✍️第一关 - 逻辑回归
一、逻辑回归的基础介绍
逻辑回归是一个分类模型
它可以用来预测某件事发生是否能够发生。分类问题是生活中最常见的问题:
生活中:比如预测上证指数明天是否会上涨,明天某个地区是否会下雨,西瓜是否熟了
金融领域:某个交易是否涉嫌违规,某个企业是否目前是否违规,在未来一段时间内是否会有违规
互联网:用户是否会购买某件商品,是否会点击某个内容
对于已知的结果,上面问题的回答只有: 0 , 1 {0,1} 0,1 。
我们以以下的一个二分类为例,对于一个给定的数据集,存在一条直线可以将整个数据集分为两个部分:
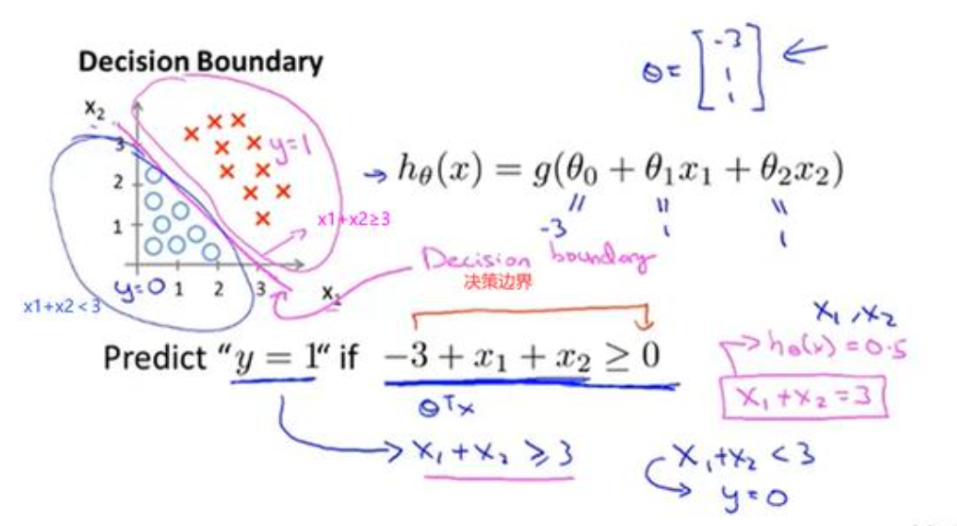
此时,决策边界为 w 1 x 1 + w 2 x 2 + b = 0 w_1x_1+w_2x_2+b=0 w1x1+w2x2+b=0,此时我们很容易将 h ( x ) = w 1 x 1 + w 2 x 2 + b > 0 h(x)=w_1x_1+w_2x_2+b>0 h(x)=w1x1+w2x2+b>0的样本设置为1,反之设置为0。但是这其实是一个感知机的决策过程。逻辑回归在此基础上还需要在加上一层,找到分类概率与输入变量之间的关系,通过概率来判断类别。
我们可以先回顾一下线性回归模型:
h ( x ) = w T x + b h(x)=w^T x +b h(x)=wTx+b
w=[0.1,0.2,0.4,0.2]
b=0.5
def linearRegression(x):
return sum([x[i]*w[i] for i in range(len(x))])+b
linearRegression([2,1,3,1])
在线性模型的基础上加上一个函数 g g g,即 h ( x ) = g ( w T x + b ) h(x)=g(w^T x+b) h(x)=g(wTx+b)。 g ( z ) = 1 / ( 1 + e − z ) g(z)=1/(1+e^{-z}) g(z)=1/(1+e−z)。这个函数就是sigmoid函数,也叫做logistic函数。
它可以将一个线性回归中的结果转化为一个概率值。此时 h ( x ) h(x) h(x)表示的就是某件事发生的概率,我们也可以记为 p ( Y = 1 ∣ x ) p(Y=1|x) p(Y=1∣x)
import numpy as np
def sigmoid(x):
return 1/(1+np.exp(-x))
sigmoid(linearRegression([2,1,3,1]))
可以看一下sigmoid函数的图:
import matplotlib.pyplot as plt
x = np.arange(-10, 10, 0.01)
y = sigmoid(x)
plt.plot(x, y)
plt.show()
通过以上内容我们知道逻辑回归的表达式,那么我们怎么进行优化呢?x是我们输入的参数,对于我们是已知的,预测西瓜是否熟了的话,我们需要知道它的大小,颜色等信息。将其输入到预测模型中,返回一个西瓜是否熟了的概率。那么对于怎么得到模型中的参数w和b呢?
