写在前面
因为时间原因本文有些图片自己没有画,来自网络的图片我尽量注出原链接,但是有的链接已经记不得了,如果有使用到您的图片,请联系我,必注释。
自编码器及其变形很多,本篇博客目前主要基于普通自编码器、栈式自编码器、欠完备自编码器、稀疏自编码器和去噪自编码器,会提供理论+实践(有的理论本人没有完全理解,就先没有写上,后更)。另外,关于收缩自编码器、变分自编码器、CNN自编码器、RNN自编码器及其自编码器的应用,后更。
本文展示的所有完整代码详见:完整代码
(目前只有Keras版本,有时间会写Tensorflow版本)
文章较长,PDF版点击链接:PDF版
一、自编码器(Autoencoder, AE)
1、自编码器的结构和思想
自编码器是一种无监督的数据维度压缩和数据特征表达方法。
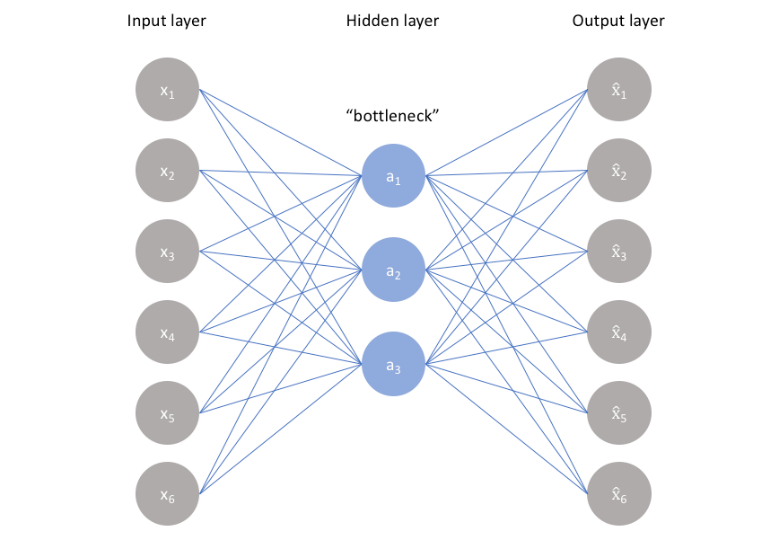
自编码器是神经网络的一种,经过训练后能尝试将输入复制到输出。自编码器由编码器和解码器组成,如下图所示(图片来源:深度学习浅层理解(三)— 常用模型之自编码器):
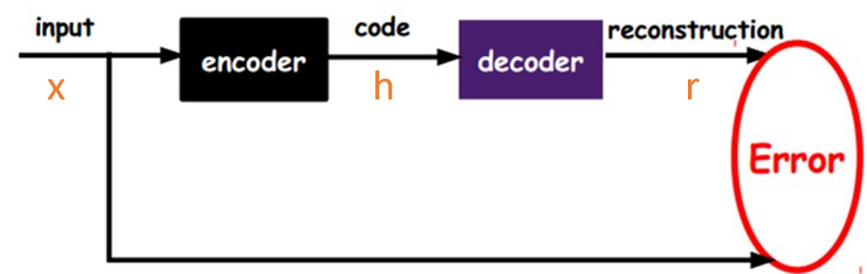
表示编码器, 表示解码器,自编码的目标便是优化损失函数 ,也就是减小图中的Error。
2、自编码器和前馈神经网络的比较
二者的区别和联系如下:
(1)自编码器是前馈神经网络的一种,最开始主要用于数据的降维以及特征的抽取,随着技术的不断发展,现在也被用于生成模型中,可用来生成图片等。
(2)前馈神经网络是有监督学习,其需要大量的标注数据。自编码器是无监督学习,数据不需要标注因此较容易收集。
(3)前馈神经网络在训练时主要关注的是输出层的数据以及错误率,而自编码的应用可能更多的关注中间隐层的结果。
3、普通自编码器存在的问题
在普通的自编码器中,输入和输出是完全相同的,因此输出对我们来说没有什么应用价值,所以我们希望利用中间隐层的结果,比如,可以将其作为特征提取的结果、利用中间隐层获取最有用的特性等。
但是如果只使用普通的自编码器会面临什么问题呢?比如,输入层和输出层的维度都是5,中间隐层的维度也是5,那么我们使用相同的输入和输出来不断优化隐层参数,最终得到的参数可能是这样:
的参数为1,其余参数为0,也就是说,中间隐层的参数只是完全将输入记忆下来,并在输出时将其记忆的内容完全输出即可,神经网络在做恒等映射,产生数据过拟合。如下图所示(图片来源:Introduction to autoencoders.):
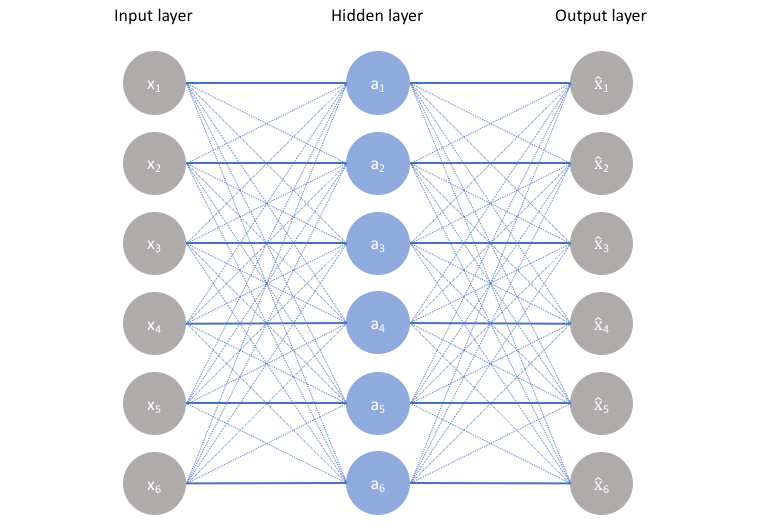
上图是隐层单元数等于输入维度的情况,当然,如果是隐层单元数大于输入维度,也会发生类似的情况,即当隐层单元数大于等于输入维度时,网络可以采用完全记忆的方式,虽然这种方式在训练时精度很高,但是复制的输出对我们来说毫无意义。
因此,我们会给隐层加一些约束,如限制隐藏单元数、添加正则化等,后面后介绍。
4、自编码器实现与结果分析
(1)实现框架: Keras
(2)数据集: Mnist手写数字识别
(3)关键代码:
def train(x_train):
"""
build autoencoder.
