自编码器是一种期望输出与输入相等的网络,通常隐含层节点数量应小于输入层的节点数量。网络大体结构如下:
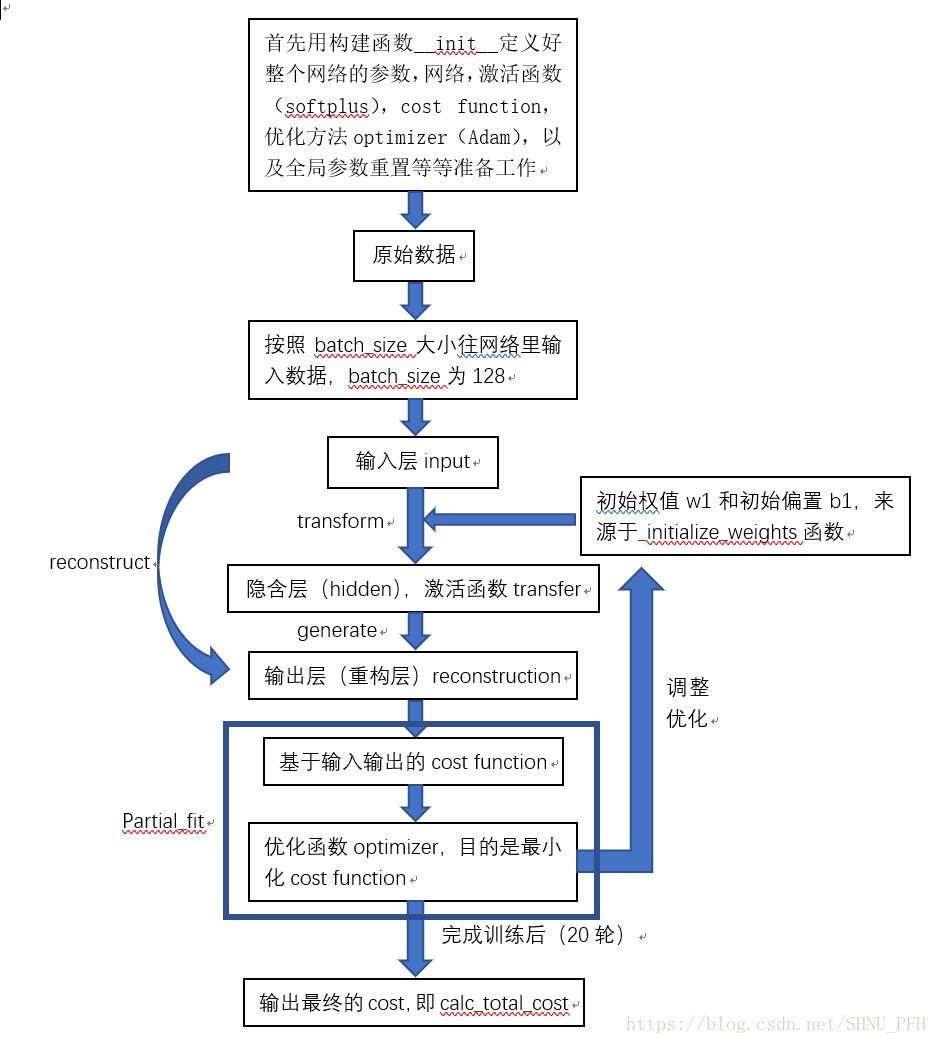
流程如下:首先定义权值初始化函数;
一、定义自编码class,包括:
1、定义参数,网络,cost function,优化函数,参数重置,包括输入输出隐含层权重等各个参数,激活函数softplus和优化器Adam;
2、构建权值字典,关键字w1,b1,w2,b2;定义一步损失优化函数,即每进行一轮训练,就输出一次损失,并对损失进行一次优化;
3、定义最终损失函数,只输出最终优化后的损失;
4、定义激活函数方法,即输出隐含层的结果;
5、定义从hidden向重构层(输出层)的输出函数;
6、定义从input层向重构层(输出层)的输出函数;
7、定义获取权值系数和偏置系数函数;
二、定义样本数据初始化函数,用来对样本数据变成零均值,标准差为1的分布;
三、定义随机数函数,作为batch_size的起点;
四、设置好样本数,最大训练轮数,batch_size大小;
五、根据AGN类创建自编码器实例,输入节点为784,隐含层节点为200,激活函数softplus,优化器Adam,学习速率0.001,噪声系数scale0.01;
六、开始训练。
疑问:cala_total_cost输出的到底是什么?为什么会到600000左右?