二、逻辑回归的优化方法
1:逻辑回归的损失函数
逻辑回归采用的是交叉熵的损失函数,对于一般的二分类的逻辑回归来说交叉熵函数为: J ( θ ) = − [ y l n ( y ‘ ) + ( 1 − y ) l n ( 1 − y ‘ ) ] J(\theta )=-[yln(y`)+(1-y)ln(1-y`)] J(θ)=−[yln(y‘)+(1−y)ln(1−y‘)],其中 y ‘ y` y‘是预测值。
注:有些地方交叉熵的log的底数是2,有些地方是e。由于 l o g 2 ( x ) l o g e ( x ) = l o g 2 ( e ) \frac{log_2(x)}{log_e(x)}=log_2(e) loge(x)log2(x)=log2(e)是一个常数,因此无论是啥对于最后的结果都是不影响的,不过由于计算的简便性用e的会比较多一些。
实际上我们求的是训练中所有样本的损失,因此:
J ( θ ) = − 1 m ∑ [ y i l n ( y i ‘ ) + ( 1 − y i ) l n ( 1 − y i ‘ ) ] J(\theta )=-\frac{1}{m}\sum[y_i ln(y_i`)+(1-y_i )ln(1-y_i`)] J(θ)=−m1∑[yiln(yi‘)+(1−yi)ln(1−yi‘)]
注: θ \theta θ代表的是所有的参数集合
Q:为什么不采用最小二乘法进行优化?(平方差)
A:因为采用最小二乘法的话损失函数就是非凸了(凸函数的定义是在整个定义域内只有一个极值,极大或者极小,该极值就是全部的最大或者最小)
更多详细地解释可以看这里:https://www.zhihu.com/question/65350200
后面可能会有不少难以解释或者需要花费很大篇幅去解释的地方,大多数比较延展性的知识,我可能还是会放个链接,有需要的朋友可以当作课外拓展去了解下。
注:损失函数的由来
在统计学中,假设我们已经有了一组样本(X,Y),为了计算出能够产生这组样本的参数。通常我们会采用最大似然估计的方法(一种常用的参数估计的方法)。使用到最大似然估计的话,我们还要一个假设估计,这里我们就是假设 Y Y Y是服从于伯努利分布的。
P ( Y = 1 ∣ x ) = p ( x ) P(Y=1|x)=p(x) P(Y=1∣x)=p(x)
P ( Y = 0 ∣ x ) = 1 − p ( x ) P(Y=0|x)=1-p(x) P(Y=0∣x)=1−p(x)
由于 Y Y Y服从于伯努利分布,我们很容易就有似然函数:
L = ∏ [ p ( x i ) y i ] [ 1 − p ( x i ) ] ( 1 − y i ) L=\prod[p(x_i)^{y_i}][1-p(x_i)]^ {(1-y_i)} L=∏[p(xi)yi][1−p(xi)](1−yi)
为了求解的方便我们可以两边取对数:
l n ( L ) = ∑ [ y i l n ( p ( x i ) ) + ( 1 − y i ) l n ( 1 − p ( x i ) ) ] ln(L)=\sum[y_iln(p(x_i))+(1-y_i)ln(1-p(x_i))] ln(L)=∑[yiln(p(xi))+(1−yi)ln(1−p(xi))]
大家其实也发现了 L L L和 J J J两个式子的关系,其实对 L L L求最大就相当于对 J J J求最小。这个也是大家以后会听到的最大似然函数和最小损失函数之间的关系。如果被问道逻辑回归为什么要采用交叉熵作为损失函数也可以回答:这是假设逻辑回归中 Y Y Y服从于伯努利分布,然后从最大似然估计中推导来的。
2:梯度下降法
逻辑回归的优化方法是梯度下降法。
从数学的角度来说,函数梯度的方向就是函数增长最快的方向,反之梯度的反方向就是函数减少最快的方向。因此我们想要计算一个函数的最小值,就朝着该函数梯度相反的方向前进。
我们先简单地介绍一下该算法。
假设我们需要优化的函数: f ( X ) = f ( x 1 , . . . , x n ) f(X)=f(x_1,...,x_n) f(X)=f(x1,...,xn)
首先我们初始化自变量,从 X ( 0 ) = ( x 1 ( 0 ) , . . . x n ( 0 ) ) X^(0)=(x_1^{(0)},...x_n^{(0)}) X(0)=(x1(0),...xn(0))开始。设置一个学习率 η \eta η。
对于任何 i > = 0 i>=0 i>=0:
如果是最小化 f f f
