂的多,人们进行了很多尝试,其中一个比较有效的版本是长短期记忆神经网络(Long Short-Term Memory,LSTM)。LSTM 的主要思想是:

2、LSTM 的工作原理
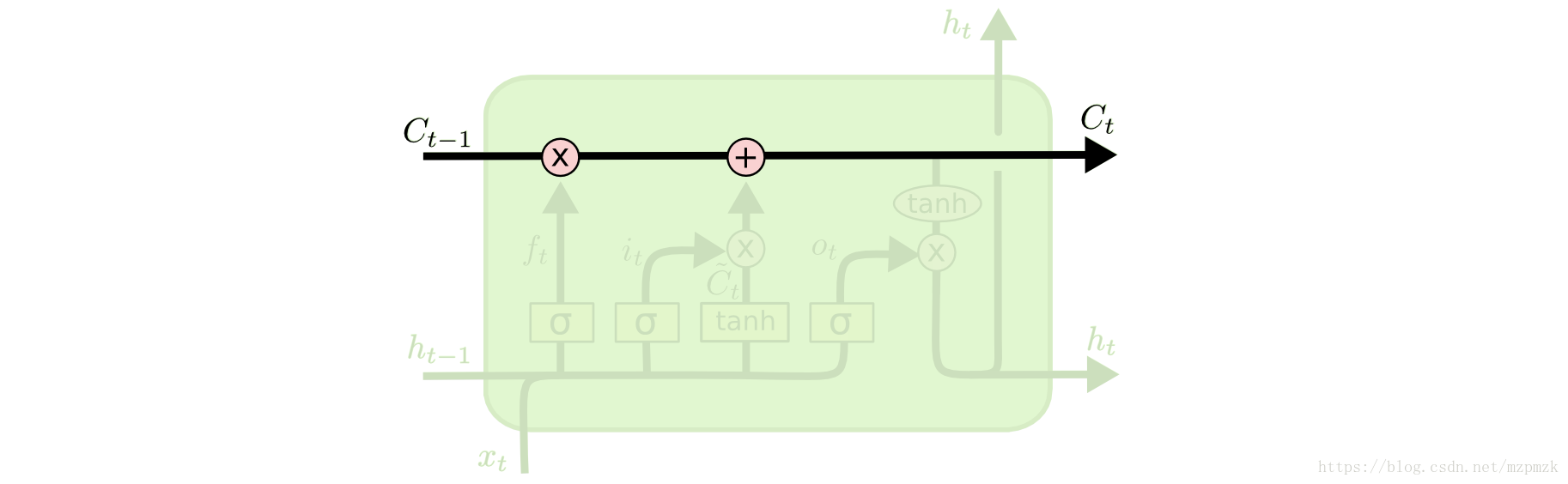
LSTM 时刻 的网络结构如下图所示。其中 是 时刻的输入, 是 时刻隐藏层的输出, 是 时刻历史信息的输出; 、 和 分别为 时刻的遗忘门、输入门和输出门; 是 时刻通过变换后的新信息, 是在 时刻更新过后的历史信息, 是 时刻隐藏层的输出。其具体计算流程如下:
首先,我们将 时刻的输入 和 隐藏层的输出 复制四份,并为它们随机初始化不同的权重,计算出遗忘门、输入门和输出门以及通过变换后的新信息。它们的计算公式如下所示,其中 是
输入层到隐藏层的参数矩阵, 是隐藏层到隐藏层的自循环参数矩阵, 为偏置参数矩阵, 为 sigmoid 函数,使得三个门的输出保持 之间。
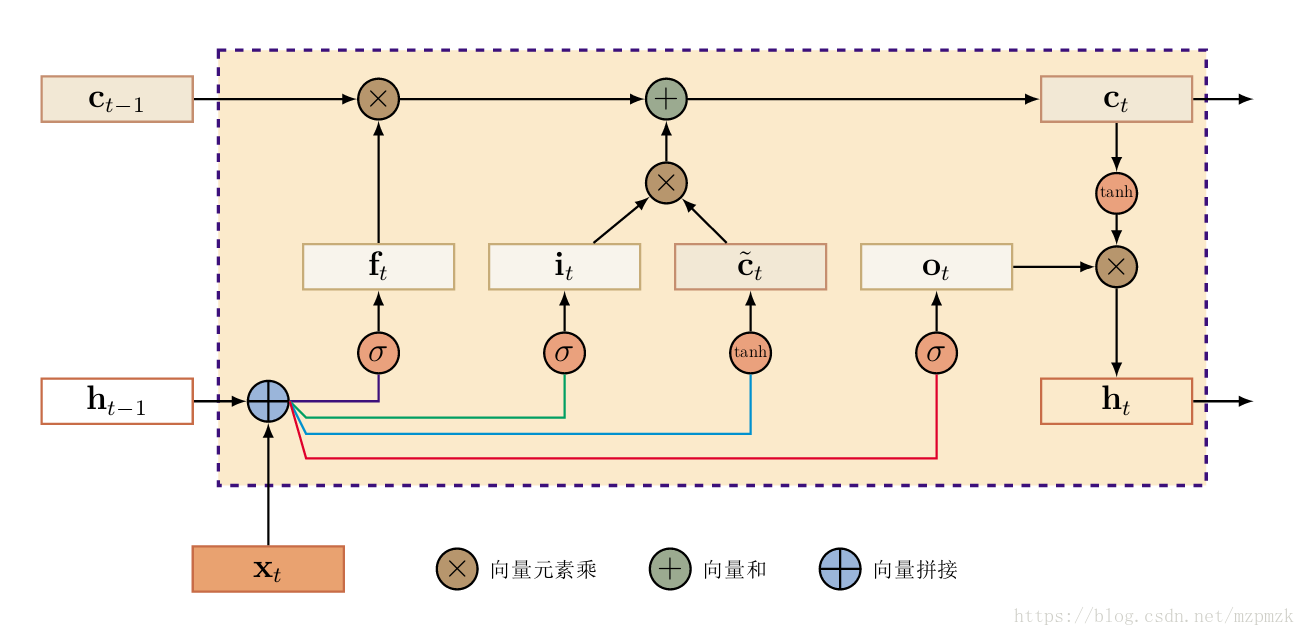
其次,我们使用遗忘门 和输入门 来控制
忘记多少历史信息和保存多少新信息,从而更新内部记忆细胞状态 ,其计算公式如下所示。
最后,我们使用输出门 来控制输出多少
内部记忆单元的信息到隐状态,其计算公式如下所示。
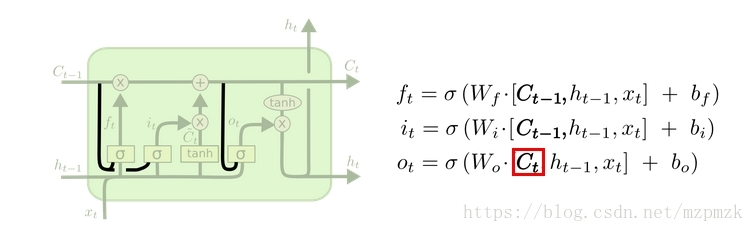
3、LSTM 的变体