:param x_train: the train data
:return: encoder and decoder
"""
# input placeholder
input_image = Input(shape=(ENCODING_DIM_INPUT, ))
# encoding layer
hidden_layer = Dense(ENCODING_DIM_OUTPUT, activation='relu')(input_image)
# decoding layer
decode_output = Dense(ENCODING_DIM_INPUT, activation='relu')(hidden_layer)
# build autoencoder, encoder, decoder
autoencoder = Model(inputs=input_image, outputs=decode_output)
encoder = Model(inputs=input_image, outputs=hidden_layer)
# compile autoencoder
autoencoder.compile(optimizer='adam', loss='mse')
# training
autoencoder.fit(x_train, x_train, epochs=EPOCHS, batch_size=BATCH_SIZE, shuffle=True)
return encoder, autoencoder
(4)代码分析:
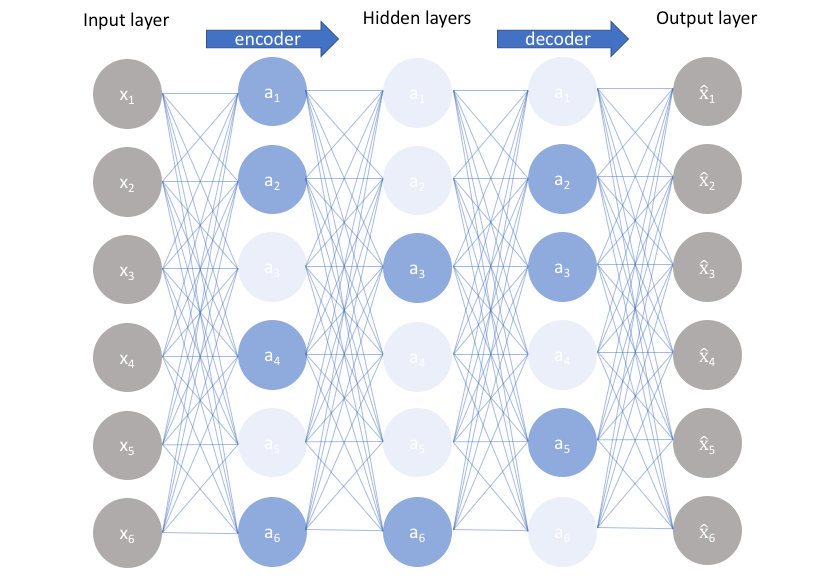
Keras封装的比较厉害,所以傻瓜式编程,这里是最简单的自编码器,其输入维度是28*28=784,中间单隐层的维度是2,使用的激活函数是Relu,返回encoder和autoencoder。encoder部分可以用于降维后的可视化,或者降维之后接分类等,autoencoder可以用来生成图片等(这部分代码git上都有)。结构见图如下:

(5)结果展示:
(i)Eencoder结果的可视化如图:
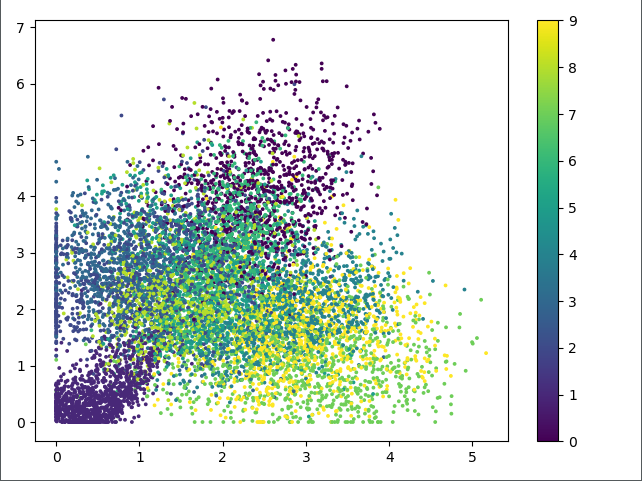
上图中不同表示表示不同的数字,由图可知,自编码器降维之后的结果并不能很好地表示10个数字。
(ii)autoencoder还原之后的图片和原图片对比如下:

上图说明,autoencoder的生成结果不是很清晰。
二、栈式自编码器(Stack Autoencoder)
1、栈式自编码器思想
栈式自编码器又称为深度自编码器,其训练过程和深度神经网络有所区别,下面是基于栈式自编码器的分类问题的训练过程(图片来自台大李宏毅老师的PPT):
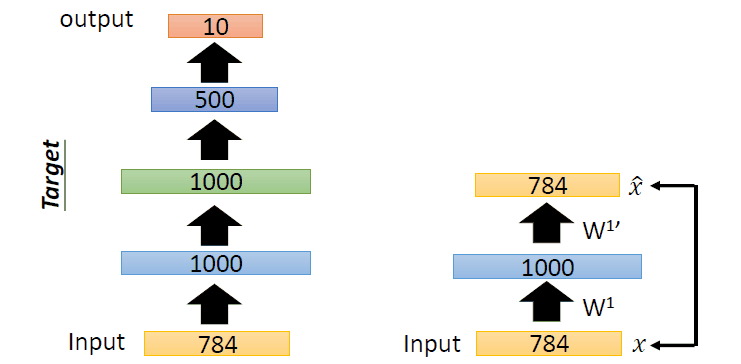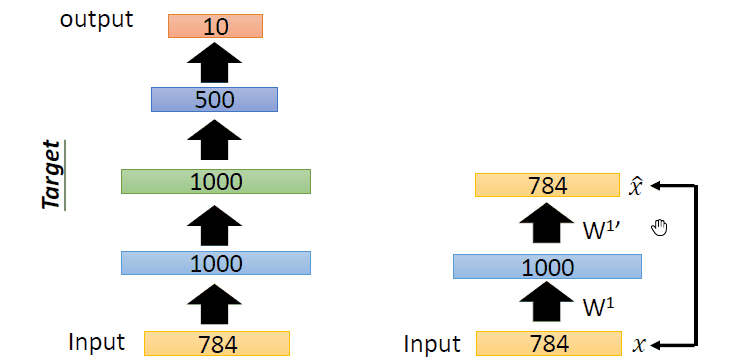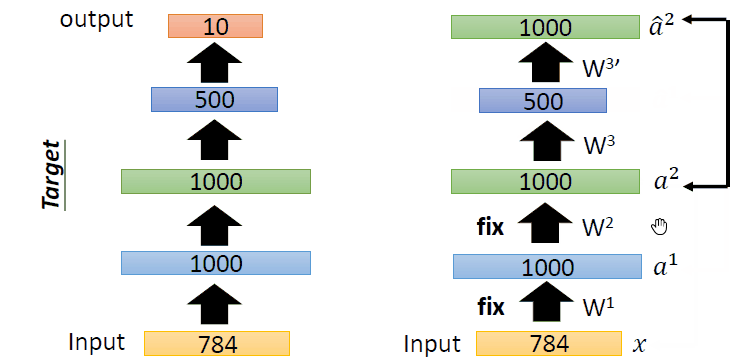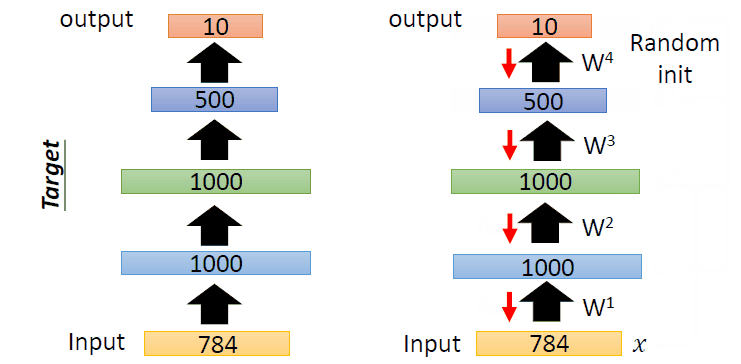
即过程如下:
首先,训练784->1000->784的自编码器,而后已经固定已经训练好的参数和1000维的结果,训练第二个自编码器:1000->1000->1000,而后固定已经训练好的参数和训练的中间层结果,训练第三个自编码器:1000->500->1000,固定参数和中间隐层的结果。此时,前3层的参数已经训练完毕,此时,最后一层接一个分类器,将整体网络使用反向传播进行训练,对参数进行微调。这便是使用栈式自编码器进行分类的整体过程。
注:encoder和decoder的参数可以是对称的,也可以是非对称的。
2、栈式自编码器实现与结果分析
(1)实现框架: Keras
(2)数据集: Mnist手写数字识别
(3)关键代码:
def train(x_train):
# input placeholder
input_image = Input(shape=(ENCODING_DIM_INPUT, ))
# encoding layer
encode_layer1 = Dense(ENCODING_DIM_LAYER1, activation='relu')(input_image)
encode_layer2 = Dense(ENCODING_DIM_LAYER2, activation='relu')(encode_layer1)
encode_layer3 = Dense(ENCODING_DIM_LAYER3, activation='relu')(encode_layer2)
encode_output = Dense(ENCODING_DIM_OUTPUT)(encode_layer3)
# decoding layer
decode_layer1 = Dense(ENCODING_DIM_LAYER3, activation='relu')(encode_output)
decode_layer2 = Dense(ENCODING_DIM_LAYER2, activation='relu')(decode_layer1)
decode_layer3 = Dense(ENCODING_DIM_LAYER1, activation='relu')(decode_layer2)
decode_output = Dense(ENCODING_DIM_INPUT, activation='tanh')(decode_layer3)
# build autoencoder, encoder
autoencoder = Model(inputs=input_image, outputs=decode_output)
encoder = Model(inputs=input_image, outputs=encode_output)
# compile autoencoder
autoencoder.compile(optimizer='adam', loss='mse')
# training
autoencoder.fit(x_train, x_train, epochs=EPOCHS, batch_size=BATCH_SIZE, shuffle=True)
return encoder, autoencoder
栈式自编码器相当于深度网络的过程,主要注意维度对应即可,另外,这里设置的encoder和decoder的维度是对称的。其架构图如下:
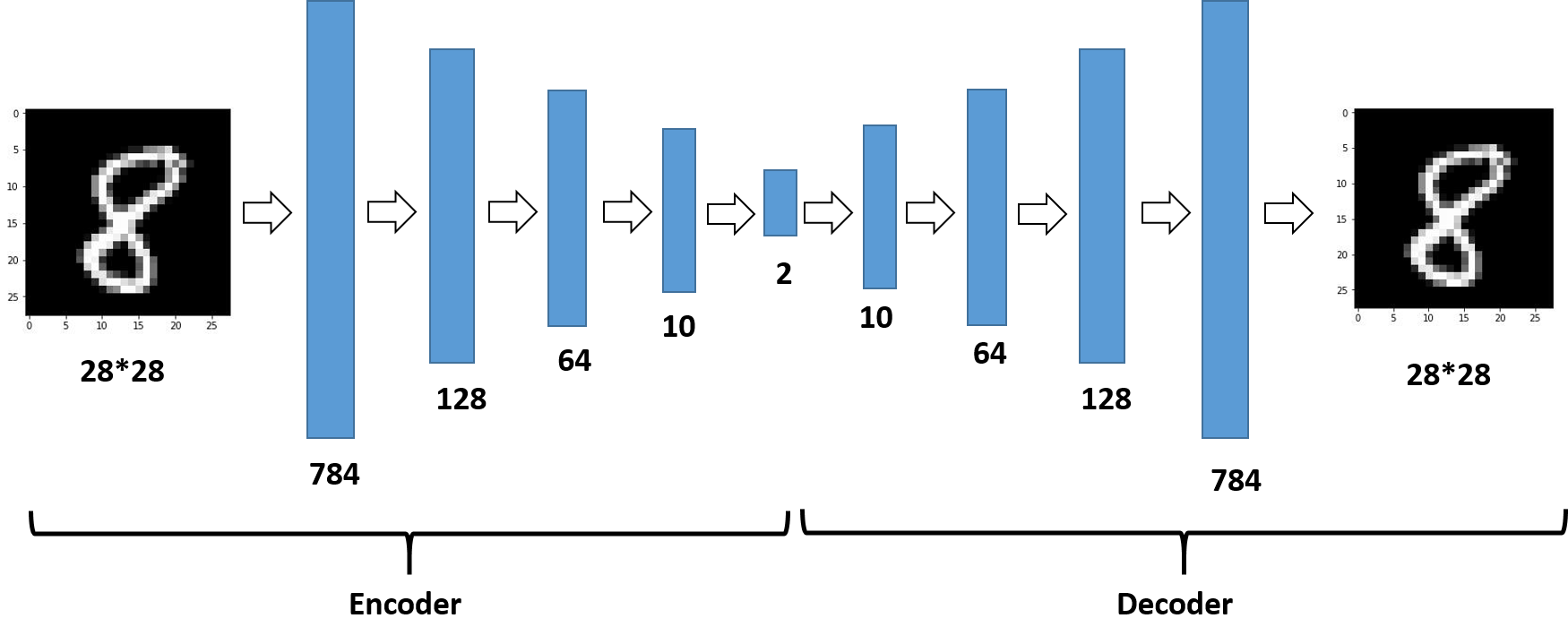
(4)结果展示:
(i)Eencoder结果的可视化如图:
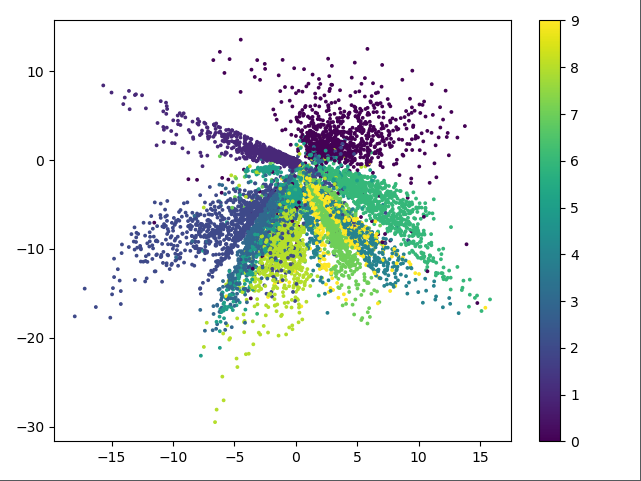
上图中不同表示表示不同的数字,由图可知,栈式自编码器的效果相比较普通自编码器好很多,这里基本能将10个分类全部分开。
(ii)autoencoder还原之后的图片和原图片对比如下:

三、欠完备自编码器(Undercomplete Autoencoder)
1、欠完备自编码器的思想
由上述自编码器的原理可知,当隐层单元数大于等于输入维度时,网络会发生完全记忆的情况,为了避免这种情况,我们限制隐层的维度一定要比输入维度小,这就是欠完备自编码器,如下图所示(图片来源:Introduction to autoencoders.)。 学习欠完备的表示将强制自编码器捕捉训练数据中最显著的特征。
2、欠完备自编码器和主成分分析(PCA)的比较
实际上,若同时满足下列条件,欠完备自编码器的网络等同于PCA,其会学习出于PCA相同的生成子空间:
- 每两层之间的变换均为线性变换。
- 目标函数 为均方误差。
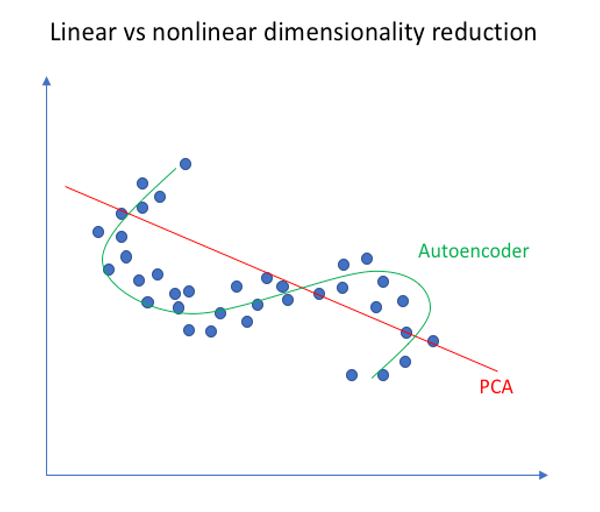
因此,拥有非线性编码器函数 和非线性解码器函数 的自编码器能够学习出比PCA更强大的知识,其是PCA的非线性推广。下图是在二维空间中PCA算法和自编码器同时作用在二维点上做映射的结果(图片来源:Introduction to autoencoders.) ,从图中可以看出,自编码器具有更好的表达能力,其可以映射到非线性函数。
3、欠完备自编码器特点
- 防止过拟合,并且因为隐层编码维数小于输入维数,可以学习数据分布中最显著的特征。
- 若中间隐层单元数特别少,则其表达信息有限,会导致重构过程比较困难。
四、稀疏自编码器(Sparse Autoencoder)
1、稀疏自编码器思想
稀疏自编码器是加入正则化的自编码器,其未限制网络接收数据的能力,即不限制隐藏层的单元数。
所谓稀疏性限制是指:
若激活函数是sigmoid,则当神经元的输出接近于1的时候认为神经元被激活,输出接近于0的时候认为神经元被抑制。使得大部分神经元别抑制的限制叫做稀疏性限制。若激活函数是tanh,则当神经元的输出接近于-1的时候认为神经元是被抑制的。
如上图所示(图片来源:Introduction to autoencoders. ),浅色的神经元表示被抑制的神经元,深色的神经元表示被激活的神经元。通过稀疏自编码器,我们没有限制隐藏层的单元数,但是防止了网络过度记忆的情况。
稀疏自编码器损失函数的基本表示形式如下:
其中
是解码器的输出,通常
是编码器的输出,即
2、损失函数和BP函数推导
损失函数可以加入L1正则化,也可以加入KL散度,下面是对加入KL散度的损失函数的分析。
损失函数的分析如下:
假设
表示在给定输入
的情况下,自编码网络隐层神经元
的激活度,则神经元在所有训练样本上的平均激活度为:
其中,
,我们的目的使得网络激活神经元稀疏,所以可以引入一个稀疏性参数
,通常
是一个接近于0的值(即表示隐藏神经元中激活神经元的占比)。则若可以使得
,则神经元在所有训练样本上的平均激活度
便是稀疏的,这就是我们的目标。为了使得