x 1 i + 1 = x 1 i − η ∂ f ∂ x 1 ( x ( i ) ) x_1^{i+1}=x_1^{i}-\eta \frac{\partial{f}}{\partial{x_1}}(x^{(i)}) x1i+1=x1i−η∂x1∂f(x(i))
x n i + 1 = x n i − η ∂ f ∂ x n ( x ( i ) ) x_n^{i+1}=x_n^{i}-\eta \frac{\partial{f}}{\partial{x_n}}(x^{(i)}) xni+1=xni−η∂xn∂f(x(i)),
反之如果求 f f f的最大值,则
x 1 i + 1 = x 1 i + η ∂ f ∂ x 1 ( x ( i ) ) x_1^{i+1}=x_1^{i}+\eta \frac{\partial{f}}{\partial{x_1}}(x^{(i)}) x1i+1=x1i+η∂x1∂f(x(i)),
x n i + 1 = x n i + η ∂ f ∂ x n ( x ( i ) ) x_n^{i+1}=x_n^{i}+\eta \frac{\partial{f}}{\partial{x_n}}(x^{(i)}) xni+1=xni+η∂xn∂f(x(i)),
注:
很多人可能是听说过随机梯度下降,批次梯度下降,梯度下降法。这三者的区别非常简单,就是看样本数据,随机梯度下降每次计算一个样本的损失,
然后更新参数 θ \theta θ,批次梯度下降是每次根据一批次的样本来更新参数,梯度下降是全部样本。一般来说随机梯度下降速度快(每计算一个样本就可以更新一次参数,参数更新的速度极快)。同样的,随机梯度下降的收敛性会比较差,容易陷入局部最优。反过来每次用来参数更新的样本越多,速度会越慢,但是更能够达到全局最优。
3:逻辑回归的优化
以上是逻辑回归优化的目标函数 J ( w , b ) = − 1 m ∑ [ y i l n ( σ ( w T x + b ) ) + ( 1 − y i ) l n ( 1 − σ ( w T x + b ) ) ] J(w,b )=-\frac{1}{m}\sum[y_i ln(\sigma(w^T x +b))+(1-y_i )ln(1-\sigma(w^T x +b))] J(w,b)=−m1∑[yiln(σ(wTx+b))+(1−yi)ln(1−σ(wTx+b))]
我们需要优化参数 w , b w,b w,b,从而使其在我们已知的样本 X , y X,y X,y上值最小。也就是我们常说的经验风险最小。
既然要优化目标函数,那么首先我们需要对 J ( w , b ) J(w,b) J(w,b)求导。
我们先令 g = σ ( w T x + b ) g=\sigma(w^T x +b) g=σ(wTx+b)
∂ J ( g ) ∂ g = − ∂ ∂ g [ y l n ( g ) + ( 1 − y ) l n ( 1 − g ) ] = − y g + 1 − y 1 − g \frac{\partial J(g)}{\partial g}=-\frac{\partial}{\partial g}[yln(g)+(1-y)ln(1-g)]=-\frac{y}{g}+\frac{1-y}{1-g} ∂g∂J(g)=−∂g∂[yln(g)+(1−y)ln(1−g)]=−gy+1−g1−y
再令: a = w T x + b a=w^T x +b a=wTx+b
∂ g ∂ a = ∂ ( 1 1 + e − a ) ∂ a = − ( 1 + e − a ) − 2 − e − a = 1 1 + e − a 1 + e − a − 1 1 + e − a = σ ( a ) ( 1 − σ ( a ) ) = g ( 1 − g ) \frac{\partial g}{\partial a}=\frac{\partial ({\frac{1}{1+e^{-a}}})}{\partial a}=-(1+e^{-a})^{-2}-e^{-a}=\frac{1}{1+e^{-a}}\frac{1+e^{-a}-1}{1+e^{-a}}=\sigma(a)(1-\sigma (a))=g(1-g) ∂a∂g=∂a∂(1+e−a1)=−(1+e−a)−2−e−a=1+e−a11+e−a1+e−a−1=σ(a)(1−σ(a))=g(1−g)
可以发现 g = σ ( a ) g=\sigma(a) g=σ(a),但是 g g g对 a a a求导之后居然是 g ( 1 − g ) g(1-g) g(1−g),这也是Sigmoid函数特别有意思的一点,在后续的梯度下降优化中,这个性质可以帮助我们减少很多不必要的计算。