peephole 连接:三个门不但依赖于输入 和上一时刻的隐状态 ,也依赖于上一个时刻的内部记忆细胞状态 。
耦合输入门和遗忘门:
- LSTM网络中的输入门和遗忘门有些互补关系,因此同时用两个门比较冗余
- We only forget when we’re going to input something in its place. We only input new values to the state when we forget something older.
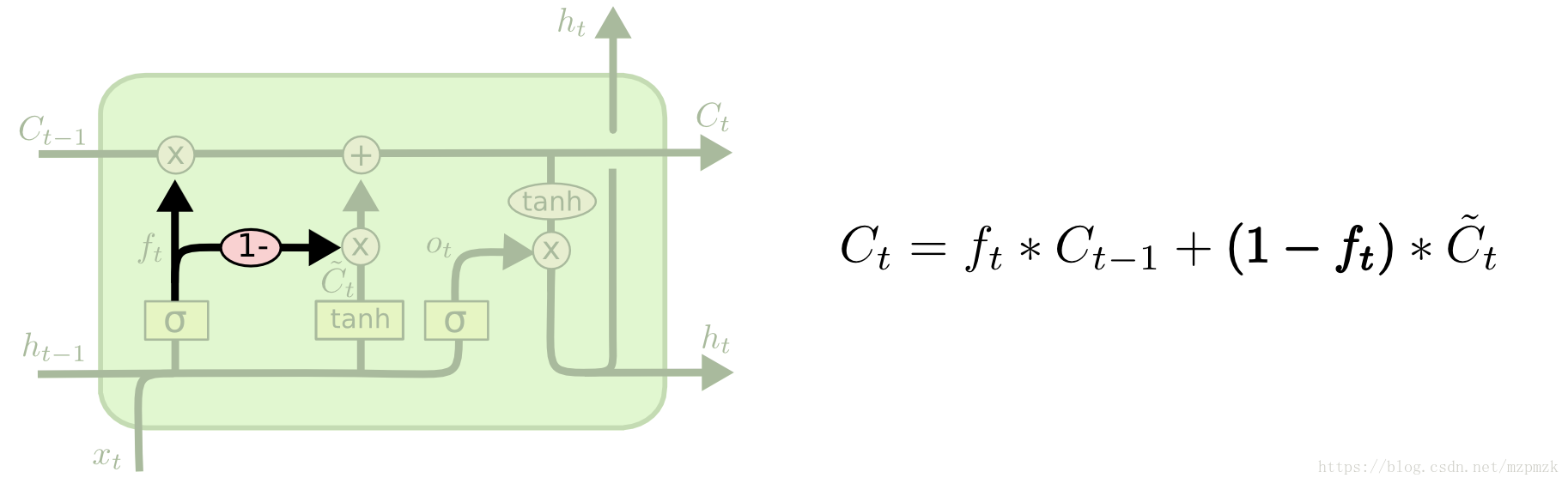
GRU(Gated Recurrent Unit):
- 输入 门与和遗忘门合并成一个门:
更新门 - 引入
重置门(不能算更改,只能说重新定义其使用的地方),用来控制输入候选状态的计算是否依赖上一时刻的状态 - 去除 LSTM 中的内部细胞记忆单元
, 直接在当前状态
和历史状态
之间引入线性依赖关系
- 输入 门与和遗忘门合并成一个门:

四、参考资料
1、完全图解RNN、RNN变体、Seq2Seq、Attention机制
2、Understanding LSTM Networks
3、Hongyi Li:Courses/ML_2016/Lecture/RNN
4、复旦大学邱锡鹏的 RNN 讲义
5、零基础入门深度学习(5) - 循环神经网络
6、零基础入门深度学习(6) - 长短时记忆网络(LSTM)