,我们使用KL散度衡量二者的距离,两者相差越大,KL散度的值越大,KL散度的公式如下:
表示平均激活度的目标值。因此损失函数如下:
其中
便是NN网络中的普通的代价函数,可以使用均方误差等。
反向传播的分析如下:
上式代价函数,左部分就是之前BP的结果,结果如下:
可参考反向传导算法。
右部分的求导如下:
\begin{align}
\frac{\partial \sum_{j=1}^{s_2}KL(\rho||\hat{\rho_j})}{\partial z_i^{(2)}}
&= \frac{\partial KL(\rho||\hat{\rho_i})}{\partial z_i^{(2)}} \newline
&= \frac{\partial KL(\rho||\hat{\rho_i})}{\partial \hat{\rho_i}}\cdot \frac{\partial \hat{\rho_i}}{\partial z_i^{(2)}} \newline
&= \frac{\partial(\rho \log \frac{\rho}{\hat{\rho_i}}+(1-\rho) \log \frac{1-\rho}{1-\hat{\rho_i}})}{\partial\hat{\rho_i}}\cdot \frac{\partial \hat{\rho_i}}{\partial z_i^{(2)}} \newline
&= (-\frac{\rho}{\hat{\rho_i}} + \frac{1-\rho}{1-\hat{\rho_i}}) \cdot {f}’(z_i^{(2)})
\end{align}
因此
的求导结果如下:
此即反向传播的方程,根据此方程可以参数
和
进行更新。
3、Mini-Batch的情况
平均激活度是根据所有样本计算出来的,所以在计算任何单元的平均激活度之前,需要对所有样本计算一下正向传播,从而获得平均激活度,所以使用小批量时计算效率很低。要解决这个问题,可采取的方法是只计算Mini-Batch中包含的训练样本的平均激活度,然后在Mini-Batch之间计算加权值:
其中,
是时刻
的Mini-Batch的平均激活度,
是时刻t-1的Mini-Batch的平均激活度。若\lambda大,则时刻
的Mini-Batch的平均激活度所占比重大,否则,时刻t的Mini-Batch的平均激活度所占比重大。
4、稀疏自编码器在分类中的应用
稀疏自编码器一般用来学习特征,以便用于像分类这样的任务。如下图(图片来源:为什么稀疏自编码器很少见到多层的?):
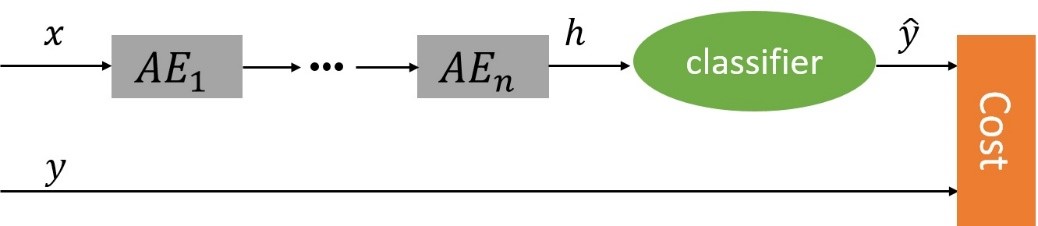
上述过程不是一次训练的,可以看到上面只有编码器没有解码器,因此其训练过程是自编码器先使用数据训练参数,然后保留编码器,将解码器删除并在后面接一个分类器,并使用损失函数来训练参数已达到最后效果。
5、稀疏编码器实现与结果分析
(1)框架: Keras
(2)数据集: Mnist手写数字识别
(3)关键代码:
def train(x_train):
# input placeholder
input_image = Input(shape=(ENCODING_DIM_INPUT, ))