有了上面的基础,我们就可以求我们需要优化的参数 w , b w,b w,b的梯度了。根据链式求导:
∂ J ∂ w = ∂ J ∂ g ∂ g ∂ a ∂ a ∂ w = ( − y g + 1 − y 1 − g ) g ( 1 − g ) x = ( g − y ) x \frac{\partial J}{\partial w}=\frac{\partial J}{\partial g}\frac{\partial g}{\partial a}\frac{\partial a}{\partial w}=(-\frac{y}{g}+\frac{1-y}{1-g})g(1-g)x=(g-y)x ∂w∂J=∂g∂J∂a∂g∂w∂a=(−gy+1−g1−y)g(1−g)x=(g−y)x
∂ J ∂ b = ∂ J ∂ g ∂ g ∂ a ∂ a ∂ b = ( − y g + 1 − y 1 − g ) g ( 1 − g ) = ( g − y ) \frac{\partial J}{\partial b}=\frac{\partial J}{\partial g}\frac{\partial g}{\partial a}\frac{\partial a}{\partial b}=(-\frac{y}{g}+\frac{1-y}{1-g})g(1-g)=(g-y) ∂b∂J=∂g∂J∂a∂g∂b∂a=(−gy+1−g1−y)g(1−g)=(g−y)
以上就是关于逻辑回归优化的介绍。根据上述的公式,我们简单地写一个根据随机梯度下降法进行优化的函数。
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
X=datasets.load_iris()['data']
Y=datasets.load_iris()['target']
Y[Y>1]=1
X_train,X_test,y_train,y_test=train_test_split(X,Y,test_size=0.4,stratify=Y)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def cal_grad(y, t):
grad = np.sum(t - y) / t.shape[0]
return grad
def cal_cross_loss(y, t):
loss=np.sum(-y * np.log(t)- (1 - y) * np.log(1 - t))/t.shape[0]
return loss
class LR:
def __init__(self, in_num, lr, iters, train_x, train_y, test_x, test_y):
self.w = np.random.rand(in_num)
self.b = np.random.rand(1)
self.lr = lr
self.iters = iters
self.x = train_x
self.y = train_y
self.test_x=test_x
self.test_y=test_y
def forward(self, x):
self.a = np.dot(x, self.w) + self.b
self.g = sigmoid(self.a)
return self.g
def backward(self, x, grad):
w = grad * x
b = grad
self.w = self.w - self.lr * w
self.b = self.b - self.lr * b
def valid_loss(self):
pred = sigmoid(np.dot(self.test_x, self.w) + self.b)
return cal_cross_loss(self.test_y, pred)
def train_loss(self):
pred = sigmoid(np.dot(self.x, self.w) + self.b)
return cal_cross_loss(self.y, pred)
def train(self):
for iter in range(self.iters):
##这里我采用随机梯度下降的方法
for i in range(self.x.shape[0]):