代码如下:
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets("C:/Users/PengFeihu/Desktop/mnist",one_hot=True)
import numpy as np
import sklearn.preprocessing as prep
import tensorflow as tf
#定义一个最大值为high,最小值为low的均匀分布
def xavier_init(fan_in, fan_out,constant = 1):
low = -constant*np.sqrt(6.0/(fan_in+fan_out))
high = constant*np.sqrt(6.0/(fan_in+fan_out))
return tf.random_uniform((fan_in,fan_out),
minval = low, maxval = high,
dtype = tf.float32)
#定义去噪自编码的class,噪声为加性高斯噪声
class AdditiveGaussianNoiseAutoencoder(object):
def __init__(self, n_input, n_hidden, transfer_function=tf.nn.softplus,
optimizer = tf.train.AdamOptimizer(), scale = 0.1):
self.n_input = n_input
self.n_hidden = n_hidden
self.transfer = transfer_function
self.scale = tf.placeholder(tf.float32)
self.training_scale = scale
network_weights = self._initialize_weights()
self.weights = network_weights
#定义去噪自编码器网络结构
self.x = tf.placeholder(tf.float32, [None, self.n_input])
self.hidden = self.transfer(tf.add(tf.matmul(self.x+scale*tf.random_normal((n_input,)),
self.weights['w1']), self.weights['b1']))
self.reconstruction = tf.add(tf.matmul(self.hidden,
self.weights['w2']),self.weights['b2'])
#定义损失函数cost function
self.cost = 0.5*tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction, self.x),2.0))
self.optimizer = optimizer.minimize(self.cost)
init = tf.global_variables_initializer()
self.sess = tf.Session()
self.sess.run(init)
#定义参数初始化函数
def _initialize_weights(self):
all_weights = dict()
all_weights['w1'] = tf.Variable(xavier_init(self.n_input, self.n_hidden))
all_weights['b1'] = tf.Variable(tf.zeros([self.n_hidden], dtype = tf.float32))
all_weights['w2'] = tf.Variable(tf.zeros([self.n_hidden, self.n_input], dtype = tf.float32))
all_weights['b2'] = tf.Variable(tf.zeros([self.n_input], dtype = tf.float32))
return all_weights
#定义计算损失cost及执行一步训练的函数partial_fit??????????????????????????????
def partial_fit(self,X):
cost, opt = self.sess.run((self.cost, self.optimizer),
feed_dict = {self.x:X, self.scale:self.training_scale})
return cost
#计算最终损失
def calc_total_cost(self, X):
return self.sess.run(self.cost, feed_dict = {self.x:X, self.scale:self.training_scale})
#返回自编码器隐含层的输出结果
def transform(self,X):
return self.sess.run(self.hidden, feed_dict = {self.x:X, self.scale:self.training_scale})
def generate(self, hidden = None):
if hidden is None:
hidden = np.random.normal(size = self.weights['b1'])
return self.sess.run(self.reconstruction,
feed_dict = {self.hidden:hidden})
#定义reconstruct函数
def reconstruct(self, X):
return self.sess.run(self.reconstruction, feed_dict = {self.x:X,
self.scale: self.training_scale})
#获取隐含层权重w1
def getWeights(self):
return self.sess.run(self.weights['w1'])
#获取隐含层偏置b1
def getBiases(self):
return self.sess.run(self.weights['b1'])
#定义标准化处理函数
def standard_scale(X_train, X_test):
preprocessor = prep.StandardScaler().fit(X_train)
X_train = preprocessor.transform(X_train)
X_test = preprocessor.transform(X_test)
return X_train, X_test
#定义block
def get_random_block_from_data(data, batch_size):
start_index = np.random.randint(0, len(data)-batch_size)
return data[start_index:(start_index+batch_size)]
#对测试集和训练集进行标准化变换
X_train, X_test = standard_scale(mnist.train.images, mnist.test.images)
#定义常用参数,总训练样本数,最大训练轮数(epoch)设为20,batch_size设为128,并设置每一轮(epoch)就损失一次cost
n_samples = int(mnist.train.num_examples)
training_epochs = 20
batch_size = 128
display_step = 1
#AGN自编码器,定义模型输入节点数n_lnput=784,隐含层节点数n_hidden=200,隐含层的激活函数为transfer_function为softplus,优化器optimizer为Adam且学习速率为0.001,同时将噪声的系数scale设为0。01
autoencoder = AdditiveGaussianNoiseAutoencoder(n_input = 784,
n_hidden = 200,
transfer_function = tf.nn.softplus,
optimizer = tf.train.AdamOptimizer(learning_rate = 0.001),
scale = 0.01)
#开始训练
for epoch in range(training_epochs):
avg_cost = 0
total_batch = int(n_samples/batch_size)
for i in range(total_batch):
batch_xs = get_random_block_from_data(X_train, batch_size)
cost = autoencoder.partial_fit(batch_xs)
avg_cost += cost/n_samples*batch_size #?????????????
if epoch % display_step == 0:
print("epoch:", '%04d'%(epoch+1), "cost=", "{:.9f}".format(avg_cost))
print("total cost: "+str(autoencoder.calc_total_cost(X_test)))