# encoding layer
# *****!!! this code is changed compared with Autoencoder, adding the activity_regularizer to make the input sparse.
encode_layer1 = Dense(ENCODING_DIM_LAYER1, activation='relu', activity_regularizer=regularizers.l1(10e-6))(input_image)
# *******************************************************
encode_layer2 = Dense(ENCODING_DIM_LAYER2, activation='relu')(encode_layer1)
encode_layer3 = Dense(ENCODING_DIM_LAYER3, activation='relu')(encode_layer2)
encode_output = Dense(ENCODING_DIM_OUTPUT)(encode_layer3)
# decoding layer
decode_layer1 = Dense(ENCODING_DIM_LAYER3, activation='relu')(encode_output)
decode_layer2 = Dense(ENCODING_DIM_LAYER2, activation='relu')(decode_layer1)
decode_layer3 = Dense(ENCODING_DIM_LAYER1, activation='relu')(decode_layer2)
decode_output = Dense(ENCODING_DIM_INPUT, activation='tanh')(decode_layer3)
# build autoencoder, encoder
autoencoder = Model(inputs=input_image, outputs=decode_output)
encoder = Model(inputs=input_image, outputs=encode_output)
# compile autoencoder
autoencoder.compile(optimizer='adam', loss='mse')
# training
autoencoder.fit(x_train, x_train, epochs=EPOCHS, batch_size=BATCH_SIZE, shuffle=True)
return encoder, autoencoder
这里是以多层的自编码器举例,单隐层的同样适用,主要是在第一层加一个正则化项,activity_regularizer=regularizers.l1(10e-6)说明加入的是L1正则化项,10e-6是正则化项系数,完整代码可参见最开始的git。其架构如下:
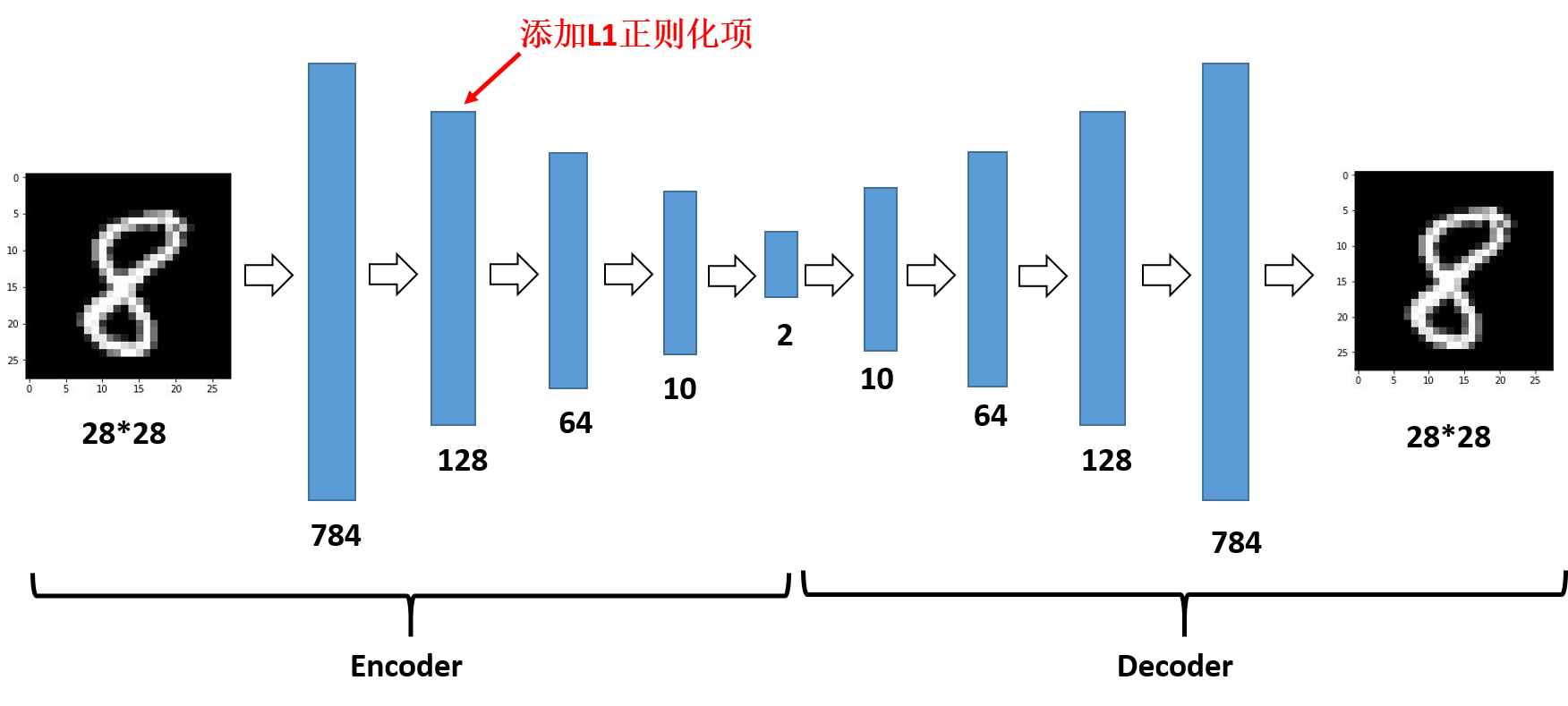
(4)结果展示:
(i)Encoder结果的可视化如图:
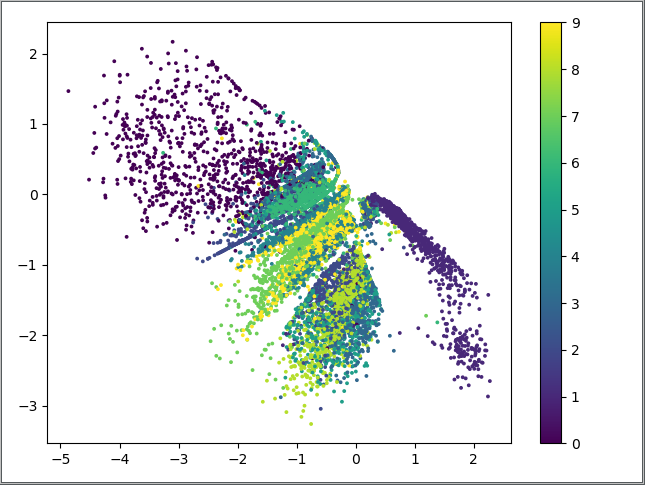
上图中不同颜色表示不同的数字,由图可知,这个编码器的分类效果还可以,比自编码器好很多,但是看起来还是作用不大,因为大部分作用需要归功于栈式自编码器。
(ii)autoencoder还原之后的图片和原图片对比如下:

五、去噪自编码器(Denoising Autoencoder)
1、去噪自编码器思想
去噪自编码器是一类接受损失数据作为输入,并训练来预测原始未被损坏的数据作为输出的自编码器。 如下图所示(图片来自花书):
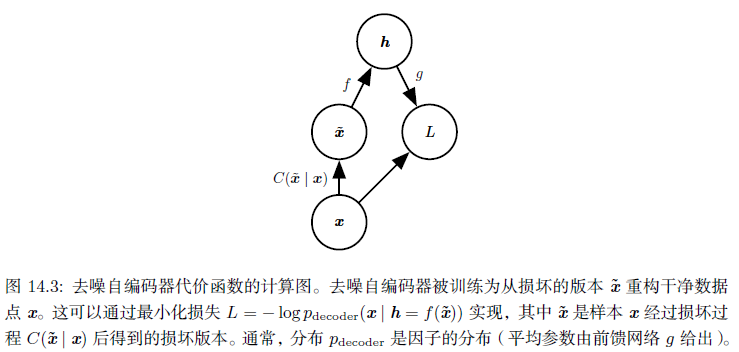
其训练过程如下:
引入一个损坏过程
,这个条件分布代表给定数据样本
产生损坏样本
的概率。自编码器学习重构分布