t = self.forward(self.x[i])
grad = cal_grad(self.y[i], t)
self.backward(self.x[i], grad)
train_loss = self.train_loss()
valid_loss = self.valid_loss()
if iter%5==0:
print("当前迭代次数为:", iter, "训练loss:", train_loss, "验证loss:", valid_loss)
model=LR(4,0.01,100,X_train,y_train,X_test,y_test)
model.train()
以上是手写的逻辑回归,用于自己练习就可以啦,通常我们还是会调sklearn包的。
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
X=datasets.load_iris()['data']
Y=datasets.load_iris()['target']
from sklearn.linear_model import LogisticRegression
X_train,X_test,y_train,y_test=train_test_split(X,Y,test_size=0.1,stratify=Y)
model=LogisticRegression(penalty='l2',
class_weight=None,
random_state=None, max_iter=100)
model.fit(X_train,y_train)
model.predict_proba(X_test)
penalty:惩罚系数,也就是我们常说的正则化,默认为"l2",也可以使用"l1",之后我们会介绍逻辑回归的l1,l2正则化。
class_weight:类别权重,一般我们在分类不均衡的时候使用,比如{0:0.1,1:1}代表在计算loss的时候,0类别的loss乘以0.1。这样在0类别的数据过多时候就相当于给1类别提权了。就我个人而言,比起在类别不均衡时采用采用,我更倾向于这个。
max_iter:最大迭代次数。
以上就是逻辑回归的整体介绍,相信大家看完之后对逻辑回归也有一个比较全面的了解。但是逻辑回归是一个很奇怪的算法,表面上看起来比较简单,但是深挖起来知识特别多,千万不要说自己精通逻辑回归。
三、逻辑回归的拓展
1: 逻辑回归的正则化
首先我们介绍一下正则化,对这个方面比较的可以跳过。一般我们模型就是训练就是为了最小化经验风险,正则化就是在这个基础上加上约束(也可以说是引入先验知识),这种约束可以引导优化误差函数的时候倾向于选择向满足约束的梯度下降的方向。
注:这里我们可以补充一下经验风险,期望风险和结构化风险。
经验风险就是训练集中的平均损失,期望风险就是(X,y)联合分布的期望损失,当样本数量N趋向于无穷大时,经验风险也趋向于期望风向。机器学习做的就是通过经验风险取估计期望风险。
结构化风险是防止防止过拟合在经验风险的基础上加上正则项。
在逻辑回归中常见的有L1正则化和L2正则化。
加上参数w绝对值的和
L 1 : J ( θ ) = − 1 m ∑ [ y i l n ( y i ‘ ) + ( 1 − y i ) l n ( 1 − y i ‘ ) ] + ∣ w ∣ L1:J(\theta )=-\frac{1}{m}\sum[y_i ln(y_i`)+(1-y_i )ln(1-y_i`)]+|w| L1:J(θ)=−m1∑[yiln(yi‘)+(1−yi)ln(1−yi‘)]+∣w∣
加上参数w平方和
L 2 : J ( θ ) = − 1 m ∑ [ y i l n ( y i ‘ ) + ( 1 − y i ) l n ( 1 − y i ‘ ) ] + ∣ ∣ w 2 ∣ ∣ L2:J(\theta )=-\frac{1}{m}\sum[y_i ln(y_i`)+(1-y_i )ln(1-y_i`)]+||w^2|| L2:J(θ)=−m1∑[yiln(yi‘)+(1−yi)ln(1−yi‘)]+∣∣w2∣∣
以 L 2 L2 L2为例,我们的优化的目标函数不再是仅仅经验风险了,我们还要在 ∣ ∣ w 2 ∣ ∣ ||w^2|| ∣∣w2∣∣最小的基础上达到最小的经验风险。用我们生活的例子就是在最小代价的基础上达成一件事,这样肯定最合理的。
如果只是到这里感觉就很容易了,但是一般别人都会问你:
1: L 1 L1 L1, L 2 L2 L2正则化有什么理论基础?
2:为什么 L 1 L1 L1正则化容易产生离散值?
吐槽:就是加上一个 ∣ w ∣ |w| ∣w∣和 ∣ ∣ w 2 ∣ ∣ ||w^2|| ∣∣w2∣∣啊,让 w w w的取值小一点,有啥可说的。
吐槽归吐槽,问题还是要回答的。
当我们假设参数 w w w服从于正态分布的时候,根据贝叶斯模型可以推导出 L 2 L2 L2正则化,当我们假设参数 w w w服从于拉普拉斯分布的时候,根据贝叶斯模型可以推导出 L 1 L1 L1正则化
具体的推导如下:
逻辑回归其实是假设参数是确定,我们需要来求解参数。贝叶斯假设逻辑回归的参数是服从某种分布的。假设参数 w w w的概率模型为 p ( w ) p(w) p(w)。使用贝叶斯推理的话:
p ( w ∣ D ) ≺ p ( w ) p ( D ∣ w ) = Π j = 1 M p ( w j ) Π i = 1 N p ( D i ∣ w j ) p(w|D)\prec p(w)p(D|w)=\Pi^{M}_{j=1}p(w_j)\Pi^{N}_{i=1}p(D_i|w_j) p(w∣D)≺p(w)p(D∣w)=Πj=1Mp(wj)Πi=1Np(Di∣wj)
对上式取 l o g log log
= > a r g m a x w [ Σ j = 1 M l o g p ( w j ) + Σ i = 1 N l o g p ( D i ∣ w ) ] = > a r g m a x w [ Σ i = 1 N l o g p ( D i ∣ w ) + Σ j = 1 M l o g p ( w j ) ] = > a r g m i n w ( − 1 N Σ i = 1 N l o g p ( D i ∣ w ) − 1 N Σ j = 1 M l o g p ( w j ) ) \begin{aligned} &=>argmax_w[\Sigma^{M}_{j=1}logp(w_j)+\Sigma^{N}_{i=1}logp(D_i|w)]\\ &=>argmax_w[\Sigma^{N}_{i=1}logp(D_i|w)+\Sigma^{M}_{j=1}logp(w_j)]\\ &=>argmin_w (-\frac{1}{N}\Sigma^{N}_{i=1}logp(D_i|w)-\frac{1}{N}\Sigma^{M}_{j=1}logp(w_j)) \end{aligned} =>argmaxw[Σj=1Mlogp(wj)+Σi=1Nlogp(Di∣w)]=>argmaxw[Σi=1Nlogp(Di∣w)+Σj=1Mlogp(wj)]=>argminw(−N1Σi=1Nlogp(Di∣w)−N1Σj=1Mlogp(wj))
前面的式子大家很熟悉,就是逻辑回归的损失函数。现在假设 p ( w ) p(w) p(w)服从某个分布,相当于引入一个先验的知识。如果 p ( w ) p(w) p(w)服从均值为0拉普拉斯分布:
p ( w ) = 1 2 λ e − ∣ w ∣ λ p(w)=\frac{1}{2\lambda}e^{\frac{-|w|}{\lambda}} p(w)=2λ1eλ−∣w∣
将 p ( w ) p(w) p(w)代入上面的式子可以得到:
Σ j = 1 M l o g p ( w j ) = > Σ j = 1 M ( − ∣ w i ∣ λ l o g ( 1 2 λ ) ) \Sigma^{M}_{j=1}logp(w_j)=>\Sigma^{M}_{j=1}(-\frac{|w_i|}{\lambda}log(\frac{1}{2\lambda})) Σj=1Mlogp(wj)=>Σj=1M(−λ∣wi∣log(2λ1))