:
- 从训练数据中采一个训练样本
- 从 采一个损坏样本
- 将 作为训练样本来估计自编码器的重构分布 ,其中 是编码器 的输出, 根据解码函数 定义。
去噪自编码器中作者给出的直观解释是:和人体感官系统类似,比如人的眼睛看物体时,如果物体的某一小部分被遮住了,人依然能够将其识别出来,所以去噪自编码器就是破坏输入后,使得算法学习到的参数仍然可以还原图片。
注: 噪声可以是添加到输入的纯高斯噪声,也可以是随机丢弃输入层的某个特性。
2、去噪自编码器和Dropout
噪声可以是添加到输入的纯高斯噪声,也可以是随机丢弃输入层的某个特性,即如果 是一个二项分布,则其表现为下图所示内容,即经过处理的 的结果是保留或者舍掉,也就是说, 会舍去一部分内容,保留一部分内容:
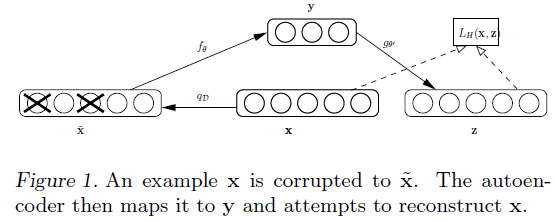
这个思想类似于Dropout,但是二者还有一些区别:
(1) 去噪自编码器操作的是输入数据,相当于对输入数据去掉一部分内容;而Dropout操作的是网络隐藏层,相当于去掉隐藏层的一部分单元。
(2) Dropout在分层预训练权值的过程中是不参与的,只是后面的微调部分会加入;而去噪自编码器是在每层预训练的过程中作为输入层被引入,在进行微调时不参与
3、去噪自编码器和PCA
去噪自编码器来源于论文[Vincent P, Larochelle H, Bengio Y, et al. Extracting and composing robust features with denoising autoencoders[C]//Proceedings of the 25th international conference on Machine learning. ACM, 2008: 1096-1103.]
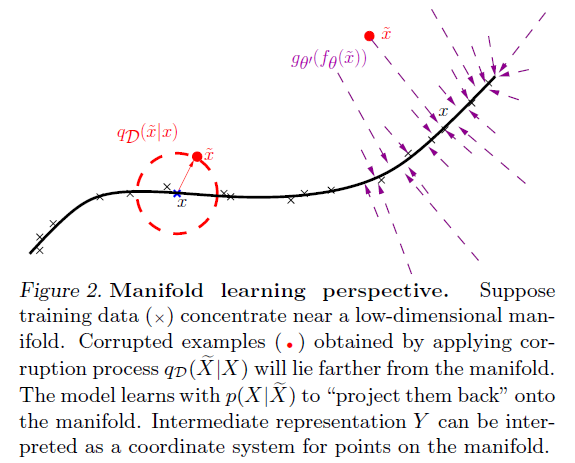
上图是去噪自编码器从流形角度的原理,图中黑色的曲线表示原始的局部流型,我们通过
将其映射到一个圆的某一点,
表示添加噪声之后数据点。我们的目标是使得添加噪声之后的点能够映射到原始点,这样损失值为最小,即:图中红色箭头是噪声添加的向量场,而紫色部分是重构过程中需要不断查找的向量场。
因此,可以理解为,去噪自编码器的局部就是简化的PCA原理,其是对PCA的非线性扩展。
除此之外,文章还从信息论文、随机算子等角度理论上证明了去噪自编码器的可行性,有兴趣的读者可以参考上面提到的论文。
4、去噪自编码器效果
论文中的实验基于Minst数据集,其实验结果如下:
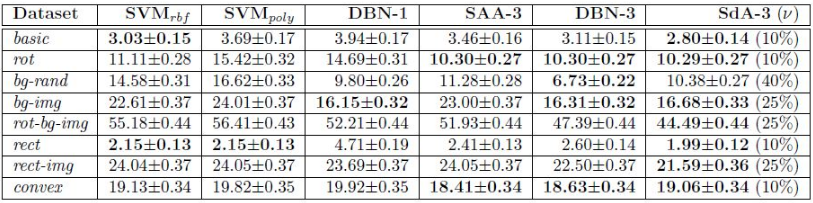
其中,第一个和第二个baseline是使用高斯核和多项式核的SVM,DBN-1是1层隐层单元的深度信念网络,DBN-3是3层隐层单元的深度信念网络,SAA-3是使用栈式自编码器初始化之后的3层深度网络,最后的Sda-3是3层的栈式去噪自编码器。从表中可以看出,使用去噪自编码器的结果优于其他网络。
除此之外,网站Denoising Autoencoders (dA)有去噪自编码器的代码和实验,其去噪前和去噪后过滤器的对比结果如下:

左图是去噪之前的过滤器数据,右图是去噪之后的过滤器数据,从图中可以看出,去噪自编码器学习到的特征更具代表性。。
5、去噪自编码器特点
- 普通的自编码器的本质是学一个相等函数,即输入和输出是同一个内容,这种相等函数的缺点便是当测试样本和训练样本不符合同一个分布时,在测试集上效果不好,而去噪自编码器可以很好地解决这个问题。
- 欠完备自编码器限制学习容量,而去噪自编码器允许学习容量很高,同时防止在编码器和解码器学习一个无用的恒等函数。
- 经过了加入噪声并进行降噪的训练过程,能够强迫网络学习到更加鲁棒的不变性特征,获得输入的更有效的表达。
6、去噪编码器实现与结果分析
(1)框架: Keras
(2)数据集: Mnist手写数字识别
(3)关键代码:
def addNoise(x_train, x_test):
"""
add noise.