将参数 1 λ l o g ( 1 2 λ ) \frac{1}{\lambda}log(\frac{1}{2\lambda}) λ1log(2λ1)用一个新的参数 λ \lambda λ代替,然后就可以得到我们正则化L1的正则化项:
λ Σ j = 1 M ∣ w i ∣ \lambda\Sigma^{M}_{j=1}|w_i| λΣj=1M∣wi∣
两部分加起来就是逻辑回归L1正则化下的损失函数了。
L2正则化也是同样的道理,只不过是假设 p ( w ) p(w) p(w)服从均值为0的正态分布。
关于 L 1 L1 L1, L 2 L2 L2等高线图大家肯定也都接触过了。
从模型优化的角度上来说:
当 w w w大于0时 ∣ w ∣ |w| ∣w∣的导数为1,根据梯度下降,w在更新完逻辑回归的那个参数之后,需要减去 l r ∗ 1 lr*1 lr∗1。这样会将w往0出趋近,
反之当 w w w小于0时,根据梯度下降|w|的梯度也会让w往0的方向趋近。直到 w w w为 ∣ w ∣ |w| ∣w∣的梯度也为0了。
L 2 L2 L2并不会出现以上情况,假设我们把一个特征复制1次。复制之前该特征的权重为w1,复制之后使用L1正则化,倾向于将另外一个特征的权重优化为0,而L2正则化倾向于将两个特征的权重都优化为w1/2,因为我们很明显的知道,当两个权重都为w1/2时。 ∣ ∣ w 2 ∣ ∣ ||w^2|| ∣∣w2∣∣才会最小。
以上只是我个人的见解,关于这个问题,我在网上也看到了大神们的各种解释,可以参照着看看:https://zhuanlan.zhihu.com/p/50142573
2: 为什么逻辑回归中经常会将特征离散化。
这个是工业界中常见的操作,一般我们不会将连续的值作为特征输入到逻辑回归的模型之中,而是将其离散成0,1变量。这样的好处有:
1:稀疏变量的内积乘法速度快,计算结果方便存储,并且容易扩展;
2:离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰。
3:逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
4:离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
5:特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问。
四、作业
STEP1: 按照要求计算下方题目结果
作业1:逻辑回归的表达式:
A: h(x)=wx+b
B:h(x)=wx
C: h(x)=sigmoid(wx+b)
D: h(x)=sigmoid(wx)
a1=“”
作业2:下面关于逻辑回归的表述是正确的(多选):
A:逻辑回归的输出结果是概率值,在0-1之间
B:使用正则化可以提高模型的泛化性
C:逻辑回归可以直接用于多分类
D:逻辑回归是无参模型
E:逻辑回归的损失函数是交叉熵
a2=“”
作业3:计算 y = s i g m o i d ( w 1 ∗ x 1 + w 2 ∗ x 2 + 1 ) y=sigmoid(w1*x1+w2*x2+1) y=sigmoid(w1∗x1+w2∗x2+1)当 w=(0.2, 0.3)时,样本X=(1,1),y=1的时w1,w2的梯度和loss:
(保存3位小数,四舍五入)
a3=“”#(w1)
a4=“”#(w2)
a5=“”#(loss)
作业4:在cal_grad梯度函数的基础上加上L2正则化,下面的函数是否正确?(Y/N)
def cal_grad(y, t,x,w):
“”"
x:输入X
y:样本y
t:预测t
w:参数w
“”"
grad = np.sum(t - y) / t.shape[0]
return gradx+2w
a6=“”