:return:
"""
x_train_noisy = x_train + NOISE_FACTOR * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + NOISE_FACTOR * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.) # limit into [0, 1]
x_test_noisy = np.clip(x_test_noisy, 0., 1.) # limit into [0, 1]
return x_train_noisy, x_test_noisy
去噪自编码器主要是对输入添加噪声,所以训练过程是不需要改变的,只需要改变输入和输出。上述便是对输入添加噪声的过程,NOISE_FACTOR * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)便是添加的噪声。 np.clip()是截取函数,将数值限制在0~1之间。其架构如下:
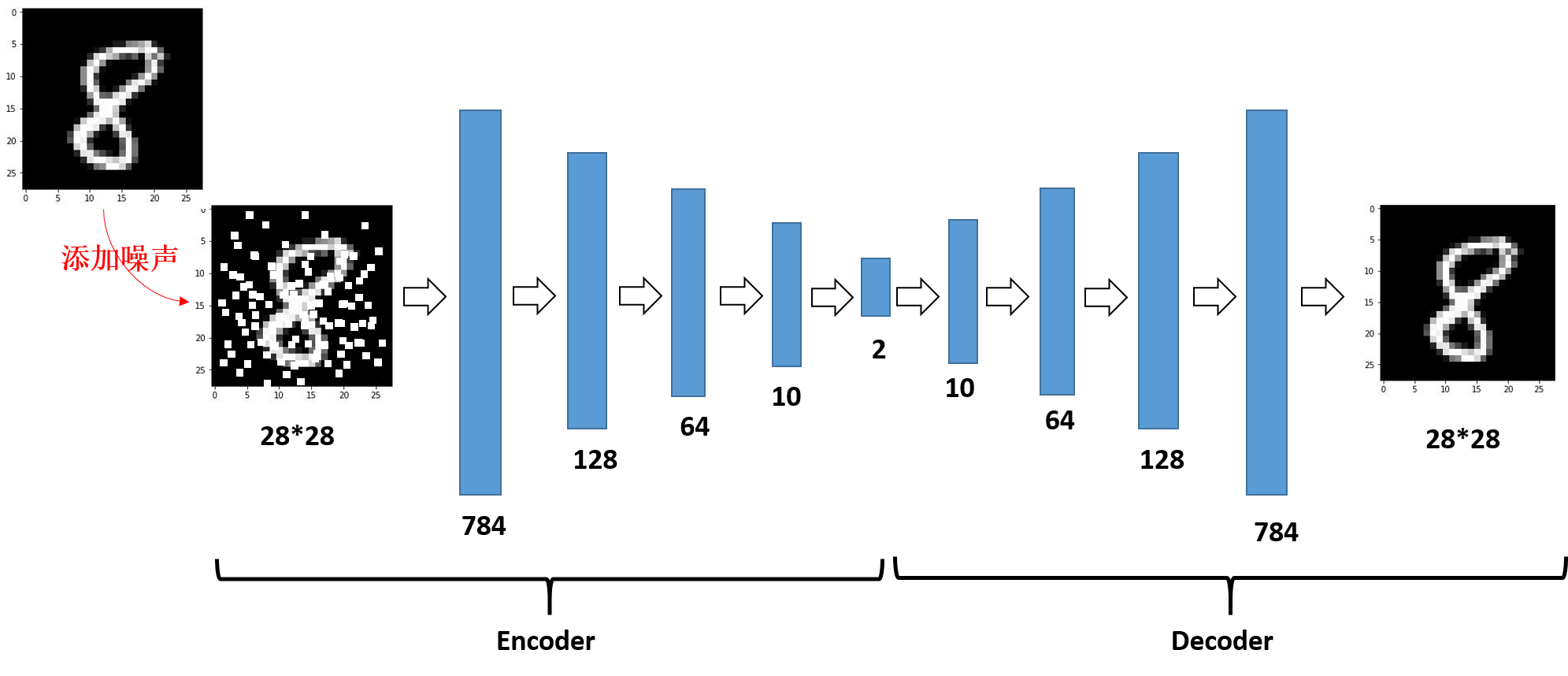
(4)结果展示:
(i)Eencoder结果的可视化如图:
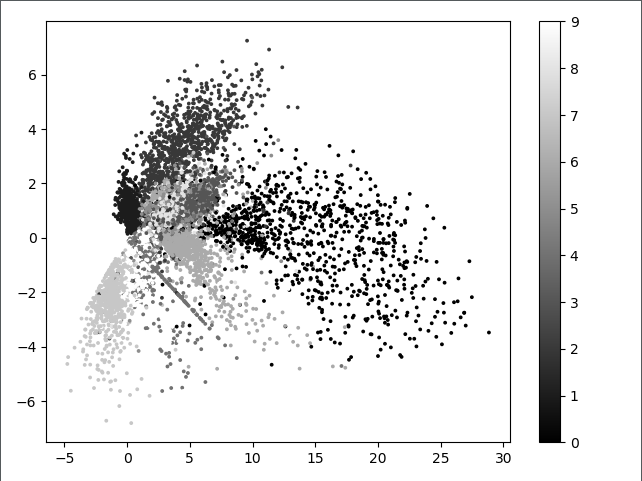
上图中不同表示表示不同的数字,这里不是很直观,看下面的图片对比
(ii)autoencoder还原之后的图片和原图片对比如下:

上图是添加噪声的效果对比,第一行表示原数据,第二行表示噪声处理过后的数据。

上图根据噪声数据还原图片的对比,第一行表示噪声处理过后的数据,第二行表示去噪自编码器decoder还原之后的结果,上图可以看出,去噪自编码器的效果还是可以的。
其他参考文章:
[1] Kandeng. 自编码算法与稀疏性[EB/OL]. (2018/11/24)[ 2018/11/24] http://ufldl.stanford.edu/wiki/index.php/自编码算法与稀疏性
[2] Goodfellow I, Bengio Y, Courville A, et al. Deep learning[M]. Cambridge: MIT press, 2016.
[3] 山下隆义. 图解深度学习[M]. 人民邮电出版社,2018:68-78
[4] Francois Chollet. Building Autoencoders in Keras[EB/OL]. (2018/11/24)[ 2018/11/25] https://blog.keras.io/building-autoencoders-in-keras.html